mirror of
https://github.com/HackTricks-wiki/hacktricks-cloud.git
synced 2026-07-28 22:51:09 -07:00
f
This commit is contained in:
+71
-46
@@ -38,6 +38,16 @@ SITE_DESCRIPTIONS = {
|
||||
"Kubernetes, CI/CD, and workspace pentesting techniques."
|
||||
),
|
||||
}
|
||||
SITE_ALTERNATE_NAMES = {
|
||||
"HackTricks Cloud": ["HT Cloud", "HackTricks Wiki Cloud"],
|
||||
}
|
||||
SITE_SAME_AS = {
|
||||
"HackTricks Cloud": [
|
||||
"https://github.com/HackTricks-wiki/hacktricks-cloud",
|
||||
"https://www.linkedin.com/company/hacktricks",
|
||||
"https://twitter.com/hacktricks_live",
|
||||
],
|
||||
}
|
||||
LANGUAGE_LOCALES = {
|
||||
"af": "af_ZA",
|
||||
"de": "de_DE",
|
||||
@@ -163,10 +173,6 @@ def homepage_description(site_name):
|
||||
return SITE_DESCRIPTIONS.get(site_name, f"{site_name}: practical cloud security guides and references.")
|
||||
|
||||
|
||||
def strip_index_suffix(path):
|
||||
return re.sub(r"(?:^|/)index\.html$", "", path.as_posix())
|
||||
|
||||
|
||||
def is_homepage(rel_path):
|
||||
return rel_path.as_posix() == "index.html"
|
||||
|
||||
@@ -211,40 +217,62 @@ def humanize_slug(value):
|
||||
|
||||
def breadcrumb_items(site_url, lang, rel_path):
|
||||
items = [{"name": "Home", "url": canonical_url(site_url, lang, Path("index.html"))}]
|
||||
bare_path = strip_index_suffix(rel_path)
|
||||
if not bare_path:
|
||||
if is_homepage(rel_path):
|
||||
return items
|
||||
|
||||
parts = [part for part in bare_path.split("/") if part]
|
||||
for idx in range(len(parts)):
|
||||
crumb_rel = Path(*parts[: idx + 1], "index.html")
|
||||
items.append({"name": humanize_slug(parts[idx]), "url": canonical_url(site_url, lang, crumb_rel)})
|
||||
if rel_path.name == "index.html":
|
||||
directory_parts = list(rel_path.parent.parts)
|
||||
page_name = None
|
||||
else:
|
||||
directory_parts = [] if rel_path.parent == Path(".") else list(rel_path.parent.parts)
|
||||
page_name = rel_path.name
|
||||
|
||||
for idx, part in enumerate(directory_parts):
|
||||
crumb_rel = Path(*directory_parts[: idx + 1], "index.html")
|
||||
items.append({"name": humanize_slug(part), "url": canonical_url(site_url, lang, crumb_rel)})
|
||||
|
||||
if page_name:
|
||||
items.append({"name": humanize_slug(page_name), "url": canonical_url(site_url, lang, rel_path)})
|
||||
|
||||
return items
|
||||
|
||||
|
||||
def build_structured_data(site_url, lang, rel_path, title, description, site_name, image_url, languages):
|
||||
def build_structured_data(site_url, lang, rel_path, title, description, site_name, image_url, languages, lastmod):
|
||||
current_url = canonical_url(site_url, lang, rel_path)
|
||||
site_root = site_url.rstrip("/")
|
||||
website_url = canonical_url(site_url, "en", Path("index.html"))
|
||||
data = [
|
||||
{
|
||||
"@context": "https://schema.org",
|
||||
"@type": "Organization",
|
||||
"@id": f"{site_root}/#organization",
|
||||
"name": site_name,
|
||||
"url": site_root,
|
||||
"logo": {"@type": "ImageObject", "url": image_url},
|
||||
},
|
||||
{
|
||||
"@context": "https://schema.org",
|
||||
"@type": "WebSite",
|
||||
"@id": f"{site_root}/#website",
|
||||
"url": site_root,
|
||||
"name": site_name,
|
||||
"inLanguage": languages,
|
||||
"publisher": {"@id": f"{site_root}/#organization"},
|
||||
},
|
||||
{
|
||||
data = []
|
||||
|
||||
if is_homepage(rel_path):
|
||||
data.extend(
|
||||
[
|
||||
{
|
||||
"@context": "https://schema.org",
|
||||
"@type": "Organization",
|
||||
"@id": f"{site_root}/#organization",
|
||||
"name": site_name,
|
||||
"alternateName": SITE_ALTERNATE_NAMES.get(site_name, []),
|
||||
"url": site_root,
|
||||
"description": homepage_description(site_name),
|
||||
"logo": {"@type": "ImageObject", "url": image_url},
|
||||
"sameAs": SITE_SAME_AS.get(site_name, []),
|
||||
},
|
||||
{
|
||||
"@context": "https://schema.org",
|
||||
"@type": "WebSite",
|
||||
"@id": f"{site_root}/#website",
|
||||
"url": site_root,
|
||||
"name": site_name,
|
||||
"alternateName": SITE_ALTERNATE_NAMES.get(site_name, []),
|
||||
"description": homepage_description(site_name),
|
||||
"inLanguage": languages,
|
||||
"publisher": {"@id": f"{site_root}/#organization"},
|
||||
},
|
||||
]
|
||||
)
|
||||
|
||||
data.extend(
|
||||
[
|
||||
{
|
||||
"@context": "https://schema.org",
|
||||
"@type": "WebPage",
|
||||
"@id": f"{current_url}#webpage",
|
||||
@@ -252,11 +280,12 @@ def build_structured_data(site_url, lang, rel_path, title, description, site_nam
|
||||
"name": title,
|
||||
"description": description,
|
||||
"inLanguage": lang,
|
||||
"dateModified": lastmod,
|
||||
"isPartOf": {"@id": f"{site_root}/#website"},
|
||||
"about": {"@id": f"{site_root}/#organization"},
|
||||
"primaryImageOfPage": {"@type": "ImageObject", "url": image_url},
|
||||
},
|
||||
{
|
||||
},
|
||||
{
|
||||
"@context": "https://schema.org",
|
||||
"@type": "BreadcrumbList",
|
||||
"itemListElement": [
|
||||
@@ -268,24 +297,18 @@ def build_structured_data(site_url, lang, rel_path, title, description, site_nam
|
||||
}
|
||||
for index, item in enumerate(breadcrumb_items(site_url, lang, rel_path), start=1)
|
||||
],
|
||||
},
|
||||
]
|
||||
|
||||
if is_homepage(rel_path):
|
||||
data[1]["potentialAction"] = {
|
||||
"@type": "SearchAction",
|
||||
"target": f"{website_url}?search={{search_term_string}}",
|
||||
"query-input": "required name=search_term_string",
|
||||
}
|
||||
},
|
||||
]
|
||||
)
|
||||
|
||||
return data
|
||||
|
||||
|
||||
def build_seo_block(site_url, lang, rel_path, languages, default_lang, title, description, site_name):
|
||||
def build_seo_block(site_url, lang, rel_path, languages, default_lang, title, description, site_name, lastmod):
|
||||
current_url = canonical_url(site_url, lang, rel_path)
|
||||
image_url = social_image_url(site_url)
|
||||
structured_data = json.dumps(
|
||||
build_structured_data(site_url, lang, rel_path, title, description, site_name, image_url, languages),
|
||||
build_structured_data(site_url, lang, rel_path, title, description, site_name, image_url, languages, lastmod),
|
||||
ensure_ascii=False,
|
||||
separators=(",", ":"),
|
||||
)
|
||||
@@ -335,13 +358,13 @@ def update_language_menu_links(document, rel_path, languages):
|
||||
return LANGUAGE_MENU_LINK_RE.sub(replace, document)
|
||||
|
||||
|
||||
def update_document(document, site_url, lang, rel_path, languages, default_lang, site_name):
|
||||
def update_document(document, site_url, lang, rel_path, languages, default_lang, site_name, lastmod):
|
||||
title_match = re.search(r"<title>(.*?)</title>", document, flags=re.I | re.S)
|
||||
page_title = clean_text(title_match.group(1)) if title_match else site_name
|
||||
fallback_description = f"{site_name}: {page_title}"
|
||||
description = homepage_description(site_name) if is_homepage(rel_path) else extract_description(document, fallback_description)
|
||||
seo_block = build_seo_block(
|
||||
site_url, lang, rel_path, languages, default_lang, page_title, description, site_name
|
||||
site_url, lang, rel_path, languages, default_lang, page_title, description, site_name, lastmod
|
||||
)
|
||||
|
||||
document = re.sub(
|
||||
@@ -457,6 +480,7 @@ def process_pages(args):
|
||||
for html_file in iter_html_files(book_dir):
|
||||
rel_path = html_file.relative_to(book_dir)
|
||||
content = html_file.read_text(encoding="utf-8")
|
||||
lastmod = page_lastmod(book_dir, rel_path, html_file)
|
||||
updated = update_document(
|
||||
content,
|
||||
args.site_url,
|
||||
@@ -465,6 +489,7 @@ def process_pages(args):
|
||||
languages,
|
||||
args.default_lang,
|
||||
args.site_name,
|
||||
lastmod,
|
||||
)
|
||||
html_file.write_text(updated, encoding="utf-8")
|
||||
|
||||
|
||||
@@ -62,13 +62,13 @@ If you have **access to the web console** you might be able to access some or al
|
||||
Variables can be stored in Airflow so the **DAGs** can **access** their values. It's similar to secrets of other platforms. If you have **enough permissions** you can access them in the GUI in `http://<airflow>/variable/list/`.\
|
||||
Airflow by default will show the value of the variable in the GUI, however, according to [**this**](https://marclamberti.com/blog/variables-with-apache-airflow/) it's possible to set a **list of variables** whose **value** will appear as **asterisks** in the **GUI**.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
However, these **values** can still be **retrieved** via **CLI** (you need to have DB access), **arbitrary DAG** execution, **API** accessing the variables endpoint (the API needs to be activated), and **even the GUI itself!**\
|
||||
To access those values from the GUI just **select the variables** you want to access and **click on Actions -> Export**.\
|
||||
Another way is to perform a **bruteforce** to the **hidden value** using the **search filtering** it until you get it:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
#### Privilege Escalation
|
||||
|
||||
|
||||
@@ -6,7 +6,7 @@
|
||||
|
||||
Atlantis basically helps you to to run terraform from Pull Requests from your git server.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Local Lab
|
||||
|
||||
@@ -304,7 +304,7 @@ Moreover, if you don't have configured in the **branch protection** to ask to **
|
||||
|
||||
This is the **setting** in Github branch protections:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
#### Webhook Secret
|
||||
|
||||
|
||||
@@ -70,7 +70,7 @@ jobs:
|
||||
These are **secrets** that are only going to be **accessible** by the **project** (by **any branch**).\
|
||||
You can see them **declared in** _https://app.circleci.com/settings/project/github/\<org_name>/\<repo_name>/environment-variables_
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
> [!CAUTION]
|
||||
> The "**Import Variables**" functionality allows to **import variables from other projects** to this one.
|
||||
@@ -79,7 +79,7 @@ You can see them **declared in** _https://app.circleci.com/settings/project/gith
|
||||
|
||||
These are secrets that are **org wide**. By **default any repo** is going to be able to **access any secret** stored here:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
> [!TIP]
|
||||
> However, note that a different group (instead of All members) can be **selected to only give access to the secrets to specific people**.\
|
||||
|
||||
@@ -10,7 +10,7 @@
|
||||
|
||||
### Architecture
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
#### ATC: web UI & build scheduler
|
||||
|
||||
|
||||
@@ -6,7 +6,7 @@
|
||||
|
||||
**Gitea** is a **self-hosted community managed lightweight code hosting** solution written in Go.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Basic Information
|
||||
|
||||
|
||||
@@ -34,7 +34,7 @@ When creating a new team, several important settings are selected:
|
||||
- **Administrator** access
|
||||
- **Specific** access:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Teams & Users
|
||||
|
||||
@@ -66,7 +66,7 @@ You can generate personal access token to **give an application access to your a
|
||||
|
||||
Just like personal access tokens **Oauth applications** will have **complete access** over your account and the places your account has access because, as indicated in the [docs](https://docs.gitea.io/en-us/oauth2-provider/#scopes), scopes aren't supported yet:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Deploy keys
|
||||
|
||||
|
||||
@@ -28,7 +28,7 @@ Without credentials you can look inside _**/asynchPeople/**_ path or _**/securit
|
||||
|
||||
You may be able to get the Jenkins version from the path _**/oops**_ or _**/error**_
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Known Vulnerabilities
|
||||
|
||||
@@ -121,7 +121,7 @@ If the plugin reuses stored creds, Jenkins will attempt to authenticate to `atta
|
||||
|
||||
If the compromised user has **enough privileges to create/modify a new Jenkins node** and SSH credentials are already stored to access other nodes, he could **steal those credentials** by creating/modifying a node and **setting a host that will record the credentials** without verifying the host key:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
You will usually find Jenkins ssh credentials in a **global provider** (`/credentials/`), so you can also dump them as you would dump any other secret. More information in the [**Dumping secrets section**](#dumping-secrets).
|
||||
|
||||
@@ -163,7 +163,7 @@ To exploit pipelines you still need to have access to Jenkins.
|
||||
|
||||
**Pipelines** can also be used as **build mechanism in projects**, in that case it can be configured a **file inside the repository** that will contains the pipeline syntax. By default `/Jenkinsfile` is used:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
It's also possible to **store pipeline configuration files in other places** (in other repositories for example) with the goal of **separating** the repository **access** and the pipeline access.
|
||||
|
||||
@@ -278,7 +278,7 @@ basic-jenkins-information.md
|
||||
|
||||
You can enumerate the **configured nodes** in `/computer/`, you will usually find the \*\*`Built-In Node` \*\* (which is the node running Jenkins) and potentially more:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
It is **specially interesting to compromise the Built-In node** because it contains sensitive Jenkins information.
|
||||
|
||||
@@ -358,7 +358,7 @@ You can list the secrets accessing `/credentials/` if you have enough permission
|
||||
|
||||
If you can **see the configuration of each project**, you can also see in there the **names of the credentials (secrets)** being use to access the repository and **other credentials of the project**.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
#### From Groovy
|
||||
|
||||
|
||||
@@ -33,7 +33,7 @@ In `/configureSecurity` it's possible to **configure the authorization method of
|
||||
- **Logged-in users can do anything**: In this mode, every **logged-in user gets full control** of Jenkins. The only user who won't have full control is **anonymous user**, who only gets **read access**.
|
||||
- **Matrix-based security**: You can configure **who can do what** in a table. Each **column** represents a **permission**. Each **row** **represents** a **user or a group/role.** This includes a special user '**anonymous**', which represents **unauthenticated users**, as well as '**authenticated**', which represents **all authenticated users**.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
- **Project-based Matrix Authorization Strategy:** This mode is an **extension** to "**Matrix-based security**" that allows additional ACL matrix to be **defined for each project separately.**
|
||||
- **Role-Based Strategy:** Enables defining authorizations using a **role-based strategy**. Manage the roles in `/role-strategy`.
|
||||
|
||||
@@ -6,11 +6,11 @@
|
||||
|
||||
In "New Item" (accessible in `/view/all/newJob`) select **Pipeline:**
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
In the **Pipeline section** write the **reverse shell**:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
```groovy
|
||||
pipeline {
|
||||
@@ -30,7 +30,7 @@ pipeline {
|
||||
|
||||
Finally click on **Save**, and **Build Now** and the pipeline will be executed:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
## Modifying a Pipeline
|
||||
|
||||
|
||||
@@ -12,13 +12,13 @@ This method is very noisy because you have to create a hole new project (obvious
|
||||
1. If **Build now** button doesn't appear, you can still go to **configure** --> **Build Triggers** --> `Build periodically` and set a cron of `* * * * *`
|
||||
2. Instead of using cron, you can use the config "**Trigger builds remotely**" where you just need to set a the api token name to trigger the job. Then go to your user profile and **generate an API token** (call this API token as you called the api token to trigger the job). Finally, trigger the job with: **`curl <username>:<api_token>@<jenkins_url>/job/<job_name>/build?token=<api_token_name>`**
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
## Modifying a Project
|
||||
|
||||
Go to the projects and check **if you can configure any** of them (look for the "Configure button"):
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
If you **cannot** see any **configuration** **button** then you **cannot** **configure** it probably (but check all projects as you might be able to configure some of them and not others).
|
||||
|
||||
@@ -28,7 +28,7 @@ Or **try to access to the path** `/job/<proj-name>/configure` or `/me/my-views/v
|
||||
|
||||
If you are allowed to configure the project you can **make it execute commands when a build is successful**:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Click on **Save** and **build** the project and your **command will be executed**.\
|
||||
If you are not executing a reverse shell but a simple command you can **see the output of the command inside the output of the build**.
|
||||
|
||||
@@ -12,7 +12,7 @@ HashiCorp Terraform is an **infrastructure as code tool** that lets you define b
|
||||
|
||||
Terraform creates and manages resources on cloud platforms and other services through their application programming interfaces (APIs). Providers enable Terraform to work with virtually any platform or service with an accessible API.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
HashiCorp and the Terraform community have already written **more than 1700 providers** to manage thousands of different types of resources and services, and this number continues to grow. You can find all publicly available providers on the [Terraform Registry](https://registry.terraform.io/), including Amazon Web Services (AWS), Azure, Google Cloud Platform (GCP), Kubernetes, Helm, GitHub, Splunk, DataDog, and many more.
|
||||
|
||||
@@ -22,7 +22,7 @@ The core Terraform workflow consists of three stages:
|
||||
- **Plan:** Terraform creates an execution plan describing the infrastructure it will create, update, or destroy based on the existing infrastructure and your configuration.
|
||||
- **Apply:** On approval, Terraform performs the proposed operations in the correct order, respecting any resource dependencies. For example, if you update the properties of a VPC and change the number of virtual machines in that VPC, Terraform will recreate the VPC before scaling the virtual machines.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Terraform Lab
|
||||
|
||||
|
||||
@@ -16,13 +16,13 @@ basic-travisci-information.md
|
||||
|
||||
To launch an attack you first need to know how to trigger a build. By default TravisCI will **trigger a build on pushes and pull requests**:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
#### Cron Jobs
|
||||
|
||||
If you have access to the web application you can **set crons to run the build**, this could be useful for persistence or to trigger a build:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
> [!NOTE]
|
||||
> It looks like It's not possible to set crons inside the `.travis.yml` according to [this](https://github.com/travis-ci/travis-ci/issues/9162).
|
||||
@@ -31,7 +31,7 @@ If you have access to the web application you can **set crons to run the build**
|
||||
|
||||
TravisCI by default disables sharing env variables with PRs coming from third parties, but someone might enable it and then you could create PRs to the repo and exfiltrate the secrets:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Dumping Secrets
|
||||
|
||||
@@ -41,7 +41,7 @@ As explained in the [**basic information**](basic-travisci-information.md) page,
|
||||
- To enumerate the **custom encrypted secrets** the best you can do is to **check the `.travis.yml` file**.
|
||||
- To **enumerate encrypted files** you can check for **`.enc` files** in the repo, for lines similar to `openssl aes-256-cbc -K $encrypted_355e94ba1091_key -iv $encrypted_355e94ba1091_iv -in super_secret.txt.enc -out super_secret.txt -d` in the config file, or for **encrypted iv and keys** in the **Environment Variables** such as:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### TODO:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ For example, in Github it will ask for the following permissions:
|
||||
|
||||
In TravisCI, as in other CI platforms, it's possible to **save at repo level secrets** that will be saved encrypted and be **decrypted and push in the environment variable** of the machine executing the build.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
It's possible to indicate the **branches to which the secrets are going to be available** (by default all) and also if TravisCI **should hide its value** if it appears **in the logs** (by default it will).
|
||||
|
||||
@@ -35,7 +35,7 @@ travis pubkey -r carlospolop/t-ci-test
|
||||
|
||||
Then, you can use this setup to **encrypt secrets and add them to your `.travis.yaml`**. The secrets will be **decrypted when the build is run** and accessible in the **environment variables**.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Note that the secrets encrypted this way won't appear listed in the environmental variables of the settings.
|
||||
|
||||
@@ -63,7 +63,7 @@ Commit all changes to your .travis.yml.
|
||||
|
||||
Note that when encrypting a file 2 Env Variables will be configured inside the repo such as:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
## TravisCI Enterprise
|
||||
|
||||
@@ -87,7 +87,7 @@ Travis CI Enterprise is an **on-prem version of Travis CI**, which you can deplo
|
||||
|
||||
The amount of deployed TCI Worker and build environment OS images will determine the total concurrent capacity of Travis CI Enterprise deployment in your infrastructure.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
@@ -4,7 +4,7 @@
|
||||
|
||||
## Organization Hierarchy
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Accounts
|
||||
|
||||
|
||||
+2
-2
@@ -20,9 +20,9 @@ I tested this doing the process in the web page, the permissions indicated previ
|
||||
|
||||
During the **creation of the build project** you can indicate a **command to run** (rev shell?) and to run the build phase as **privileged user**, that's the configuration the attacker needs to compromise:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### ?`codebuild:UpdateProject, codepipeline:UpdatePipeline, codepipeline:StartPipelineExecution`
|
||||
|
||||
|
||||
@@ -38,7 +38,7 @@ For example, an attacker with those **permissions over a cloudformation bucket**
|
||||
|
||||
And the hijack is possible because there is a **small time window from the moment the template is uploaded** to the bucket to the moment the **template is deployed**. An attacker might just create a **lambda function** in his account that will **trigger when a bucket notification is sent**, and **hijacks** the **content** of that **bucket**.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
The Pacu module [`cfn__resouce_injection`](https://github.com/RhinoSecurityLabs/pacu/wiki/Module-Details#cfn__resource_injection) can be used to automate this attack.\
|
||||
For mor informatino check the original research: [https://rhinosecuritylabs.com/aws/cloud-malware-cloudformation-injection/](https://rhinosecuritylabs.com/aws/cloud-malware-cloudformation-injection/)
|
||||
|
||||
+1
-1
@@ -65,7 +65,7 @@ Therefore, users with `ssm:StartSession` will be able to **get a shell inside EC
|
||||
aws ssm start-session --target "ecs:CLUSTERNAME_TASKID_RUNTIMEID"
|
||||
```
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
**Potential Impact:** Direct privesc to the `ECS`IAM roles attached to running tasks with `ExecuteCommand` enabled.
|
||||
|
||||
|
||||
+1
-1
@@ -21,7 +21,7 @@ Moreover, in order to **access Internet**, there are some interesting configurat
|
||||
- You could also have a **NAT gateway** in a **private subnet** so it's possible to **connect to external services** from that private subnet, but it's **not possible to reach them from the outside**.
|
||||
- The NAT gateway can be **public** (access to the internet) or **private** (access to other VPCs)
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
## VPC
|
||||
|
||||
|
||||
@@ -16,7 +16,7 @@ A Lambda can have **several versions**.\
|
||||
And it can have **more than 1** version exposed via **aliases**. The **weights** of **each** of the **versions** exposed inside and alias will decide **which alias receive the invocation** (it can be 90%-10% for example).\
|
||||
If the code of **one** of the aliases is **vulnerable** you can send **requests until the vulnerable** versions receives the exploit.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Resource Policies
|
||||
|
||||
@@ -122,7 +122,7 @@ Now it's time to find out possible lambda functions to execute:
|
||||
aws --region us-west-2 --profile level6 lambda list-functions
|
||||
```
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
A lambda function called "Level6" is available. Lets find out how to call it:
|
||||
|
||||
@@ -130,7 +130,7 @@ A lambda function called "Level6" is available. Lets find out how to call it:
|
||||
aws --region us-west-2 --profile level6 lambda get-policy --function-name Level6
|
||||
```
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Now, that you know the name and the ID you can get the Name:
|
||||
|
||||
@@ -138,7 +138,7 @@ Now, that you know the name and the ID you can get the Name:
|
||||
aws --profile level6 --region us-west-2 apigateway get-stages --rest-api-id "s33ppypa75"
|
||||
```
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
And finally call the function accessing (notice that the ID, Name and function-name appears in the URL): [https://s33ppypa75.execute-api.us-west-2.amazonaws.com/Prod/level6](https://s33ppypa75.execute-api.us-west-2.amazonaws.com/Prod/level6)
|
||||
|
||||
|
||||
+4
-4
@@ -36,11 +36,11 @@ Inside each folder each log will have a **name following this format**: **`Accou
|
||||
|
||||
Log File Naming Convention
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Moreover, **digest files (to check file integrity)** will be inside the **same bucket** in:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Aggregate Logs from Multiple Accounts
|
||||
|
||||
@@ -81,7 +81,7 @@ Note that in order to allow CloudTrail to send the logs to CloudWatch a **role**
|
||||
|
||||
CloudTrail Event History allows you to inspect in a table the logs that have been recorded:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Insights
|
||||
|
||||
@@ -203,7 +203,7 @@ In the past there were some **AWS services that doesn't send logs to CloudTrail*
|
||||
|
||||
This way, an **attacker can obtain the ARN of the key without triggering any log**. In the ARN the attacker can see the **AWS account ID and the name**, it's easy to know the HoneyToken's companies accounts ID and names, so this way an attacker can identify id the token is a HoneyToken.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
> [!CAUTION]
|
||||
> Note that all public APIs discovered to not being creating CloudTrail logs are now fixed, so maybe you need to find your own...
|
||||
|
||||
+1
-1
@@ -30,7 +30,7 @@ A configuration item or **CI** as it's known, is a key component of AWS Config.
|
||||
- Lambda feeds back to Config
|
||||
- If rule has been broken, Config fires up an SNS
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Config Rules
|
||||
|
||||
|
||||
@@ -46,7 +46,7 @@ In the talk [**Breaking the Isolation: Cross-Account AWS Vulnerabilities**](http
|
||||
|
||||
During the talk they specify several examples, such as S3 buckets **allowing cloudtrai**l (of **any AWS** account) to **write to them**:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Other services found vulnerable:
|
||||
|
||||
|
||||
+1
-1
@@ -62,7 +62,7 @@ This is a policy example:
|
||||
|
||||
That is the **error** you will find if you uses a **role that doesn't exist**. If the role **exist**, the policy will be **saved** without any errors. (The error is for update, but it also works when creating)
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
#### CLI
|
||||
|
||||
|
||||
+3
-3
@@ -108,7 +108,7 @@ or you can access the bucket visiting: `flaws.cloud.s3-us-west-2.amazonaws.com`
|
||||
|
||||
If you try to access a bucket, but in the **domain name you specify another region** (for example the bucket is in `bucket.s3.amazonaws.com` but you try to access `bucket.s3-website-us-west-2.amazonaws.com`, then you will be **indicated to the correct location**:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Enumerating the bucket
|
||||
|
||||
@@ -116,11 +116,11 @@ To test the openness of the bucket a user can just enter the URL in their web br
|
||||
|
||||
Open to everyone:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Private:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
You can also check this with the cli:
|
||||
|
||||
|
||||
+1
-1
@@ -27,7 +27,7 @@ Moreover, if someone compromise a VM where an automation account script is runni
|
||||
|
||||
As it's possible to see in the following image, having Administrator access over the VM it's possible to find in the **environment variables of the process** the URL and secret to access the automation account metadata service:
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
### `Microsoft.Automation/automationAccounts/jobs/write`, `Microsoft.Automation/automationAccounts/runbooks/draft/write`, `Microsoft.Automation/automationAccounts/jobs/output/read`, `Microsoft.Automation/automationAccounts/runbooks/publish/action` (`Microsoft.Resources/subscriptions/resourcegroups/read`, `Microsoft.Automation/automationAccounts/runbooks/write`)
|
||||
|
||||
@@ -20,7 +20,7 @@ These are the **different permissions** [according to the docs](https://learn.mi
|
||||
|
||||
There are also some **built-in roles** that can be assigned, and it's also possible to create **custom roles**.
|
||||
|
||||

|
||||

|
||||
|
||||
### Authentication
|
||||
|
||||
|
||||
@@ -19,7 +19,7 @@ Get-AzureADGroup -Filter "DisplayName eq 'Intune Administrators'"
|
||||
2. Go to **Devices** -> **All Devices** to check devices enrolled to Intune
|
||||
3. Go to **Scripts** and click on **Add** for Windows 10.
|
||||
4. Add a **Powershell script**
|
||||
- .png>)
|
||||
- .png>)
|
||||
5. Specify **Add all users** and **Add all devices** in the **Assignments** page.
|
||||
|
||||
The execution of the script can take up to **one hour**.
|
||||
|
||||
@@ -70,7 +70,7 @@ Note that **`iam.serviceAccountKeys.update` won't work to modify the key** of a
|
||||
|
||||
If you have the **`iam.serviceAccounts.implicitDelegation`** permission on a Service Account that has the **`iam.serviceAccounts.getAccessToken`** permission on a third Service Account, then you can use implicitDelegation to **create a token for that third Service Account**. Here is a diagram to help explain.
|
||||
|
||||
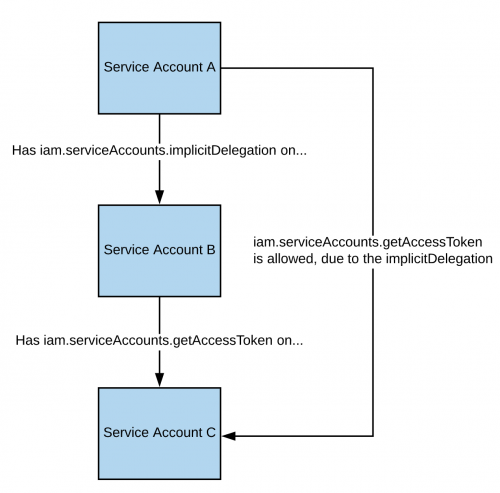
|
||||

|
||||
|
||||
Note that according to the [**documentation**](https://cloud.google.com/iam/docs/understanding-service-accounts), the delegation of `gcloud` only works to generate a token using the [**generateAccessToken()**](https://cloud.google.com/iam/credentials/reference/rest/v1/projects.serviceAccounts/generateAccessToken) method. So here you have how to get a token using the API directly:
|
||||
|
||||
|
||||
@@ -6,7 +6,7 @@
|
||||
|
||||
**If you are lucky enough you may be able to escape from it to the node:**
|
||||
|
||||
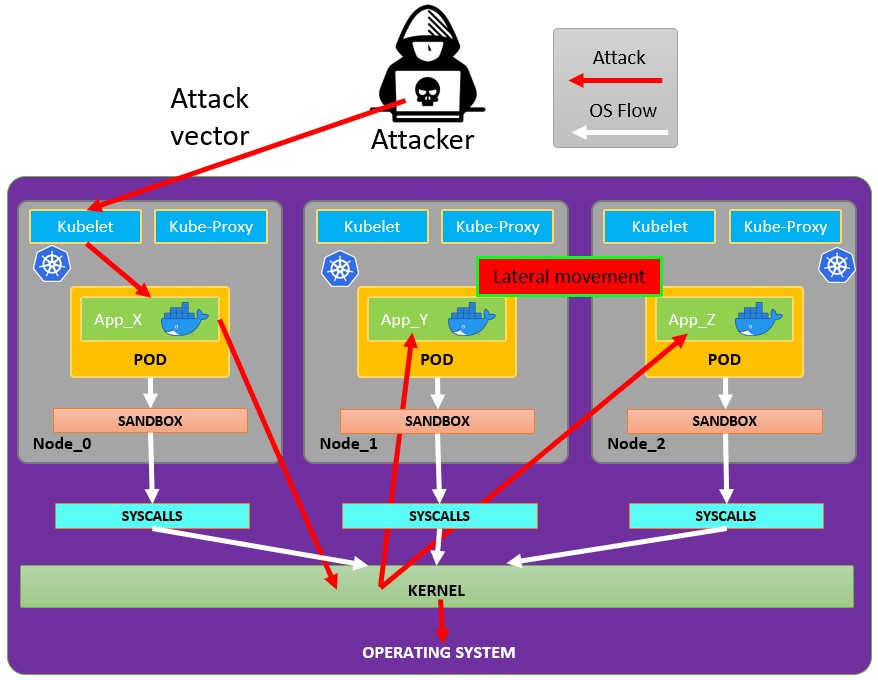
|
||||

|
||||
|
||||
### Escaping from the pod
|
||||
|
||||
|
||||
@@ -17,7 +17,7 @@
|
||||
|
||||
### Architecture
|
||||
|
||||
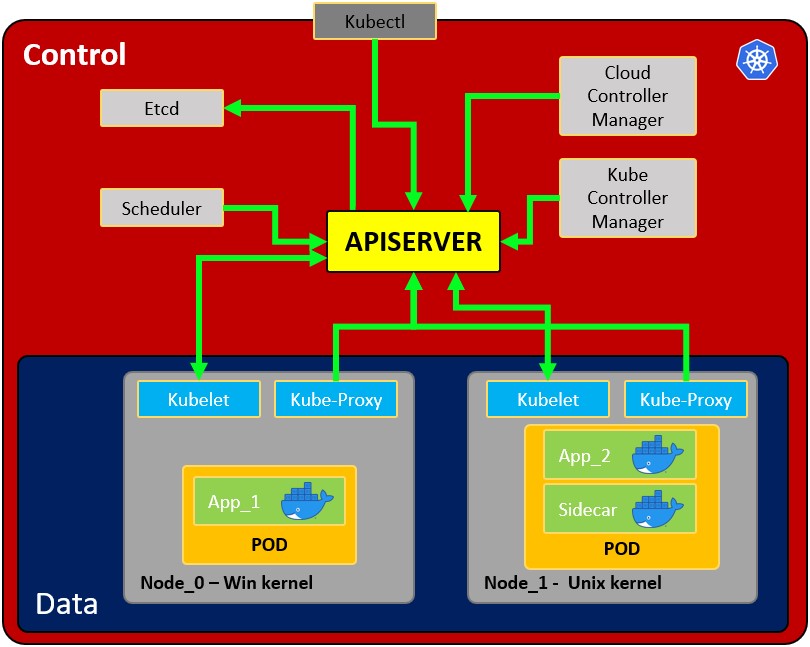
|
||||

|
||||
|
||||
- **Node**: operating system with pod or pods.
|
||||
- **Pod**: Wrapper around a container or multiple containers with. A pod should only contain one application (so usually, a pod run just 1 container). The pod is the way kubernetes abstracts the container technology running.
|
||||
@@ -53,7 +53,7 @@ When a pod creates data that shouldn't be lost when the pod disappear it should
|
||||
|
||||
### PKI infrastructure - Certificate Authority CA:
|
||||
|
||||
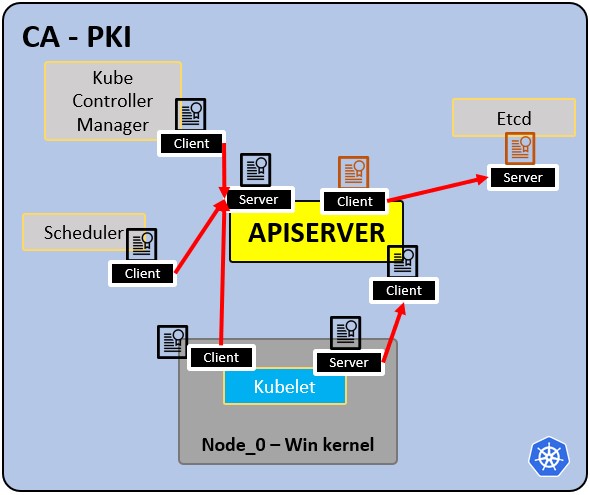
|
||||

|
||||
|
||||
- CA is the trusted root for all certificates inside the cluster.
|
||||
- Allows components to validate to each other.
|
||||
@@ -394,7 +394,7 @@ There are different types of secrets in Kubernetes
|
||||
|
||||
**How secrets works:**
|
||||
|
||||
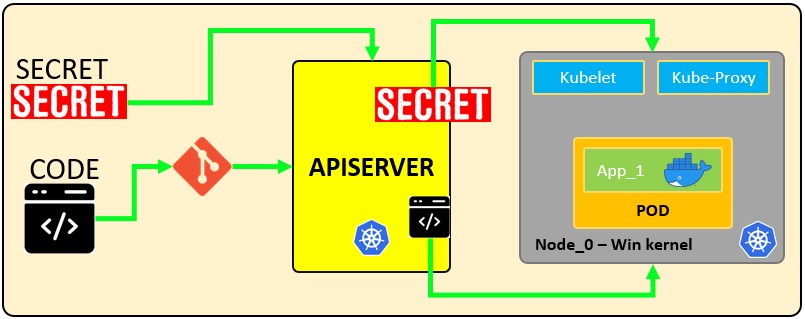
|
||||

|
||||
|
||||
The following configuration file defines a **secret** called `mysecret` with 2 key-value pairs `username: YWRtaW4=` and `password: MWYyZDFlMmU2N2Rm`. It also defines a **pod** called `secretpod` that will have the `username` and `password` defined in `mysecret` exposed in the **environment variables** `SECRET_USERNAME` \_\_ and \_\_ `SECRET_PASSWOR`. It will also **mount** the `username` secret inside `mysecret` in the path `/etc/foo/my-group/my-username` with `0640` permissions.
|
||||
|
||||
|
||||
+1
-1
@@ -12,7 +12,7 @@ RBAC’s permission model is built from **three individual parts**:
|
||||
2. **Subject (User, Group or ServiceAccount) –** The object that will receive the permissions.
|
||||
3. **RoleBinding\ClusterRoleBinding –** The connection between Role\ClusterRole and the subject.
|
||||
|
||||
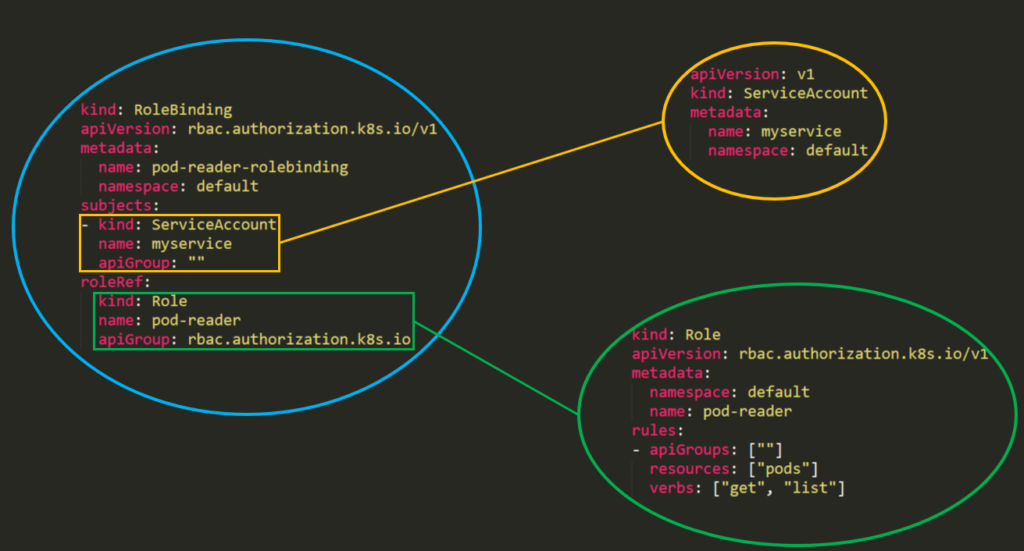
|
||||

|
||||
|
||||
The difference between “**Roles**” and “**ClusterRoles**” is just where the role will be applied – a “**Role**” will grant access to only **one** **specific** **namespace**, while a “**ClusterRole**” can be used in **all namespaces** in the cluster. Moreover, **ClusterRoles** can also grant access to:
|
||||
|
||||
|
||||
@@ -132,7 +132,7 @@ sudo nmap -sS -p 30000-32767 <IP>
|
||||
|
||||
Anonymous access to **kube-apiserver API endpoints is not allowed**. But you could check some endpoints:
|
||||
|
||||
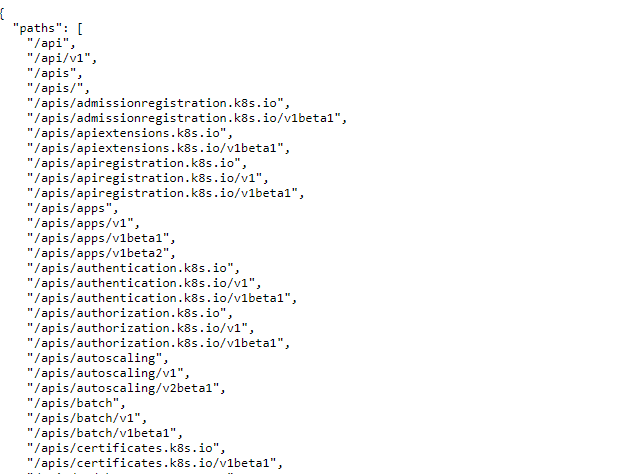
|
||||

|
||||
|
||||
### **Checking for ETCD Anonymous Access**
|
||||
|
||||
@@ -199,7 +199,7 @@ When a **kubelet read-only port** is exposed, it becomes possible for informatio
|
||||
|
||||
An example of how this vulnerability can be exploited involves a remote attacker accessing a specific URL. By navigating to `http://<external-IP>:10255/pods`, the attacker can potentially retrieve sensitive information from the kubelet:
|
||||
|
||||

|
||||

|
||||
|
||||
## References
|
||||
|
||||
@@ -214,4 +214,3 @@ https://labs.f-secure.com/blog/attacking-kubernetes-through-kubelet
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -104,7 +104,7 @@ Users can only delegate access to another user in the same organization, regardl
|
||||
|
||||
Sign in using an _administrator account_, not your current account CarlosPolop@gmail.com
|
||||
|
||||
2. In the Admin console, go to Menu  **Apps****Google Workspace****Gmail****User settings**.
|
||||
2. In the Admin console, go to Menu  **Apps****Google Workspace****Gmail****User settings**.
|
||||
3. To apply the setting to everyone, leave the top organizational unit selected. Otherwise, select a child [organizational unit](https://support.google.com/a/topic/1227584).
|
||||
4. Click **Mail delegation**.
|
||||
5. Check the **Let users delegate access to their mailbox to other users in the domain** box.
|
||||
|
||||
Reference in New Issue
Block a user